Я разработал бэкенд на C++, чтобы моя видеокарта перестала засасывать воздух.
Как устранить накладные расходы на заполнение и ускорить вывод LLM на аппаратном уровне.
Делиться

Это юмористический, но реалистичный обзор бэкенда WarpGroup — мы рассмотрим упаковку контейнеров с учетом VRAM, передачу данных через закрепленную память и как ускорить работу вашего LLM до 5,89 раз, слегка погрубив PyTorch.
Репозиторий: github.com/AnubhabBanerjee/WarpGroup-backend
Вкратце: стандартная пакетная обработка LLM дополняет короткие последовательности нулями, чтобы они соответствовали самой длинной. Затем ваш графический процессор добросовестно выполняет миллиарды умножений на эти нули, что является вычислительным эквивалентом оплаты повару за приготовление пустой тарелки. WarpGroup-Backend заменяет это небольшим движком на C++, который сжимает последовательности переменной длины вместе, как очень взволнованный чемпион по тетрису. Результат: в 2,08 раза большая пропускная способность на H100 , в 5,89 раза больше на GTX 1080 и ни одного сбоя из-за нехватки памяти. В статье вся история рассказывается с помощью кода, шуток и лишь умеренного количества ругани в адрес NVIDIA.
(Небольшое признание, прежде чем мы начнем: я пришел к этому с инженерного опыта в области 5G/6G RAN. Как оказалось, упаковка графических процессоров в контейнеры поразительно близка к тому, что делает планировщик MAC в вашем телефоне уже два десятилетия. Об этом есть целый раздел ниже — раздел 7 — но именно поэтому я и пишу это.)
1. Признание: большая часть «работы» вашей видеокарты — это обман.
Если вы когда-либо обрабатывали текст переменной длины пакетами с помощью преобразователя, вот что на самом деле происходит, в драматизированной форме:
Вы: «Пожалуйста, кратко изложите содержание этих 8 документов, GPU».
PyTorch: «Конечно. Давайте сначала сделаем их все одинаковой формы».
Вы: «Подождите, это 80, 90, 110, 130, 95, 1850, 2000 и 60 жетонов. Не надо…»
PyTorch: «Всё дополнил до 2000. Удачи!» 🫡
GPU: с удовольствием тратит примерно половину своих вычислительных ресурсов и пропускной способности памяти на заполнение нулями.
Ваш счёт за AWS: *проявляет чувство юмора*
В этом вся шутка. В этом грязный секрет всей индустрии. Данные переменной длины + прямоугольные тензоры = ваша видеокарта получает почасовую оплату за фиктивную работу.
WarpGroup-Backend — это результат того, что вы решили, что с вас хватит, и предпочли бы писать 30% кода на C++, чем продолжать платить за эту ерунду.
2. Зачем вообще нужны отступы? (краткий курс за одну минуту)
Если вы уже знаете ответ, пропустите его. Для всех остальных:
Графический процессор (GPU) обожает прямоугольники . В частности, он обожает матрицы, в которых каждая строка имеет одинаковую длину, потому что это позволяет ему выполнять тысячи одинаковых математических операций параллельно. Именно это делает GPU графическим процессором, а не дорогостоящим пресс-папье.
Но текст — это не прямоугольник. Текст — это беспорядочная мешанина. Один твит — это 12 токенов. Один юридический контракт — это 4000. Если вы хотите пропустить 8 из них одновременно через трансформатор, у вас есть два варианта:
- Дополните их все до самого длинного с помощью токена
- Объедините их в одну длинную одномерную ленту и сообщите ядру внимания: «Эй, пожалуйста, не позволяйте токену 12 взаимодействовать с токеном 4001, они из разных документов». Это внимание переменной длины , и именно для этого существует
flash_attn_varlen_funcиз FlashAttention-2.
Вариант 2, очевидно, лучше, и все большее число используемых в производственных средах для вывода результатов (vLLM, TensorRT-LLM, SGLang, FlashInfer, внутренние механизмы TGI) уже применяют его варианты.
Но вызов функции flash_attn_varlen_func — это простая часть. Сложная часть — та, которую все постоянно переписывают в немного разных вариантах — это организация ленты: определение того, какие документы попадают в какую группу, в каком порядке, до какой общей длины, при этом сохраняя загрузку графического процессора и не создавая накладных расходов на стороне хоста.
WarpGroup-Backend — это та самая часть уравнения, которая отвечает за организацию работы групп, и написана она на C++, что позволяет ей работать быстро.
3. Загадка «просто упакуйте их» (и почему это сложнее, чем кажется)
Суть проста: возьмите очередь последовательностей переменной длины и упакуйте их в контейнеры, как очень напряженная бабушка в день переезда. Каждый контейнер вмещает до N токенов. Вы помещаете столько коротких последовательностей, сколько сможете уместить рядом с каждой большой, а затем отправляете весь контейнер на графический процессор в виде одной плоской ленты.
Это классическая задача упаковки в контейнеры , и её решение, описанное в учебниках, — это метод первого подходящего убывающего порядка (First Fit Decreasing, FFD) :
- Отсортируйте последовательности от самой длинной к самой короткой.
- Для каждой последовательности пройдитесь по открытым контейнерам. Опустите предмет в первый свободный контейнер.
- Если места нет, откройте новый контейнер.
Это тот же алгоритм, который использует ваш мозг при упаковке чемодана: сначала большие камни, затем галька заполняет щели. Он не оптимален, но в худшем случае приближается к оптимальному результату примерно на 22%, при этом его сложность составляет O(n log n), а не достигает тепловой смерти Вселенной.
Вот три вещи, которые отличают этот скрипт от обычного 10-строчного Python-скрипта:
Задача А: Какого размера должен быть контейнер?
Простой ответ: «настолько большой, насколько позволяет объем видеопамяти». Неправильный ответ: это число нельзя найти в интернете. Фактический объем доступной видеопамяти зависит от:
- Размер модели (7B в BF16 занимает около 14 ГБ, прежде чем вы успеете что-либо сделать).
- Кэш активации/KV-кэш-память для этой конкретной длины последовательности (которая масштабируется странным образом).
- Фрагментация распределителя памяти в PyTorch (искусство, а не наука).
- Чихнули ли вы на водителя?
Это невозможно вычислить. Это нужно измерить . Нулевая фаза WarpGroup — это буквально «собеседование с графическим процессором»: заставляйте его обрабатывать всё более крупные последовательности, пока не произойдёт ошибка нехватки памяти (OOM), а затем снижайте нагрузку на 10% для безопасности.
Проблема B: Графические процессоры очень привередливы в еде (из-за ограничения в 16 токенов).
Тензорные ядра NVIDIA выполняют инструкции умножения-накопления матриц (MMA) для фиксированных форм тайлов — например, m16n8k16 на Hopper, при этом точные размеры варьируются в зависимости от типа данных и архитектуры. Практическая эвристика, вытекающая из всей этой сложности, удивительно проста: ядра GPU (включая FlashAttention-2) достигают максимальной эффективности, когда размеры, связанные с последовательностью, кратны 16 (иногда 8, в зависимости от типа данных и архитектуры). Поэтому мы округляем длину каждой последовательности в большую сторону: 137 → 144, 200 → 208. Дело не в том, что GPU буквально не может обработать последние 9 токенов — дело в том, что оставление их в таком неопределенном состоянии обходится дорого из-за объединения памяти, разбиения на тайлы и форм GEMM, которые действительно нужны нижестоящим ядрам.
Это самая нелепая часть всего процесса, и тем не менее, игнорирование этого приводит к ощутимым потерям производительности.
Проблема C: Python слишком медленный для выполнения этого в цикле обработки событий.
Я люблю Python. У меня на душе вытатуирована import this . Но в Python есть GIL , глобальная блокировка интерпретатора, которая, по сути, является вышибалой, пропускающей в «ночной клуб Python» только один поток одновременно. Пока Python занят токенизацией PDF-файлов, он не может одновременно заниматься упаковкой контейнеров. Пока он упаковывает контейнеры, он не может быть занят подачей данных на графический процессор. Конвейер «производитель-потребитель» сворачивается в медленную, печальную линию из одного файла.
Решение: выполняйте упаковку на C++ , в фоновом потоке , и освобождайте GIL на границе PyBind11, чтобы сторона Python могла продолжать токенизацию, пока C++ продолжает упаковку. Теперь у вас есть настоящий параллелизм. Вышибала впускает двух друзей одновременно. Наслаждайтесь!
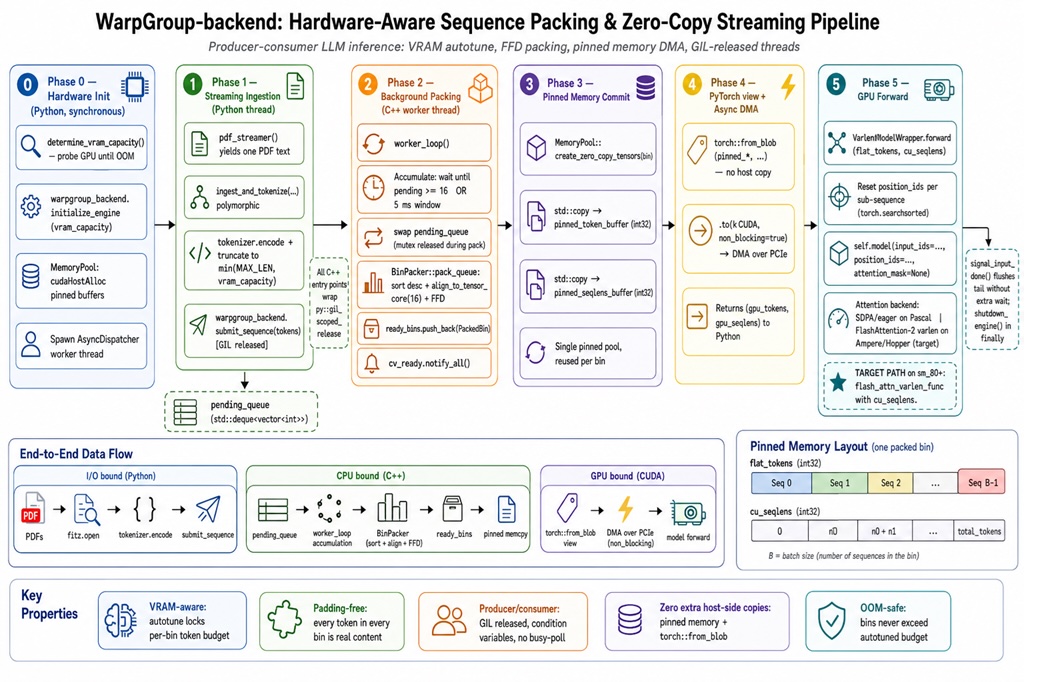
4. Пятифазный трубопровод (самая интересная часть)
Вот высокоуровневая архитектура, с шутками:
Этап 0: Эмпирическое измерение объема оставшейся видеопамяти у модели. (Python)
Этап 1: Токенизация текста и вывод целых чисел за пределы C++. (Python → C++)
Этап 2: Обработка запросов в потокобезопасной очереди без проблем с GIL (асинхронный диспетчер на C++).
Этап 3: Сортировка, выравнивание и размещение в одномерные контейнеры с помощью «тетриса». (Упаковщик контейнеров на C++)
Этап 4: Передача файлов в пул памяти графическому процессору через асинхронный DMA с закрепленной памятью. (Пул памяти C++)
Этап 5: FlashAttention-2 наслаждается своим обедом без заполнения. (PyTorch)
Давайте разберем каждый пример с реальным кодом. Я буду приводить короткие фрагменты; полные файлы доступны по ссылкам.
Этап 0 — Собеседование на должность, связанную с графическим процессором.
Нам нужно точно знать, сколько токенов помещается в видеопамять. Поэтому мы вежливо, но настойчиво просим об этом графический процессор, пока он не заплачет.
Этот код находится в файле streaming_dataloader.py :
def determine_vram_capacity(model, device, start_tokens=0, step_size=5000, vocab_size=32000): """ Phase 0: this method detects the device (GPU) on which it is currently hosted, loads the model into the VRAM, see how much space is left and how many tokens can be fit into the remaining space of the VRAM. It then increments the number of tokens by the step size and repeats the process until the max capacity is reached. It returns the maximum number of tokens that can be fit into the VRAM while the model is loaded. """ # this part loads the model into the VRAM and checks if it can be loaded. if it can, it's okay. if it cannot be done, # it raises an error. try: model.to(device) except Exception: sys.exit("error loading model into VRAM") print("nStarting Phase 0: model loaded successfully in VRAMnn") # this part checks how much space is left, after the model is loaded, in terms of number of tokens # Probe remaining capacity by running synthetic forwards until CUDA OOM; then scale down by 0.9 for fragmentation. model.eval() # inference-only (dropout off, batchnorm stats fixed), matching real packing inference max_tokens = start_tokens # current sequence length to try; grows by step_size after each success safe_limit = 0 # last max_tokens that completed a forward without OOM (hardware redline before the failed step) with torch.no_grad(): # no autograd state = roughly half the activation memory vs training mode while True: try: # Synthetic token IDs: distribution does not matter for memory; size drives activations/attention workspace dummy_tokens = torch.randint(0, vocab_size, (max_tokens,), device=device) # Single packed sequence [0, max_tokens): worst-case one long sequence for max seqlen in the pass dummy_cu_seqlens = torch.tensor([0, max_tokens], dtype=torch.int32, device=device) # Real forward on target device: stresses the same kernels/allocations as production (unlike padding-only tests) # Signature must match your model (eg FlashAttention varlen). Adjust kwargs if your forward differs. _ = model(dummy_tokens, cu_seqlens=dummy_cu_seqlens, max_seqlen=max_tokens) safe_limit = max_tokens # this length fit; treat as the best known redline so far max_tokens += step_size # try a longer stretch next (coarse search; reduces how many forwards you run) del _, dummy_tokens, dummy_cu_seqlens # drop references so the next trial's peak memory is not inflated by leftovers except RuntimeError as e: if "out of memory" in str(e).lower(): # Forward at max_tokens exceeded free VRAM: stop; safe_limit is the last successful length torch.cuda.empty_cache() # return cached blocks to the pool (no-op on CPU-only builds in many versions) gc.collect() # free any Python objects still holding device tensor views break # Shape/keyword errors mean the dummy call does not match the model API, not “out of VRAM” raise if safe_limit == 0: # If the very first try at start_tokens OOMs, there is no successful redline; lower start_tokens (no automatic halving here) sys.exit("Error: Model cannot process the starting token count without OOM. Decrease start_tokens.") # 0.9x: headroom for allocator fragmentation and small spikes on real batches vs this idealized probe optimal_capacity = int(safe_limit * 0.9) print(f"nOptimal bin capacity locked at: {optimal_capacity} tokens.n") return optimal_capacity
Вот и всё. В этом и заключается вся суть «автонастройки». Забрасываем модель всё более и более сложными фиктивными последовательностями, пока CUDA не перевернёт всё с ног на голову, записываем последнюю выжившую, умножаем на 0,9 для подстраховки. Никаких официальных документов от производителя. Никаких теоретических формул. Просто издеваемся над графическим процессором, пока он не покажет свой реальный предел.
На устройстве H100 с модулем Qwen2.5–7B-Instruct это составляет примерно 76 500 токенов на один контейнер . Попробуйте представить это в виде партии из 8 токенов.
Этап 1 — Токенизация и запуск
Python считывает документы (PDF, JSONL и т.д.), токенизирует их с помощью токенизатора HuggingFace и отправляет каждый документ в виде списка целых чисел через интерфейс PyBind11. Это описано в reader_and_tokennizer.py :
for text in _iter_text_units(data_source, json_key): tokens = tokenizer.encode(text, add_special_tokens=True) if len(tokens) > effective_cap: if max_length is not None and effective_cap == max_length: tokens = tokens[:effective_cap] else: print( f"Warning: Sequence length ({len(tokens)}) exceeds VRAM capacity " f"({effective_cap}). Truncating sequence...", file=sys.stderr, ) tokens = tokens[:effective_cap] if cxx_backend is not None: cxx_backend.submit_sequence(tokens)
Обратите внимание, насколько это скучно. Отлично. Скучный Python = быстрый C++. Python выполняет ввод-вывод и токенизацию, и всё. Никакой логики пакетной обработки, никакой логики упаковки, никакой работы с GPU. Всего одна задача, детка.
Этап 2 — Перчатка ловца на C++
На стороне C++ файл async_dispatcher.cpp перехватывает каждый вызов submit_sequence и помещает его в потокобезопасную std::deque защищенную мьютексом:
void AsyncDispatcher::submit_sequence(std::vector tokens) { { std::lock_guard<:mutex> lk(queue_mutex); if (!engine_started.load()) { // Quiet no-op before initialize_engine() — avoids crashing notebooks // that accidentally submit early; uncomment throw if you prefer fail-fast. return; } pending_queue.push_back(std::move(tokens)); } cv_data.notify_one(); }
Тем временем фоновый рабочий поток находится в цикле wait() . Когда появляются токены, он просыпается, захватывает партию и запускает упаковщик. Хитрость в том, что он не просыпается мгновенно, потому что это означало бы упаковку по одной последовательности за раз, что противоречит самой идее контейнерной упаковки.
Вместо этого он ожидает либо накопления 16 последовательностей , либо истечения 5 мс :
// Accumulation window: if there are few pending sequences and the // producer is still feeding (not input_done, not shutting down), // wait a brief moment for more before swapping. This lets the // FFD packer see a real batch instead of one sequence at a time. // Wakes early on: reaching kPackMinBatch, shutdown, or input_done. if (pending_queue.size() < kPackMinBatch && !stop_flag.load() && !input_done_flag.load()) { cv_data.wait_for(lk, kPackWaitWindow, [&] { return pending_queue.size() >= kPackMinBatch || stop_flag.load() || input_done_flag.load(); }); }В этом и заключается разница между «упаковкой в контейнеры» и «контейнером… ну, контейнер с одной последовательностью технически является контейнером». 5 мс короче, чем один прямой проход на этом оборудовании, поэтому задержка практически незаметна. Прирост плотности достигает 8 раз.
Слой PyBind11 в bindings.cpp оборачивает все с помощью py::gil_scoped_release так что любая работа на C++, которая блокирует выполнение или приостанавливается, не будет удерживать GIL Python :
m.def( "get_next_bin", []() -> std::tuple<:tensor torch::tensor> { PackedBin bin; { py::gil_scoped_release release; bin = engine().get_next_ready_bin(); } // Re-acquired the GIL here -- creating torch::Tensor objects and // returning them to Python touches CPython refcounts. if (bin.flat_tokens.empty()) { auto opts = torch::TensorOptions().dtype(torch::kInt32).device(torch::kCUDA); return std::make_tuple(torch::empty({0}, opts), torch::empty({0}, opts)); } return engine().get_memory_pool().create_zero_copy_tensors(bin); }, "Block until a packed bin exists; returns (token_ids, cu_seqlens) on CUDA.");
Если вы когда-либо отлаживали взаимоблокировку в Python-C++, комментарии в этом файле вызовут у вас ностальгию. Определенно стоит прочитать, особенно если вы выпили слишком много кофе и вам трудно заснуть!
Этап 3 — Тетрис с правилами (FFD + выравнивание из 16 фишек)
Это суть всего проекта, и она удивительно коротка. Из bin_packer.cpp :
int BinPacker::align_to_tensor_core(int raw_length) { /* * NVIDIA Tensor Cores execute matrix math in 16x16 or 32x32 tiles. * If a sequence length is not perfectly divisible by 16, the Tensor Core * cannot process the ragged edge, causing the GPU to stall. * We calculate the remainder and round up to the nearest multiple of 16. */ int remainder = raw_length % 16; if (remainder == 0) { return raw_length; } return raw_length + (16 - remainder); }
Три строки. Это «выравнивание Tensor Core с 16 токенами», которое в блогах NVIDIA описывается как диссертация на соискание степени доктора наук. Это roundup(n, 16) . Вот и всё. Вот в чём суть.
Сама упаковка:
std::vector BinPacker::pack_queue(std::deque<:vector>>& pending_queue) { std::vector ready_bins; if (pending_queue.empty()) { return ready_bins; } // Step 1: Drain the queue into a standard vector so we can sort it. // We use std::move to transfer memory ownership instantly without copying data. std::vector<:vector>> sequences; while (!pending_queue.empty()) { sequences.push_back(std::move(pending_queue.front())); pending_queue.pop_front(); } // Step 2: Sort Decreasing (Longest sequences first) // Packing large rocks first, then filling gaps with pebbles yields the highest density. std::sort(sequences.begin(), sequences.end(), [](const std::vector& a, const std::vector& b) { return a.size() > b.size(); }); // Step 3: First-Fit Packing for (auto& seq : sequences) { int raw_len = seq.size(); int aligned_len = align_to_tensor_core(raw_len); // Edge case safety: If alignment pushes it barely over the VRAM limit, clamp it. if (aligned_len > max_vram_capacity) { aligned_len = max_vram_capacity; seq.resize(aligned_len, 0); } else if (aligned_len > raw_len) { // Physically inject invisible '0' pad tokens to reach the 16-boundary seq.insert(seq.end(), aligned_len - raw_len, 0); } bool placed = false; // Try to fit the sequence into an existing open bin (First-Fit) for (auto& bin : ready_bins) { if (bin.current_token_count + aligned_len <= max_vram_capacity) { // It fits! Record the starting boundary in cu_seqlens bin.cu_seqlens.push_back(bin.current_token_count); // Append the tokens to the flat 1D array bin.flat_tokens.insert(bin.flat_tokens.end(), seq.begin(), seq.end()); bin.current_token_count += aligned_len; placed = true; break; } } // If it didn't fit in ANY existing bin, we must allocate a new bin if (!placed) { PackedBin new_bin; new_bin.current_token_count = aligned_len; // The first sequence in a new bin always starts at index 0 new_bin.cu_seqlens = {0}; // Move the tokens into the flat array new_bin.flat_tokens = std::move(seq); ready_bins.push_back(std::move(new_bin)); } }
Прочитайте это дважды. Усвойте. Это и есть алгоритм. Всё остальное в этом репозитории — потоки C++, закреплённая память, хитросплетения GIL — существует для того, чтобы задействовать этот 30-строчный цикл и передать его результат на графический процессор в рамках одного асинхронного DMA без дополнительных копирований на стороне хоста.
cu_seqlens — это волшебное кольцо декодера. Это небольшой целочисленный массив кумулятивных смещений. Если ваш контейнер содержит три документа длиной 200, 144 и 64 (уже выровненные), то cu_seqlens = [0, 200, 344, 408] . FlashAttention-2 считывает этот массив и говорит: «А, я вижу, три подпоследовательности», и применяет к ним точное внимание без заполнения. В памяти не материализуется гигантский плотный тензор маски. Нет междокументного загрязнения. Нет лишних операций с плавающей запятой на областях с заполнением.
Этап 4 — Волшебный трюк с «нулевым копированием» (один DMA, никаких дополнительных копий)
Итак, у нас есть упакованный бинарный объект в std::vector на ЦП. Нам нужно использовать его на ГП. Наивный подход: memcpy в тензор PyTorch с помощью memcpy, а затем .to('cuda') . Это работает, но за каждый бинарный объект приходится платить две суммы: (1) дополнительное копирование на стороне хоста (ваш вектор → некоторый промежуточный тензор → ГП) и (2) на x86_64 ОС может в любой момент перетаскивать ваши страницы памяти, что заставляет CUDA выполнять передачу данных через буфер синхронизации вместо того, чтобы позволить механизму DMA напрямую обращаться к вашим байтам.
Секрет заключается в использовании фиксированной (заблокированной по страницам) памяти хоста , выделяемой с помощью cudaHostAlloc . Фиксированная память — это оперативная память, которую ОС не может использовать для обмена или перемещения данных. Поскольку адрес стабилен, механизм DMA графического процессора может передавать байты по шине PCIe за один асинхронный цикл , без необходимости предварительной подготовки промежуточного копирования со стороны ЦП. Сама передача всё ещё происходит — это не буквально «нулевое копирование» в строгом смысле UVA/UM, DMA хост→устройство реально — но это одно копирование вместо двух, оно выполняется асинхронно с ЦП и попадает непосредственно в память устройства. В мире вывода результатов все так называют это «нулевым копированием», и функция в репозитории названа соответствующим образом. Педантам просьба направлять жалобы в раздел комментариев; мы рассмотрим их после обеда.
Из файла memory_pool.cpp :
// --------------------------------------------------------- // 1. ALLOCATE PINNED MEMORY (Happens once during Phase 0) // --------------------------------------------------------- MemoryPool::MemoryPool(size_t max_vram_tokens) : max_capacity(max_vram_tokens) { // Allocate the token buffer. cudaHostAlloc locks this memory into physical RAM. cudaError_t err1 = cudaHostAlloc((void**)&pinned_token_buffer, max_capacity * sizeof(int), cudaHostAllocDefault); // Allocate the sequence length boundaries buffer. // +1 because cu_seqlens always has one more element than the number of sequences. cudaError_t err2 = cudaHostAlloc((void**)&pinned_seqlens_buffer, (max_capacity + 1) * sizeof(int), cudaHostAllocDefault); if (err1 != cudaSuccess || err2 != cudaSuccess) { throw std::runtime_error("[MemoryPool] Fatal: Failed to allocate pinned memory. " "Host system may be out of RAM."); } std::cout << "[MemoryPool] Successfully locked " << (max_capacity * sizeof(int)) / 1024 << " KB of DMA-ready pinned memory." << std::endl; }
Затем, когда нам нужно отправить файл в GPU, мы копируем упакованный файл в закрепленный буфер (одна быстрая std::copy ) и оборачиваем этот закрепленный буфер в тензор PyTorch , не выделяя новое хранилище для тензоров :
std::tuple<:tensor torch::tensor> MemoryPool::create_zero_copy_tensors(const PackedBin& bin) { // Step 1: Fast C++ copy from our packing algorithm into the pinned memory block. // std::copy is highly optimized by the compiler at the assembly level. std::copy(bin.flat_tokens.begin(), bin.flat_tokens.end(), pinned_token_buffer); std::copy(bin.cu_seqlens.begin(), bin.cu_seqlens.end(), pinned_seqlens_buffer); // Step 2: The PyTorch Metadata Shell // torch::from_blob does NOT allocate new memory. It simply wraps our existing // pinned_token_buffer pointer in a PyTorch Tensor object so Python can interact with it. auto token_opts = torch::TensorOptions().dtype(torch::kInt32).device(torch::kCPU); torch::Tensor token_tensor = torch::from_blob( pinned_token_buffer, // The raw pinned pointer {static_cast(bin.current_token_count)}, // The exact size of this specific batch token_opts ); torch::Tensor seqlens_tensor = torch::from_blob( pinned_seqlens_buffer, {static_cast(bin.cu_seqlens.size())}, token_opts ); // Step 3: Trigger the PCIe DMA transfer. // Because the underlying memory is pinned, the .to(cuda) call triggers an // asynchronous DMA transfer. The CPU immediately moves on to packing the next bin // while the GPU hardware silently pulls the data over the bus. torch::Tensor gpu_tokens = token_tensor.to(torch::kCUDA, /*non_blocking=*/true); torch::Tensor gpu_seqlens = seqlens_tensor.to(torch::kCUDA, /*non_blocking=*/true); return std::make_tuple(gpu_tokens, gpu_seqlens); }
torch::from_blob — одна из самых восхитительно зловещих функций в PyTorch. Она говорит: «Я не буду выделять новое хранилище для тензоров. Я оберну этот необработанный указатель в представление тензора, а вы отвечаете за поддержание активности базовой памяти». Это эквивалент на C++ того, как если бы вы взяли стикер с надписью «TENSOR» и приклеили его к уже существующему объему памяти. PyTorch в это верит. Все довольны. (Да, небольшая структура метаданных тензора все равно выделяется. Хранилище не выделяется, и именно это обходится вам в определенную сумму за каждый бин. Педанты из HPC, пожалуйста, уберите вилы обратно; мы почти закончили этот раздел.)
Параметр non_blocking=True в методе .to(torch::kCUDA) запускает асинхронную передачу данных по PCIe DMA и немедленно возвращает управление. Процессор переходит к упаковке следующего контейнера, в то время как графический процессор незаметно переносит данные из предыдущего контейнера по шине. Упаковщик и графический процессор теперь работают параллельно. Именно в этот момент вы начинаете слышать, как начинает вращаться вентилятор графического процессора, словно у него наконец-то появилась реальная задача.
Фаза 5 — FlashAttention-2 наслаждается обедом без заполнения.
Теперь код на Python в main_working_file.py стал до смешного коротким:
# Phase 0, Step C: Initialize the C++ Background Engine # Locks in hardware limits and spawns background worker thread warpgroup_backend.initialize_engine(vram_capacity) # Phase 1: Ingest and Tokenize # Streams tokens into the C++ background queue ingest_and_tokenize( file_path, tokenizer, vram_capacity, cxx_backend=warpgroup_backend ) # Phase 4 & 5: Inference Execution print("nStarting Inference Phase...") try: # Phase 4: Orchestration & Queue Management while not warpgroup_backend.is_queue_empty(): # Retrieve the hardware-optimized bin tensors # This triggers the zero-copy DMA handoff from pinned memory bin_tensors = warpgroup_backend.get_next_bin() # Phase 5: GPU Execution (FlashAttention-2) with torch.no_grad(): # The wrapper translates the 1D bin to 2D for the HF model output = model(bin_tensors[0], cu_seqlens=bin_tensors[1]) print(f"Executed FlashAttention-2 for bin size: {bin_tensors[0].shape[0]} tokens.")
Небольшое, но важное замечание для внимательного читателя: стандартная функция
forward()в HuggingFace не принимаетcu_seqlensнапрямую. Здесь используется тонкаяmodelизVarlenModelWrapperstreaming_dataloader.pyкоторая преобразует одномерный упакованный поток в форму(1, N)ожидаемую HF, и — что крайне важно — перестраиваетposition_idsтаким образом, чтобы каждая подпоследовательность начиналась с позиции 0 (иначе первый токен документа B будет иметь positionlen(A), а вращающиеся эмбеддинги будут отображаться боком). Для побитово корректного междокументного маскирования в многопоследовательном бине также необходимо загрузить базовую модель HF сattn_implementation='flash_attention_2', а слои внимания должны быть настроены на вызовflash_attn_varlen_funcс тем жеcu_seqlens— в документации к обертке подробно объясняется, почему и как это делается. FA-2 — это то, что фактически выполняет внимание переменной длины; Вклад WarpGroup заключается в том, что компания обеспечивает интенсивную и своевременную подачу данных.
Несколько строк бизнес-логики. Вот и всё. Всё остальное происходит в движке C++, пока Python потягивает кофе.
5. Чеки (т.е., цифры)
Пора унизить базовый показатель. Все цифры взяты из файла README репозитория.
Краткое замечание о методологии бенчмаркинга , прежде чем кто-либо начнет критиковать: каждое сравнение ниже использует одну и ту же контрольную точку модели, один и тот же токенизатор, один и тот же входной корпус и один и тот же тип данных (bf16) на одном и том же графическом процессоре при стандартных тактовых частотах. Базовый путь (HuggingFace) — это стандартный конвейер обработки данных с заполненными пакетами от HF с attn_implementation="flash_attention_2" — то есть, он уже использует FA-2, а не намеренно упрощенный наивный цикл. Оптимизированный путь использует то же ядро FA-2. Единственное различие заключается в способе пакетной обработки последовательностей (упаковка FFD в одномерный бин с учетом VRAM против заполнения до прямоугольного тензора batch_size × longest_sequence ). Тип рабочей нагрузки — предварительная обработка документов , а не авторегрессивное потоковое декодирование — это различие важно для следующего подраздела. Если вы хотите поспорить с цифрами, скрипты для воспроизведения ошибки находятся в папке example_runs/ .
Стресс-тест: H100, Qwen2.5–7B, 400 PDF-файлов разной длины.
В наборе данных намеренно чередуются небольшие документы (45–130 слов) с объемными (1820–2000 слов) — по сути, это наихудший вариант для пакетной обработки с добавлением лишних слов.
| Метрическая система | Исходный уровень (HF) | WarpGroup | Улучшение |
|---|---|---|---|
| Набивка сверху | 48,41% | 0,55% | 47,9 pp абсолютное снижение |
| Пропускная способность | 14 713 ток/с | 30 672 ток/с | В 2,08 раза выше |
| Пиковое значение видеопамяти | 19,88 ГБ | 16,50 ГБ | Снижение на 17% (экономия 3,38 ГБ) |
| Динамический объем видеопамяти (прибл.) * | ~5,38 ГБ | ~2,00 ГБ | Примерно на 62% меньше динамической памяти |
| Настенные часы | 28,69 с | 13,76 с | В 2,08 раза быстрее |
Перевод: базовый показатель потратил половину своих токенов на добавление нулей. Половину. Представьте, что вы заказываете пиццу, а 4 из 8 кусочков — это просто картон.
Масштабирование производства: одинаковое оборудование, единый формат документов от 50 до 1900 слов.
| Метрическая система | Исходный уровень (HF) | WarpGroup | Улучшение |
|---|---|---|---|
| Набивка сверху | 36,20% | 0,67% | абсолютное снижение на 35,5 pp |
| Пропускная способность | 18 047 ток/с | 30 700 ток/с | в 1,70 раза выше |
| Настенные часы | 17,86 с | 10,50 с | В 1,70 раза быстрее |
Даже на «хорошем», равномерно распределенном наборе данных (то есть, единственном, который когда-либо используется в сравнительных тестах в блогах), WarpGroup все равно выигрывает с преимуществом в 70%, потому что накладные расходы на заполнение существуют даже при нормальном распределении данных .
Базовая конфигурация: GTX 1080 (8 ГБ), SmolLM2–360M
| Метрическая система | Исходный уровень (HF) | WarpGroup | Улучшение |
|---|---|---|---|
| Набивка сверху | 41,13% | 0,00% | Базовая прокладка удалена. |
| Пропускная способность | 405 ток/с | 2387 ток/с | в 5,89 раза выше |
| Пиковое значение видеопамяти | 2,85 ГБ | 1,86 ГБ | на 35% ниже |
Это мой любимый пример. Почему? Потому что чем меньше ваше оборудование, тем хуже экономия ресурсов. GTX 1080, работающая в 5,89 раза быстрее, означает, что небольшие стартапы, любители, университетские лаборатории и все, кто использует одну потребительскую видеокарту, получили бесплатное обновление оборудования. Та же самая 1080, которая была «едва достаточной», теперь «на самом деле довольно хороша».
Бонусный раунд: не разбиться
Если полностью убрать ограничение MAX_LEN , то базовый параметр будет выглядеть следующим образом:
torch.OutOfMemoryError: Tried to allocate 30.00 GiB
Потому что программа попыталась создать прямоугольник (batch_size × longest_sequence) , а самая длинная последовательность оказалась, э-э, большой.
WarpGroup: успешно завершено, пиковое использование видеопамяти 3,60 ГБ. Поскольку автонастройка фазы 0 фиксирует строгий, выровненный по аппаратному обеспечению, бюджет входных данных, упаковщик отказывается принимать любые данные, превышающие его . Фрагментация распределителя памяти и рабочие пространства временного хранения ядра могут по-прежнему удивлять вас в теории; на практике же патологические ошибки нехватки памяти, вызванные заполнением, на которые срабатывают пакетные операции с фиксированной формой, просто перестают происходить. Никаких сообщений в Slack в 3 часа ночи от вашего дежурного кузена. Просто последовательности, упакованные, выполненные, готово.
«Хорошо, но чем это отличается от vLLM / страничного внимания / непрерывной пакетной обработки?»
Вполне резонный вопрос, и на него стоит ответить напрямую, потому что в мире инфраструктуры вывода много пересекающихся примитивов, и читатель, интересующийся высокопроизводительными вычислениями, обязательно задаст его в первом же комментарии.
- vLLM / непрерывная пакетная обработка оптимизирована для обслуживания во время декодирования: множество одновременных запросов на разных этапах генерации, планирование следующего токена между ними, поддержание высокой загрузки графического процессора при потоковой нагрузке. Ее основной примитив — страничное внимание — менеджер памяти кэша ключ-значение, который выгружает физически несмежные блоки, подобно таблице страниц операционной системы.
- TensorRT-LLM, SGLang и FlashInfer поддерживают различные варианты механизма внимания Варлена. Их логика упаковки обычно находится внутри среды выполнения, настроенной для потоков запросов в реальном времени, чувствительных к задержкам.
- WarpGroup-Backend ориентирован на другую половину спектра рабочих нагрузок: автономные/высокопроизводительные задачи с предварительным заполнением. Оценка документов, индексирование RAG, пакетное извлечение эмбеддингов, пакетное суммирование OAM-логов, массовая классификация, инструменты оценки. Единицей работы является конечный корпус последовательностей переменной длины, а не поток запросов на декодирование. Основное внимание уделяется плотности упаковки на стороне хоста, асинхронной диспетчеризации без GIL и жесткой передаче данных в закрепленную память, а не страничной организации кэша ключ-значение.
Представьте себе: vLLM — это менеджер ресторана , рассаживающий посетителей за столиками в режиме реального времени. WarpGroup — это кейтеринговая компания , упаковывающая ланчи на день в фургоны для доставки перед тем, как грузовики покинут склад. Разные задачи, взаимодополняющие базовые элементы, часто развертываемые совместно в одном здании.
6. Итак… как же мне это попробовать?
В репозитории есть одноразовый пример для воспроизведения проблемы:
# 1. Clone git clone https://github.com/AnubhabBanerjee/WarpGroup-backend.git cd WarpGroup-backend # 2. Python env + deps python3.12 -m venv .venv source .venv/bin/activate pip install --upgrade pip pip install -r requirements.txt pip install -e . # 3. Compile the C++ backend mkdir build && cd build cmake .. make -j4 cp warpgroup_backend*.so .. cd .. # 4. Smoke test python3 main_working_file.py
Если вам нужен корректный сравнительный тест (базовый HF против WarpGroup), в папке example_runs/ находится скриптовый сквозной инструмент, который генерирует синтетический корпус PDF-файлов, запускает оба стека и записывает результаты в формате JSON, а также гистограммы.
Вам понадобится:
- Linux, набор инструментов CUDA, графический процессор NVIDIA (подходит как для потребительского, так и для дата-центров).
- Сборка PyTorch с поддержкой CUDA (не стоит выпускать версию только для ЦП, а потом удивляться, когда ничего не ускоряется).
- LLM, поддерживающий
flash_attention_2(Qwen2.5, Llama-3, Mistral, SmolLM2 и др.).
7. Неожиданный поворот сюжета — это всего лишь планирование MAC в костюме CUDA.
Наверное, стоит признаться: я не специалист по графическим процессорам по образованию. Я начинал свою карьеру в телекоммуникационной отрасли — 5G NR, с небольшим увлечением исследованиями в области 6G — и начал изучать инфраструктуру для инференции LLM, потому что каждая проблема в этом коде казалась мне до боли знакомой.
Сравните эти два примера и скажите мне совершенно серьезно:
Планировщик MAC-адресов 5G NR (на gNB) WarpGroup-Backend (на GPU) MAC SDU переменного размера от каждого UE / логического канала Последовательности токенов переменного размера от каждого документа Упаковка в транспортный блок каждый TTI Упаковка в блок VRAM каждый цикл диспетчеризации Размер TB ограничен доступными PRB × битами MCS Размер блока ограничен эмпирическим бюджетом VRAM Должен соответствовать сегментации кодовых блоков LDPC (TS 38.212 §5.2.2) Должен соответствовать 16-токеновым плиткам Tensor Core Приоритизация логических каналов (LCP) выбирает, что будет поступать Метод First-Fit Decreasing выбирает, что будет поступать Жесткий крайний срок: один слот (0,5 мс при нумерологии μ=1) Мягкий крайний срок: постоянно подавать данные на GPU Пропуск TB → резкое падение пропускной способности PDSCH Пропуск блока → GPU простаивает, пропускная способность кратеры
Если вы когда-либо читали 3GPP TS 38.321, то видите тот же алгоритм. Планировщик MAC на базовой станции с момента появления LTE-Advanced упаковывает блоки SDU переменного размера в транспортные блоки — размер которых соответствует фиксированной сетке PRB, выровнен по пороговым значениям блоков кода LDPC и имеет приоритет по логическим каналам. В WarpGroup меняются только единицы измерения (токены, а не биты), бюджет (VRAM, а не PRB) и квант выравнивания (плитки по 16 токенов, а не размеры блоков кода LDPC).
Даже у Phase 0 есть телекоммуникационный аналог. В репозитории GPU проверяется с помощью синтетических последовательностей до тех пор, пока не возникнет ошибка нехватки памяти (OOM), после чего производительность снижается на 10%. В RAN аналогичная процедура выполняется каждые TTI: отслеживаются отчеты CQI/SINR, выбирается MCS, отслеживается BLER, после чего производительность снижается. Оба варианта говорят об одном и том же — спецификация дает теоретический максимум, но единственное достоверное значение — это то, которое измеряется в реальных условиях.
Небольшое замечание, адресованное двум совершенно разным аудиториям.
Моим друзьям, которые в первую очередь разбираются в высокопроизводительных вычислениях и CUDA и читают это: я знаю. Вы занимаетесь именно этим с тех пор, как в 2003 году появились первые статьи о GPGPU. Упаковка контейнеров — это курс алгоритмов для начинающих, cudaHostAlloc есть в каждом руководстве по CUDA, а закрепленная память — для вас это, по сути, черта характера. Ничего из этого не новость. Пожалуйста, прекратите возмущаться.
Но это новость для инженеров телекоммуникаций, и это половина причины существования этой статьи. Двадцать лет наш мир состоял из FPGA, ASIC и PRB. Мы оптимизировали спектр, а не кремний. Попросите среднестатистического инженера RAN объяснить выравнивание тайлов Tensor Core, и вы получите вежливый взгляд. Затем AI-RAN, NWDAF, NVIDIA Aerial, SoftBank AITRAS, альянс AI-RAN и исследования 3GPP Rel-20 — все это произошло примерно за те же восемнадцать месяцев, и следующее десятилетие карьеры в телекоммуникациях теперь требует двуязычия между миром спектра и миром GPU — причем многие из нас начинают практически с нуля в области GPU. Если термин «закрепленная память» еще десять минут назад звучал как иностранный язык: добро пожаловать, вы не отстаете, вы пришли раньше. В любом случае, интуиция понятна. Вы уже знаете, как упаковывать полезные нагрузки переменного размера в окно с фиксированным бюджетом при ограничениях аппаратного выравнивания. Раньше вы просто называли это планированием MAC. То же животное, новый зоопарк.
Рассматривайте эту статью как полшага на этом пути.
Почему это должно волновать работающего инженера-телекоммуникационщика прямо сейчас
Это не абстрактная аналогия. Четыре конкретные причины, по которым это произойдет в 2026 году:
- 6G официально является технологией, изначально разработанной для ИИ. ITU-R IMT-2030, исследовательские работы 3GPP Rel-20, альянс AI-RAN, рабочие группы O-RAN по ИИ/машинному обучению — все они предполагают, что модели LLM и большие модели машинного обучения находятся внутри сети, а не добавляются к OSS/BSS позже. Управление лучом, RIC xApps/rApps, аналитика NWDAF, конфигурация на основе намерений, агентное управление доступом — каждая из этих задач может быть использована в стеке для вывода результатов, который делает именно то, что делает WarpGroup.
- Голосовая речь уже представляет собой поток токенов. Нейронные аудиокодеки (Encodec, SoundStream, Mimi) токенизируют речь в диапазоне 25–75 Гц. Голосовые LLM-системы, такие как Moshi, AudioPaLM и Spirit-LM, обрабатывают эти токены напрямую. Колл-центр, обрабатывающий 10 000 одновременных звонков, с вычислительной точки зрения представляет собой огромное количество потоков токенов переменной длины, поступающих асинхронно из разнородных источников — именно такую нагрузку имитирует стресс-тест этого репозитория. Замените «400 PDF-файлов» на «400 потоков RTP», и расчеты будут идентичными: тот же перекос, тот же налог на заполнение, тот же обрыв нехватки памяти.
- MEC использует крошечные графические процессоры. Многодоступные узлы Edge Compute на уровне gNB/UPF не могут работать с 8 стойками H100. Они получают один L4, возможно, A10, а может быть, и один H100, если отдел закупок настроен благосклонно. Увеличение пропускной способности в 2–6 раз с помощью одного графического процессора на периферии — это разница между «функциями ИИ, доступными на периферии» и «функциями ИИ только в ядре ЦОД, плюс 30 мс дополнительного времени обработки». Именно в этом разрыве и заключается успех или провал приложений класса URLLC.
- Телеметрия OAM — это скучное, но эффективное приложение. Счетчики PM, события syslog, CDR, записи NetFlow/IPFIX, трассировки NF — это потоки структурированного текста переменной длины, которые значительно выигрывают от суммирования на основе LLM, обнаружения аномалий и преобразования намерений. Они также обладают поразительной вариативностью длины: обычная трассировка вызова содержит несколько сотен токенов; одна трассировка сбоя при передаче данных в сети 5G может превышать 50 000. Пакетная обработка с добавлением заполнения в этом дистрибутиве заставит плакать ваш кластер вывода, затем директора по операциям, а затем и финансового директора.
Поэтому, когда я вижу код, который использует упаковку FFD с учетом VRAM, выравнивание по аппаратным плиткам и передачу данных через закрепленную память с помощью одного DMA, я не вижу «оптимизацию GPU». Я вижу аналог планировщика MAC на стороне вывода. Причина, по которой я трачу на это вечера, не связана со сменой карьеры — это та же работа, но на другом чипе, для следующего поколения телекоммуникационных нагрузок, которые будут работать наполовину в спектре, а наполовину на GPU.
Кроме того, честно говоря, после десяти лет изучения спецификаций 3GPP, кодовая база, из которой можно git clone весь планировщик за 30 секунд, — это просто отпуск.
8. Мораль, если вы пришли сюда за ней.
Есть три вывода, которые, на мой взгляд, применимы не только к этому конкретному репозиторию:
1. Пакетная обработка по умолчанию — это вежливая ложь. Параметр «batch_size = 8» ничего не говорит о том, насколько заполнен ваш графический процессор. Правильная единица измерения — токены в видеопамяти, и вам нужно измерить это, потому что ни одна библиотека не покажет вам правду. День, когда вы начнете думать о количестве токенов на ячейку вместо количества элементов на пакет, — это день, когда ваш график пропускной способности перестанет вас смущать.
2. Интересная работа над производительностью ведется на границах. Самые затратные части конвейера LLM — это не умножение матриц, которые были оптимизированы вручную инженерами NVIDIA, на которых висят ипотечные кредиты. Самые затратные части — это переходы : от токенов к тензорам, от хоста к устройству, от Python к C++, от планировщика к GPU. Практически каждая история типа «Подождите, я сделал это в 2 раза быстрее» в современном машинном обучении — это история, связанная с границами.
3. Иногда правильный ответ — «написать на C++». Не весь код. Даже не большую его часть. Python, безусловно, может координировать высокопроизводительные системы вывода — vLLM доказывает это каждый день. Но перенос цикла упаковки «горячих путей» в фоновый поток C++ избавляет от двух специфических издержек на стороне Python, которые ощущаются под нагрузкой: конфликт GIL с потоком обработки данных и накладные расходы интерпретатора и распределителя памяти в плотном цикле планирования, где каждая микросекунда является частью бюджета. Правильное соотношение Python/C++ для высокопроизводительной инфраструктуры вывода — это не 100/0 или 0/100, а тонкая, четко определенная граница PyBind11, где критически важный по задержке планировщик находится на стороне C++, а все интересные вещи (код модели, бизнес-логика, связующее звено) — на стороне Python. WarpGroup — это ~64% Python, ~30% C++, ~5% связующего звена сборки. Это соотношение не случайно.
9. Что будет дальше?
План развития репозитория намекает на очевидный следующий шаг: сегментирование на нескольких графических процессорах . Расширить диспетчер для управления несколькими очередями C++ и распределения динамически изменяемых размеров ячеек по локальным межсоединениям (NVLink / PCIe). Сложность заключается не в C++, а в решении вопроса о балансировке размеров ячеек между устройствами при неравномерном распределении длин последовательностей. (Приветствуются запросы на добавление изменений и т.д.)
Если хотите углубиться в детали, вот те моменты, которые я бы хотел увидеть более подробно рассмотренными:
- Адаптивное значение
kPackWaitWindow— это 5-миллисекундное окно накопления, заданное вручную. Вероятно, оно должно быть функцией наблюдаемой скорости генерации. - Предварительное резервирование места в контейнере — закрепление объема памяти хоста, соответствующего второму контейнеру, чтобы мы могли упаковать следующую партию, пока текущая еще находится в процессе обработки.
- Непрерывная пакетная обработка для генерации — сейчас это конвейер предварительного заполнения/оценки. Естественным расширением стало бы подключение к потоковому декодированию для чат-сервера.
10. Обертка
Заполнение — это скрытый налог на каждую рабочую нагрузку LLM, которая работает с текстом переменной длины. Вклад WarpGroup-Backend заключается не в новом алгоритме — упаковка FFD в контейнеры существует с 1970-х годов — а в инженерной интеграции : эмпирическая автонастройка VRAM, асинхронная диспетчеризация без GIL, выравнивание по 16 токенам для нижестоящих ядер и передача данных через единую DMA-память в ядро varlen FlashAttention-2, всё это объединено таким образом, что один python3 main_working_file.py обеспечивает в 2–6 раз большую пропускную способность на реальном оборудовании.
Если вы профессионально занимаетесь разработкой инфраструктуры для вывода LLM-данных, клонируйте репозиторий, прочтите файлы C++ (в них много комментариев и иногда встречаются ироничные шутки) и подумайте, сколько ваших собственных конвейеров сейчас платят налог за заполнение данных.
Если вы занимаетесь разработкой телекоммуникационных систем и подозреваете, что в течение следующего десятилетия вашей работы будет гораздо больше серверов обработки данных, чем вы изначально предполагали, — совет тот же. Планировщик MAC в вашем gNB и упаковщик bin в этом репозитории работают по одному и тому же сценарию.
Если вы новичок, который просто хотел понять, почему видеокарты ненавидят текст переменной длины, — поздравляю, теперь вы знаете больше, чем 80% людей, которые зарабатывают этим на жизнь. Вперед, перестаньте заполнять текст лишним.
О репозитории
- Код: github.com/AnubhabBanerjee/WarpGroup-backend
- Стек технологий: C++17, PyBind11, среда выполнения CUDA, PyTorch 2.5+, FlashAttention-2, HuggingFace Transformers
- Лицензия: Все права защищены (см. файл README репозитория).
- Автор: Анубхаб Баннерджи
Если вам это понравилось, то самое доброе, что вы можете сделать: ⭐ ссылку на репозиторий, поделиться этим постом и сказать одному пользователю PyTorch в вашей жизни, что его параметр batch_size его обманывает.
А теперь иди и покричи на свою видеокарту. С любовью.
Анубхаб Банерджи Посмотреть все в Анубхаб Банерджи
Источник: towardsdatascience.com
Оцените материал:
