Новая структура для аудита разучивания машин.
Мы представляем метод, разработанный для уверенного определения наличия статистически значимых доказательств того, что два набора данных получены из совершенно разных базовых распределений.
Быстрые ссылки
- Бумага
- Делиться
Машинное разучивание позволяет системам ИИ «забывать» определенные части обучающих данных без огромных затрат на переобучение модели с нуля. Это крайне важно для соблюдения нормативных требований (например, «права на забвение» в рамках GDPR), безопасности ИИ и качества моделей.
Поскольку модели обрабатывают все более массивные и крайне конфиденциальные наборы данных, проверка процесса разучивания машин перешла из теоретического идеала в строгое требование, где разработчики теперь должны математически доказывать конфиденциальность. Однако, поскольку аудиторы часто не имеют доступа к внутренней работе модели или исходным обучающим данным, они должны проверять систему строго путем запросов к ней и анализа выходных данных.
Один из методов, используемых специалистами по анализу данных и исследователями для проверки достоверности данных, — это двухвыборочное тестирование, статистический метод, определяющий, принадлежат ли два набора данных совершенно разным базовым распределениям. Например, для проверки процесса «разучивания» аудиторы могут сравнить результаты модели, которая никогда не видела конкретную запись, с результатами модели, которая, предположительно, «забыла» её. Если результаты статистически различаются в пределах заданного порога, процесс «разучивания» не удался.
По мере роста размеров и сложности моделей, двухвыборочное тестирование и другие статистические инструменты, используемые для аудита с применением машинного обучения, становятся сложными в реализации и теряют статистическую мощность. Для выявления реального нарушения на фоне случайного шума, присущего крупномасштабным моделям, и с достаточной статистической значимостью, аудитору необходимо извлечь большое количество выборок. Это делает тестирование в реальных условиях чрезвычайно затратным с точки зрения вычислительных ресурсов.
Для решения этой растущей проблемы мы представляем тесты ядра регуляризованной f-дивергенции, представленные на конференции AISTATS 2026, — новую структуру, разработанную для того, чтобы сделать аудит моделей машинного обучения гораздо более чувствительным, гибким и точным. Мы теоретически доказываем, что наши тесты естественным образом контролируют ложноположительные результаты для любого размера выборки и что риск ложноотрицательных результатов надежно сходится к нулю по мере увеличения количества доступных выборок данных.
Задача: Почему стандартные инструменты не справляются со своей задачей?
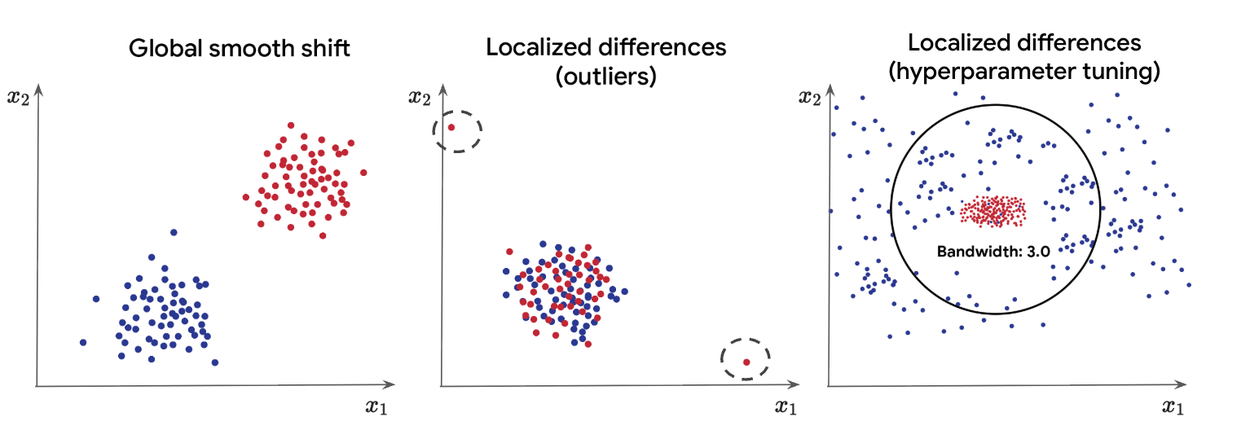
Оценка безопасности модели часто требует измерения расстояния, или расхождения, между двумя сложными наборами данных. Различные приложения, естественно, требуют разных представлений о «расстоянии». Хотя популярные стандартные инструменты, такие как максимальное среднее расхождение (MMD), отлично справляются с обнаружением широких, глобальных сдвигов в данных (например, когда модель систематически генерирует более яркие изображения, чем ее аналог), им часто не хватает необходимой специфичности для выявления сложных аномалий. Например, если добавление данных конкретного человека приводит к тому, что модель генерирует очень специфический выброс только при очень точном запросе — при этом имея одинаковое распределение по всем остальным образцам — традиционные тесты MMD могут полностью проигнорировать этот локальный сдвиг.
Кроме того, большинство существующих фреймворков для тестирования вынуждают исследователей делать подверженные ошибкам ручные выборы, такие как выбор конкретной статистики, наиболее подходящей для глобальных или локальных сдвигов, или настройка сложных параметров, таких как ширина полосы пропускания ядра и параметры регуляризации.

В простом двухвыборочном тесте между двумя двумерными распределениями (выше синим и красным цветом) MMD отлично справляется с обнаружением глобальных сдвигов, таких как различия в среднем значении ( слева ), но может пропускать локальные различия, такие как выбросы ( посередине ) или негладкие различия, требующие настройки гиперпараметров, например, установки параметра ширины полосы пропускания ( справа ).
Помимо сложности на практике, двухвыборочное тестирование как метод верификации имеет недостатки при проверке разучивания моделей машинного обучения. Рассмотрим приведенный ниже пример, показывающий, как две модели, обученные с нуля на одних и тех же данных, могут давать разные распределения. Синее распределение — это распределение модели, переобученной без искажения данных. Однако его распределение отличается от стандартного (зеленого) из-за переобучения с разными размерами пакетов. Это приводит к ложноположительному результату, указывающему на небезопасность тестируемой модели.
Использование двухвыборочного теста для проверки разучивания приводит к ложным срабатываниям, когда тестируемая модель имеет распределение, отличное от стандартного, с которым сравнивает ее аудитор.
Кроме того, недавние исследования показывают, что модель ИИ никогда не сможет идеально «забыть» данные, просто изменив текущие настройки; если она не повторит каждый шаг своего первоначального обучения, она всегда оставит после себя постоянный след информации, которую должна была удалить. Соответственно, достижение идеальной «эквивалентности переобучения» принципиально невозможно для стандартных алгоритмов локального разучивания, и традиционный двухвыборочный тест всегда может выявить зависимость от «множества забытых данных».
Структура
Мы решаем эту проблему, предлагая тест относительного расстояния, который измеряет, находится ли необученная модель в распределении ближе к безопасно переобученной модели или к исходной, скомпрометированной модели.
Наш тест представляет собой высокоадаптивный статистический инструментарий, использующий f-дивергенции для выявления аудиторами специфических типов изменений данных, в том числе:
- Критерий хи-квадрат и дивергенция Кульбака-Лейблера (КЛ): эти критерии весьма эффективны для выявления плавных и локализованных различий в данных, таких как выбросы в физических моделях.
- Дивергенция по принципу «хоккейной клюшки»: этот метод, специально разработанный для учета определений конфиденциальности и разучивания, работает с параметром, контролирующим степень статистической неразличимости. Он эффективно устанавливает приемлемый порог, игнорируя незначительные различия ниже уровня безопасности и вызывая оповещение только при существенном нарушении конфиденциальности.
Вычисление этих расхождений на многомерных данных из реального мира, как известно, представляет собой сложную задачу. Чтобы сделать эти сложные задачи оптимизации решаемыми без необходимости огромных вычислительных ресурсов, мы используем методы ядерной регуляризации для эффективной оценки разностей.
Наш адаптивный подход к тестированию автоматически выбирает наилучшее расхождение и оптимальные конфигурации гиперпараметров для максимизации надежности теста, полностью исключая необходимость разделения выборки.
Эксперименты
Поскольку предложенные нами тесты носят общий характер, мы провели эксперименты на самых разных задачах. Мы оценили нашу систему на возмущенных равномерных распределениях (синтетические тесты с двумя выборками), а также на задаче обнаружения выбросов Expo1D в физических наборах данных — специализированной области, использующей машинное обучение для поиска новых физических явлений за пределами стандартной модели физики элементарных частиц. Мы использовали данные физики высоких энергий, поскольку эта область требует самых точных в мире «детекторов разностей» — идея заключается в том, что если система может обнаружить редкую частицу, которая противоречит законам физики, она может обнаружить крошечную утечку конфиденциальной информации в модели ИИ.
Затем мы переключили наше основное внимание на критически важные практические применения аудита дифференциальной конфиденциальности и оценки методов машинного разучивания:
- Аудит конфиденциальности : Дифференцированная конфиденциальность обеспечивает основу для защиты пользовательских данных путем введения калиброванного шума, ограничивающего влияние любого отдельного человека. Мы протестировали несколько неконфиденциальных механизмов, выбрав их выходные данные из двух смоделированных наборов данных, которые отличались всего одной записью. Если механизм действительно является конфиденциальным, два полученных образца должны быть неотличимы; если он ошибочен, тест должен выявить нарушение конфиденциальности.
- Оценка разучивания модели: Вместо того чтобы полагаться на ошибочный подход простого сравнения эталонной модели (переобученной с нуля без забытых данных) с разученной моделью, мы использовали трехвыборочный относительный тест, применив его к различным известным алгоритмам разучивания, включая селективное синаптическое подавление, обрезку и методы случайных меток. Наш тест оценивал, было ли распределение разученной модели ближе к безопасной эталонной модели или ближе к исходной, полностью обученной модели, которая активно запоминала конфиденциальные данные.
Предлагаемая структура для определения относительного расстояния. Если тестируемая модель ближе к скомпрометированной модели, чем к переобученному эталонному образцу, тест выявляет ошибку разучивания. Если тестируемая модель ближе к эталонному образцу, тест не выявляет никаких ошибок.
Результаты
Наша система успешно восстановила или превзошла все предыдущие базовые методы, при этом значительно сократив объем ручной настройки.
Результаты эксперимента показали, что ни один тест не превосходит другие во всех возможных сценариях. Вместо этого, различные f-дивергенции действуют как специализированные датчики, которые «загораются» при различных типах локальных сдвигов данных. Используя агрегированный подход на основе различных статистических показателей, наша система успешно выявила тонкие ошибки и аномалии, которые стандартные тесты полностью пропустили.
Для аудита конфиденциальности тест на дивергенцию типа «хоккейная клюшка» оказался мощным и эффективным инструментом. Поскольку он напрямую соответствует математическим основам чистой дифференциальной конфиденциальности, он позволяет аудиторам строго контролировать допустимую степень смещения данных. Наша адаптивная система тестирования успешно выявила нарушения конфиденциальности, используя значительно меньшее количество выборок данных и требуя гораздо меньшей настройки гиперпараметров, чем предыдущие базовые тестеры.
Показатель обнаружения неконфиденциальных механизмов ( на основе стандартных аудиторских критериев). Наш тестер, основанный на модели «хоккейной клюшки», превосходит ранее изученные методы ( DP-Auditorium ) при меньшем количестве выборок.
В одном примечательном случае наша система обнаружила нарушения в конкретном механизме разреженного векторного анализа (SVT3), используя всего несколько тысяч образцов, в то время как ранее изученные методы, такие как DP-Auditorium, требовали миллионов образцов для достижения приблизительно такой же скорости обнаружения нарушений.
Наши результаты также предполагают пересмотр подхода к оценке процесса разучивания машин. Как показано в таблице ниже, мы обнаружили, что ни один из оцененных нами приблизительных методов разучивания не соответствовал строгому стандартному определению разучивания на основе двух выборок. Поскольку двухвыборочные тесты просто ищут любые различия в распределении, они ошибочно помечали совершенно безопасные, переобученные модели как модели, не прошедшие процесс разучивания.
Напротив, предложенный нами относительный тест на основе трех выборок успешно преодолел этот недостаток. Он правильно и последовательно определял безопасно переобученные модели как «безопасные». При оценке алгоритмов приблизительного разучивания только метод случайных меток прошел проверку.
Другие популярные методы, такие как тонкая настройка, обрезка и селективное синаптическое подавление, оказались неэффективными для истинного забывания целевых данных. Мы подчеркиваем, что нашей основной целью в этих экспериментах была оценка методов разучивания, а не разработка самих алгоритмов. Следовательно, мы использовали упрощенные реализации этих процедур разучивания; для ранжирования методов разучивания в практических производственных условиях потребуются более строгие настройки.
Результаты аудита различных (упрощенных) алгоритмов разучивания. Точные механизмы разучивания переобучаются с нуля без доступа к данным для забывания и, следовательно, по определению безопасны. Однако двухвыборочные тесты ошибочно помечают их как небезопасные из-за различий в распределении с «стандартом». Трехвыборочный тест решает эту проблему.
Заключение
Предложенная нами новая структура обеспечивает гораздо более точный, адаптируемый и математически обоснованный подход к анализу поведения машинного обучения. Используя регуляризованные тесты ядра f-дивергенции, исследователи и аудиторы теперь могут статистически доказать, ведет ли себя модель небезопасно или допускает утечку данных в широком классе задач и при сложных сдвигах распределений.
По мере развития этой области теоретическое обоснование наших эмпирических наблюдений для точного определения того, какое именно расхождение является оптимальным для других новых задач, остается захватывающим направлением для будущих исследований. Установление более строгих границ сложности выборки также станет ключевым направлением для повышения эффективности этих проверок.
Благодарности
Описанная здесь работа была выполнена совместно с Антонином Шрабом и Артуром Греттоном. Мы благодарим Николь Митчелл и Элени Триантафиллу за ценные замечания, а также Кимберли Шведе за графическое оформление и Марка Симборга за полезные правки.
Источник: research.google
Оцените материал:
