Обеспечение надежных ответов с помощью Agentic RAG от Gemini Enterprise Agent Platform
Представляем нашу новую агентную RAG-платформу. Разработанная в результате сотрудничества Google Research и Google Cloud, наша многоагентная рабочая среда выходит за рамки стандартного RAG, разбивая сложные корпоративные запросы на части и итеративно ища достаточный контекст перед генерацией надежных ответов.
Быстрые ссылки
- Поиск информации в разных корпусах с помощью RAG Engine
- Делиться
Современные одношаговые системы поиска с расширенным поиском (RAG) не были разработаны для многоисточниковых запросов, характерных для современных бизнес-процессов. Например, если запрос звучит так: «Каковы характеристики сервера, используемого в проекте X?», система может найти документы о проекте X, но в этих документах может упоминаться только идентификатор сервера. Она не будет знать, что нужно использовать этот идентификатор для выполнения второго поиска в другой базе данных, чтобы найти характеристики. В результате получается частичный ответ или сообщение «не найдено», поскольку информация разбросана по разным «островкам» данных, что требует более глубокого исследования для поиска фактов.
Представляем «агентный RAG», который планирует, анализирует и итеративно взаимодействует с источниками данных, позволяя обрабатывать сложные запросы для повышения надежности и точности.
Сегодня мы рады представить версию Cross-Corpus Retrieval на базе Agentic RAG, размещенную на платформе Google Gemini Enterprise Agent Platform. Как и другие многоагентные RAG-фреймворки, наш использует различных агентов, которые работают вместе для надежного ответа на сложные запросы. В отличие от других многоагентных фреймворков, наш включает в себя достаточный контекст, чтобы подтвердить наличие информации для точного ответа. По сравнению со стандартным RAG, наш фреймворк повышает точность на наборах данных, содержащих фактическую информацию, до 34%. Мы также оценили нашу систему на собственных внутренних наборах данных и обнаружили, что достигаем лучшей обоснованности и улучшенной точности рассуждений в нескольких предметно-ориентированных задачах.
Как работают многоагентные архитектуры: планирование, переписывание и маршрутизация.
Полезно рассматривать многоагентную систему RAG не как единую поисковую систему, а как организованный исследовательский отдел. В «монолитной» или «стандартной» системе RAG компонент поиска просто рассматривает ваш запрос и пытается найти соответствующие документы, прежде чем модуль LLM сгенерирует ответ.
В многоагентной среде система разбивает задачу на специализированные роли:
- Оркестратор оценивает ваш сложный запрос и решает: «Это не задача на один шаг», после чего делегирует работу агентам.
- Агент-планировщик составляет карту информационных каналов. Например, если вы спрашиваете о бюджете проекта и сроках его реализации, агент-планировщик принимает решение: «Сначала нам нужно проверить финансовую базу данных, затем — журналы управления проектом».
- Функция перефразирования запросов преобразует ваш запрос в несколько поисковых запросов. Она превращает запрос «Что происходит с проектом X?» в «Отчет о состоянии проекта X, 3 квартал» и «Ключевые проблемы для команды проекта X».
- Агент распространения поисковых запросов берет эти уточненные запросы и отправляет их в различные источники для сбора фрагментов информации.
- Наконец, LLM объединяет весь контекст для выдачи окончательного ответа.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Демонстрация стандартной агентной системы RAG. Хотя она включает в себя несколько агентов, она не предусматривает итеративного поиска или специализированной поддержки работы с различными корпусами данных.
Чем наша агентная группа RAG отличается от других?
Ключевое отличие нашей новой агентной RAG-системы заключается в устойчивости . По сравнению с другими RAG-решениями, наша система эффективна, потому что она знает, когда ей не хватает информации, и продолжает поиск до тех пор, пока контекст не будет полным. Это предотвращает «угадывание» ИИ, когда первый поиск не дает результатов, или простое сообщение: «У меня недостаточно информации». Хотя в некоторых случаях это уместный ответ, иногда информация есть, и нам просто нужно ее найти.
Например, представьте, что врач спрашивает пациента о принимаемых им лекарствах, диете и аллергиях:
«Какие лекарства и диетические ограничения были назначены Джону Доу после операции на колене, и были ли у него какие-либо аллергические реакции во время пребывания в больнице? Не включайте лекарства, которые применялись только во время пребывания в стационаре или в отделении неотложной помощи, за исключением внутривенного введения гепарина или тенектеплазы».
В ответ на это наша система запускает множество специализированных агентов. Общий обзор нашего решения представлен на рисунке ниже, а затем мы опишем его более подробно.
На иллюстрации представлено наше многоагентное решение RAG, включающее агента, обеспечивающего достаточный контекст, а также возможность итеративного получения дополнительной информации перед ответом на запрос.
Этап 1: Оркестрация
Основной агент анализирует запрос врача и делегирует задачи субагентам. Агент-планировщик определяет, что ему необходимо проверить три отдельные области: аптека, питание и клинические заметки. Переформулировщик запросов разбивает длинный запрос на простые, удобные для поиска вопросы, чтобы средство поиска могло более точно находить релевантный контент.
Этап 2: Поиск (стандартный шаг)
Система RAG Agent одновременно выполняет поиск по всем параметрам запроса в медицинской карте пациента. Она находит информацию о лекарствах и диете, но не может найти упоминания об аллергиях в наиболее очевидных файлах. В стандартной или «ванильной» системе RAG процесс мог бы на этом закончиться неполным ответом.
Этап 3: Агент, обеспечивающий достаточный контекст (новая исследовательская инновация)
Представьте себе Агента достаточного контекста как инспектора контроля качества, стоящего в конце конвейера. Он анализирует три конкретных момента, прежде чем разрешить генерацию ответа:
1. Полученные фрагменты
Агент достаточного контекста оценивает фактические фрагменты текста, извлеченные из базы данных агентом RAG. В примере с врачом это могут быть конкретные абзацы из разделов «Выписной эпикриз» и «Примечания по питанию». Он читает их, чтобы определить, содержится ли в этих предложениях информация, необходимая для ответа на запрос.
2. Промежуточный проект
Система также создает черновой вариант ответа. Затем агент обеспечения достаточного контекста анализирует запрос, черновой вариант и полученные фрагменты текста, чтобы оценить, обладает ли модель всем необходимым для предоставления исчерпывающего и обоснованного ответа. Если запрос содержит информацию о трех вещах (лекарства, диета, аллергии), а фрагменты текста содержат информацию только о двух, агент обеспечения достаточного контекста помечает его как «недостаточный контекст».
3. Анализ недостающих элементов
Это самая важная часть. Агент обеспечения достаточного контекста точно определяет, чего не хватает. Он не просто выдает сообщение «этого недостаточно»; он генерирует конкретный журнал «Причина» и «Обратная связь». Например:
Вывод: «У нас есть список лекарств и инструкции по низкосолевой диете».
Недостаток: «В исходных документах отсутствует информация об аллергических реакциях или нежелательных явлениях во время пребывания».
Агент обеспечения достаточного контекста сравнивает найденную информацию с исходным запросом и спрашивает: «Ответили ли мы на вопрос об аллергии?» Если нет, он выдает сигнал «Недостаточный контекст» и предоставляет конкретную обратную связь: «Вы нашли информацию о лекарствах и диете, но пропустили информацию об аллергии. Вернитесь и выполните поиск по запросам, содержащим слова «сыпь» или «побочные эффекты»». В ситуации с несколькими источниками он также может запросить дополнительную информацию или решить, что источник не имеет отношения к запросу.
Этап 4: Итерация
Благодаря обратной связи от агента Sufficient Context Agent, механизм переписывания запросов создает новый поиск по запросу «rashes». Затем агент RAG углубляется в файлы, которые он игнорировал в первый раз, и находит недостающую информацию.
Этап 5: Синтез (окончательный ответ)
Агент достаточного контекста проверяет данные в последний раз. Теперь, когда у него есть информация о лекарствах, диете и аллергиях, он решает, что поиск можно прекратить. Наконец, агент синтеза составляет четкое и точное резюме для врача.
Эксперименты и результаты
Мы оценили агентный RAG на платформе FramesQA, основанной на статье FRAMES. Пример многошагового вопроса:
«Из двух самых просматриваемых финальных серий телевизионных сезонов (по состоянию на июнь 2024 года), какая из них была длиннее по продолжительности и насколько?»
Для получения правильного ответа системе RAG необходимо выполнить несколько шагов. Во-первых, она должна определить, что два самых просматриваемых финала принадлежат сериалам «M*A*S*H» и «Cheers». Затем она должна найти их продолжительность и вычислить разницу в длине. Во многих сценариях RAG (стандартный RAG или агентный RAG без достаточного контекста) мы можем оказаться в ситуации, когда модель выдаст что-то вроде:
«Несмотря на многочисленные проверки, я не нашел точной информации о продолжительности сериалов M*A*S*H или Cheers. В документах приводятся данные о количестве просмотров, но не указывается продолжительность в минутах или часах».
Это не отвечает на вопрос.
К счастью, наш агент RAG может решить эту проблему, сначала выполнив поиск телешоу, а затем используя функцию переписывания запросов и агент достаточного контекста для целевого поиска по продолжительности сериалов M*A*S*H или Cheers. После этого Gemini легко сможет определить, какой финал длился дольше всего и насколько:
«Финал сериала M*A*S*H длился 150 минут, что сделало его самым длинным из двух предыдущих. Он был на 52 минуты длиннее финала сериала Cheers, который длился примерно 98 минут».
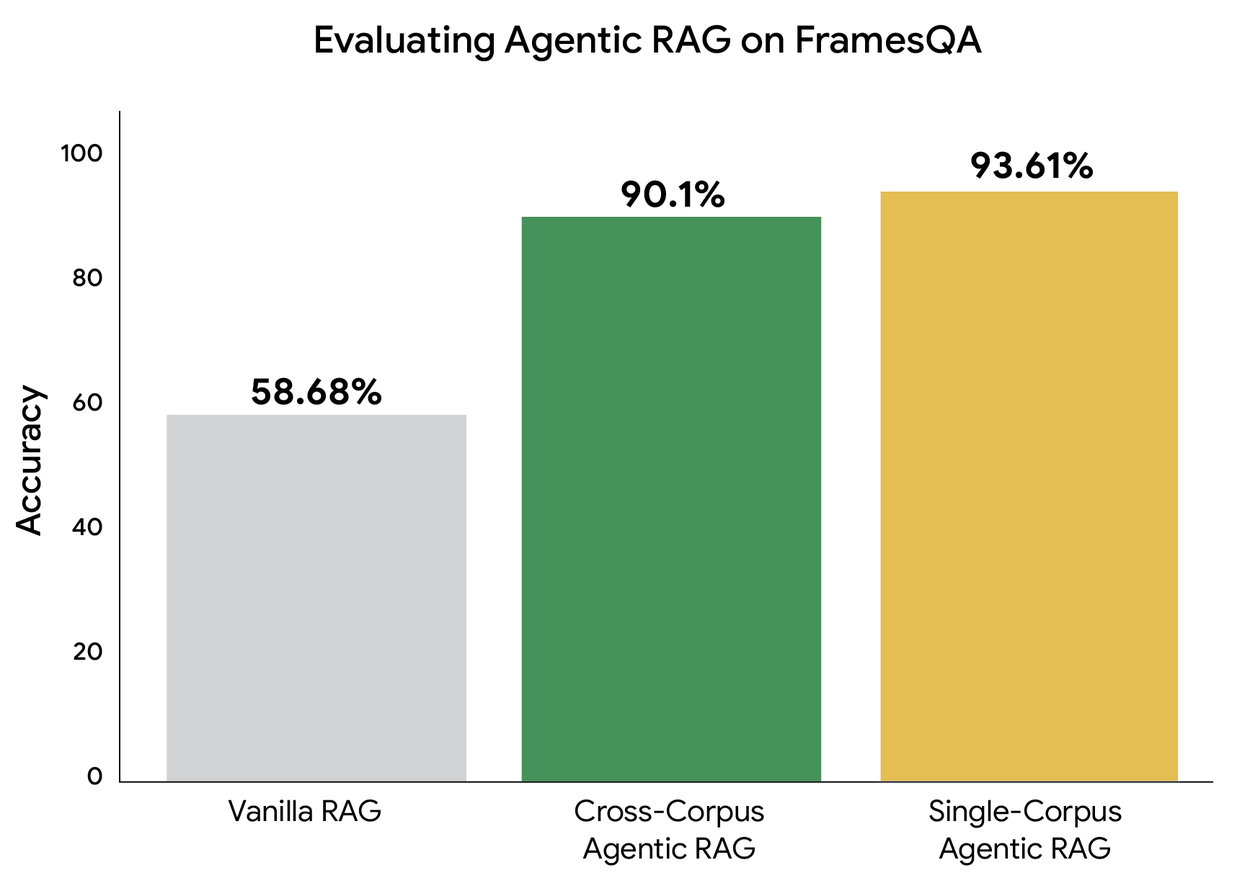
Мы провели эксперимент для проверки этой возможности в масштабе (FramesQA содержит 824 запроса, а также корпус, включающий 2676 PDF-документов). В «стандартной» настройке RAG мы использовали движок RAG от Google (который имеет расширенный механизм поиска, парсер LLM и механизм переранжирования). Мы сравнили его с нашим агентным RAG в двух вариантах. В варианте с одним корпусом мы осуществляли поиск из документов FramesQA. В варианте с несколькими корпусами мы также включили три других отвлекающих набора данных, где агент-планировщик должен определить, откуда осуществлять поиск. Этот вариант с несколькими корпусами имитирует сценарии использования, когда в компаниях базы данных управляются отдельными командами. Мы вычисляем точность, используя LLM в качестве судьи для сравнения ответов системы с истинными ответами в наборе данных.
В условиях обработки данных из разных корпусов наша система практически не уступает по точности системам, использующим один корпус. Даже когда агенту-планировщику необходимо выбрать правильный корпус из 4 возможных, мы успешно перенаправляем поисковые запросы и правильно отвечаем на 90,1% вопросов. Кроме того, задержка как в версиях для одного корпуса, так и в версиях для разных корпусов примерно одинакова (в среднем в пределах 3%). Это демонстрирует, что наша система Agentic RAG способна обрабатывать несколько несвязанных источников данных, что открывает возможности для более гибких сценариев поиска.

Сравнение результатов поиска по нескольким корпусам с поиском по одному корпусу и с использованием стандартного алгоритма RAG на платформе FramesQA демонстрирует высокую точность наших агентных решений.
Заключение
Благодаря сочетанию расширенного планирования запросов, маршрутизации и достаточного контекста, наша агентная система RAG гарантирует, что ответы, генерируемые ИИ, являются проверяемыми, отслеживаемыми и обоснованными. Мы с нетерпением ждем, как сообщество машинного обучения будет использовать эти новые агентные возможности для создания следующего поколения надежных систем ИИ. Эта новая функция теперь доступна в качестве публичной предварительной версии в Gemini Enterprise Agent Platform.
Благодарности
Этот проект — совместная работа с Бо Ли, Чжунцзе Мао, Тайгером Цзинем, Юхонгом Каном, Мохдом Абдуллой (Обито), Чун-Сун Фернгом, Пуне Мортазави, Роджером (Пэном) Ю, Эраном Льюисом и Иваном Кузнецовым. Мы благодарим Кимберли Шведе за разработку графики и Марка Симборга за помощь в написании текста. Мы также благодарим наших ключевых корпоративных партнеров за важные отзывы пользователей, данные и ценные выводы.
Источник: research.google
Оцените материал:
