Байесовские сети и сети Маркова: интуитивно понятное руководство по структурированной неопределенности
Интуитивное введение в рассуждения в условиях неопределенности, от направленных байесовских сетей до ненаправленных марковских сетей и взвешенных логических правил.
Делиться

Большинство объяснений принципов машинного обучения начинаются с прогнозирования. Модель оттока клиентов оценивает вероятность ухода клиента. Модель выявления мошенничества оценивает, является ли транзакция подозрительной. Модель диагностики оценивает вероятность заболевания на основе симптомов, анализов и истории болезни. Классификатор документов присваивает категорию на основе текста, метаданных или векторных представлений.
В каждом случае схема в целом одинакова. У нас есть некоторая наблюдаемая информация, обычно называемая входными данными или признаками , и то, что мы хотим предсказать, обычно называемое целевым значением . Если мы обозначим входные данные как X, а целевое значение как Y, то обычная задача обучения с учителем состоит в том, чтобы обучить модель:
- P(Y | X)
То есть, учитывая входные данные, насколько вероятен каждый возможный выходной результат?
Такая структура очень полезна. Она предоставляет нам логистическую регрессию, машины опорных векторов, случайные леса, градиентный бустинг, нейронные сети и значительную часть современного прикладного машинного обучения. Во многих производственных условиях это правильная отправная точка. У вас есть целевая переменная, некоторые данные и метрика. Задача модели — дать хороший ответ для этой целевой переменной.
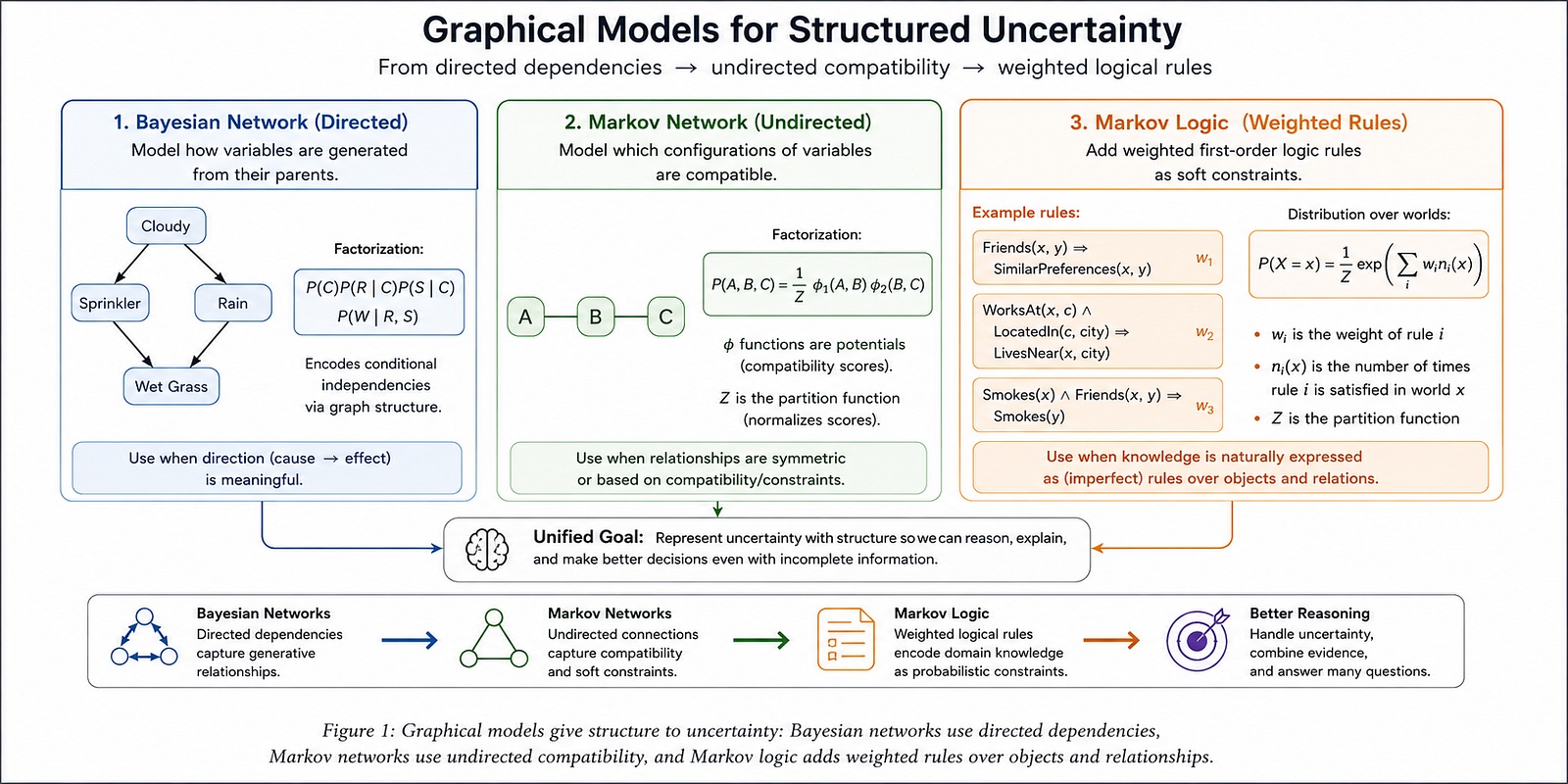
Байесовские сети основаны на ином подходе к моделированию. Они полезны, когда нам нужно представить небольшой неопределенный мир, а не просто выучить отображение входных данных на один выход. Вместо того чтобы делить мир на «входы» и «цель», мы описываем набор неопределенных переменных:
- X₁, …, Xₙ
Некоторые из этих переменных могут быть наблюдаемыми, некоторые — скрытыми, и любая из них может стать тем, что нас интересует в плане прогнозирования. График описывает, как эти неопределенные переменные зависят друг от друга, откуда могут поступать данные и как должны обновляться убеждения при поступлении новой информации.
Классификатор обычно строится вокруг одного вопроса прогнозирования:
- Исходя из этих входных данных, каков будет выходной результат?
Байесовская сеть строится вокруг более общего вопроса неопределенности:
Эти неопределенные вещи взаимосвязаны. Имея данные в любой точке системы, чему мы теперь должны верить относительно остального?
Таким образом, вместо того чтобы запрашивать только P(Y | X), мы представляем более полное совместное распределение по переменным:
- P(X₁, …, Xₙ)
Цель графа — сделать это совместное распределение управляемым, закодировав, какие переменные напрямую зависят от каких других.
Мы будем формировать интуитивное понимание поэтапно: сначала полное совместное распределение, затем крошечная байесовская сеть типа «мокрая трава» на Python, затем объяснение любой условной независимости, затем обучение параметров и вывод, и, наконец, сети Маркова и логика Маркова.
Полное совместное распределение — это то, чего мы не можем себе позволить.
Представьте себе небольшой мир с несколькими неопределенными фактами: облачность, дождь, использование дождевателей, мокрая трава, скользкое покрытие, пробки и опоздание.
В принципе, наиболее полная вероятностная модель описывала бы вероятность каждой возможной конфигурации:
- P(Облачно, Дождь, Полив, Мокрая трава, Скользкое покрытие, Пробки, Опоздание)
Это полное совместное распределение. Если бы оно у нас было, мы могли бы задать практически любой вопрос:
- P(Дождь | Влажная трава)
- P(Опоздание | Дождь, Пробки)
- P(Спринклер | Влажная трава, без дождя)
Проблема в том, что полное совместное распределение растет невероятно быстро. Если каждая переменная бинарна, то для n переменных требуется 2ⁿ возможных конфигураций. Семь переменных уже дают 128 состояний. Двадцать переменных дают более миллиона. Сто переменных — это недостижимо.
Таким образом, проблема отчасти статистическая, а отчасти репрезентативная. Нам нужен способ избежать ситуации, когда каждая переменная рассматривается как потенциально взаимосвязанная со всеми другими переменными всеми возможными способами.
Именно здесь вступают в игру графические модели.
Графическая модель — это компактный способ представления распределения вероятностей на основе предположений о его структуре. Граф показывает, какие локальные взаимосвязи мы моделируем непосредственно, а какие рассматриваем как косвенные следствия этих локальных элементов.
Главная идея проста:
- Не следует представлять весь неопределенный мир как одну большую таблицу. Разбейте его на более мелкие, условные части.
Байесовская сеть — это направленное отображение локальной зависимости.
Рассмотрим классический пример с мокрой травой. Вы выходите на улицу и видите, что трава мокрая. Возможно, шел дождь. Возможно, работал поливальный насос. Возможно, произошло и то, и другое. Модель утверждает, что дождь и работа поливального насоса влияют на то, мокрая трава или нет. Распределение вероятностей факторизуется следующим образом:
- P(Дождь, Дождевик, Мокрая трава) = P(Дождь) P(Дождевик) P(Мокрая трава | Дождь, Дождевик)
Вместо того чтобы составлять отдельную таблицу для каждой комбинации дождя, полива и мокрой травы, мы пишем более мелкие детали:
- P(Дождь)
- P(Спринклер)
- P(WetGrass | Дождь, Полив)
Условную таблицу для мокрой травы представить несложно:
Для каждой переменной строится локальная вероятностная модель, обусловленная её родителями. Для байесовской сети над X₁, …, Xₙ общая факторизация выглядит следующим образом:
- P(X₁, …, Xₙ) = произведение P(Xᵢ | Parents(Xᵢ)) по переменной i
Каждой переменной достаточно знать только о своих непосредственных родителях. Именно так большая вероятностная модель превращается в набор более мелких, понятных частей.
Небольшая байесовская сеть на Python
Это поможет сделать это более наглядным. Мы построим самую маленькую и полезную версию модели мокрой травы:
- дождь может пойти, а может и не пойти.
- Система полива может быть включена, а может и нет.
- Трава может быть мокрой, а может и нет.
Структура проста. И дождь, и полив влияют на то, будет ли трава влажной. Мы можем записать модель следующим образом:
- P(Дождь, Дождевик, Мокрая трава) = P(Дождь) P(Дождевик) P(Мокрая трава | Дождь, Дождевик)
Первые два члена представляют собой простые априорные вероятности. Последний член — это таблица условных вероятностей. Вот намеренно упрощенная реализация на чистом Python:
from itertools import product # Prior probabilities P_RAIN = { True: 0.2, False: 0.8, } P_SPRINKLER = { True: 0.1, False: 0.9, } # Conditional probability table: # P(WetGrass = True | Rain, Sprinkler) P_WET_GIVEN_RAIN_SPRINKLER = { (False, False): 0.01, (False, True): 0.80, (True, False): 0.90, (True, True): 0.99, } def p_wet_grass(wet, rain, sprinkler): """ Return P(WetGrass = wet | Rain = rain, Sprinkler = sprinkler). """ p_wet = P_WET_GIVEN_RAIN_SPRINKLER[(rain, sprinkler)] return p_wet if wet else 1 - p_wet def joint_probability(rain, sprinkler, wet): """ Return P(Rain, Sprinkler, WetGrass). """ return ( P_RAIN[rain] * P_SPRINKLER[sprinkler] * p_wet_grass(wet, rain, sprinkler) )
Это вся байесовская сеть. Здесь нет библиотек, нет обучения и нет механизмов, скрытых за API. Структура модели видна в результате умножения:
P_RAIN[rain] * P_SPRINKLER[sprinkler] * p_wet_grass(wet, rain, sprinkler)
Эта строка — это разложение на множители, записанное в коде. Теперь мы можем перечислить все возможные миры.
for rain, sprinkler, wet in product([False, True], repeat=3): p = joint_probability(rain, sprinkler, wet) print( f"Rain={rain:5} Sprinkler={sprinkler:5} " f"WetGrass={wet:5} P={p:.4f}" )
Это позволяет нам определить вероятность каждого выполненного задания.
Полное выполнение задания подразумевает полное возможное состояние маленького мира: шел ли дождь, работал ли поливальный насос и была ли мокрая трава.
Сумма вероятностей во всех возможных мирах должна равняться единице:
total = 0.0 for rain, sprinkler, wet in product([False, True], repeat=3): total += joint_probability(rain, sprinkler, wet) print(total)
Результат должен быть равен 1,0, что является полезной проверкой на адекватность. Мы построили допустимое совместное распределение вероятностей, умножив меньшие локальные таблицы вероятностей.
Задавая вопросы модели
Получив совместное распределение, мы можем задавать вопросы. Например:
- P(Дождь | Влажная трава)
Другими словами, если трава мокрая, какова вероятность того, что шел дождь? По правилу Байеса:
- P(Дождь | Влажная трава) = P(Дождь, Влажная трава) / P(Влажная трава)
Мы можем рассчитать это, просуммировав значения ненаблюдаемой переменной, которой является разбрызгиватель:
def probability_of_evidence(**evidence): """ Sum the joint probability of all worlds that match the observed evidence. Example: probability_of_evidence(wet=True) probability_of_evidence(rain=True, wet=True) """ total = 0.0 for rain, sprinkler, wet in product([False, True], repeat=3): world = { "rain": rain, "sprinkler": sprinkler, "wet": wet, } matches_evidence = all( world[name] == value for name, value in evidence.items() ) if matches_evidence: total += joint_probability(rain, sprinkler, wet) return total
Теперь мы можем вычислить:
p_rain_and_wet = probability_of_evidence(rain=True, wet=True) p_wet = probability_of_evidence(wet=True) p_rain_given_wet = p_rain_and_wet / p_wet print(p_rain_given_wet)
Это дает 0,6897. Таким образом, в этой крошечной модели, как только мы наблюдаем мокрую траву, вероятность дождя возрастает с ее предыдущего значения 0,2 до примерно 0,69. Это байесовское обновление. Наблюдение изменило наше убеждение.
Доказательства могут подтверждать более одного объяснения.
Мокрая трава также повышает вероятность срабатывания поливальной системы:
p_sprinkler_and_wet = probability_of_evidence(sprinkler=True, wet=True) p_sprinkler_given_wet = p_sprinkler_and_wet / p_wet print(p_sprinkler_given_wet)
В результате получаем: 0,3577. Вероятность срабатывания разбрызгивателя составляла 0,1. После наблюдения за мокрой травой эта вероятность возрастает примерно до 0,36. Это логично. Мокрая трава является доказательством обеих возможных причин.
Теперь мы можем рассмотреть способ объяснения. Предположим, нам известны две вещи:
- Трава мокрая
- дождь определенно шел.
Насколько вероятно, что система полива была включена?
- P(Спринклер | Мокрая трава, Дождь)
p_sprinkler_rain_wet = probability_of_evidence( sprinkler=True, rain=True, wet=True, ) p_rain_wet = probability_of_evidence( rain=True, wet=True, ) p_sprinkler_given_wet_and_rain = p_sprinkler_rain_wet / p_rain_wet print(p_sprinkler_given_wet_and_rain)
Это даёт 0,1099, что намного ниже 0,3577. Когда мы знали только, что трава мокрая, версия с дождевателем стала более правдоподобной. Как только мы узнали, что ещё и дождь пошёл, версия с дождевателем стала менее необходимой в качестве объяснения. Это объяснение. Трава мокрая. Сначала дождь и дождеватель кажутся правдоподобными объяснениями. Как только становится известно о дожде, часть доказательной базы в пользу версии с дождевателем исчезает.
Это одна из причин, почему байесовские сети полезны для структурированного мышления. Доказательства не просто перемещаются от входных данных к выходным. Они перемещаются внутри структуры.
Полная реализация игрушки
Вот всё целиком:
from itertools import product # ----------------------------- # 1. Define the Bayesian network # ----------------------------- P_RAIN = { True: 0.2, False: 0.8, } P_SPRINKLER = { True: 0.1, False: 0.9, } P_WET_GIVEN_RAIN_SPRINKLER = { (False, False): 0.01, (False, True): 0.80, (True, False): 0.90, (True, True): 0.99, } def p_wet_grass(wet, rain, sprinkler): p_wet = P_WET_GIVEN_RAIN_SPRINKLER[(rain, sprinkler)] return p_wet if wet else 1 - p_wet def joint_probability(rain, sprinkler, wet): return ( P_RAIN[rain] * P_SPRINKLER[sprinkler] * p_wet_grass(wet, rain, sprinkler) ) # ----------------------------- # 2. Sum over matching worlds # ----------------------------- def probability_of_evidence(**evidence): total = 0.0 for rain, sprinkler, wet in product([False, True], repeat=3): world = { "rain": rain, "sprinkler": sprinkler, "wet": wet, } if all(world[name] == value for name, value in evidence.items()): total += joint_probability(rain, sprinkler, wet) return total def conditional_probability(query, given): """ Compute P(query | given). query and given are dictionaries. Example: conditional_probability( query={"rain": True}, given={"wet": True}, ) """ numerator_evidence = dict(given) numerator_evidence.update(query) numerator = probability_of_evidence(**numerator_evidence) denominator = probability_of_evidence(**given) return numerator / denominator # ----------------------------- # 3. Ask questions # ----------------------------- print("Prior P(Rain):") print(P_RAIN[True]) print("nP(Rain | WetGrass):") print( conditional_probability( query={"rain": True}, given={"wet": True}, ) ) print("nP(Sprinkler | WetGrass):") print( conditional_probability( query={"sprinkler": True}, given={"wet": True}, ) ) print("nP(Sprinkler | WetGrass, Rain):") print( conditional_probability( query={"sprinkler": True}, given={"wet": True, "rain": True}, ) )
Ожидаемый результат:
P(Rain): 0.2 P(Rain | WetGrass): 0.6896551724137931 P(Sprinkler | WetGrass): 0.3577283372365339 P(Sprinkler | WetGrass, Rain): 0.10987791342952276
Вероятности ключевых элементов развиваются следующим образом:
Мокрая трава повышает вероятность как дождя, так и срабатывания дождевателя. Затем, узнав о дожде, вероятность срабатывания дождевателя снова снижается. Это первый конкретный результат статьи. С помощью нескольких таблиц вероятностей и некоторых перечислений мы получаем модель, которая может рассуждать вперед, назад и вбок в условиях неопределенности.
График кодирует то, что перестаёт иметь значение.
Теперь добавим облачность. Облачность влияет на то, будет ли дождь, и может также повлиять на то, включит ли кто-нибудь поливальную машину. Дождь и поливальная машина, в свою очередь, влияют на то, будет ли трава мокрой.
Разложение на множители принимает следующий вид:
- P(C, R, S, W) = P(C) P(R | C) P(S | C) P(W | R, S)
где:
C = Cloudy R = Rain S = Sprinkler W = Wet grass
Это уже тонкий нюанс. Модель утверждает, что мокрая трава напрямую зависит от дождя и работы дождевателя. Она может косвенно зависеть от облачности, поскольку облачность влияет на дождь и работу дождевателя. Как только мы узнаем, шел ли дождь и был ли включен дождеватель, облачность больше ничего не добавляет о мокрой траве.
Формально:
- WetGrass ⟂ Облачно | Дождь, полив
Проще говоря:
- Если известны осадки и наличие дождевальных установок, то состояние влажной травы не зависит от облачности.
Это не делает облачность неактуальной. Это означает, что облачность становится неактуальной после того, как были учтены соответствующие переменные.
Это одна из самых полезных идей в байесовских сетях. Они кодируют условную независимость. Они показывают, какая информация становится избыточной, как только становится известна другая информация.
В реальных системах это имеет значение. Сигнал может быть полезен до того, как вы обнаружите более непосредственную причину, и бесполезен после этого. Переменная может казаться прогностической, потому что она заменяет другую переменную. Байесовская сеть предоставляет язык для явного выражения этих предположений.
Доказательства могут попасть куда угодно.
Стандартный классификатор обычно имеет фиксированное направление. Вы подаете на вход признаки и получаете прогноз.
Байесовская сеть более гибкая. Доказательства могут поступать в любую точку графа, и убеждения обновляются по всей системе.
В модели мокрой травы, если мы наблюдаем мокрую траву, наша вера в дождь возрастает. Наша вера в работу дождевальных установок также возрастает. Этот эффект дал нам доказательства его возможных причин.
Это диагностическое мышление:
- P(Дождь | Влажная трава)
Теперь предположим, что мы узнаем, что дождь точно шел.
В качестве объяснения необходимость использования дождевателя становится менее очевидной. Вероятность его появления может снизиться по сравнению с моментом, когда единственным доказательством была мокрая трава. Это называется «оправданием».
До появления мокрой травы дождь и полив могут быть независимыми или слабо связанными между собой факторами. После появления мокрой травы они становятся взаимосвязанными благодаря общему эффекту. Наличие доказательств одной причины уменьшает необходимость в другой. Эта закономерность наблюдается повсюду.
Повышенная температура делает более вероятными как грипп, так и COVID-19. Положительный тест на грипп может снизить вероятность того, что для объяснения лихорадки также необходим COVID-19, в зависимости от остальной части модели. Пропущенные платежи могут быть объяснены макроэкономическим стрессом, личной чрезвычайной ситуацией или и тем, и другим. Наличие доказательств в пользу одного объяснения изменяет вероятность другого.
Это еще одна причина, по которой байесовские сети полезны для структурированного рассуждения. Они поддерживают рассуждения в нескольких направлениях. Причины предсказывают следствия, следствия указывают на причины, а объяснения конкурируют друг с другом.
Байесовские сети полезны, когда вопрос не имеет четкого ответа.
В этом заключается практическое отличие от логистической регрессии или SVM. Модель логистической регрессии обычно строится для одного условного вопроса:
- P(Y = 1 | X)
Метод опорных векторов (SVM) по своей сути похож, хотя по умолчанию менее вероятностный. Он пытается найти границу принятия решения, которая хорошо разделяет классы.
Эти модели часто оказываются именно тем, что вам нужно. Если задача состоит в том, чтобы «предсказать дефолт на основе этого вектора признаков», то регуляризованная логистическая регрессия является надежным базовым вариантом, а модель бустированного дерева может быть более подходящим кандидатом для внедрения в производство.
Байесовская сеть становится интересной, когда задача приобретает более структурированную форму.
Предположим, мы моделируем кредитный риск. Экономические условия могут повлиять на потерю работы. Потеря работы может повлиять на просроченные платежи. Процентные ставки могут повлиять на платежеспособность. Просроченные платежи могут повлиять на риск неплатежа.
Теперь возникает не один полезный вопрос. Возможно, вы захотите спросить:
- P(Просроченные платежи | Несвоевременные платежи)
- P(Потеря работы | Пропущенные платежи)
- P(По умолчанию | Потеря работы, без пропущенных платежей)
- P(Пропущенные платежи | Экономические условия)
- P(Default | do(InterestRates = high))
Последний вопрос смещает акцент в сторону причинно-следственного моделирования и требует более строгих допущений, но суть остается прежней: на этом этапе модель делает больше, чем просто одностороннее предсказание. Она представляет собой структурированную неопределенную систему.
Полезное эмпирическое правило:
Реальный пример: байесовские сети для визуального наблюдения.
Полезный пример из реальной жизни можно найти в докторской диссертации Кристофера Тауна «Обработка визуальной информации на основе онтологий», выполненной в компьютерной лаборатории Кембриджского университета. В диссертации рассматривается проблема получения высокоуровневых представлений из визуальных данных путем интеграции различных типов данных и включения априорных знаний. В ней разработана структура вывода для компьютерного зрения, основанная на онтологиях и онтологических языках.

Данная задача хорошо подходит для байесовских сетей, поскольку видеозаписи с камер наблюдения содержат множество неопределенных промежуточных фактов.
На низком уровне система машинного зрения может обнаруживать пятна, контуры, следы, положения объектов, модели движения и внешние признаки. Эти признаки содержат шум. Трекер может на короткое время потерять из виду человека. Тень может выглядеть как движение. Два человека могут слиться в одно пятно. Детектор объектов может выдать правдоподобную, но неопределенную метку.
На высоком уровне системе может потребоваться вывести больше семантических фактов:
- Этот предмет — человек?
- Этот человек идёт, стоит, входит, выходит или встречается с кем-то?
- Это нормальное движение или подозрительное событие?
- Какие объекты участвуют в одном и том же сценарии?
Плоский классификатор можно обучить предсказывать одну метку на основе набора визуальных признаков. Схема Тауна более структурирована. Онтология определяет словарь предметной области: объекты, состояния, роли, события, ситуации и сценарии. Затем байесовская сеть предоставляет вероятностный слой, который связывает зашумленные визуальные данные с этими интерпретациями более высокого уровня.
Полезный шаблон моделирования:
- Визуальные описания → Состояния объектов → События → Сценарии
Например, система может заметить, что движущийся объект имеет определенный размер, форму, траекторию и внешний вид. Эти визуальные описания подтверждают, что объект — это человек. Траектория движения человека и его близость к другим объектам позволяют определить, идет ли он, ждет, приближается, встречается или уходит. Затем эти выведенные состояния используются для присвоения меток событиям и сценариям более высокого уровня.
Важно отметить, что каждый слой является неопределенным. Модель представляет собой промежуточную структуру интерпретации.
В данном случае байесовская сеть вполне уместна, поскольку данные могут поступать на разных уровнях. Надежная траектория может укрепить гипотезу об объекте. Известная роль объекта может изменить интерпретацию характера движения. Высокоуровневый сценарий может сделать некоторые интерпретации более низкого уровня более правдоподобными, чем другие.
Это тот же принцип, что и в примере с мокрой травой, но в более сложной обстановке. Мокрая трава свидетельствует о дожде или работе дождевателя. На видеозаписи с камер наблюдения шум, форма, характер движения и пространственное положение свидетельствуют о состоянии объекта или событии. Как только одно объяснение становится более вероятным, другие объяснения могут стать менее необходимыми.
Работа Тауна также является хорошим примером того, почему структура графа имеет значение. Онтология обеспечивает структуру предметной области: какие типы сущностей существуют, какие состояния и события имеют значение и какие отношения допустимы. Байесовская сеть предоставляет вероятностный механизм: как объединять данные, обрабатывать неопределенность и выводить высокоуровневые метки из зашумленных наблюдений.
Это делает его полезным практическим примером, поскольку он находится между экспертными системами, созданными вручную, и обычным обучением с учителем. Он использует знания предметной области, но также обучается на размеченном видео. Он использует визуальные детекторы, но не рассматривает их результаты как достоверные. Он распознает ситуации высокого уровня, но достигает их через цепочку неопределенных промежуточных переменных.
Байесовские сети полезны, когда мы хотим связать зашумленные данные со структурированной интерпретацией мира.
Скрытая цена: кто-то должен поверить графику.
Сила байесовской сети заключается в её структуре. Опасность также исходит от структуры.
В модели мокрой травы мы делаем предположения.
Мы утверждаем, что в этом мире игрушек у мокрой травы нет других прямых причин. Мы утверждаем, что облачность влияет на мокрую траву только через дождь и полив. Мы утверждаем, что стрелки указывают на соответствующие зависимости.
В небольших примерах это кажется очевидным. В реальных системах это сложнее. Кто определяет структуру графа?
Иногда его определяют эксперты. Иногда он формируется на основе данных. Часто это сочетание того и другого. Графы, созданные экспертами, могут быть интерпретируемыми, но предвзятыми. Графы, сформированные на основе данных, могут быть нестабильными, особенно когда переменные коррелированы, данных мало или причинно-следственная связь неясна.
Это одна из причин, почему байесовские сети требуют большей дисциплины в моделировании, чем стандартные сети с учителем. Необходимо тщательно продумывать переменные, стрелки, пропущенные причины, ошибки измерений и предположения об условной независимости.
Как оцениваются вероятности
До сих пор мы рассматривали вероятности в байесовской сети так, как если бы они были просто записаны. В примере с мокрой травой мы использовали значения типа P(Дождь) = 0,2 и P(Мокрая трава | Дождь, Полив) = 0,99. Эти числа должны откуда-то браться.
В байесовской сети обычно возникают две задачи обучения.
- Структурное обучение определяет, какие переменные взаимосвязаны.
- В процессе обучения параметров оцениваются вероятности или распределения, присвоенные каждому узлу.
Структура — это граф. Параметры — это локальные вероятностные модели. После выбора графа обучение параметров означает оценку каждого локального члена:
- P(Xᵢ | Parents(Xᵢ))
Это одно из практических преимуществ байесовских сетей: одна большая задача оценивания превращается в набор меньших локальных задач оценивания.
Категориальные переменные
Для категориальных переменных обучение параметров обычно подразумевает заполнение таблицы условных вероятностей.
Например, для конфигурации WetGrass | Rain, Sprinkler требуется одна строка для каждой родительской конфигурации:
Если у нас есть данные с метками, мы оцениваем каждую строку путем подсчета. Среди всех примеров, где Rain = true и Sprinkler = false, подсчитайте, как часто трава была мокрой:
- P(WetGrass = true | Rain = true, Sprinkler = false) = count(WetGrass = true, Rain = true, Sprinkler = false) / count(Rain = true, Sprinkler = false)
Если мы рассмотрим 90 случаев мокрой травы из 100 примеров с дождем и без полива, то оценка составит 0,9.
Принцип прост: для каждой родительской конфигурации берётся соответствующий фрагмент данных, и оценивается распределение дочерних элементов внутри этого фрагмента. На языке Python:
from collections import defaultdict def estimate_binary_cpt(rows, child, parents): counts = defaultdict(lambda: {"total": 0, "true": 0}) for row in rows: parent_values = tuple(row[parent] for parent in parents) counts[parent_values]["total"] += 1 if row[child] is True: counts[parent_values]["true"] += 1 cpt = {} for parent_values, values in counts.items(): cpt[parent_values] = values["true"] / values["total"] return cpt
Для категории, содержащей более двух значений, применяется тот же принцип. Подсчитайте значения в каждой категории и нормализуйте их так, чтобы сумма значений в каждой строке равнялась единице.
Сглаживание
Простой подсчет может давать сбои при недостатке данных. Если родительская конфигурация встречается один раз, оценка получается неточной. Если она никогда не встречается, оценка неопределена.
Распространенное решение — сглаживание. Для бинарной переменной вместо:
- count(true) / count(total)
использовать:
- (count(true) + α) / (count(total) + 2α)
Когда α = 1, это сглаживание Лапласа. Оно предотвращает получение точных нулевых или единичных вероятностей из очень маленьких выборок.
Это важно, потому что таблицы условных вероятностей быстро растут. Если у категориального узла k возможных значений, а у его родителей m возможных конфигураций, то таблица содержит примерно m(k − 1) свободных параметров. По мере роста числа родителей данные становятся разреженными. Это одна из причин, почему байесовские сети обычно предпочитают разреженные наборы родителей.
Непрерывные переменные
Для непрерывных переменных требуется локальная модель плотности, а не таблица. Для непрерывного узла без родителей простым выбором является гауссово распределение:
- X ~ Normal(μ, σ²)
Обучение параметров подразумевает оценку μ и σ² на основе данных. Оценки максимального правдоподобия представляют собой выборочное среднее и дисперсию.
Если у непрерывного потомка родители относятся к категориальной группе, мы можем оценить отдельное гауссово распределение для каждого состояния родителя. Например:
- Температура | Грипп = истинно ~ Нормально (μ₁, σ₁²)
- Температура | Грипп = ложь ~ Норма (μ₀, σ₀²)
Таким образом, модель обучается одному распределению температуры для случаев гриппа и другому для случаев, не связанных с гриппом.
Если и ребенок, и родители являются непрерывными переменными, то распространенным выбором является линейная гауссова модель. Например:
- Артериальное давление | Возраст, ИМТ
Это можно смоделировать следующим образом:
- Артериальное давление = β₀ + β₁ Возраст + β₂ ИМТ + ε
где:
- ε ~ Normal(0, σ²)
Локальное условное распределение имеет следующий вид:
- Артериальное давление | Возраст, ИМТ ~ Нормальный (β₀ + β₁ Возраст + β₂ ИМТ, σ²)
Теперь оценка параметров выглядит как обычная линейная регрессия. Байесовская сеть по-прежнему факторизует совместное распределение, но один локальный фактор представляет собой регрессионную модель.
Каждый узел имеет локальную прогностическую модель, обусловленную его родителями. Для дочерних узлов с категориальными переменными эта локальная модель часто представляет собой таблицу условных вероятностей. Для дочерних узлов с непрерывными переменными это может быть гауссово распределение, линейное гауссово распределение или другая модель условной плотности распределения.
Отсутствующие данные
Если все переменные присутствуют в обучающих данных, обучение параметров в основном сводится к подсчету, усреднению или построению локальных регрессий. Если переменные скрыты или отсутствуют, мы часто используем алгоритм ожидания-максимизации (EM). Примерная идея такова:
- Начнём с первоначальных предположений о параметрах.
- Используйте текущую модель для определения вероятных значений отсутствующих переменных.
- Переоцените параметры, используя полученные значения.
- Повторяйте до стабилизации параметров.
Это полезно, когда некоторые важные переменные являются скрытыми, наблюдаются частично или регистрируются непоследовательно. Например, мы можем наблюдать симптомы и результаты анализов, но не истинное состояние заболевания у каждого пациента.
График не отменяет необходимости в статистической оценке. Он делает оценку модульной.
Три основные структуры
Большая часть интуитивного понимания байесовских сетей основана на трех небольших закономерностях.
1. Цепь
Цепь имеет следующую форму:
- А → В → С
Например, заболевание может влиять на биомаркер, а биомаркер может влиять на результат анализа. В данном случае А влияет на С через В. Если мы знаем В, то А может уже ничего дополнительного не рассказать о С:
- А ⟂ С | Б
Как только становится известна промежуточная переменная, переменная, находящаяся выше по потоку, отделяется от переменной, находящейся ниже по потоку.
2. Вилка
Вилка имеет следующую форму:
- А → В
и:
- А → С
Например, жаркая погода может увеличить как продажи мороженого, так и количество солнечных ожогов.
Продажи мороженого и солнечные ожоги могут быть взаимосвязаны, но эта связь объясняется общей причиной. Если мы добавим фактор погоды, связь может исчезнуть:
- B ⟂ C | A
Это закономерность, имеющая общие причины.
3. Коллайдер
Коллайдер имеет следующую форму:
- А → С ← В
Например, и дождь, и поливальная установка могут привести к намоканию травы. В данном случае всё иначе. Если мы не наблюдаем C, то A и B могут быть независимыми. Как только мы наблюдаем C, они становятся зависимыми.
Мокрая трава связывает дождь и полив. Лихорадка связывает возможные болезни. Решение о найме связывает талант и удачу. Пробка на дороге связывает аварии и дорожные работы.
Это типичная модель объяснения происходящего.
Коллайдер — это также структура, которая чаще всего сбивает людей с толку. Обусловливание общим эффектом может создать зависимость там, где её раньше не было.
Это является источником многих проблем, связанных с систематической ошибкой отбора.
Если рассматривать только успешные стартапы, то качество основателя и рыночная удача могут казаться отрицательно взаимосвязанными. Компания может попасть в число «успешных» благодаря исключительной реализации, удачному выбору времени для выхода на рынок или сочетанию того и другого. Зависимость от успеха может привести к конкуренции между этими факторами.
График позволяет нам это увидеть.
Умозаключение — это распространение убеждений, а не структурирование.
После того как у нас есть граф и локальные таблицы вероятностей, вывод сводится к ответам на такие вопросы, как:
- P(Дождь | Влажная трава)
- P(Default | MissedPayments, JobLoss)
- P(Заболевание | Симптомы, Результат теста)
Механика процесса может быть довольно сложной: исключение переменных, распространение доверия, деревья соединений, методы выборки. Но интуитивное понимание довольно простое.
В граф поступают данные. Убеждения обновляются локально. Эти обновления распространяются через связанные переменные, ограниченные условной независимостью, закодированной в структуре.
В древовидных графах это может быть эффективно и точно. В плотных или иглообразных графах вывод может стать дорогостоящим. Это еще одно практическое ограничение. Байесовские сети элегантны, но точный вывод не всегда дешев.
Тем не менее, концептуальная польза сохраняется. График позволяет проверить ход рассуждений. Часто можно объяснить, почему изменилась та или иная вероятность:
- Наблюдается влажная трава.
- Вероятность дождя возросла.
- Вероятность срабатывания спринклерной системы возросла.
- Затем подтвердился дождь.
- Вероятность срабатывания спринклерной системы частично объяснена.
Подобное объяснение гораздо сложнее получить с помощью чисто дискриминативного классификатора.
Что такое дерево соединений
Точный вывод в байесовской сети может стать затруднительным, когда граф содержит много взаимодействующих переменных.
В простой цепочке данные могут передаваться эффективно по графу. В более сложных сетях граф может содержать петли, если не учитывать направление стрелок. Эти петли затрудняют локальную передачу сообщений, поскольку информация может циркулировать и учитываться более одного раза.
Дерево соединений — это способ реорганизации графа, позволяющий осуществлять точный вывод.
Идея заключается в следующем:
- Возьмите исходную графическую модель, сгруппируйте тесно связанные переменные в кластеры и расположите эти кластеры в виде дерева.
- Каждый кластер называется кликой. Вместо передачи сообщений между отдельными переменными, алгоритм передает сообщения между кластерами переменных.
Предположим, у нас есть четыре переменные:
- А, В, С, Г
и модель имеет следующие зависимости:
- А → В
- А → С
- Б → Д
- C → D
Иными словами, А влияет на В и С, а затем и В, и С влияют на D. Байесовская сеть факторизуется следующим образом:
- P(A, B, C, D) = P(A) P(B | A) P(C | A) P(D | B, C)
Это небольшая сеть, но в ней уже есть замкнутый контур, если не учитывать направление стрелок:
- A − B − D − C − A
Такой замкнутый цикл делает точный вывод менее прямолинейным, чем в простой цепочке. Например, предположим, что мы наблюдаем:
- D = истина
и хотят вычислить:
- P(A | D = true)
Доказательства относительно D должны пройти в обратном направлении через B и C, а затем объединиться в A. Эти два пути связаны, потому что B и C имеют общего родителя A.
Дерево соединений решает эту задачу, группируя переменные в клики. Для данной модели полезным набором клик являются:
- (A, B, C)
и:
- (B, C, D)
Дерево соединений выглядит следующим образом:
- (A, B, C) − (B, C, D)
Пересечение между двумя группами составляет:
- (B, C)
Это перекрытие называется разделителем.
Теперь идея стала понятнее. Одна группа отвечает за часть модели, включающую A, B и C. Другая группа отвечает за часть, включающую B, C и D. Они общаются через общие переменные: B и C.
Две таблицы клик можно представить следующим образом:
- ψ₁(A, B, C)
и:
- ψ₂(B, C, D)
Доказательство D = истина поглощается второй кликой, поскольку D находится там. Затем вторая клика отправляет сообщение первой клике.
Сообщение — это всего лишь сводная таблица. В ней говорится:
- Исходя из всего, что мне известно о моей стороне графика, вот что я могу сказать о переменных, которые мы разделяем.
Правая клика не может отправить весь свой стол левой клике, потому что в левой клике нет группы D. Единственными общими языками для обеих клик являются B и C.
Таким образом, вторая клика сжимает все свои знания в таблицу, касающуюся только пунктов B и C:
- m₂→₁(B, C) = сумма по D от ψ₂(B, C, D)
Если значение D было обнаружено, скажем, D = true, то несовместимые значения D игнорируются. В этом случае сообщение по сути следующее:
- m₂→₁(B, C) = ψ₂(B, C, D = true)
Сообщение может выглядеть примерно так:
В этой таблице указано, что при условии D = true правая клика считает комбинацию B = true, C = true наиболее правдоподобной.
Затем левая клика объединяет это сообщение со своей собственной локальной таблицей по A, B, C.
Предположим, таблица левых клик выглядит следующим образом:
Сообщение используется путем умножения каждой строки на значение сообщения для пары B, C этой строки:
Теперь просуммируйте суммарные баллы для каждого значения А.
Если A = false:
- 0,020 + 0,060 + 0,060 + 0,090 = 0,230
Если A = true:
- 0,005 + 0,040 + 0,090 + 0,720 = 0,855
Таким образом, ненормализованное убеждение выглядит следующим образом:
Теперь проведите нормализацию:
- P(A = true | D = true) = 0,855 / (0,855 + 0,230) = 0,788
- P(A = ложно | D = истинно) = 0,230 / (0,855 + 0,230) = 0,212
Таким образом, получив сообщение от правой клики, левая клика делает вывод:
Это миниатюрная версия идеи дерева соединений. Доказательства относительно D преобразуются в сообщение, охватывающее B и C. Левая клика объединяет это сообщение со своей локальной связью между A, B и C. Затем она суммирует B и C, чтобы получить убеждение относительно A.

Этот метод точен, но имеет свою цену. Каждой клике нужна таблица со всеми её переменными. Если A, B, C и D — бинарные переменные, то каждая клика с тремя переменными имеет 2³ = 8 состояний, что очень мало. Если дерево соединений создаёт клику с 20 бинарными переменными, то эта клика будет иметь 2²⁰ = 1 048 576 состояний. В этом и заключается компромисс. Деревья соединений делают точный вывод систематизированным, но они практичны только тогда, когда самая большая клика не слишком велика. Размер самой большой клики связан со свойством графа, называемым шириной дерева. Графы с низкой шириной дерева могут обрабатываться эффективно. Графы с высокой шириной дерева могут сделать точный вывод невозможным.
Практический вывод заключается в том, что с байесовскими сетями проще рассуждать, когда граф разрежен, а зависимости локальны. Граф — это не просто объяснительный объект. Он влияет на то, насколько вычислительно осуществим вывод.
Генеративный и дискриминативный подходы — это разные методы моделирования.
Это полезный способ размещения байесовских сетей среди других моделей машинного обучения.
Байесовская сеть обычно является генеративной моделью. Она пытается смоделировать, как переменные в определенной области совместно возникают. Логистическая регрессия или SVM обычно являются дискриминативными моделями. Они моделируют граничные или условные отношения, необходимые для прогнозирования.
Дискриминационная формулировка:
- P(Y | X)
Генеративное формирование контекста:
- P(X, Y)
или, в более общем смысле:
- P(X₁, …, Xₙ)
Генеративные модели часто требуют больше работы, поскольку они моделируют большую часть окружающего мира. Эта дополнительная структура может быть полезна, когда необходимо обрабатывать недостающие данные, рассуждать от следствий к причинам, моделировать сценарии или учитывать знания предметной области.
Дискриминативные модели часто хорошо подходят для решения узких задач прогнозирования, поскольку они используют свои ресурсы непосредственно для принятия важного для вас решения. Ключевой вопрос: вы пытаетесь предсказать метку или представить систему?
Для многих задач обучения с учителем начинайте с модели, предназначенной для обучения с учителем. В условиях структурированной неопределенности байесовские сети становятся более интересными.
Небольшой медицинский пример.
Предположим, мы моделируем грипп, лихорадку, кашель и усталость. Предположение простое: грипп может вызывать лихорадку, кашель и усталость.
Разложение на множители выглядит так:
- P(Грипп, Лихорадка, Кашель, Усталость) = P(Грипп) P(Лихорадка | Грипп) P(Кашель | Грипп) P(Усталость | Грипп)
Это простая диагностическая модель. Если мы наблюдаем лихорадку и кашель, вероятность гриппа возрастает:
- P(Грипп | Лихорадка, Кашель)
Если мы также наблюдаем отрицательный результат теста на грипп, вероятность заболевания гриппом снижается. Если результаты теста неоднозначны, вероятность может не упасть до нуля. Если мы также наблюдаем усталость, вероятность может снова возрасти.
Одна и та же модель может отвечать на разные вопросы в зависимости от имеющихся данных. В этом и заключается важный момент.
Для классификатора обычно требуется фиксированный вектор признаков, состоящий из лихорадки, кашля, усталости, результатов анализов и любых других доступных предикторов. Это может быть проще и точнее, если все признаки присутствуют, и единственный вопрос — прогнозирование гриппа. Байесовская сеть предоставляет более структурированный объект. Она может представлять надежность тестов, отсутствующие симптомы, общие причины и конкурирующие диагнозы.
Теперь продолжим пример. Грипп может вызывать лихорадку и кашель. COVID также может вызывать лихорадку и кашель.
Теперь лихорадку и кашель можно объяснить разными заболеваниями. Наблюдение за симптомами повышает уверенность в обоих диагнозах. Подтверждение одного диагноза изменяет вероятность другого. Именно такие рассуждения и были призваны выражать байесовские сети.
Где вступают в действие сети Маркова
Байесовские сети используют направленные ребра. Стрелки имеют значение. Они поддерживают естественную картину локальной условной зависимости, а иногда и причинно-следственную интерпретацию, если граф был построен таким образом.
В некоторых областях существуют взаимосвязи, направление которых трудно определить. Рассмотрим шумоподавление изображений. Соседние пиксели, как правило, имеют схожие метки. Если один пиксель находится на переднем плане, то его соседи с большей вероятностью тоже будут находиться на переднем плане. Какой пиксель на что влияет? Обычно ни один из них. Взаимосвязь симметрична. Соседние метки взаимно совместимы.
Именно здесь сети Маркова, также называемые марковскими случайными полями, становятся естественными.
Сеть Маркова — это неориентированная графическая модель. Вместо стрелок и таблиц условных вероятностей она использует функции совместимости для связанных групп переменных.
Для простой цепочки из трех переменных A, B и C, где A соединена с B, а B соединена с C, мы можем записать:
- P(A, B, C) = (1 / Z) φ₁(A, B) φ₂(B, C)
Функции φ — это потенциалы. Сами по себе они не являются вероятностями. Это оценки, показывающие, насколько совместимы определенные назначения. Например:
Это означает, что А и В предпочитают иметь одинаковое значение. Член Z — это функция распределения. Она нормализует все ненормализованные показатели совместимости в правильное распределение вероятностей:
- Z = сумма по A, B, C от φ₁(A, B) φ₂(B, C)
Такая нормализация часто обходится дорого. В больших сетях Маркова вычисление Z может быть одной из главных трудностей.
Байесовские сети генерируют; марковские сети ограничивают.
Полезное интуитивное представление заключается в следующем:
- Байесовская сеть описывает, как переменные генерируются из своих родительских элементов.
- Сеть Маркова описывает, какие конфигурации переменных являются совместимыми.
Для байесовской сети медицинский пример кажется естественным: болезнь влияет на симптомы. Для сети Маркова пример с изображением кажется естественным: метки соседних пикселей, как правило, совпадают.
Байесовская сеть воспринимается как причинно-следственная или диагностическая модель. Сеть Маркова же воспринимается как система мягких ограничений.
Это различие не является абсолютным. Байесовские сети могут представлять некаузальную структуру, а сети Маркова могут использоваться во многих ситуациях, выходящих за рамки пространственных ограничений. Но в качестве первой ментальной модели она полезна.
Используйте байесовскую сеть, когда направление имеет значение. Облачность влияет на дождь. Дождь влияет на мокрую траву. Болезнь влияет на симптомы. Экономический стресс влияет на просроченные платежи.
Используйте сеть Маркова, когда совместимость более естественна, чем направление. Соседние пиксели обычно должны совпадать. Соседние слова должны иметь совместимые метки. Близлежащие местоположения должны иметь схожие состояния.
Условные случайные поля относятся к этому семейству. Модели условных случайных полей:
- P(Y | X)
где Y обычно представляет собой структурированный результат, например, последовательность меток, а X — наблюдаемый входной сигнал. Они стали популярны для таких задач, как распознавание именованных сущностей, прежде чем нейронные модели последовательностей заняли значительную часть этой области.
По-прежнему актуален концептуальный аспект: иногда прогнозирование имеет структурированный характер, и метки следует моделировать совместно.
Где уместна логика Маркова
В этом семействе есть еще один полезный шаг: марковская логика. Сеть Маркова предоставляет нам мягкие ограничения совместимости между переменными. Марковская логика добавляет язык для записи этих ограничений в виде правил.
Например:
- Друзья(x, y) → Похожие предпочтения(x, y)
или:
- WorksAt(x, c) AND LocatedIn(c, city) → LivesNear(x, city)
В обычной логике правила хрупки. Правило может быть истинным или ложным. Если правило нарушено, мир становится недействительным.
В реальных условиях такое поведение встречается редко. Друзья часто разделяют одни и те же предпочтения, но не всегда. Люди часто живут рядом с работой, но не всегда. Клиенты, которые постоянно жалуются, с большей вероятностью уйдут, но не всегда. Это полезные закономерности, а не законы.
В сетях марковской логики правилам присваиваются веса. Правило с высоким весом указывает на сильное предпочтение. Правило с низким весом указывает на слабое предпочтение. Миры, удовлетворяющие многим правилам с высоким весом, имеют более высокую вероятность. Миры, нарушающие эти правила, остаются возможными, но менее вероятными.
Обычно используется следующий формат:
- P(X = x) = (1 / Z) exp(сумма по i из wᵢ nᵢ(x))
где:
- wᵢ — это вес правила i
- nᵢ(x) — это количество раз, когда правило i выполняется в мире x.
- Z — это функция распределения.
Логика проста: миры, удовлетворяющие множеству правил с высоким весом, имеют более высокую вероятность существования.
Предположим, мы пишем:
- w: Smokes(x) AND Friends(x, y) → Smokes(y)
Это не означает, что друзья обязательно должны иметь схожее поведение в отношении курения. Это означает, что при прочих равных условиях миры, в которых друзья имеют схожее поведение в отношении курения, должны быть более вероятны, чем миры, в которых эта тенденция неоднократно нарушается.
Это идея сети Маркова, выраженная логически. Правила определяют мягкие ограничения. Веса показывают, насколько важно каждое ограничение. Полученное распределение вероятностей представляет собой сеть Маркова, основанную на объектах и отношениях в данной области.
Это становится полезным, когда предметная область имеет реляционную структуру: люди, организации, продукты, документы, ссылки, транзакции, счета, устройства, события. Одно и то же правило может применяться многократно ко многим сущностям.
Например:
- Mentions(Document, Company) AND Acquires(Company, Target) → Relevant(Document, Target)
Такую закономерность сложно выразить в виде плоского вектора признаков. Логика Маркова позволяет напрямую записать реляционную закономерность, сохраняя при этом неопределенность.
Это естественное развитие событий:
- Байесовские сети представляют собой направленную зависимость.
- Сети Маркова представляют собой неориентированную совместимость.
- Сети марковской логики представляют взвешенные логические правила в виде неориентированной вероятностной структуры.
Это мост от графических моделей к вероятностной логике и представлению знаний.
Почему это всё ещё важно
Легко воспринимать байесовские сети и сети Маркова как устаревшие механизмы, существовавшие до современной нейронной эры. В некоторых производственных средах это вполне оправданное предположение. Однако, если у вас огромный размеченный набор данных и узкая задача прогнозирования, эти методы редко используются в первую очередь.
Основные идеи, лежащие в их основе, остаются центральными. Они дают нам дисциплинированный способ осмысления неопределенности, структуры, доказательств, независимости, объяснения и реляционного мышления. Они заставляют нас задавать вопросы, которые обычное контролируемое обучение может скрывать:
- Какова цель?
- Каковы причины?
- Каковы последствия?
- Какие переменные становятся неактуальными после того, как другие становятся известны?
- Куда могут поступать доказательства в систему?
- Мы предсказываем что-то одно или рассуждаем о многом?
- Являются ли эти отношения направленными, симметричными или подчиняющимися определенным правилам?
Эти вопросы важны даже в том случае, если итоговая модель не является байесовской сетью, сетью Маркова или сетью марковской логики.
В прикладном машинном обучении легко свести мир к матрице признаков и позволить модели самой разобраться в этом. Иногда это именно правильное инженерное решение. Но оно всё равно сопряжено с определёнными предположениями. Эти предположения влияют на конвейер обработки данных, набор признаков, процесс выборки и уровень интерпретации.
Графические модели вновь выявляют эти предположения. В этом и заключается их непреходящая ценность.
Практический вывод
Логистическую регрессию следует использовать, если необходим простой и понятный классификатор.
Используйте SVM, когда вам нужна надежная граница принятия решений, особенно в задачах среднего размера с высокой размерностью.
Используйте бустинг деревьев решений или нейронные сети, когда основной целью является повышение точности прогнозирования и у вас достаточно данных.
Используйте байесовскую сеть, когда вам нужно рассуждать о структурированной неопределенной системе, особенно когда данные могут поступать из разных источников, важны знания в предметной области, часто встречаются пропущенные данные или объяснение является частью работы.
Сеть Маркова следует использовать в тех случаях, когда взаимосвязи меньше связаны с направлением и больше с совместимостью, согласием или неявными ограничениями между соседними переменными.
Используйте логику Маркова, когда предметная область содержит объекты, отношения и несовершенные правила. Она позволяет выразить реляционные знания, не претендуя на абсолютность каждого правила.
Главное отличие заключается в следующем:
- Классификатор строится на основе вопроса прогнозирования.
- Графическая модель строится на основе неопределенной системы.
- Логика Маркова расширяет эту систему за счет взвешенных правил, применяемых к объектам и отношениям.
Как только это различие становится ясным, байесовские сети, сети Маркова и логика Маркова становятся проще для классификации. Байесовские сети полезны, когда направление имеет значение. Сети Маркова полезны, когда совместимость является лучшим представлением. Логика Маркова полезна, когда эти совместимости проще записать в виде несовершенных правил для объектов и отношений.
Оговорка: Мнения и взгляды, выраженные в этой статье, являются моими собственными и не отражают мнения моего работодателя или каких-либо аффилированных организаций. Содержание основано на личном опыте и размышлениях и не должно рассматриваться как профессиональная или академическая консультация.
📚Ссылки
- Перл, Дж. (1988). Вероятностные рассуждения в интеллектуальных системах: сети правдоподобных выводов. Morgan Kaufmann. Классические основы байесовских сетей, распространения убеждений и вероятностных рассуждений в условиях неопределенности.
- Коллер, Д. и Фридман, Н. (2009). Вероятностные графические модели: принципы и методы. Издательство MIT Press. Стандартный современный учебник по байесовским сетям, сетям Маркова, выводу, обучению и структурированному вероятностному моделированию.
- Таун, К. (2004). Обработка визуальной информации на основе онтологий. Докторская диссертация, Кембриджский университет. Полезный прикладной пример объединения визуальных данных, онтологий и вероятностных рассуждений для понимания сцены.
- Таун, К. (2004). «Байезианские сети, основанные на онтологии, для понимания динамических сцен». Семинар CVPR по обнаружению и распознаванию событий в видео. Компактный пример применения байесовских сетей в реальных условиях для распознавания динамических сцен и событий.
- Ричардсон, М. и Домингос, П. (2006). «Сети марковской логики». Машинное обучение. Основная статья, представляющая марковскую логику: взвешенная логика первого порядка, основанная на марковских сетях.
- Коллер, Д., Фридман, Н., Гетор, Л. и Таскар, Б. (2007). «Графические модели в двух словах». Краткий обзор графических моделей и их роли в статистическом реляционном обучении.
Шон Моран. Все материалы от Шона Морана.
Источник: towardsdatascience.com
Оцените материал:

