Зачем GenAI-ассистенту platform logic: как управлять источниками, evidence и ответами
GenAI-ассистент может довольно быстро начать отвечать «по теме»: находить релевантные фрагменты, собирать уверенный текст и создавать ощущение, что система уже работает.
Если подключить LLM к корпоративным документам через RAG, подобрать параметры поиска, немного почистить контекст и добавить хороший prompt, первые результаты часто выглядят обнадеживающе. Пользователи начинают пробовать систему, появляются первые метрики использования, а сама идея быстро кажется готовой к расширению.
Но для продуктового контура этого недостаточно.
Проблема не только в том, может ли модель сформировать релевантный ответ. Проблема в том, является ли поведение системы ожидаемым, проверяемым и управляемым.
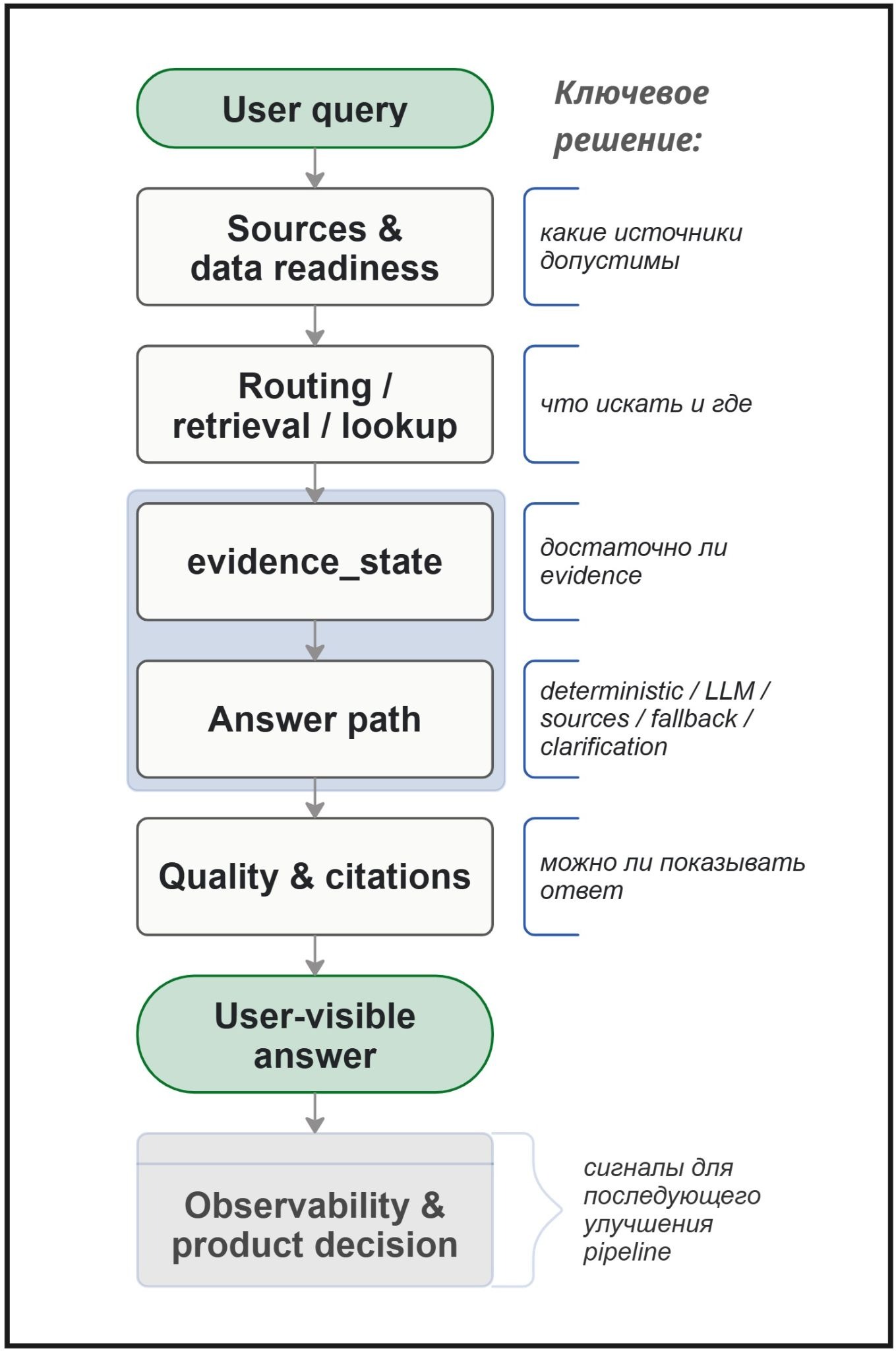
Можно получить ассистента, который уверенно отвечает на вопросы, но при этом плохо контролируется в деталях: какие источники он использовал, достаточно ли найденной информации для ответа, можно ли показывать ответ пользователю, где безопаснее остановиться и дать ограниченный ответ (fallback), как проверяется качество, кто управляет ссылками на источники и что происходит при неполных, устаревших или плохо структурированных данных.
В этой статье я разбираю не готовый «рецепт правильного GenAI-ассистента», а результаты и выводы из проверки на малом контролируемом прототипе: какие решения появляются вокруг GenAI-системы, когда она должна не просто отвечать, а вести себя управляемо.
Фокус будет не на том, как «улучшить prompt» или выбрать модель побольше, а на том, как система управляет ответом после retrieval:
Источник: habr.com
Оцените материал:


Присоединяйтесь и подпишитесь на рассылку самых свежих новостей по Email
Получайте свежие новости и идеи на почту. Без спама — только самое интересное.
Нажимая «Подписаться», вы соглашаетесь с политикой конфиденциальности.