Обучение на основе парных предпочтений: Введение в модель Брэдли-Терри
Как превратить простые сравнения «один на один» в вероятностные рейтинги
Делиться

В статистическом обучении часто предполагается наличие абсолютных меток. Например, экземпляр принадлежит к классу, документ получает оценку, наблюдению присваивается вероятность, продукт оценивается по фиксированной шкале. Однако на практике человеческое суждение часто принимает более локальную и сравнительную форму. Люди могут не знать, заслуживает ли ответ 7,4 из 10, но они часто могут сказать, какой из двух ответов лучше. Они могут колебаться, прежде чем присвоить кандидату абсолютную оценку качества, но они могут сказать, какой из двух кандидатов кажется более сильным. Во многих реальных системах сравнение намного проще, чем калибровка.
В таких условиях модель Брэдли-Терри оказывается особенно полезной, предлагая математически чистый способ обучения на основе парных предпочтений. Вместо того чтобы требовать абсолютных оценок, она исходит из простых результатов прямого противостояния и использует их для вывода скрытого порядка элементов, что позволяет получить согласованное вероятностное ранжирование.
Основная идея: каждый предмет обладает скрытой силой.
Модель начинается с простого предположения. Каждому элементу i соответствует ненаблюдаемый положительный параметр силы, обозначаемый как πᵢ > 0. При сравнении элемента i с элементом j вероятность того, что i предпочтительнее j, определяется следующим образом:
и симметрично мы можем записать:
Эта форма весьма привлекательна, поскольку она одновременно проста и понятна. Если два элемента обладают одинаковой силой, то вероятность выигрыша каждого из них составляет 1/2. Если πᵢ значительно больше πⱼ, то вероятность выигрыша i значительно возрастает. Модель Брэдли-Тери преобразует скрытые относительные силы в наблюдаемые парные вероятности.
Второй, и зачастую более удобный способ записать ту же модель, — выразить каждое положительное значение как экспоненту вещественного показателя:
Подставив это в выражение для вероятности, получим:
что также можно записать следующим образом:
Это позволяет увидеть важный факт. Вероятность того, что i победит j, зависит только от разницы βᵢ − βⱼ. Таким образом, модель Брэдли-Терри тесно связана с логистическим моделированием. Это та же структурная идея, которая встречается в логистической регрессии. В логистической регрессии бинарный результат моделируется путем применения логистической функции к линейной оценке. В модели Брэдли-Терри бинарный результат является следствием прямого сравнения, а соответствующая оценка представляет собой просто разницу между двумя скрытыми показателями силы. Эквивалентно, логарифм отношения шансов того, что i победит j, линейно зависит от βᵢ − βⱼ, что делает модель Брэдли-Терри особенно естественной для парных данных о предпочтениях.
В частности, важен не абсолютный уровень оценки элемента, а его положение относительно другого элемента в сравнении.
Простой пример
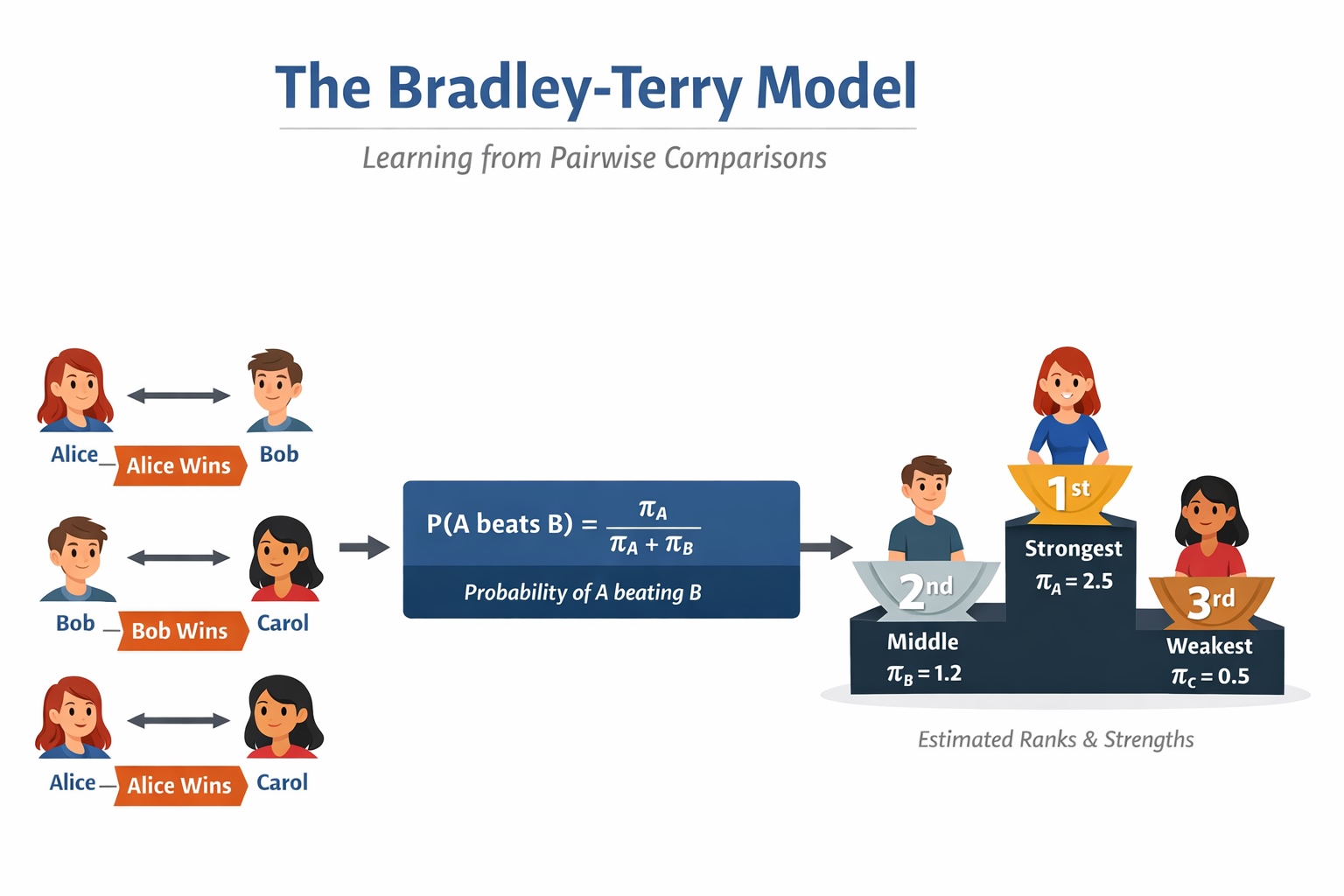
Рассмотрим три варианта ответа, сгенерированные языковой моделью: A, B и C. Предположим, что специалисты по разметке текста выдают следующие предпочтения:
- А предпочтительнее В
- Предпочтение отдается варианту А, а не варианту С.
- Вариант B предпочтительнее варианта C.
Даже без числовых оценок структура уже видна. А кажется самым сильным, В — следующим, а С — самым слабым. Модель Брэдли-Терри формализует эту интуицию, выявляя скрытые сильные стороны, которые делают наблюдаемые результаты правдоподобными в рамках модели.
Это первый концептуальный шаг, заслуживающий внимания. Модель не начинает с глобальных оценок, а затем выводит попарные результаты. Она делает обратное. Она начинает с локальных сравнений и выводит скрытые оценки, которые наилучшим образом их объясняют.
Подгонка модели на основе данных
Теперь предположим, что сравнения повторяются много раз для большего набора элементов. Для каждой упорядоченной пары (i, j) пусть wᵢⱼ обозначает количество раз, когда элемент i превосходит элемент j, а wⱼᵢ обозначает количество раз, когда j превосходит i.
Модель Брэдли-Терри подбирает параметры, выбирая значения силы, которые делают наблюдаемые данные сравнения максимально вероятными. Это делается с помощью метода максимального правдоподобия.
Для одной пары элементов i и j вклад вероятности составляет:
Интерпретация проста. Если элемент i многократно превосходил элемент j, то подобранная модель должна присвоить высокую вероятность тому, что i превзошёл j. Если j также выиграл несколько сравнений, то модель должна это учесть. Вероятность вознаграждает настройки параметров, которые придают высокую вероятность результатам, которые фактически наблюдались.
Полная вероятность для всех пар элементов получается путем перемножения этих членов. На практике же используется логарифмическая функция правдоподобия, поскольку ее проще оптимизировать. Логарифмическая функция правдоподобия выглядит следующим образом:
Задача подгонки состоит в том, чтобы найти значения параметров, которые максимизируют эту величину.
Более подробный анализ подгонки по модели Брэдли-Терри.
На интуитивном уровне процесс оптимизации корректирует скрытые значения таким образом, чтобы прогнозируемые моделью вероятности соответствовали результатам эмпирического сравнения.
Если какой-либо элемент часто побеждает, его сила должна возрастать. Если он часто проигрывает, его сила должна падать. Если два элемента примерно поровну делят победы в своих поединках, их силы должны сближаться. Это неформальные следствия. Технический механизм, лежащий в их основе, — это градиент логарифмической функции правдоподобия.
Используя параметризацию πᵢ = exp(βᵢ), градиент по βᵢ можно записать следующим образом:
Это выражение является центральным сигналом обучения в модели Брэдли-Терри и имеет очень понятную интерпретацию.
- Первый член, wᵢⱼ, — это количество побед, которые элемент i фактически одержал над элементом j.
- Второй член, (wᵢⱼ + wⱼᵢ) P(i ≻ j), — это количество побед, которое, по прогнозам текущей модели, должен одержать элемент i над элементом j.
Таким образом, градиент измеряет расхождение между двумя величинами: наблюдаемыми победами и ожидаемыми победами.
Метод градиентного спуска корректирует скрытую силу следующим образом:
- Если элемент i выигрывает чаще, чем предсказывает текущая модель, то градиент положителен, и βᵢ должно увеличиваться.
- Если элемент i выигрывает реже, чем прогнозировалось, то градиент отрицательный, и βᵢ должно уменьшаться.
Обучение происходит путем многократной коррекции этих расхождений до тех пор, пока ожидаемые результаты модели не будут максимально приближены к наблюдаемым данным. Это наиболее полезный способ осмысления процесса подгонки по Брэдли-Терри. Обучение заключается в корректировке скрытых значений до тех пор, пока ожидаемое парное поведение не совпадет с эмпирическим парным поведением.
Однако в модели Брэдли-Терри есть один важный нюанс. Модель не определяет абсолютную шкалу качества. Важны только относительные значения. Если каждый параметр качества умножить на одну и ту же положительную константу c, парные вероятности не изменятся:
Это означает, что модель обучается относительной структуре ранжирования, а не абсолютному значению в какой-либо внешней единице. На практике обычно масштаб фиксируют, применяя нормализацию, например, устанавливая одно из значений β равным нулю или ограничивая сумму параметров константой.
От локальных судебных решений к глобальной структуре
Более глубокая привлекательность модели Брэдли-Терри заключается в том, как она преобразует множество локальных оценок в единое глобальное представление. Каждое отдельное сравнение само по себе говорит очень мало. Оно лишь указывает на то, что в одном прямом противостоянии один предмет был предпочтительнее другого. Однако, когда эти локальные наблюдения агрегируются по всему набору данных, начинает вырисовываться более широкая структура. Модель восстанавливает эту структуру в виде скрытых сильных сторон и парных вероятностей.
Именно поэтому модель Брэдли-Терри остается такой полезной, но, возможно, менее известной в инструментарии специалистов по анализу данных. Она предлагает принципиальный мост между зашумленными сравнительными оценками и глобальным вероятностным ранжированием. Она учитывает тот факт, что человеческий контроль зачастую проще получить в относительной, а не абсолютной форме, и преобразует эти относительные данные в нечто математически поддающееся анализу.
Естественно возникает следующий вопрос: почему попарные сравнения зачастую оказываются более стабильными и надежными, чем прямая оценка? Именно здесь практическая привлекательность сравнительного управления становится еще более очевидной.
Почему попарные сравнения часто лучше, чем прямые оценки
Одно из главных практических преимуществ подхода Брэдли-Терри заключается в том, что парные оценки часто легче даются людям, чем абсолютные. Отчасти это связано с когнитивной нагрузкой. Чтобы определить, лучше ли ответ А, чем ответ В, требуется локальное сравнение. Чтобы определить, заслуживает ли ответ А оценки 7,8 из 10, необходим внутренний стандарт, калибровка по предыдущим примерам и устойчивая интерпретация того, что должна представлять собой числовая шкала. Во многих областях люди гораздо лучше справляются с первым, чем со вторым.
Эта разница важна, потому что шум, возникающий при оценке, бывает разным. Прямые оценки часто страдают от непоследовательности шкалы. Один аннотатор может использовать весь диапазон от 1 до 10, в то время как другой сжимает почти все оценки в интервал от 6 до 8. Один рецензент может считать 5 средним результатом, другой — плохим. Даже один и тот же человек может выставлять более строгие оценки утром, чем днем. Проблема заключается не просто в разногласиях по поводу качества. Она заключается в разногласиях по поводу смысла самой шкалы.
Попарные сравнения позволяют избежать многих из этих трудностей. Они не требуют от аннотатора привязки суждения к глобальной числовой системе координат. Они требуют лишь относительного решения: какой из этих двух вариантов лучше? Это более простой и часто более стабильный вопрос. В результате сравнительные оценки часто менее подвержены влиянию шума, их легче собирать последовательно и они более надежны для разных аннотаторов.
Существует также структурная причина привлекательности парных данных. Во многих реальных системах истинная конечная цель — ранжирование. Поисковой системе необходимо упорядочивать результаты. Рекомендательной системе необходимо размещать лучшие элементы выше худших. Модели вознаграждения для генерации языка должны различать предпочтительные результаты от менее предпочтительных. В этих условиях абсолютные оценки могут быть ненужной промежуточной абстракцией. Парное обучение с учителем ближе к задаче принятия решений, которую система в конечном итоге пытается решить.
Это не означает, что попарные оценки лишены трудностей. Они могут быть дорогостоящими, когда количество элементов очень велико, и могут содержать циклы или несоответствия. Один аннотатор может предпочитать A, а не B, B, а не C, и в то же время C, а не A. Разные аннотаторы могут резко расходиться во мнениях. Тем не менее, попарное обучение с учителем часто остается привлекательным, поскольку оно смещает задачу с требования от людей предоставить идеально откалиброванные оценки на задачу от модели вывести скрытую структуру из локальных сравнительных данных.
Именно для этого и предназначен алгоритм Брэдли-Терри. Он берет набор небольших, возможно, зашумленных, результатов прямых сравнений и строит глобальный вероятностный рейтинг, который наилучшим образом их объясняет. Ценность модели заключается не в том, что парные оценки идеальны, а в том, что они часто являются наиболее естественным и надежным доступным сигналом.
Углублённый анализ: идентифицируемость, кривизна и оптимизация.
Базовую модель Брэдли-Терри легко сформулировать, но ее техническая структура становится более интересной, если задаться вопросом, как именно оцениваются параметры и при каких условиях эта оценка является корректной.
Идентифицируемость
Первая проблема — идентифицируемость. При параметризации с использованием положительных значений πᵢ вероятности остаются неизменными, если каждый параметр умножается на одну и ту же положительную константу. Причина проста:
Зависит только от соотношения сил, а не от их общей шкалы. Если каждое πᵢ заменить на cπᵢ для некоторого c > 0, вероятности останутся точно такими же.
Та же проблема возникает и при параметризации логарифмической силы πᵢ = exp(βᵢ). Добавление одной и той же константы к каждому βᵢ оставляет все попарные вероятности неизменными, поскольку имеют значение только такие различия, как βᵢ − βⱼ. Следовательно, модель имеет одну избыточную степень свободы.
На практике это решается путем наложения нормализации. Наиболее распространенные варианты включают:
или
Эти ограничения не изменяют подобранные вероятности. Они просто фиксируют базовый уровень, благодаря чему решение становится единственным.
Существует также графотеоретический аспект идентифицируемости. Если граф сравнения несвязен, то относительная сила элементов в различных связных компонентах не может быть определена на основе данных. В более общем смысле, для оценки осмысленного глобального рейтинга наблюдаемые сравнения должны достаточно хорошо связывать элементы. В противном случае данные идентифицируют только отдельные локальные рейтинги внутри изолированных подмножеств.
Логарифмическая вероятность снова
Вспомним логарифмическую функцию правдоподобия:
Это целевая функция, которую мы максимизируем. Её градиент относительно βᵢ равен:
Как обсуждалось ранее, это разница между наблюдаемыми и ожидаемыми победами. Это придает градиенту особенно привлекательную интерпретацию. Модель увеличивает оценку элемента, когда он выигрывает чаще, чем прогнозировалось, и уменьшает ее, когда элемент выигрывает реже, чем прогнозировалось.
В оптимальном случае эти расхождения максимально компенсируются по всей сети сравнения.
Гессиан и кривизна
Для понимания геометрии задачи оптимизации полезно рассмотреть вторые производные. Для логарифмической функции правдоподобия Брэдли-Терри диагональная вторая производная принимает следующий вид:
А для i ≠ j недиагональная вторая производная равна:
При сравнении элементов i и j, в противном случае — 0. Из этой структуры следует несколько выводов:
- Во-первых , матрица Гессе является отрицательно полуопределенной, что означает, что логарифмическая функция правдоподобия вогнута по β с учетом уже обсуждавшейся проблемы идентифицируемости. Это важное свойство. Оно подразумевает, что после устранения неопределенности масштаба задача оптимизации имеет хорошо управляемый глобальный оптимум, а не множество несвязанных локальных максимумов.
- Во-вторых , кривизна зависит от члена P(i ≻ j) P(j ≻ i). Эта величина максимальна, когда состязание неопределенно, то есть когда два предмета имеют схожую силу и каждый имеет существенные шансы на победу. Она становится малой, когда один предмет значительно сильнее другого. Интуитивно понятно, что сравнения, которые уже почти детерминированы, вносят меньший вклад в локальную кривизну, поскольку модель уже достаточно уверена в них.
В технической статье полезно упомянуть этот момент, поскольку он связывает математику с геометрией данных. Наиболее информативными часто являются сравнения между элементами примерно одинакового качества. Именно такие сравнения дают наиболее сильный локальный сигнал об относительном порядке.
Градиентный подъем
Наиболее прямым методом оптимизации является градиентный подъем. Начиная с начального приближения параметров, выполняется многократное обновление:
где η — скорость обучения.
Поскольку логарифмическая функция правдоподобия после нормализации становится вогнутой, эта процедура концептуально проста. На каждом шаге параметры перемещаются в направлении, которое улучшает соответствие между ожиданиями модели и наблюдаемыми результатами. В задачах малого или среднего размера этого часто вполне достаточно.
Тем не менее, простой градиентный подъем не всегда является наиболее эффективным подходом. Скорость его сходимости зависит от скорости обучения и локальной кривизны целевой функции. Если η слишком мало, обучение происходит медленно; если оно слишком велико, обновления могут выйти за пределы допустимого диапазона.
Методы Ньютона и второго порядка
Поскольку градиент и гессиан доступны в замкнутой форме, метод Брэдли-Терри также можно аппроксимировать методами Ньютона или квазиньютоновскими методами. Шаг Ньютона имеет следующий вид:
где H — матрица Гессе, а ∇ℓ — вектор градиента.
Преимущество методов второго порядка заключается в том, что они напрямую учитывают кривизну. Вместо того чтобы двигаться только по наклону, они также используют информацию о том, насколько резко изгибается целевая функция. Это часто приводит к более быстрой сходимости, особенно вблизи оптимума.
Недостаток заключается в вычислительных затратах. Вычисление и обращение матрицы Гессе может быть дорогостоящим процессом при большом количестве элементов. По этой причине в практических реализациях часто предпочтение отдается квазиньютоновским методам или специализированным итеративным схемам.
Обновления MM
Одним из классических методов подгонки для алгоритма Брэдли-Терри является алгоритм MM, где MM означает миноризацию-максимизацию или мажоризацию-минимизацию в зависимости от используемой конвенции. Эти методы заменяют сложную целевую функцию более простой аппроксимирующей функцией, которую легче оптимизировать на каждом шаге.
Для Брэдли-Терри обновление MM для положительных сторон может быть записано в следующей форме:
где:
— это общее количество побед по пункту i, и
— это общее количество сравнений между i и j.
Это обновление предлагает привлекательную интерпретацию. Числитель показывает, как часто я действительно выигрывал тот или иной предмет. Знаменатель отражает, насколько велика была вероятность выигрыша при текущих параметрах. Алгоритм многократно масштабирует каждую величину, чтобы эти показатели лучше согласовывались.
Методы ММ популярны для синдрома Брэдли-Терри, потому что они автоматически сохраняют позитивный настрой и часто демонстрируют стабильную работу на практике.
Статистическая интерпретация оптимума
Особенно показательно условие оптимальности первого порядка. Приравнивая градиент к нулю, получаем:
для каждого элемента i.
Это означает, что в оптимальном случае общее количество наблюдаемых выигрышей по пункту i равно общему количеству выигрышей, ожидаемых для пункта i в соответствии с подобранной моделью. Другими словами, оцениваемые показатели силы — это те, для которых модель максимально точно воспроизводит эмпирическое количество выигрышей в ожидании.
Это, пожалуй, наиболее точная интерпретация обучения по Брэдли-Терри. Модель считается подходящей, когда её внутреннее вероятностное описание мира находится в равновесии с данными сравнения.
Контекстуальный подход Брэдли-Терри: Когда сила зависит от обстановки
Стандартная модель Брэдли-Терри присваивает каждому элементу единую скрытую силу. Это полезное упрощение, но и важное ограничение. На практике сила элемента часто зависит от обстоятельств сравнения. Языковая модель может хорошо справляться с математическими рассуждениями, но плохо — с творческим письмом. Шахматист может быть сильнее в быстрых форматах, чем в классических. Продукт может быть предпочтительнее в одном сегменте рынка, но не в другом.
Контекстуальная модель Брэдли-Терри решает эту проблему, позволяя скрытой силе изменяться в зависимости от наблюдаемых ковариат. Вместо фиксированного параметра βᵢ для каждого элемента, используется следующий код:
где xᵢ — вектор признаков, связанных с элементом i в текущем контексте сравнения, а w — вектор коэффициентов, общий для всех элементов и оцениваемый на основе данных. Вероятность сравнения становится:
Эта формулировка выявляет структурную эквивалентность, на которой стоит остановиться. Если определить вектор проектирования для сравнения как dᵢⱼ = xᵢ − xⱼ, то контекстная модель Брэдли-Терри принимает следующий вид:
где σ — логистическая функция. Это просто логистическая регрессия на основе разницы векторов признаков. Каждое попарное сравнение рассматривается как задача бинарной классификации, а признаками являются поэлементные различия между векторами ковариат двух элементов.
Эта эквивалентность имеет практическое значение. Любой программный пакет, подходящий для логистической регрессии, может быть использован для построения контекстной модели Брэдли-Терри. Создается обучающий набор данных, в котором каждая строка соответствует сравнению, признаки — dᵢⱼ = xᵢ − xⱼ, а метка равна 1, если i было предпочтительным, и 0 в противном случае. Затем оцениваемый вектор коэффициентов w определяет, как каждый признак влияет на вероятность выигрыша.
Какие ковариаты учитываются
Выбор ковариат определяет, что может выразить модель. В контексте оценки языковых моделей к релевантным ковариатам могут относиться тема задания (математика, программирование, творческое письмо), сложность задания (оцениваемая на основе показателей согласованности аннотаторов или на основе предикторов, основанных на векторном представлении), длина задания или оборот разговора, в котором проводилось сравнение.
С учетом этих ковариат модель больше не оценивает единую глобальную силу для каждой языковой модели. Вместо этого она оценивает профиль силы в пространстве признаков. Модель может иметь высокую оцененную силу в заданиях на программирование, но более низкую силу в открытых творческих задачах. Вектор обученных коэффициентов w количественно определяет, насколько каждый контекстный признак изменяет вероятность результата.
Это существенное отступление от стандартной модели. В неконтекстном случае модель отвечает на вопрос: «Какой элемент в целом сильнее?» В контекстном случае она отвечает: «При каких условиях каждый элемент сильнее и насколько?»
Приложение: Арена чат-ботов
Наиболее известным современным применением контекстного моделирования Брэдли-Терри является платформа LMSYS Chatbot Arena (Chiang et al., 2024), предназначенная для краудсорсинговой оценки больших языковых моделей. Пользователи отправляют запросы, получают ответы от двух анонимизированных моделей и указывают, какой ответ они предпочитают.
Проблема, с которой сталкивается Arena, заключается в том, что наивная система ранжирования Брэдли-Терри рассматривает все сравнения как одинаково информативные. На практике простые вопросы дают практически неотличимые результаты от большинства моделей, в то время как сложные вопросы выявляют значимые различия в качестве. Сравнение по тривиальному фактическому вопросу дает гораздо меньше сигнала для ранжирования, чем сравнение по сложной многошаговой задаче на логическое рассуждение.
Система Arena решает эту проблему, включая ковариаты на уровне подсказок в структуру Брэдли-Терри. Сложность подсказки, категория темы и другие лингвистические свойства включены в качестве признаков, что позволяет системе оценивать контекстно-специфические рейтинги для каждой модели. В результате получается не единый балл Эло для каждой модели, а усвоенный профиль силы в пространстве подсказок и заданий.
Доверительные интервалы, рассчитанные методом бутстрапа, вычисляются путем повторной выборки данных сравнения и переоценки коэффициентов Брэдли-Терри для каждой выборки бутстрапа, что позволяет оценить неопределенность в ранжировании.
Байесовское расширение: TrueSkill
Связанное, но отличное от предыдущего расширение — байесовский подход к оценке силы заданий. Система TrueSkill от Microsoft (Herbrich et al., 2006; Minka et al., 2018) заменяет точечные оценки апостериорными распределениями. Сила каждого задания моделируется как гауссовская случайная величина со средним значением μᵢ и дисперсией σᵢ². После каждого сравнения апостериорное распределение обновляется:
где τ² — параметр системного шума, учитывающий ничьи и сбои. Дисперсия σᵢ² уменьшается по мере увеличения числа сравнений, отражая растущую уверенность в оцененной силе.
Ключевое практическое преимущество этого подхода заключается в том, что он обеспечивает естественную меру неопределенности. Элемент с небольшим количеством сравнений имеет высокую дисперсию и, следовательно, широкий доверительный интервал. Элемент с большим количеством сравнений имеет низкую дисперсию и более точную оценку. Эта информация о неопределенности может быть использована для адаптивного сопоставления: сопоставление элементов с высокой неопределенностью друг с другом ускоряет сходимость ранжирования.
TrueSkill не учитывает ковариаты так же, как контекстная модель Брэдли-Терри, но эти две идеи дополняют друг друга. Можно было бы использовать байесовские априорные распределения для контекстно-зависимых характеристик, сохраняя при этом апостериорные распределения, которые варьируются в пространстве признаков. Это остается активной областью исследований.
Преимущества контекстуализации
Практические преимущества контекстного расширения можно суммировать следующим образом.
- Во-первых , интерпретируемость. Вместо одной непрозрачной оценки для каждого элемента, модель предоставляет профиль эффективности, который показывает, при каких условиях элемент работает хорошо, а при каких — нет.
- Во-вторых , эффективность использования данных. Используя структуру пространства признаков, контекстные модели могут извлекать больше сигнала ранжирования из меньшего количества сравнений. Элемент, который сравнивался только по заданиям на программирование, все еще может получить оценку силы по заданиям на математику, если модель научилась понимать, как тема влияет на производительность, на основе других элементов.
- В-третьих , обобщение на новые элементы. В стандартной модели новый элемент без истории сравнений не имеет оцененной силы. В контекстной модели, если вектор признаков нового элемента доступен, его силу можно оценить с помощью изученного вектора коэффициентов w без каких-либо прямых сравнений. Это форма прогнозирования с «холодным стартом», которая особенно ценна, когда количество элементов велико по сравнению с количеством сравнений.
Учет необъективных оценок: когда не все сравнения одинаковы
Модель Брэдли-Терри, как в стандартной, так и в контекстной форме, предполагает, что каждое наблюдаемое сравнение является одинаково надежным результатом из распределения вероятностей модели. Это предположение часто нарушается. В условиях краудсорсинга, когда сравнения собираются от множества людей-аннотаторов, качество индивидуальных оценок существенно различается.
Некоторые аннотаторы внимательны, последовательны и хорошо разбираются в предметной области. Другие могут спешить при сравнениях, применять специфические критерии или давать ответы, которые по сути являются случайными. Небольшая часть может быть враждебной или невнимательной. Если модель рассматривает все сравнения одинаково, оценка силы будет искажена шумом от ненадежных аннотаторов, и полученные рейтинги будут менее достоверными, чем это оправдывают данные.
Неявное предположение стандартной модели
Рассмотрим стандартную функцию правдоподобия Брэдли-Терри для одного сравнения, в котором аннотатор k сообщает, что элемент i предпочтительнее элемента j:
В этом выражении вообще не упоминается аннотатор. Предполагается, что результат представляет собой зашумленное наблюдение истинной вероятности сравнения, без различий в уровне шума между аннотаторами. Неявная модель состоит в том, что каждый аннотатор, независимо от квалификации или вовлеченности, имеет одинаковую вероятность правильного определения лучшего элемента.
На практике это случается редко. Разные аннотаторы привносят в задачу разный уровень квалификации, внимания и знаний в предметной области. Игнорирование этой неоднородности приводит к предвзятым оценкам качества, чрезмерно самоуверенным рейтингам и неспособности диагностировать или исправлять некачественные аннотации.
CrowdBT: Совместная оценка элементов и аннотаторов.
Чен и др. (2013) предложили CrowdBT — модель, которая решает эту проблему путем совместной оценки силы элементов и надежности аннотаторов. Ключевая идея заключается во введении параметра надежности для каждого аннотатора ρₖ ∈ [0, 1], который определяет качество сравнений, проводимых аннотатором k.
В системе CrowdBT вероятность сравнения моделируется как смесь:
Интерпретация этой смеси интуитивно понятна. С вероятностью ρₖ аннотатор наблюдает истинный результат Брэдли-Терри и правильно его сообщает. С вероятностью 1 − ρₖ аннотатор выдает равномерно случайный ответ. Абсолютно надежный аннотатор имеет ρₖ = 1 и ведет себя точно так же, как в стандартной модели. Полностью ненадежный аннотатор имеет ρₖ = 0 и вносит только шум.
Эта формулировка отражает важную особенность ненадежных аннотаторов. Предполагается, что они не склонны к враждебности (систематически ошибаются), а скорее склонны к шуму (иногда правы, иногда случайны). Это более реалистичная модель поведения человека при аннотировании, чем предположение об идеальной надежности или рассмотрение низкокачественных аннотаций как инвертированных сигналов.
Оценка с помощью EM-алгоритма
Полная логарифмическая функция правдоподобия в рамках CrowdBT выглядит следующим образом:
где Cₖ — множество сравнений, выполненных аннотатором k. Эта целевая функция оптимизируется с помощью алгоритма ожидания-максимизации (EM).
На этапе E для каждого наблюдаемого сравнения алгоритм вычисляет апостериорную вероятность того, что аннотатор действовал надежно (в отличие от случайного угадывания), с учетом текущих оценок β и ρ. Пусть zₖᵢⱼ обозначает этот скрытый индикатор. Его апостериорная вероятность равна:
На этапе M обновляются показатели надежности элементов β для максимизации вероятности сравнений, которые приписываются надежному поведению, а показатели надежности аннотаторов ρₖ обновляются на основе доли сравнений, которые на этапе E приписываются подлинной экспертизе, а не случайному угадыванию.
Алгоритм чередует эти два шага до сходимости. В результате получается набор показателей качества элементов, очищенных от шума путем уменьшения веса ненадежных аннотаторов, а также набор оценок надежности аннотаторов, которые можно использовать для контроля качества и диагностики.
Практические последствия
Модель CrowdBT имеет ряд практических последствий, которые заслуживают внимания.
- Во-первых, это обеспечивает автоматический контроль качества. Вместо отдельного этапа для выявления и удаления некачественных аннотаторов, модель обучается качеству аннотаторов как побочному результату подгонки ранжирования. Аннотаторы с низким расчетным значением ρₖ могут быть отмечены для проверки, переобучены или исключены из будущих задач.
- Во-вторых, это повышает точность ранжирования. За счет уменьшения веса зашумленных сравнений модель выдает оценки силы элементов, менее чувствительные к качеству аннотаций. Это особенно важно, когда пул аннотаторов неоднороден, что типично для краудсорсинговых платформ.
- В-третьих, это позволяет диагностировать сложность аннотирования. Если у многих аннотаторов низкая надежность при сравнении определенной пары элементов, это может указывать на то, что эти два элемента действительно трудно различить, а не на некомпетентность аннотаторов. Выходные данные модели могут помочь отделить шум, создаваемый аннотаторами, от неоднозначности на уровне отдельных элементов.
Расширения: за пределами единого параметра надежности
Последующие исследования позволили расширить формулировку CrowdBT в нескольких направлениях.
Естественным расширением является разложение поведения аннотаторов на надежность и предвзятость. Единственный параметр ρₖ отражает шум, но не систематические предпочтения. Аннотатор, который постоянно отдает предпочтение определенному элементу независимо от его качества, плохо описывается одним лишь параметром надежности. Добавление члена, описывающего предвзятость каждого аннотатора, позволяет модели различать шум (случайные ошибки) и систематическое искажение (постоянное предпочтение).
Второе расширение заключается в том, чтобы позволить надежности аннотаторов варьироваться в зависимости от области или темы. Аннотатор, являющийся экспертом в математике, может давать очень надежные сравнения по математическим вопросам, но гораздо более неточные сравнения по задачам на творческое письмо. Моделирование надежности, специфичной для конкретной области, как ρₖ,c, где c обозначает категорию сравнения, позволяет учесть эту неоднородность.
Третье расширение, разработанное в байесовском контексте, накладывает априорное распределение на параметры надежности. Естественным выбором является бета-априорное распределение:
которая кодирует априорное представление о распределении качества аннотаторов. Эта байесовская формулировка, иногда называемая BBQ (байесовский метод Брэдли-Терри с оценкой качества), предоставляет апостериорные распределения как по силе элементов, так и по надежности аннотаторов. Она обрабатывает случай, когда отдельные аннотаторы вносят лишь небольшое количество сравнений, используя априорное представление для регуляризации оценок надежности.
Связь с более широкой литературой по краудсорсингу.
Проблема агрегирования оценок от множества аннотаторов с шумом имеет богатую историю в статистической литературе и литературе по машинному обучению. Основополагающей моделью является модель Давида-Скена (1979), которая решает ту же проблему в контексте категориальной разметки. В модели Давида-Скена каждый аннотатор характеризуется матрицей ошибок, описывающей вероятность того, что он сообщит о каждой метке, учитывая истинную метку. Алгоритм EM совместно оценивает истинные метки и матрицы ошибок аннотаторов.
CrowdBT можно рассматривать как адаптацию этого принципа к условиям попарного сравнения. Вместо матрицы ошибок каждый аннотатор характеризуется параметром надежности. Вместо категориальных меток истинным сигналом является вероятность сравнения по Брэдли-Терри. Концептуальная структура та же: совместная оценка скрытой истинной величины и качества аннотатора, используя каждую из них для получения информации о другой.
Главный вывод из этой литературы заключается в том, что модели, которые совместно оценивают параметры элементов и параметры аннотаторов, неизменно превосходят модели, которые рассматривают любое из этих измерений как фиксированное. Рассмотрение всех аннотаторов как одинаково надежных приводит к потере информации о качестве аннотаций. Рассмотрение качества элементов как известного приводит к потере сигнала, предоставляемого аннотаторами. Наиболее эффективный подход — это одновременное обучение обоим параметрам, что и является целью CrowdBT и его расширений.
Краткое содержание
Стандартная модель Брэдли-Терри предоставляет удобную основу для обучения на основе попарных сравнений, но она предполагает, что все сравнения одинаково надежны. На практике качество аннотаторов варьируется, и это различие может искажать оцененные ранги.
Модель CrowdBT решает эту проблему, вводя параметр надежности для каждого аннотатора, который определяет вероятность наблюдения подлинного сравнения по сравнению со случайным предположением. Алгоритм EM совместно оценивает сильные стороны элементов и надежность аннотаторов, получая в качестве естественного побочного результата рейтинги без шума и оценки качества аннотаторов.
Расширения, касающиеся предметно-ориентированной надежности, байесовских априорных распределений и моделирования смещения, обеспечивают дополнительную гибкость для приложений, где гетерогенность аннотаторов особенно выражена. Вместе с контекстными расширениями, обсуждавшимися в предыдущем разделе, эти методы преобразуют базовую модель Брэдли-Терри из инструмента для простого ранжирования в многофункциональную структуру, способную справляться со сложностями сравнительной оценки в реальных условиях.
Оговорка: Мнения и взгляды, выраженные в этой статье, являются моими собственными и не отражают мнения моего работодателя или каких-либо аффилированных организаций. Содержание основано на личном опыте и размышлениях и не должно рассматриваться как профессиональная или академическая консультация.
📚 Дополнительная информация
Р. А. Брэдли и М. Э. Терри (1952) — Ранговый анализ неполных блочных схем: I. Метод парных сравнений — основополагающая работа Брэдли и Терри. В ней была представлена одна из канонических статистических моделей для данных парных сравнений, и она остается естественной отправной точкой для любого обсуждения ранжирования на основе предпочтений.
Мануэла Каттелан (2012) — Модели для парных сравнительных данных: обзор с акцентом на зависимые данные — Четкий обзор литературы по парным сравнениям, особенно полезный для понимания того, как классические модели, такие как модели Брэдли-Терри и Терстона, расширяются, когда сравнения не являются независимыми.
Си Чен, Пол Н. Беннетт, Кевин Коллинз-Томпсон и Эрик Хорвиц (2013) — Агрегация попарных ранжирований в условиях краудсорсинга — Полезный справочник по ранжированию в условиях зашумленных оценок людей. В статье рассматривается, как агрегировать попарные сравнения в условиях краудсорсинга, учитывая качество аннотаторов и эффективность разметки.
Вэй-Линь Чан и др. (2024) — Chatbot Arena: открытая платформа для оценки языковых моделей на основе человеческих предпочтений — основной справочник по оценке языковых моделей в стиле Arena с помощью масштабного попарного голосования людей. Особенно актуален, если ваша статья связывает модели парного сравнения с современными методами оценки языковых моделей.
AP Dawid и AM Skene (1979) — Оценка частоты ошибок наблюдателей методом максимального правдоподобия с использованием алгоритма EM — Классическая статья Давида и Скина об оценке скрытой истинности и надежности аннотаторов на основе зашумленных меток. Она является основополагающей для агрегирования коллективных меток и для тщательного обдумывания качества оценок в процессах анализа.
Ральф Хербрих, Том Минка и Тор Грепель (2006) — TrueSkill: Байесовская система оценки навыков — Оригинальная статья о TrueSkill, представляющая байесовскую структуру для вывода скрытых навыков на основе повторяющихся результатов соревнований. Она весьма актуальна, когда парные победы и поражения используются для построения динамических рейтингов во времени.
Том Минка, Райан Клевен и Йордан Зайков (2018) — TrueSkill 2: Улучшенная байесовская система оценки навыков — Более поздняя доработка TrueSkill, которая включает в себя более насыщенные сигналы и повышает точность прогнозирования. Она полезна, если вы хотите выйти за рамки простого агрегирования побед/поражений и перейти к более выразительным байесовским системам ранжирования.
Шон Моран. Все материалы от Шона Морана.
Источник: towardsdatascience.com
Оцените материал:

