Ускорение моделей Gemini Nano на пикселях с помощью замороженного прогнозирования нескольких токенов.
Мы предлагаем метод для внедрения многотокенного прогнозирования в замороженные производственные модели, ускоряющий вывод данных на устройстве без недостатков, связанных с использованием отдельных инструментов для составления прогнозов.
Быстрые ссылки
- Ключевые слова для блога
- Делиться
Теперь мощные модели обработки больших языков (LLM) доступны прямо в вашем кармане благодаря таким устройствам, как Gemini Nano и Gemma. Эта технология позволяет использовать повседневные функции телефона — например, мгновенно обобщать множество уведомлений или проверять важные текстовые сообщения — без отправки ваших личных данных за пределы устройства. Но чтобы эти функции были полезны для обычных пользователей, они должны работать очень эффективно.
Обеспечение такой скорости на мобильном устройстве представляет собой серьезную проблему. В отличие от обширных серверных сред, мобильные телефоны работают в условиях жесткого ограничения энергопотребления и объема оперативной памяти (ОЗУ). Кроме того, стандартные языковые модели генерируют текст «авторегрессивно» — то есть обрабатывают и выводят только одно слово (или токен) за раз. Этот пошаговый процесс создает узкое место, недоиспользуя вычислительную мощность телефона и перегружая его память, что в конечном итоге может замедлить работу пользователя и разрядить батарею.
Для преодоления этого узкого места мы объявляем о новой архитектуре, которая интегрирует многотокенное предсказание (MTP) в существующие, «замороженные» модели Gemini Nano v3. Основываясь на предыдущих подходах, таких как фреймворк EAGLE и Confident Adaptive Language Modeling (CALM), мы разработали новые архитектурные компоненты для максимального повышения эффективности, особенно в мобильных средах. В наших недавних объявлениях мы подчеркнули ускорение Gemma 4 с помощью MTP и предоставление этой возможности разработчикам.
В сегодняшней статье рассматриваются уникальные, экстремальные ограничения периферийных вычислений. Этот подход, недавно внедренный в серии Pixel 9 и 10, обеспечивает ускорение работы «из коробки». Для пользователей это означает, что такие функции, как сводки уведомлений с использованием ИИ и проверка орфографии, генерируют текст значительно быстрее и с меньшим энергопотреблением. Для разработчиков это устраняет одну из главных проблем: предоставление высокоскоростного ИИ на устройстве без необходимости тонкой настройки отдельных, ресурсоемких моделей для каждой новой задачи.
Стратегия «позднего выхода»
MTP основан на эволюции спекулятивного декодирования. В традиционной схеме генерация N токенов требует N прямых проходов большой модели. Спекулятивное декодирование разделяет этот процесс на две части:
- Черновой вариант: более компактная и быстрая модель аппроксимации («черновой вариант») генерирует короткую последовательность токенов-кандидатов (например, 3 токена).
- Проверка: большая модель («верификатор») обрабатывает эти кандидаты параллельно. Если кандидаты соответствуют предсказаниям большой модели, они принимаются. В противном случае система возвращается к первому расхождению.
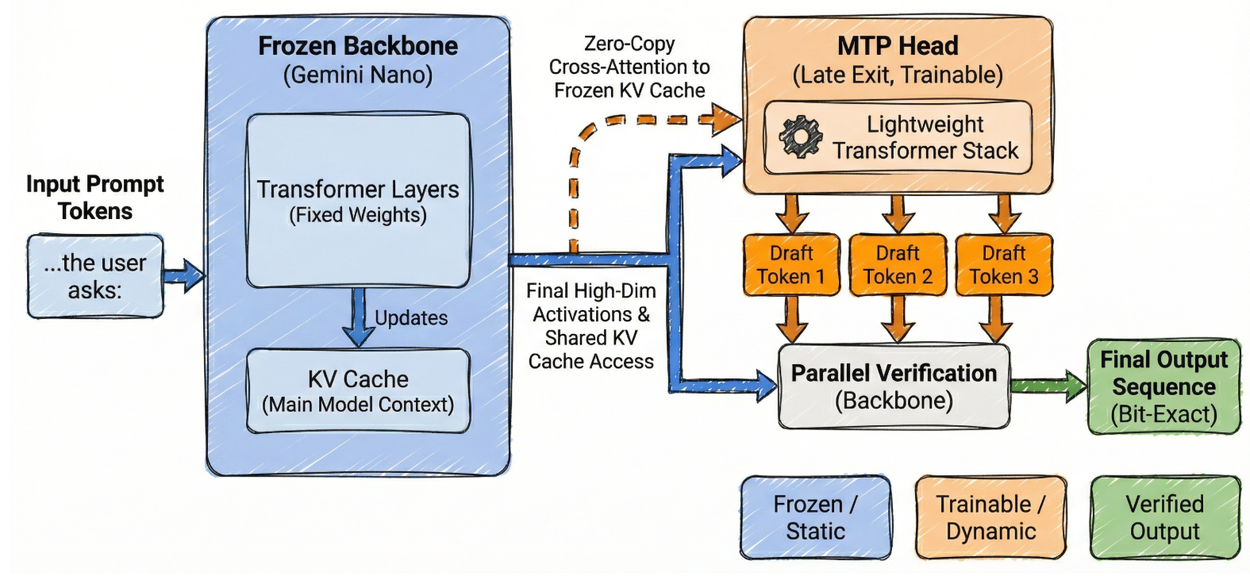
Однако это приводит к некоторым неэффективностям. Запуск отдельной «автономной» модели для создания черновиков (например, 128 миллионов параметров) конкурирует за ограниченный объем оперативной памяти. Кроме того, автономная модель «слепа» к богатому внутреннему состоянию основной модели, предсказывая следующие токены, основываясь исключительно на истории текста без семантического контекста, который уже вычислил основной модель. MTP решает эти проблемы, переходя от автономной архитектуры к интегрированной. Вместо обучения отдельной небольшой языковой модели для создания черновиков, мы добавляем облегченный модуль Transformer, модуль MTP, к последним слоям основной модели.
Эта архитектура, использующая глубокий выходной слой для формирования шаблонов, задействует работу, уже выполненную базовой моделью. Голова MTP берет окончательные многомерные активации (скрытые состояния) основной модели и использует их для авторегрессионного прогнозирования последовательности будущих токенов.
Преимущество замороженного позвоночника
Хотя головки MTP обычно предварительно обучаются вместе с базовой моделью — как, например, в наших последних версиях моделей Gemma 4 — это нецелесообразно при использовании уже развернутых на устройстве базовых моделей. Вместо этого наша работа сосредоточена на модернизации головки чертежника для работы независимо от конвейера предварительного обучения.
Мы берем полностью обученную модель Gemini Nano v3, замораживаем ее веса и добавляем плотный стек трансформеров — головку MTP — к финальным слоям. Мы обучаем только эти параметры, чтобы минимизировать ошибку предсказания для будущих токенов. Благодаря замороженной базовой архитектуре, MTP становится исключительно оптимизацией эффективности, гарантируя отсутствие ухудшения возможностей базовой модели или соответствия требованиям безопасности.
Поскольку некорректные черновики отбрасываются в процессе проверки, окончательный результат остается побитово идентичным основной модели, что позволяет нам внедрять обновления, повышающие эффективность, с полной обратной совместимостью.
Архитектура без копирования
В то время как стандартные реализации MTP оптимизируют эффективность обучения за счет совместного использования статических параметров (таких как веса встраивания) между основной моделью и программистом, вывод на устройстве сталкивается с более строгим узким местом: динамической памятью. Даже при совместном использовании весов, если программист обрабатывает контекст независимо, он берет на себя «двойную нагрузку» на память, создавая и поддерживая собственный кэш ключ-значение (KV). Учитывая ограниченную память на мобильных устройствах, предотвращение этой избыточности имеет решающее значение.
Для решения этой проблемы мы разработали архитектуру с нулевым копированием, в которой головной модуль MTP эффективно использует состояние основной модели. Вместо хранения собственной истории, головной модуль MTP предназначен для прямого обращения к замороженному кэшу ключ-значение основной модели. Это позволяет разработчику запрашивать «память» и контекст, уже вычисленные базовой сетью, без дублирования.
Данная конструкция обеспечивает два преимущества в эффективности. Во-первых, она устраняет задержку предварительного заполнения в редакторе шаблонов: благодаря использованию существующего кэша, головному устройству не требуется дополнительное время для обработки запроса. Во-вторых, она уменьшает объем используемой памяти во время выполнения. Мы наблюдали экономию в 130 МБ на экземпляр по сравнению с автономным редактором шаблонов за счет экономии таблиц поиска встраивания в редактор шаблонов, вариантов точечного внимания для предварительного заполнения и параметров настройки, специфичных для приложения.
Используя скрытые состояния и кэш ключ-значение основной модели, головной узел MTP генерирует токены-кандидаты, которые параллельно проверяются магистральной сетью, что устраняет избыточную задержку предварительного заполнения и сокращает использование памяти до 130 МБ.
Раскрытие более полных возможностей представления информации
В наших экспериментах мы обнаружили, что MTP-фреймворки неизменно выдают более точные предсказания токенов, что приводит к ускорению работы устройств Pixel 9 на 50% и более [aef552], в зависимости от задачи, по сравнению с «автономными фреймворками» с сопоставимым количеством параметров.
Этот разрыв в производительности обусловлен доступом MTP к более богатым представлениям. В отличие от автономных графических редакторов, которые рассматривают основную модель как черный ящик, модуль MTP напрямую использует окончательные активации, уже обработанные более крупной базовой схемой:
- Инструкция следующая: В таких задачах, как составление резюме или переписывание текста со сложными ограничениями, MTP значительно превзошла автономные программы для точного составления черновиков.
- Предсказуемые текстовые структуры: Для задач с высокой структурной предсказуемостью (например, интеллектуальные ответы) головная часть MTP эффективно изучала синтаксические шаблоны основной модели, достигая улучшения принятия токенов до 55%.
Влияние на реальный мир
Для развертывания MTP на устройствах Pixel 9 и 10 мы переработали стек обработки данных на устройстве, чтобы справиться со сложной зависимостью между этапами верификации и проектирования.
Результаты подтвердили правильность выбранной архитектуры. В производственных задачах, таких как создание сводок уведомлений с использованием ИИ и проверка орфографии, MTP правильно предсказывает в среднем почти два дополнительных токена за один проход вывода. Кроме того, меньшее количество шагов проверки означает меньшее время, затрачиваемое на пробуждение ресурсоемких процессоров, снижение энергопотребления и увеличение времени автономной работы.

Влияние генерации токенов Gemini Nano на использование MTP по сравнению с автономным инструментом создания шаблонов для отдельных приложений в различных приложениях Pixel 9.
Перспективы на будущее
Мы рассчитываем интегрировать MTP в будущие устройства Pixel, а также изучить альтернативные архитектуры, включая параллельное декодирование и парадигмы без вспомогательных модулей, чтобы еще больше снизить задержку черновика и увеличить одновременную проверку токенов в условиях жестких ограничений мобильных устройств.
Мы также изучаем способы более эффективного решения проблемы присущей генерации языка неоднозначности. В то время как стандартное спекулятивное декодирование предполагает единственный наилучший будущий путь, мы разрабатываем методы, позволяющие модели параллельно исследовать возможности ветвления. Это направлено на максимизацию вероятности принятия длинных последовательностей даже в условиях неопределенности. Кроме того, мы изучаем снисходительность к проверке: ослабление строгого требования точного совпадения токенов между черновиком и проверкой для конкретных случаев использования с целью повышения эффективности на периферии сети.
Благодарности
Эта работа является частью наших усилий по оптимизации эффективности LLM на устройствах, в которых участвуют Филиппо Гальгани, Омри Хомбургер, Пуджа Консул, Мэтью Марквелл и Вивек Кумар. Некоторые элементы были разработаны на основе разработок команды Gemini в Google DeepMind: Тал Шустер, Цивей джи, Иван Коротков и Ганеш Джавахар. Мы также хотели бы выразить огромную благодарность за рецензии, ценные отзывы и поддержку Надаву Бару, Утку Эвчи, Ниру Шабату, Джо Зоу и командам Google Research, Google Deepmind и Platforms & Devices.
Источник: research.google
Оцените материал:
