Следующая глава в области устойчивости к наводнениям: открытый исходный код гидрологической платформы Google.
Мы открыли исходный код нашей гидрологической модели, чтобы позволить национальным метеорологическим и гидрологическим службам интегрировать передовые методы прогнозирования наводнений на основе искусственного интеллекта в свои рабочие процессы.
Быстрые ссылки
- Гидрологическая структура
- Центр по борьбе с наводнениями
- Делиться
Наводнения — одно из самых разрушительных стихийных бедствий в мире, часто возникающее без предупреждения и оставляющее после себя долгосрочный ущерб. В течение нескольких лет исследовательский центр Google разрабатывал передовые модели искусственного интеллекта для более точного прогнозирования наводнений, обеспечивая доступ к этой технологии службам экстренного реагирования, чтобы дать им время на действия. Для дальнейшей защиты уязвимых сообществ мы теперь публикуем исходный код нашей системы гидрологического моделирования на GitHub, чтобы другие могли использовать и развивать её.
Эта открытая платформа для моделирования позволяет исследователям и синоптикам обучать модели прогнозирования наводнений на основе ИИ, используя ту же архитектуру и аналогичные обучающие данные, что и для прогнозирования речных наводнений в Google Flood Hub. Она разработана для того, чтобы специалисты по гидрологии могли развивать достижения Google Research, добавляя и тестируя новые модели, данные и подходы. Она также позволяет оперативным синоптикам — людям, чья работа заключается в предоставлении действенных предупреждений о наводнениях для конкретных районов — интегрировать местные данные и знания в современные системы прогнозирования наводнений на основе ИИ.
Мы считаем, что научный прорыв достигает своего полного потенциала, когда он дает возможность другим воспроизводить и расширять полученные результаты, обеспечивая, чтобы инновации становились катализатором глобального прогресса. Именно поэтому мы разработали эту структуру внутри компании и протестировали ее с такими партнерами, как Чешский гидрометеорологический институт (CHMI). Выпуск нашей архитектуры модели и конвейера обучения представляет собой фундаментальный сдвиг в глобальной готовности к наводнениям, позволяя национальным метеорологическим и гидрологическим службам (НМГС), другим метеорологическим агентствам и властям сохранять полный контроль над своими данными, одновременно предоставляя местным экспертам возможность совершенствовать модели, используя специализированные наборы данных.
Как это работает
Наша гидрологическая модель представляет собой пакет Python, использующий пакет моделирования машинного обучения с открытым исходным кодом PyTorch для реализации модели прогнозирования речного стока, которая лежит в основе Google Flood Hub. Эти модели принимают на вход географические данные, связанные с климатом, почвами, топографией и растительным покровом, а также метеорологические прогнозы, касающиеся осадков, температуры и других погодных условий, для прогнозирования суточного расхода воды в реках по всему миру.
Пакет программного обеспечения для гидрологического моделирования включает в себя архитектуры моделей, основанные на сетях долговременной кратковременной памяти (LSTM), а также конвейер обучения, позволяющий обучать эти модели с использованием исторических данных о реках из открытого набора данных Caravan. Исследователи и агентства по прогнозированию наводнений могут добавлять свои собственные данные в это открытое хранилище данных для обучения или тонкой настройки моделей под свои местные водосборные бассейны.
Для начала работы над реализацией ознакомьтесь с этим интерактивным обучающим блокнотом на Python и соответствующим видеоуроком на YouTube по навигации по коду модели.
Улучшения модели
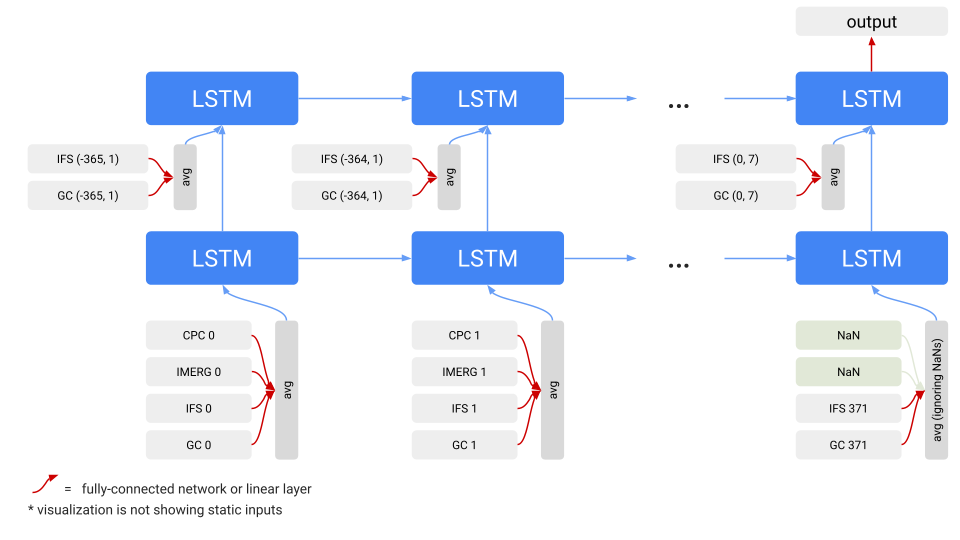
Этот репозиторий кода содержит две различные версии нашей гидрологической модели: оригинальную версию, протестированную в нашем сравнительном исследовании, опубликованном в 2024 году, и модернизированную модель, которая в настоящее время используется для прогнозирования глобальных наводнений в режиме реального времени на платформе Flood Hub. Новая модель основана на фундаментальном успехе наших первоначальных исследований и переходит к новой архитектуре модели. Эта структура позволяет нам обрабатывать разнообразные метеорологические данные из нескольких источников в единую систему прогнозирования наводнений, как показано на рисунке ниже. Наше недавнее сравнительное исследование показывает, что эта новая модель увеличивает надежный горизонт прогнозирования на шесть дней в бассейнах с измерительными станциями и на один день в бассейнах без измерительных станций по сравнению с предыдущей версией.

Модель v2 использует архитектуру ME-LSTM для обработки разрозненных метеорологических данных и преобразования их в единый прогноз паводков. Каждый метеорологический продукт обрабатывается отдельной сетью; эти выходные данные подаются в сеть LSTM, которая генерирует распределение вероятностей для речного стока. Временные шаги указываются с указанием прогноза и времени упреждения. Система интегрирует глобальные метеорологические продукты: Graphcast (GC); Европейский центр среднесрочных прогнозов погоды (IFS); спутниковые оценки осадков NASA (IMERG); CPC = ежедневные данные об осадках на основе показаний метеорологических станций NOAA .
От теории к практической реальности
В докладе «Глобальное состояние систем раннего предупреждения о множественных опасностях к 2025 году» Всемирная метеорологическая организация признает, что как локальные данные, так и знания коренных народов и местных жителей (ILK) являются важнейшими компонентами эффективных систем предупреждения о стихийных бедствиях, и отмечает, что «систематическая интеграция ILK в процесс формирования знаний о рисках по-прежнему является скорее исключением, чем правилом». Наш рабочий процесс прогнозирования наводнений с открытым исходным кодом решает проблему, описанную в докладе, позволяя региональным синоптикам напрямую управлять моделями прогнозирования на основе искусственного интеллекта. Эти системы относительно просты и недороги в обучении, обеспечивая точность без сложности традиционных гидрологических моделей прогнозирования и позволяя пользователям использовать собственные специализированные данные для обучения и прогнозирования.
Легко внедряемые инструменты с открытым исходным кодом имеют решающее значение для преодоления разрыва между технологическими инновациями и реальной эффективностью систем предупреждения о наводнениях, особенно для ускорения развития потенциала систем раннего предупреждения.
Наилучшим образом оперативный потенциал этой версии иллюстрирует наше партнерство с CHMI. Их сотрудничество сыграло ключевую роль в подтверждении того, что наша модель на основе ИИ обеспечивает прогнозы, сопоставимые по качеству с традиционными, локально откалиброванными концептуальными моделями. CHMI также разработала адаптер, который интегрирует открытую гидрологическую платформу в Delft-FEWS, популярный оперативный инструмент прогнозирования наводнений, используемый национальными и местными агентствами по прогнозированию наводнений, НПО и частными компаниями для создания прогностических моделей. Delft-FEWS управляется и поддерживается исследовательским институтом Deltares. Это позволяет CHMI и другим гидрологическим службам по всему миру использовать модель в своих стандартных рабочих процессах. Эта интеграция служит образцом того, как глобальные агентства могут включать машинное обучение в свои рабочие процессы управления водными ресурсами.
Помимо крупных организаций, таких как CHMI, выпуск модели с открытым исходным кодом предлагает масштабируемый и доступный инструмент, демократизирующий доступ к передовым методам прогнозирования и открывающий возможности для регионов с ограниченными ресурсами и местных команд использовать высококачественные аналитические данные без необходимости в дорогостоящей традиционной инфраструктуре прогнозирования.
Международное метеорологическое сообщество признало ценность такого подхода, основанного на открытой науке. Доктор Хвирин Ким, руководитель отдела гидрологического моделирования и прогнозирования Всемирной метеорологической организации, отмечает: «Я приветствую расширение использования инструментов гидрологического моделирования с открытым исходным кодом, которые имеют решающее значение для поддержки управления водными ресурсами и реагирования на экологические проблемы в обществе. Мы в ВМО стремимся поддерживать модели и инструменты с открытым исходным кодом, совместимые и разработанные членами организации, которые могут помочь спасти жизни и продвинуть глобальную миссию по обеспечению того, чтобы сообщества во всем мире были заблаговременно предупреждены об опасностях для защиты своей жизни и средств к существованию».
Единая рамочная программа действий по борьбе с изменением климата
Архитектура модели, подробная документация и учебные материалы теперь доступны на GitHub под лицензией Apache 2.0, что делает эту структуру полностью доступной как для исследователей, так и для специалистов по оперативному прогнозированию.
Предоставив нашу гидрологическую модель мировому сообществу гидрологов, мы можем построить мир, более устойчивый к наводнениям. Более подробная информация о более широких инициативах и ресурсах Google в области прогнозирования наводнений доступна на сайте Google Research. Мы приглашаем мировое сообщество гидрологов использовать эти открытые инструменты.
Благодарности
В разработке этого проекта участвовало множество людей. Особую благодарность мы хотели бы выразить Якубу Крейчи и Яну Данхелке из CHMI за их сотрудничество и отзывы, а также следующим сотрудникам Google Research и команды по социальному партнерству: Амиту Маркелю, Авинатану Хассидиму, Деборе Коэн, Эмили Рейнштейн, Гиле Лойке, Грей Ниринг, Нине Бекеле, Омри Шефи, Реувену Саягу, Рони Амире, Шмулику Фронману, Стефани Рис и Йосси Матиасу.
Источник: research.google
Оцените материал:

