На пути к науке масштабирования агентных систем: когда и почему агентные системы работают.
В результате контролируемой оценки 180 конфигураций агентов мы вывели первые количественные принципы масштабирования для систем агентов ИИ, показав, что координация нескольких агентов значительно улучшает производительность при выполнении параллельных задач, но ухудшает ее при выполнении последовательных; мы также представили прогностическую модель, которая определяет оптимальную архитектуру для 87% ранее не встречавшихся задач.
Быстрые ссылки
- Бумага
- Делиться
Искусственный интеллект — системы, способные рассуждать, планировать и действовать, — становится распространенной парадигмой для реальных приложений ИИ. От помощников в программировании до персональных тренеров по здоровью, отрасль переходит от ответов на разовые вопросы к длительным многоэтапным взаимодействиям. Хотя исследователи давно используют устоявшиеся метрики для оптимизации точности традиционных моделей машинного обучения, агенты вводят новый уровень сложности. В отличие от отдельных прогнозов, агенты должны управлять длительными многоэтапными взаимодействиями, где одна ошибка может распространиться по всему рабочему процессу. Этот сдвиг заставляет нас выйти за рамки стандартной точности и задать вопрос: как на самом деле проектировать эти системы для оптимальной производительности?
Практикующие специалисты часто полагаются на эвристические методы, такие как предположение, что «чем больше агентов, тем лучше», полагая, что добавление специализированных агентов неизменно улучшит результаты. Например, в исследовании «Больше агентов — это все, что вам нужно» сообщается, что производительность LLM масштабируется с количеством агентов, а исследования масштабирования сотрудничества показали, что многоагентное взаимодействие «…часто превосходит возможности каждого отдельного агента благодаря коллективному мышлению».
В нашей новой статье «К науке масштабирования агентных систем» мы ставим под сомнение это предположение. В ходе крупномасштабной контролируемой оценки 180 конфигураций агентов мы выводим первые количественные принципы масштабирования агентных систем, показывая, что подход «больше агентов» часто достигает потолка и может даже ухудшить производительность, если он не соответствует специфическим свойствам задачи.
Определение понятия «агентная» оценка
Чтобы понять, как масштабируются агенты, мы сначала определили, что делает задачу «агентной». Традиционные статические тесты измеряют знания модели, но они не отражают сложности развертывания. Мы утверждаем, что агентные задачи требуют трех специфических свойств:
- Длительное многоступенчатое взаимодействие с внешней средой.
- Итеративный сбор информации в условиях частичной наблюдаемости.
- Адаптивное совершенствование стратегии на основе обратной связи от окружающей среды.
Мы оценили пять канонических архитектур: одну одноагентную систему (SAS) и четыре многоагентных варианта (независимую, централизованную, децентрализованную и гибридную) на четырех различных тестовых наборах данных, включая Finance-Agent (финансовое мышление), BrowseComp-Plus (веб-навигация), PlanCraft (планирование) и Workbench (использование инструментов). Архитектуры агентов определены следующим образом:
- Одноагентный агент (SAS): Одиночный агент, выполняющий все этапы рассуждения и действия последовательно с использованием единого потока памяти.
- Независимый режим: несколько агентов работают параллельно над подзадачами, не обмениваясь информацией, и агрегируют результаты только в конце.
- Централизованная модель: модель «центр-периферия», в которой центральный координатор делегирует задачи работникам и синтезирует результаты их работы.
- Децентрализованная сеть: одноранговая сеть, в которой агенты напрямую общаются друг с другом для обмена информацией и достижения консенсуса.
- Гибридный подход: сочетание иерархического контроля и координации между участниками для достижения баланса между централизованным управлением и гибким исполнением.

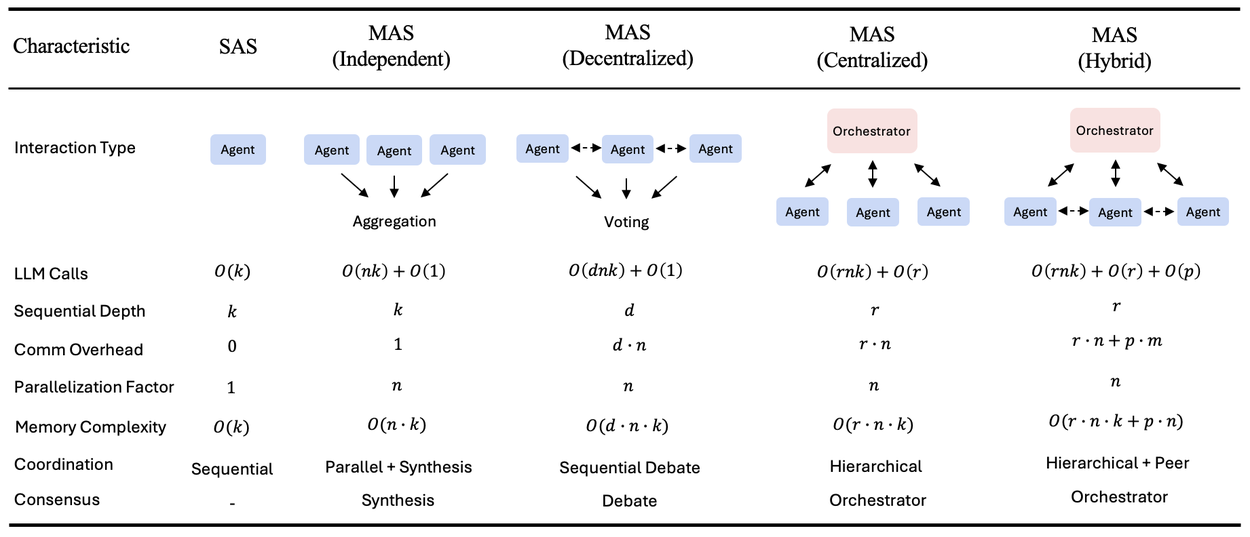
Краткое описание пяти канонических архитектур агентов, оцененных в данном исследовании, включая их вычислительную сложность, накладные расходы на связь и механизмы координации. k = максимальное количество итераций на агента, n = количество агентов, r = раунды оркестрации, d = раунды обсуждения, p = раунды взаимодействия между участниками, m = среднее количество запросов от участников за раунд. Накладные расходы на связь учитывают обмен сообщениями между агентами. Независимая архитектура обеспечивает максимальную параллелизацию при минимальной координации. Децентрализованная архитектура использует последовательные раунды обсуждения. Гибридная архитектура сочетает в себе управление оркестрацией с направленным взаимодействием между участниками.
Результаты: Миф о «большем количестве агентов»
Для количественной оценки влияния возможностей модели на производительность агентов мы протестировали наши архитектуры на трех ведущих семействах моделей: OpenAI GPT, Google Gemini и Anthropic Claude. Результаты показывают сложную взаимосвязь между возможностями модели и стратегией координации. Как показано на рисунке ниже, хотя производительность, как правило, повышается с увеличением возможностей модели, многоагентные системы не являются универсальным решением — они могут либо значительно повысить, либо неожиданно снизить производительность в зависимости от конкретной конфигурации.
Сравнение производительности трех основных семейств моделей (OpenAI GPT, Google Gemini, Anthropic Claude) показывает, как различные архитектуры агентов масштабируются в зависимости от интеллекта модели, при этом многоагентные системы могут либо повышать, либо понижать производительность в зависимости от конфигурации.
Приведенные ниже результаты сравнивают производительность пяти архитектур в различных областях, таких как веб-браузинг и финансовый анализ. Диаграммы разброса представляют распределение точности для каждого подхода, а проценты указывают на относительное улучшение (или ухудшение) работы многоагентных команд по сравнению с базовым вариантом с одним агентом. Эти данные показывают, что, хотя добавление агентов может значительно повысить производительность в задачах, допускающих параллельное выполнение, оно часто приводит к снижению эффективности — или даже падению производительности — в более последовательных рабочих процессах.
Анализ производительности по конкретным задачам показывает, что координация нескольких агентов обеспечивает существенное повышение производительности в параллельных задачах, таких как Finance-Agent (+81%), в то время как производительность в последовательных задачах, таких как PlanCraft (-70%).
Принцип выравнивания
В задачах, допускающих параллельное выполнение, таких как финансовое мышление (например, различные агенты могут одновременно анализировать тенденции доходов, структуру затрат и сравнение рынков), централизованная координация повысила производительность на 80,9% по сравнению с одним агентом. Возможность разбивать сложные проблемы на подзадачи позволила агентам работать более эффективно.
Последовательный штраф
Напротив, в задачах, требующих строгой последовательной логики (например, планирование в PlanCraft), каждый протестированный нами вариант с несколькими агентами снижал производительность на 39-70%. В этих сценариях издержки на обмен данными фрагментировали процесс рассуждений, оставляя недостаточно «когнитивного бюджета» для выполнения самой задачи.
Узкое место в использовании инструментов
Мы выявили «компромисс между координацией инструментов». По мере того, как задачи требуют больше инструментов (например, программист, имеющий доступ к более чем 16 инструментам), «налог» на координацию нескольких агентов возрастает непропорционально.
Архитектура как элемент безопасности
Возможно, наиболее важным для практического применения является обнаруженная нами взаимосвязь между архитектурой и надежностью. Мы измерили усиление ошибки — скорость, с которой ошибка одного агента распространяется на конечный результат.
Комплексный анализ показателей различных архитектур показывает, что централизованные системы обеспечивают наилучший баланс между вероятностью успеха и локализацией ошибок, в то время как независимые многоагентные системы увеличивают количество ошибок до 17,2 раз.
Мы обнаружили, что независимые многоагентные системы (агенты, работающие параллельно без обмена данными) усиливают ошибки в 17,2 раза. Без механизма проверки работы друг друга ошибки распространялись бесконтрольно. Централизованные системы (с оркестратором) ограничивают это усиление всего 4,4 раза. Оркестратор фактически действует как «узкое место проверки», выявляя ошибки до того, как они распространятся.
Прогностическая модель для проектирования агентов
Выходя за рамки ретроспективного анализа, мы разработали прогностическую модель ( R² = 0,513), которая использует измеримые свойства задачи, такие как количество инструментов и возможность декомпозиции, для прогнозирования того, какая архитектура будет работать лучше всего. Эта модель правильно определяет оптимальную стратегию координации для 87% ранее не встречавшихся конфигураций задач.
Это говорит о том, что мы движемся к новой науке масштабирования агентов. Вместо того чтобы гадать, использовать ли рой агентов или одну мощную модель, разработчики теперь могут анализировать свойства своей задачи, в частности, ее последовательные зависимости и плотность инструментов, чтобы принимать обоснованные инженерные решения.
Заключение
По мере развития таких базовых моделей, как Gemini, наши исследования показывают, что более совершенные модели не заменяют необходимость в многоагентных системах, а, наоборот, ускоряют её, но только при условии правильной архитектуры. Переходя от эвристических методов к количественным принципам, мы можем создать следующее поколение агентов ИИ, которые будут не просто многочисленнее, но и умнее, безопаснее и эффективнее.
Благодарности
Мы хотели бы поблагодарить наших соавторов и коллег из Google Research, Google DeepMind и академических кругов за их вклад в эту работу.
Источник: research.google
Оцените материал:

