VL-DAC — обучаем VLM быстрее и дешевле И говорим за…
VL-DAC — обучаем VLM быстрее и дешевле
И говорим за это спасибо лабе фундаментальных исследований Т-Банка. Её исследователи представили новый метод дообучения визуально-языковых моделей на AAMAS — одной из главных конференций по автономным агентам и мультиагентным системам уровня А.
Главное открытие: новые навыки для VLM можно получать не на реальных данных, а на синтетических средах — и переносить на внешние задачи.
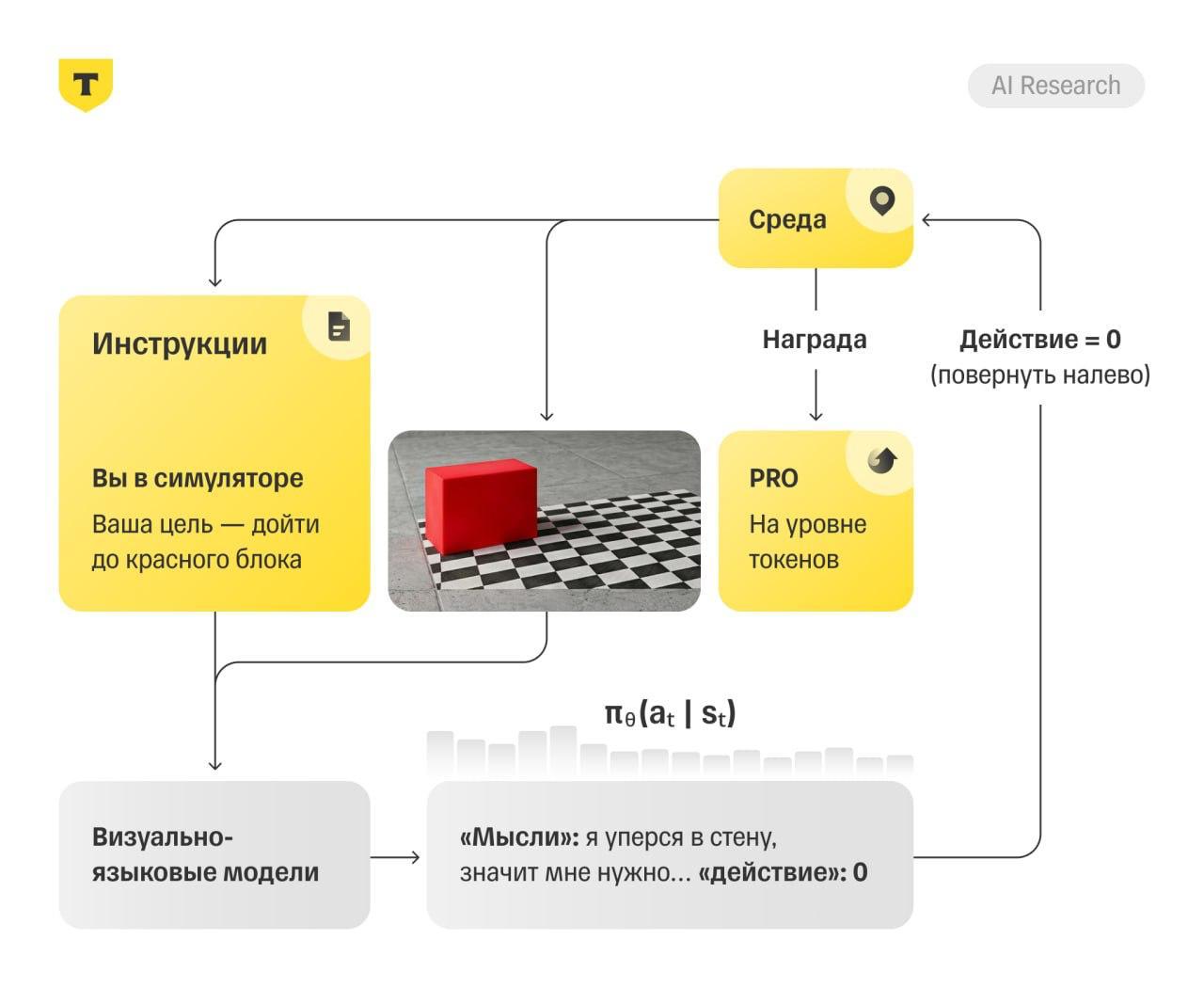
Сейчас модели сильны в распознавании изображений и интерфейсов, но плохо справляются с задачами, где нужно действовать последовательно. Например, открыть нужный раздел сайта, применить фильтр, выбрать товар или построить маршрут. Для такого обучения обычно нужны реальные среды и огромное количество данных. Но исследователи решили пойти другим путем — использовать набор симуляторов, каждый из которых тренирует отдельный навык.
Так появился метод VL-DAC. Один симулятор учит модель навигации, другой — взаимодействию с объектами, третий — работе с веб-интерфейсами. В итоге модель учится не просто “видеть”, а понимать, какое действие приближает её к цели. После обучения Qwen2-VL-7B стала более чем на 50% лучше справляться с интерактивными задачами, а также улучшила навыки пространственной ориентации и веб-навигации.
Главный плюс подхода — стоимость и скорость. Вместо дорогого сбора реальных данных модель можно быстро прогонять через тысячи синтетических сценариев, а затем переносить навыки уже в прикладные задачи.
VL-DAC также не нуждается в больших объёмах памяти для хранения информации о “полезности” шагов и не требует постоянной ручной донастройки коэффициентов. Прогон на 50 тысяч шагов среды для Qwen2-VL-7B занял около 20 GPU-часов на одной H100-80GB.
#полезное

Оцените материал:

