Together AI научились ужимать KV-кэш LLM до 2 бит —…
Together AI научились ужимать KV-кэш LLM до 2 бит — почти без потери качества
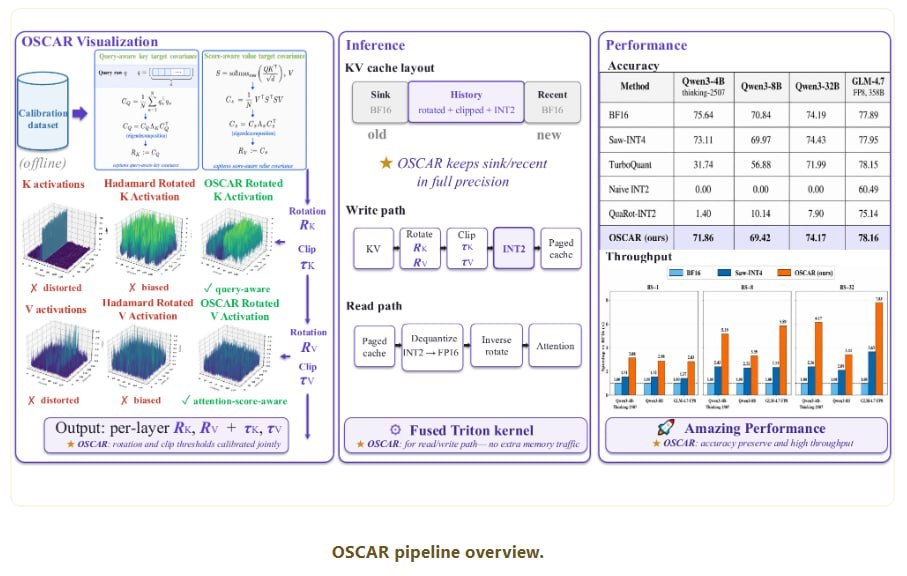
Together AI выложила OSCAR — систему экстремального сжатия KV-кэша до 2 бит.
И это одна из самых важных optimization-тем для LLM прямо сейчас.
Почему вообще все воюют за KV-cache:
при длинных контекстах именно KV-кэш начинает жрать огромную часть VRAM.
Из-за этого:
— падает throughput
— растёт стоимость инференса
— уменьшается число параллельных запросов
Раньше попытки ужать кэш до 2-bit обычно ломали качество генерации.
OSCAR пытается обойти проблему через «умное вращение» активаций перед квантованием.
Что делает метод:
— собирает статистику attention
— строит covariance matrices
— вычисляет layer-specific rotation
— применяет Hadamard transform
— делает bit-reversal permutation
— только потом квантует кэш
При этом:
— первые 64 токена
— и последние 256 токенов
хранятся в полном BF16 как опорные.
Остальное — в 2-bit.
Результаты выглядят очень серьёзно:
На:
— AIME25
— GPQA
— HumanEval
— LiveCodeBench
— MATH500
качество остаётся близко к BF16.
Например:
— Qwen3-32B → почти без потерь
— GLM-4.7-FP8 → почти совпадает с BF16
А на H100:
— speedup при 100k context:
— 2.8–3.1x
Главное ограничение:
на маленьких моделях degradation всё ещё заметен на сверхдлинных контекстах.
Но для крупных моделей результаты уже выглядят очень практично.
Поддерживается:
— paged attention
— интеграция в SGLang
— Apache 2.0 license
Похоже, следующая большая гонка в LLM — уже не только «кто умнее», а «кто сможет впихнуть больше контекста в меньшее количество VRAM».

Оцените материал:


