PLC Smart Splitter: как ИИ помогает инженеру АСУ ТП не утонуть в технических заданиях
Если вы хоть раз программировали контроллер на реальном объекте, вы знаете этот ритуал. Перед вами лежит PDF на 180 страниц — «Техническое задание на разработку АСУ ТП». Рядом — Excel с IOLIST на 600 строк. Ваша задача, прежде чем написать первую строчку кода на ST или LAD, — разобраться, что куда относится: какие сигналы принадлежат вентиляции, какие — насосной станции, что за уставки у каждого узла, где аварии, где режимы. Это занимает полдня в лучшем случае, день — в среднем.
Именно эту боль закрывает PLC Smart Splitter — новый инструмент от российской студии plcstudio, опубликованный в открытом доступе на GitVerse и GitHub.

Что это такое и зачем
PLC Smart Splitter — это локальное Windows-приложение, которое принимает на вход два файла: текст технического задания и таблицу сигналов (IOLIST), а на выходе отдаёт структурированные блоки ТЗ по каждой подсистеме.
Звучит просто, но дьявол в деталях. Реальные ТЗ не имеют единого стандарта оформления. Один заказчик пишет ТЗ в Word с нумерованными заголовками, другой — в виде сплошного текста с абзацами, третий отдаёт отсканированный PDF 2003 года. То же самое с IOLIST: у одного предприятия колонки называются Tag, Description, SubSystem, у другого — Адрес, Наименование, Узел, у третьего нет заголовков вообще, и подсистема кодируется в самом теге через разделитель.
Программа умеет работать с этим зоопарком. Давайте разберём как.
Архитектура решения
Под капотом — Python + Flask + pandas, упакованные в один .exe через PyInstaller. При запуске поднимается локальный веб-сервер на 127.0.0.1:8053, интерфейс открывается в браузере. Это грамотное решение: не нужна установка, всё в одном файле, интерфейс привычный, данные не покидают машину.
Для генерации текста ТЗ используется DeepSeek API — нужен собственный ключ с аккаунтом на platform.deepseek.com. Если ключа нет, предусмотрен режим «Промпт чата»: программа формирует готовое сообщение, которое можно скопировать и вставить в веб-интерфейс ChatGPT, Claude или DeepSeek вручную.
Весь процесс из четырёх шагов отражён прямо в интерфейсе как четыре кнопки в левой панели:
1. Профилировать таблицу → 2. Нарезать ТЗ → 3. Разбить на подсистемы → 4. ТЗ для всех
Рассмотрим каждый.
Шаг 1. Профилирование таблицы сигналов
Это, пожалуй, самая нетривиальная часть продукта. Программа не полагается на названия колонок — она анализирует содержимое каждой колонки и по статистике значений определяет её роль:
-
Тег — высокая доля уникальных значений, короткие строки, часто содержат спецсимволы и цифры в определённых позициях (AI_101, FCV-23.4, GS_PUMP_01).
-
Описание — длинные строки, почти уникальные, кириллица или смешанный текст.
-
Тип сигнала — очень ограниченный словарь значений (DI, DO, AI, AO, AO_4-20, и т.п.).
-
Подсистема — ограниченный словарь, часто повторяющиеся группы.
После профилирования программа показывает разметку с указанием уверенности (confidence) по каждой колонке и числом найденных «якорей» подсистем.
Если автоматика ошиблась — есть блок «Обучение ИИ»: вы показываете 3–7 примеров «тег → подсистема», и классификация пересчитывается.
Шаг 2. Нарезка технического задания
Текст ТЗ разбивается на смысловые блоки по иерархии заголовков с сохранением полного пути: Раздел → Подраздел → Пункт. Для каждого блока подсчитывается количество токенов — это нужно для того, чтобы при формировании промпта не выходить за лимит контекста модели.
Поддерживаемые форматы ТЗ: .txt, .md, .html. PDF и DOCX нужно предварительно конвертировать в текст — это единственное ограничение, которое немного снижает удобство при работе с «тяжёлыми» документами от заказчиков.
Шаг 3. Группировка по подсистемам
Алгоритм находит «якорные» строки в таблице сигналов — строки, которые явно задают границу подсистемы — и приписывает каждый сигнал к своей группе. Затем для каждой подсистемы подбираются релевантные фрагменты из нарезанного ТЗ.
Это критически важный момент: модель не получает весь документ целиком. Она получает только те блоки ТЗ, которые семантически относятся к данной подсистеме. Это снижает «галлюцинации», уменьшает расход токенов и повышает качество.
Перед финальной генерацией доступен предпросмотр (3b. Предпросмотр подсистем) — можно убедиться, что сигналы сгруппировались правильно, прежде чем запускать дорогой батч-запрос к API.
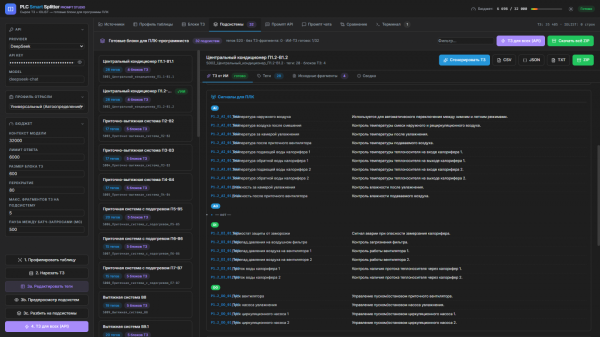
Шаг 4. Генерация структурированного ТЗ
Это финальный шаг. Для каждой подсистемы модель генерирует полное структурированное ТЗ в строгом JSON-формате. Структура зафиксирована промптом и включает:
-
Назначение подсистемы
-
Перечень оборудования
-
Описание сигналов AI / AO / DI / DO с тегами и описаниями
-
Режимы работы (ручной / автоматический / аварийный и т.д.)
-
Пошаговый алгоритм управления
-
Уставки и параметры
-
Аварии и события
-
Взаимодействия с другими подсистемами
Промпт поддерживает плейсхолдеры ({{name}}, {{tags}}, {{tz_fragments}}, {{tag_count}} и др.) и полностью редактируется опытными пользователями — можно подстраивать стиль и структуру под стандарты своей организации.
Контроль качества и антигаллюцинационные правила
Отдельного внимания заслуживает вкладка «Сравнение». Сценарий: вы сгенерировали ТЗ через API, но хотите проверить, не «выдумала» ли модель данные. Вставляете рядом ответ, полученный вручную через веб-чат, — программа сравнивает два JSON секция за секцией и подсвечивает расхождения.
В самом промпте прямо запрещено выдумывать уставки и режимы, которых нет в исходных документах. Если модели не хватило данных из ТЗ — она явно указывает, что информации недостаточно, а не заполняет пробел правдоподобной выдумкой.
Режим без API-ключа
Инженеры на объектах часто работают без стабильного интернета или без корпоративного разрешения подключать рабочие документы к внешним сервисам. Для этого предусмотрен режим «Промпт чата»: программа формирует полный промпт с контекстом по одной подсистеме и предлагает скопировать его в буфер обмена. Дальше — открываете ChatGPT или Claude в браузере, вставляете, получаете JSON-ответ и возвращаете его обратно во вкладку «Сравнение».
Не самый автоматичный режим, но для единичных подсистем или при работе на закрытом контуре — вполне рабочий.
Лицензирование
Программа работает по схеме «пробный период → постоянная лицензия». Первые 5 дней все функции доступны бесплатно. Далее — покупка лицензии через электронную почту support@plcstudio.ru. Активация привязана к Hardware ID компьютера, лицензия на одну машину.
Если меняете компьютер или переставляете Windows — достаточно написать с новым Hardware ID, перенос для легальных пользователей бесплатный.
Цена публично не указана — нужно запрашивать у разработчика.
Стек и системные требования
|
Параметр |
Значение |
|---|---|
|
ОС |
Windows 10 / 11 (64-бит) |
|
Установка |
Не требуется, один .exe |
|
Бэкенд |
Python + Flask + pandas |
|
ИИ-провайдер |
DeepSeek API (ключ пользователя) |
|
Интерфейс |
Локальное веб-приложение (127.0.0.1:8053) |
|
Форматы ТЗ |
.txt, .md, .html |
|
Форматы IOLIST |
.xlsx, .xls, .csv |
|
Форматы экспорта |
.csv, .json, .txt, .zip |
Что получается на выходе
Практический результат работы программы выглядит примерно так. Исходный IOLIST на 600 сигналов и ТЗ на 150 страниц → за 5–10 минут (в зависимости от числа подсистем и скорости DeepSeek API) → ZIP-архив, в котором для каждой подсистемы лежит отдельный структурированный файл с полным ТЗ для программиста.
Программист открывает файл по своей подсистеме и видит ровно то, что ему нужно: список сигналов, алгоритм, уставки, аварии. Не 180-страничный PDF, из которого нужно выловить нужные три страницы.
Кому это нужно
Продукт нишевый, но попадает точно в аудиторию:
-
Инженеры-программисты ПЛК, работающие на объектах без собственного отдела разработки — небольшие интеграторы, фриланс.
-
Небольшие компании-интеграторы АСУ ТП, где один инженер ведёт несколько проектов одновременно.
-
Технические руководители, которым нужно быстро разложить ТЗ по исполнителям-программистам.
Для крупных проектных организаций с выстроенными процессами ценность меньше — там обычно есть специализированные инженеры-постановщики задачи. Но для рынка небольших интеграторов, где один человек и ТЗ читает, и код пишет — инструмент закрывает реальную боль.
Выводы
PLC Smart Splitter — редкий пример ИИ-инструмента, заточенного под специфику промышленной автоматизации, а не очередной «AI-помощник для всего». Разработчики не пытаются заменить инженера — они автоматизируют конкретную, хорошо описанную рутину, которую все ненавидят.
Технически решение не самое сложное (Python + Flask, внешний LLM-провайдер), но инженерная мысль в алгоритме профилирования таблицы и семантической нарезки ТЗ заслуживает уважения. Именно эти части — не вызов к LLM, а собственная логика — делают продукт надёжным на «грязных» реальных данных.
Из пожеланий: было бы здорово видеть поддержку PDF и DOCX напрямую (без ручной конвертации), возможность выбора альтернативных LLM-провайдеров (например, Ollama для полностью офлайн-работы на закрытых объектах), и прозрачное ценообразование на сайте.
Ссылки:
-
GitHub: github.com/ura-ch/PLC_Smart_Splitter
-
GitVerse: gitverse.ru/plcstudio/PLC_Smart_Splitter
-
Видеообзор:
Если вы работаете в сфере АСУ ТП и пробовали подобные инструменты — расскажите в комментариях, как решаете задачу декомпозиции ТЗ сейчас. Интересно, насколько широко распространена эта боль и есть ли у коллег собственные скрипты или подходы.
Источник: habr.com
Оцените материал:


