В мае я занимался оценкой различных движков для распознавания текста (OCR).
Тестирование четырнадцати двигателей на девяноста трех документах, составленных людьми.
Делиться
. 1")
Не все документы должны были считываться машиной. Старые счета из отелей, банковские выписки, расчетные листки, заявления на кредиты, медицинские счета, таможенные декларации, судебные документы, заказы на выполнение работ.
Большинство компаний используют бесплатные инструменты наряду с платными API для преобразования этих документов, и если вам нужен структурированный вывод, такие API, как Textract Structured, обойдутся вам примерно в 65 долларов за 1000 страниц.
Однако за последние несколько лет появилось множество новых вариантов: небольшие модели обработки изображений с открытым исходным кодом, специализированные для оптического распознавания символов (OCR), универсальные модели обработки изображений и языка, а также инструменты для анализа документов, такие как LlamaParse, — что изменило как возможности, так и стоимость таких решений.
Поэтому мне показалось, что сейчас самое подходящее время провести собственный эксперимент и проверить некоторые из этих методов на документах различной сложности .
Я отобрал 93 документа, которые могли бы служить аналогом того, для чего компании используют OCR — рукописные заметки, таблицы, старые финансовые документы, отсканированные счета-фактуры, квитанции, диаграммы, старые газеты, налоговые декларации, — а затем пропустил их все через 14 различных алгоритмов.
Идея заключалась в том, чтобы посмотреть, как они справляются с двумя задачами: восстановлением текста и сохранением полезной структуры таблиц.
Главный вопрос, на который я хотел получить ответ: действительно ли нужно платить 65 долларов за 1000 структурированных страниц , или можно снизить эту сумму до доли доллара? И превосходят ли специализированные модели универсальные?
В ходе подобных экспериментов всегда обнаруживается немало странных вещей, о которых я тоже расскажу. Но чтобы ответить на главный вопрос, я расскажу вам, что такое OCR (пропустите, если вам это незнакомо), об экономической стороне вопроса, о самом тесте, о некоторых результатах и о том, что еще это мне показало.
Примечание: Я не тестировал полное извлечение поля, поскольку сложно провести однозначное сравнение результатов на четырнадцати движках.
Вкратце:
Не существует единого лучшего механизма распознавания текста. Распознавание текста — это задача маршрутизации.
Для обработки большого объема чистых документов Tesseract по-прежнему остается лучшим вариантом, поскольку он бесплатный и быстрый. Для документов смешанного производства Gemini Flash оказался лучшим универсальным решением в этом тесте. Для таблиц Mistral OCR показал себя более дешевым вариантом для структурированной документации.
Небольшие специализированные модели хорошо работали в своей зоне комфорта, но гораздо хуже справлялись с документами, которые не видели. Поэтому для важных или сложных документов имеет смысл обратиться к более крупной модели.
Главный вывод носит экономический характер: не стоит платить за дорогостоящее структурированное оптическое распознавание текста, если документ в этом не нуждается. Классифицируйте свои документы, тестируйте алгоритмы на собственных данных и выбирайте маршруты, исходя из стоимости, точности, структуры и допустимого уровня ошибок.
Тестовые примеры полезны для анализа, но они не покажут, что работает именно с вашими документами.
Объясните мне, что такое пространство OCR.
Оптическое распознавание символов (OCR) — это способ, которым машина преобразует изображение в машиночитаемый текст. В принципе, это просто, и для простых документов эта задача в основном решена, но становится сложнее, когда речь идёт о человеческом восприятии.
Чтобы дать вам краткий обзор, более старые системы распознавания текста (OCR) находили текст на странице, разбивали его на символы и сопоставляли каждый из них с библиотекой известных геометрических фигур. Tesseract делает это с 1980-х годов.
Однако современные системы распознавания текста (включая более новые версии Tesseract) обычно используют нейронную сеть, которая анализирует всю страницу целиком и выводит документ в виде текста. Таким образом, если ваш документ представляет собой чистый PDF-файл или высококачественный скан со стандартным шрифтом, задача распознавания текста в большинстве случаев решена.
Решение перестаёт работать, как только ситуация становится ещё более запутанной: сфотографированные чеки, рукописные заметки, странные графики и диаграммы, сложные финансовые таблицы или отсканированные налоговые декларации и заявки на кредиты.
Компаниям необходимо, чтобы это было сделано качественно по очевидным причинам, поскольку с этим взаимодействует каждая последующая система. Чем лучше становится оптическое распознавание символов (OCR), тем больше документов система может анализировать самостоятельно, а не заставлять человека читать их вручную.
Кроме того, если мы будем передавать системам ИИ плохо обработанные документы, всему последующему будет трудно доверять.
Меня очень интересует экономика, поэтому эта область привлекла мое внимание, как только я увидел, сколько денег в нее вкладывается. По прогнозам, к началу 2030-х годов объем рынка интеллектуальной обработки документов (IDP) достигнет от 20 до 90 миллиардов долларов, в зависимости от того, какого аналитика вы спросите.
Вероятно, это связано с тем, что компании тратят 15–25 долларов на ручную обработку каждого счета-фактуры.
А поскольку я хорошо знаком с миром технологий, за последний год я наблюдал за появлением множества специализированных небольших моделей распознавания текста (в основном китайских), которые теперь используются разработчиками по всему миру.
Это поднимает вопрос, который я хотел проверить: могут ли небольшие модели с открытым исходным кодом действительно выполнять работу, за которую взимаются дорогостоящие API, или нам следует обратиться к универсальным моделям компьютерного зрения для обработки OCR?
Пропустите следующий раздел, если хотите понять, что показал этот эксперимент. Сначала мне нужно описать схему проведения эксперимента.
Документация, движки и метрики
В основе этого эксперимента лежат три вопроса: какие движки мы использовали, с какой документацией проводили тестирование и как определяли победителя.
Что касается движков, мне нужна была линейка, которая охватывала бы все варианты, о которых я говорил, а это означало: старые и новые, открытые и закрытые, локальные и облачные, специализированные и универсальные.
Tesseract стал классическим выбором. Он работает локально и очень быстро. Затем я добавил два конвейера для анализа документов: Docling и Marker . Docling медленнее, но работает на ЦП, Marker — это открытый алгоритм, но для быстрой работы ему требуется графический процессор, что отражается на цене.
Затем рассмотрим новую волну специализированных открытых моделей распознавания текста: GLM-OCR, PaddleOCR-VL, DeepSeek-OCR и MinerU 2.5 (пограничный случай, по сути, конвейер с VLM внутри). Я выбрал их из таблицы лидеров OmniDocBench от OpenDataLab, где они заняли первое, второе, четвертое и пятое места.
Я разместил их в Modal и запускал подходящие из них с помощью vLLM, используя пакетную обработку для ускорения процесса. Время масштабирования я зафиксировал позже при измерении задержки.
Я также добавил одну закрытую, специально разработанную модель, Mistral OCR , о которой слышал много хорошего.
Что касается открытых сервисов, я использовал Qwen3-VL (8B, с Alibaba), также размещенный на Modal вместе с остальными более мелкими моделями. Следует отметить, что я использовал для него обычную подсказку для транскрипции, а не оптимизированную конфигурацию обслуживания, для которой он был разработан, поэтому, возможно, я не дал ему справедливой оценки.
Что касается закрытых моделей, то для общего тестирования я выбрал Gemini Flash 3.1 Lite (в настоящее время занимает первое место в рейтинге IDP Leaderboard, западный аналог, построенный на OmniDocBench v1.5) и Claude Sonnet 4.6 , находящийся на шестом месте.
Что касается облачных сервисов для работы с документами: LlamaParse и AWS Textract , как в текстовом, так и в структурированном виде. Структурированный Textract способен на гораздо большее, чем я от него требовал. Я тестировал только его точность обработки текста и извлечение таблиц по сравнению с восемью другими движками.
Перейдём к документам . Я выбрал семнадцать типов документов, которые были либо лёгкими, либо средними, либо сложными. Всего девяносто три файла.
Простые задачи, которые OCR в основном решала много лет назад: чистые счета-фактуры и квитанции. Задачи средней сложности были взяты в основном из набора данных OmniAI OCR Benchmark: банковские выписки, медицинские справки, фотографии квитанций, транспортные документы, налоговые декларации.
Выбор варианта «сложно» пал, когда ситуация становилась более запутанной: диаграммы, формы, рукописные заметки, странно отсканированные финансовые таблицы, юридические документы, газеты и старые отчеты.
Некоторые документы оказались действительно сложными для обработки, например, старые отсканированные документы, которые вы видите ниже. И это просто потому, что мне было любопытно, смогут ли некоторые из них сделать это хорошо.
Некоторые из этих изображений имели эталонные данные, а некоторые — нет, и имеющиеся у меня эталонные данные не всегда были последовательными: некоторые файлы были помечены правильно, некоторые — нет. Именно поэтому нам следует кратко рассмотреть и метрики.
Поскольку каждый движок генерирует разную разметку, стандартные критерии оценки не совсем подходили. В подобных случаях можно было бы выбрать точность и полноту .
Показатель точности (Precision) отражает, сколько слов, полученных в результате распознавания текста, фактически совпадают с исходным текстом (GT), а показатель полноты (Recall) измеряет, сколько раз было распознано каждое слово из исходного текста.
Точность наказывала бы поисковые системы, которые выдают структуру Markdown, отсутствующую в GT, а также GT иногда полностью пропускала метки, что несправедливо наказывало бы систему. Полнота измеряла бы количество слов, но наказывала бы частоту встречаемости.
Поэтому я добавил третий показатель, который называется «Покрытие» . Я просто хотел измерить, насколько точное соответствие отображается в выходных данных движка. Это не идеальный показатель, но он показывает, обнаружил ли движок большую часть важной информации, не наказывая его за пробелы, которые возникли по вине самого движка, а не по его вине.
Для документов, в которых не было абсолютно никакой достоверной информации, я обратился к эксперту LLM, используя в качестве базовой модели Gemini 3 Pro, а любой, кто им пользовался, знает, что это довольно капризное дело.
Что показал этот эксперимент
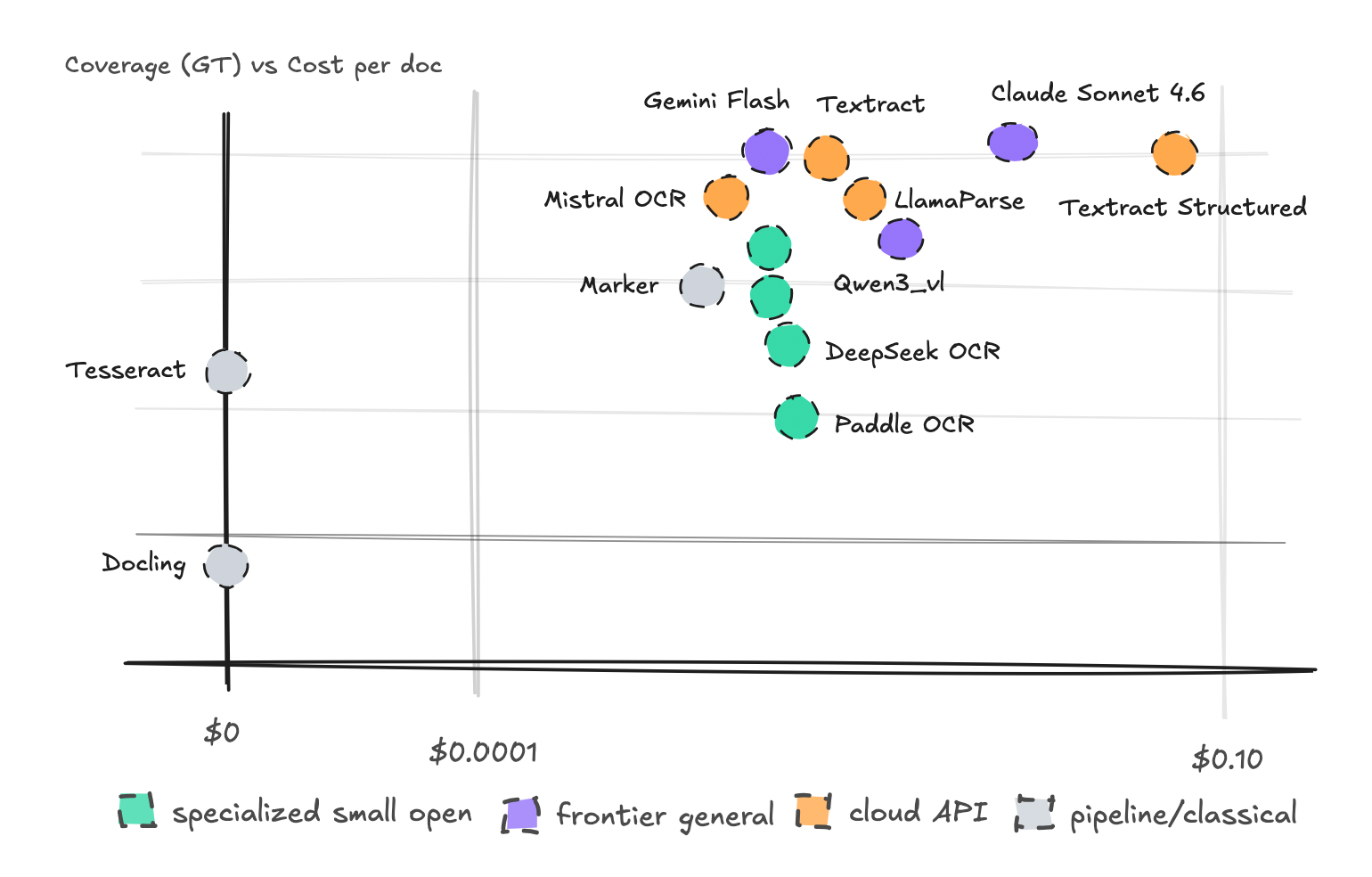
Мы сопоставили каждый документ с метрикой покрытия, чтобы построить диаграмму рассеяния, и отслеживали задержку на отдельной диаграмме. Однако обобщенная диаграмма не может показать, что сбои в работе движков происходили по-разному.
Пузырьковая диаграмма показала, что большинство двигателей находятся где-то в верхней средней части, с двумя выбросами по обе стороны от нее.
Gemini Flash и Textract Text показали очень хорошие результаты по всем параметрам, за исключением некоторых частных случаев. Специализированные модели уступили универсальным моделям и специализированным API. Sonnet показал лучшие результаты, но и стоил дороже.
Это, возможно, не стало неожиданностью, поскольку тестовый набор был весьма необычным. Некоторые из специализированных моделей, вероятно, встречались нечасто. Кроме того, тест проводился на английских документах, а большинство этих небольших моделей имеют китайское происхождение.
Когда мы также провели анализ задержки, некоторые модели оказались очень медленными, но большинство, опять же, показали результаты где-то посередине.
Исключениями здесь стали: Tesseract, Claude Sonnet 4.6 и Docling. Tesseract оказался невероятно быстрым по сравнению со всеми остальными движками. Он должен стать вашим основным инструментом для создания документов более простой формы.
Эти графики являются общими для всех документов, но я разделил результаты по типу и уровню сложности.
Начнём с простых документов. По счетам-фактурам все показали себя хорошо, особенно Tesseract. А вот квитанции немного подвели всех.
Единственным исключением стала компания Docling, которая испытывала трудности во многих категориях, даже в самых простых.
Когда я изучил ошибки Docling, я обнаружил такие вещи, как Ifjointreturn вместо “joint return”, и, что еще хуже, строки типа City,wrostffielfouaveaoreignadresalcomletacesb . DeepSeek также упустил ключевые детали, такие как номер и дата счета-фактуры, поэтому его рейтинг низкий.
Та же закономерность наблюдается и в категории среднего уровня, хотя именно здесь PaddleOCR начал демонстрировать снижение качества на отдельных типах документов: банковские выписки, квитанции о доставке, налоговые декларации. Налоговые декларации оказались сложными для всех, но PaddleOCR и Docling в итоге оказались в самом низу списка.
Textract был лучшим движком для распознавания текста на многих средних шрифтах, наряду с Claude Sonnet 4.6 и Mistral OCR.
На более сложных типах Gemini Flash начал набирать популярность, превосходя Textract на бланках и рукописных заметках, и сравнявшись с ним в других областях. Он показал себя замечательно везде. Tesseract и Docling потерпели сокрушительное поражение на рукописных заметках, и даже с бланками у них возникли трудности.
Практически все специализированные модели не справились с этими сложными документами, за исключением финансовых таблиц, где их результаты были примерно одинаковыми.
Для документов, не имеющих подтверждающих данных (газеты, юридические документы, отчеты, некоторые отсканированные старые документы), мы привлекли к работе судью с магистерской степенью. Эти документы действительно сложные, поэтому неудивительно, что почти все провалили экзамены по отчетам и газетам.
За исключением Gemini Flash, который показал себя довольно неплохо везде. Mistral OCR также хорошо показал себя в газетах. Gemini Flash победил везде по мнению экспертов, хотя мы использовали Gemini Pro в качестве эксперта, поэтому относитесь к этому с долей скептицизма (но я сам это перепроверил).
Перед завершением: я также протестировал 8 поисковых систем на Textract Structured, чтобы посмотреть, как они справятся с финансовыми таблицами, извлекая HTML-таблицу. Я использовал результаты Textract Structured в качестве эталонных данных для TEDS (Tree Edit Distance Similarity) и сравнил их с Claude Sonnet 4.6, LlamaParse, Mistral OCR, Gemini Flash, Marker, MinerU, DeepSeek-OCR и Docling.
Mistral OCR, LlamaParse и Sonnet показали очень хорошие результаты, при этом будучи значительно дешевле. Я также проверил их с помощью эксперта из LLM, и победителями стали те же три программы (даже до Textract Structured), хотя я бы хотел улучшить этот тест, прежде чем полностью ему доверять.
Теперь давайте поговорим о том, во сколько обойдется масштабирование этого проекта и где это будет целесообразно.
Когда то, что имеет смысл
Давайте рассмотрим, во сколько обходится масштабирование с использованием этих движков, а затем, исходя из этой документации, что вы бы выбрали для каждого варианта.
Во-первых, как вы уже видели, стоимость использования этих программных движков сильно варьируется. Иногда полезно видеть стоимость не только для одного документа, но и для тысяч, вплоть до миллиона.
Мы размещаем приложение на собственном сервере Modal, поэтому эти расходы покрываются фактическим использованием. Можно запустить его локально, но на моём компьютере это не получилось, и я не захотел пробовать.
Если использовать только один алгоритм, который обрабатывает как простые, так и сложные документы, то, думаю, счет окажется больше, чем необходимо. Использование Textract Structured для всех ненужных документов обойдется в 6,5 тыс. долларов за каждые 100 тыс. документов.
Мне интересно, сколько компаний идут по легкому пути, выбирая дорогостоящие варианты как для простых, так и для сложных документов, и при этом упускают значительную прибыль.
Главная мысль, которую следует усвоить, заключается в том, что не существует единого лучшего механизма для всех случаев использования; всё зависит от типа документа, конфиденциальности, структуры таблицы, отказоустойчивости, стоимости и так далее.
Что касается представленных здесь документов, Gemini Flash 3.1-Lite — явный победитель. Это подтвердилось, судя по рейтинговым таблицам. Mistral OCR хорошо справился со структурированными таблицами, оставаясь при этом недорогим. Claude Sonnet 4.6 тоже показал себя очень хорошо, но он сравнительно медленный и дорогой.
Docling работает на моем ноутбуке очень медленно. Я уверен, что есть способы ускорить его, но он также дал сбои, которые делают его по своей сути нестабильным (хотя это все же небольшой тест).
Специализированные модели распознавания текста доставили немало хлопот, особенно при работе с документами на английском языке; я также обнаружил ошибки в китайских документах, о которых расскажу чуть позже, поэтому мне интересно, не является ли это одной из причин.
Textract — это надежный вариант, но структурированный вывод практически не повышает точность текста, поэтому, если вы платите такую высокую наценку за структурированный вывод, убедитесь, что вы действительно им пользуетесь. Думаю, для них это довольно выгодная бизнес-модель.
Итак, в целом, для этого очень небольшого теста: для качественной печати больших объемов используйте Tesseract. Для общего гетерогенного производства — Gemini Flash. Для минимального уровня затрат с табличной структурой протестируйте Mistral OCR. Для документов с высокими требованиями используйте Sonnet или более крупную модель.
Поскольку у каждого всё получилось по-разному, вам придётся связаться со мной для уточнения деталей, но если вам нужно обратиться в частный сектор, возможно, стоит подумать о тонкой настройке модели в ваших документах. Или же используйте небольшую специализированную модель и сообщайте о сбоях вышестоящему руководству.
Позвольте мне вкратце рассказать о некоторых вещах, которые бросились в глаза после проведения этого эксперимента.
Есть и другие вещи, о которых я должен упомянуть.
В результате этого всплыло несколько моментов, которые заслуживают отдельного внимания.
Во-первых, если вы хотите понять, как модель или движок будут работать с вашими документами, единственный способ — протестировать их на этих документах ; нельзя полагаться на бенчмарки . Это был главный вывод, который показал данный эксперимент. Полезность OCR зависит от состава ваших документов, их макетов, языков, качества сканирования, таблиц, рукописного ввода и допустимого уровня ошибок.
Не платите за структуру, если она вам не нужна. Интересно, сколько людей используют определенные API или модели по причинам, которые они не могут обосновать. Составьте карту затрат, чтобы понять, что вы теряете, не используя правильный механизм для работы с документами.
Как уже упоминалось, специализированные модели имеют четкие границы. Это очевидно: они могут быть превосходны в рамках своей обучающей выборки, но терпеть неудачу за ее пределами. Именно здесь универсальные модели окажутся более эффективными.
Если вы хотите выполнить более точную настройку, это может помочь, но только если поток стабилен, поскольку он также будет давать сбои, если постоянно добавляются новые классы документов.
Наконец, анализ причин отказов дал нам больше информации, чем усредненные значения.
В PaddleOCR присутствуют циклы повторения, слияние столбцов, а также использование шаблонного текста из китайского учебника, например书名:___ повторяющегося сотни раз. В Docling же наблюдаются ошибки символов, слияние слов и смещение столбцов, которые накапливаются одновременно.
Функция распознавания текста DeepSeek OCR не распознает текст и выдает пустые результаты в некоторых документах. Tesseract хорошо справлялся с чистыми документами (как уже упоминалось), но полностью проваливал обработку фотографий и рукописного текста, выдавая бессмысленный результат.
Следует учитывать ряд оговорок.
Прежде чем подвести итог, позвольте мне рассказать о том, почему этот тест в конечном итоге несовершенен, указав на проблемы, описанные в GT, используемые метрики и размер выборки.
Я уже затрагивал этот вопрос в одном из разделов выше, но истинные значения различаются для разных документов в зависимости от набора данных, в котором они были найдены. В целом, артефакты токенизации могут привести к тому, что правильное распознавание текста будет выглядеть хуже, чем есть на самом деле.
Большинство поисковых систем работают с разными форматами: одни возвращают обычный текст, другие — разметку Markdown, третьи — HTML/расширенную разметку Markdown, и сложно дать обобщение для всех случаев.
Мы используем Coverage , а также некоторые другие метрики, но они не идеальны. Coverage не будет начислять баллы поисковой системе, если она выдает слишком много текста или его структура некорректна. Хотя я обнаружил, что у поисковых систем, которые давали сбой, это происходило в начале или середине процесса, а не в конце.
Это означает, что он полезен для ранжирования, но не является идеальным способом оценки.
Судьи, рассматривающие магистерские диссертации, не являются объективными источниками истины: я уже говорил об этом раньше, но они предвзяты и очень чувствительны к срочным решениям.
Тогда я просто хочу сказать, что этот тест интересен, но не настолько масштабен, размер выборки слишком мал, чтобы использовать его в качестве фактического исследования. Но я не полностью доверяю этим показателям и эксперту, поэтому это был единственный способ для меня перепроверить результаты самостоятельно, не превращая это в проект на целый год.
Таким образом, этот тест полезен для определения направления работы и понимания того, что работает, но для того, чтобы понять, как это будет работать в вашем конкретном случае, вам нужно провести его с использованием вашей конкретной документации.
Наконец, следует отметить нестабильность задержки и воспроизводимости. Холодные запуски бессерверных приложений приводят к неточности синхронизации, а модели API могут незаметно меняться со временем, поэтому точное воспроизведение затруднено.
Как всегда в случае с подобными статьями, проведение такого эксперимента требует немалых усилий, но я делаю это не просто ради контента, а из искреннего любопытства.
Однако, похоже, проблема с распознаванием текста (OCR) связана с маршрутизацией, а возможно, и с оценкой результатов. Классифицируйте документы и пропустите их через несколько алгоритмов распознавания, затем попробуйте создать в своем конвейере корректный маршрутизатор и валидатор для обработки сбоев и регистрации затрат.
Если вам нужны полные результаты этого эксперимента или вы хотите, чтобы я проверил их на ваших документах, свяжитесь со мной.
Вы можете следить за моими публикациями на Medium, на моем сайте или связаться со мной через LinkedIn.
❤
Все наборы данных, использованные в этом сравнительном тесте, находятся в открытом доступе и получены от HuggingFace. Лицензии включают MIT, CC-BY-4.0 и добросовестное использование (библиотека отраслевых документов UCSF), охватывающее исследования, научную работу и образование. Исходные документы не воспроизводятся — наборы данных использовались исключительно в качестве входных данных для оценки производительности механизма распознавания текста.
Ида Сильфвершельд Посмотреть все работы Иды Сильфвершельд
Источник: towardsdatascience.com
Оцените материал:


