Структура с дифференциальной приватностью для получения информации об использовании чат-ботов на основе ИИ.
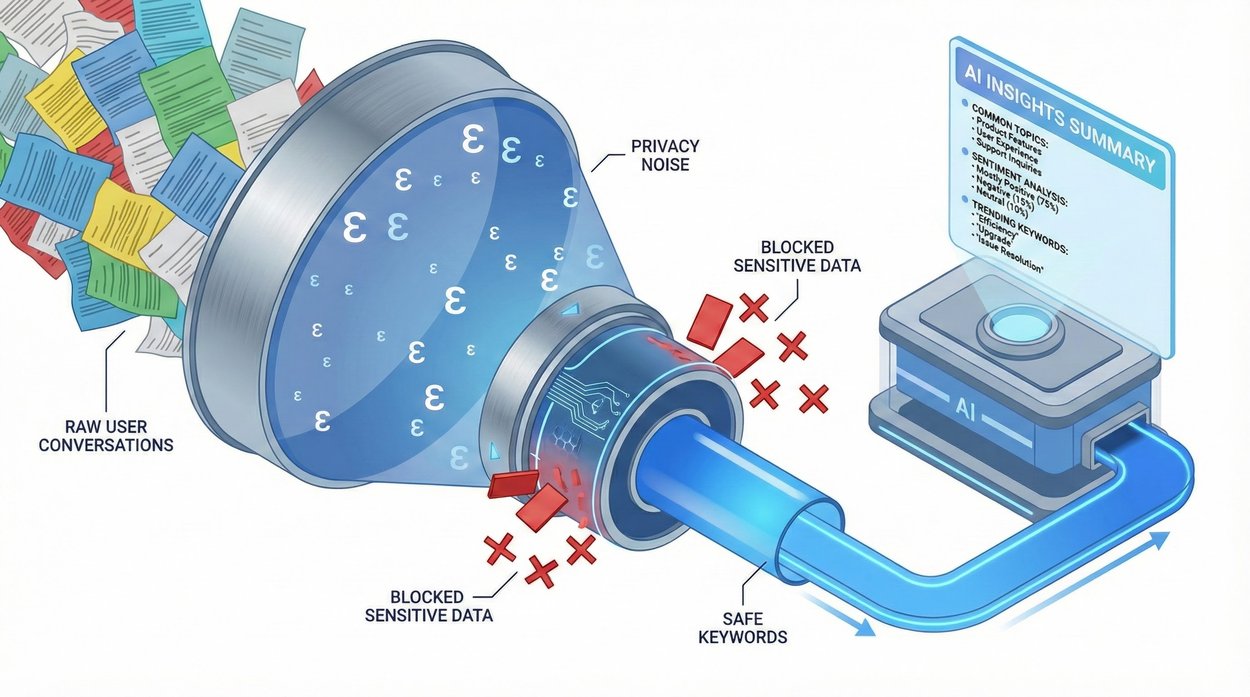
Представляем новую структуру, которая генерирует высокоуровневые аналитические данные об использовании чат-ботов с искусственным интеллектом посредством конвейера кластеризации данных о пользователях, извлечения ключевых слов из данных о пользователях и суммирования LLM. Этот подход обеспечивает строгие сквозные гарантии данных о пользователях, гарантируя конфиденциальность диалогов с пользователями и одновременно предоставляя возможности для улучшения платформы.
Быстрые ссылки
- Бумага
- Делиться
Чат-боты на основе больших языковых моделей (LLM) ежедневно используются сотнями миллионов людей для решения самых разных задач: от составления электронных писем и написания кода до планирования отпусков и создания меню для кафе. Понимание этих высокоуровневых сценариев использования невероятно ценно для поставщиков платформ, стремящихся улучшить сервисы или внедрить политику безопасности. Это также дает общественности представление о том, как искусственный интеллект меняет наш мир.
Но это поднимает важный вопрос: как мы можем получить ценные сведения, если сами разговоры могут содержать личную или конфиденциальную информацию?
Существующие подходы, такие как структура CLIO, пытаются решить эту проблему, используя модель LLM для обобщения разговоров, одновременно заставляя её удалять персональные данные. Хотя это хороший первый шаг, этот метод основан на эвристической защите конфиденциальности. Полученную гарантию конфиденциальности сложно формализовать, и она может оказаться неэффективной по мере развития моделей, что затрудняет поддержку и аудит таких систем. Это ограничение заставило нас задаться вопросом, возможно ли достичь аналогичной эффективности с помощью формальных, сквозных гарантий конфиденциальности.
В нашей статье «Urania: Анализ использования ИИ с учетом дифференцированной конфиденциальности», представленной на конференции COLM 2025, мы представляем новую структуру, которая генерирует аналитические данные из взаимодействий чат-ботов LLM с жесткими гарантиями дифференцированной конфиденциальности (ДПК). Эта структура использует алгоритм кластеризации ДПК и метод извлечения ключевых слов, чтобы гарантировать, что ни один отдельный разговор не оказывает чрезмерного влияния на результат (т.е. выходные сводки не раскрывают информацию о разговоре какого-либо отдельного человека). Здесь мы объясняем алгоритм и демонстрируем, что эта структура действительно обеспечивает лучшие гарантии конфиденциальности, чем предыдущие решения.

Изображение, созданное Gemini, схематически демонстрирует работу алгоритма для одной группы диалогов.
Система, обеспечивающая конфиденциальность при анализе данных.
В DP используется параметр бюджета конфиденциальности ε для измерения максимально допустимого влияния вклада любого отдельного пользователя на конечный результат модели. Наша структура основана на двух ключевых свойствах DP:
- Постобработка: Если B — алгоритм ε -DP, а A — любой алгоритм, не являющийся алгоритмом DP, то выполнение A на выходных данных B обеспечивает конфиденциальность на уровне ε -DP.
- Композиция: Если A и B — два отдельных ε -DP алгоритма, то запуск A на наборе данных и результатах работы B по-прежнему обеспечивает конфиденциальность всего процесса на уровне 2ε -DP.
Данный конвейер с дифференцированной приватностью разработан для обеспечения сквозной защиты пользовательских данных на следующих этапах:
- Кластеризация на основе динамического программирования : Сначала диалоги преобразуются в числовые представления (встраивания). Затем структура группирует представления, расположенные близко друг к другу, с помощью алгоритма кластеризации на основе динамического программирования. Это гарантирует, что ни один отдельный диалог не будет чрезмерно влиять на центры кластеров.
- Извлечение ключевых слов с помощью динамического программирования : Ключевые слова извлекаются из каждого диалога. Для каждого кластера наш подход вычисляет гистограмму ключевых слов, то есть подсчитывает количество раз, когда каждое ключевое слово встречается в кластере, используя механизм гистограммы динамического программирования (например, [1, 2]). Мы добавляем шум к гистограмме, чтобы замаскировать влияние отдельных диалогов, гарантируя, что выбираются только ключевые слова, общие для нескольких пользователей, предотвращая раскрытие уникальных или конфиденциальных терминов. Мы рассматриваем три метода создания ключевых слов для каждого диалога:
- Выбор ключевых слов под руководством магистра права: Мы предоставляем магистру права вести беседу и просим его составить список из пяти наиболее релевантных ключевых слов;
- Версия TF-IDF для динамического программирования: мы получаем все слова из разговора и присваиваем им вес пропорционально количеству их употреблений в тексте и обратно пропорционально количеству их употреблений в корпусе;
- Подход, основанный на использовании LLM, предполагает наличие исходного списка ключевых слов, полученных из общедоступных данных: вместо того, чтобы просить LLM самостоятельно генерировать ключевые слова для каждого разговора, мы создаем список потенциальных ключевых слов и просим LLM выбрать 5 наиболее релевантных ключевых слов из этого списка.
- LLM-суммирование на основе ключевых слов : В конечном итоге, LLM-система генерирует высокоуровневое резюме для каждого кластера, используя только выбранные вручную ключевые слова. LLM-система никогда не видит исходные беседы в кластере, только анонимизированные ключевые слова. Это свойство постобработки обеспечивает сквозную конфиденциальность всей системы.
Схема потока данных в рамках данной структуры. Желтые узлы обозначают данные, не относящиеся к DP (данные о защите данных), зеленые узлы представляют операции, относящиеся либо к DP, либо к каждому диалогу, светло-голубые узлы обозначают частные данные, а темно-синие узлы представляют операции, не относящиеся к частной информации.
Благодаря интеграции защиты данных в основу этой структуры, гарантии конфиденциальности являются математическими, а не эвристическими. Они не зависят от способности LLM идеально скрывать конфиденциальные данные: другими словами, даже если ключевые слова содержат персональные данные или другую конфиденциальную информацию, сгенерированные резюме не будут содержать этих данных. На практике эта гарантия делает невозможным раскрытие конфиденциальных данных со стороны LLM (например, из-за атак с внедрением мгновенных данных).
Проверка этой структуры на практике
Для оценки полезности нашей системы (качество сводных данных) и уровня конфиденциальности (сила защиты) мы сравнили ее производительность с Simple-CLIO, базовым показателем без приватности, который мы создали по образцу CLIO. Базовый показатель построен в два этапа:
- Диалоги преобразуются в векторные представления и группируются в неконфиденциальные кластеры.
- Для каждого кластера в LLM подается образец разговоров для генерации сводной информации по этим образцам.
Компромисс между конфиденциальностью и полезностью
Как и ожидалось, мы наблюдали компромисс: более жесткие настройки конфиденциальности (более низкие значения параметра конфиденциальности ϵ ) приводили к снижению детализации сводок. Например, охват тем снижался по мере ужесточения бюджета конфиденциальности, поскольку алгоритм кластеризации DP создавал меньше кластеров и менее точных кластеров.
Однако результаты оказались неожиданными. В прямых сравнительных тестах эксперты LLM часто отдавали предпочтение закрытым резюме, сгенерированным нашей системой. В одном из тестов резюме, сгенерированные с помощью DP, были предпочтительнее до 70% случаев. Это говорит о том, что ограничения, накладываемые этим конвейером DP — заставляющие создавать резюме на основе общих, часто встречающихся ключевых слов — могут приводить к более лаконичным и целенаправленным результатам, чем те, которые получаются при использовании неограниченного, не закрытого подхода.
Эмпирическая оценка конфиденциальности
Для проверки устойчивости разработанной системы мы провели атаку, имитирующую вывод о принадлежности данных к группе, с целью определить, включен ли конкретный конфиденциальный разговор в набор данных. Результаты были очевидны: атака на конвейер обработки данных о конфиденциальности показала примерно такие же результаты, как и случайное угадывание, достигнув показателя площади под кривой (AUC) 0,53 (т.е. интеграла ROC- кривой). В отличие от этого, атака оказалась более успешной против конвейера обработки данных без приватности, у которого AUC был выше — 0,58, что указывает на большую утечку информации. Этот эксперимент предоставляет эмпирические доказательства того, что наша система защиты конфиденциальности обеспечивает значительно более надежную защиту от утечки конфиденциальной информации.
Кривая ROC для конвейера DP демонстрирует производительность, близкую к случайному угадыванию (AUC = 0,53), что подтверждает его устойчивость.
Кривая ROC для нечастного трубопровода более уязвима (AUC = 0,58).
Взгляд в будущее
Наша работа — это первый шаг к созданию систем, способных анализировать крупномасштабные текстовые корпуса с формальными гарантиями конфиденциальности. Мы показали, что можно найти баланс между необходимостью получения значимых результатов и строгой защитой конфиденциальности пользователей.
В перспективе мы видим несколько интересных направлений для будущих исследований. К ним относятся адаптация структуры для онлайн-среды, где постоянно добавляются новые диалоги, изучение альтернативных механизмов защиты данных для дальнейшего улучшения компромисса между полезностью и конфиденциальностью, а также добавление поддержки многомодальных диалогов (т.е. диалогов, включающих изображения, видео и аудио).
По мере того как ИИ все больше интегрируется в нашу повседневную жизнь, разработка методов, обеспечивающих конфиденциальность при понимании его использования, становится не просто технической задачей, а фундаментальным требованием для создания заслуживающего доверия и ответственного ИИ.
Благодарности
Благодарим всех участников проекта, чьи неоценимые усилия сыграли решающую роль в его успехе. Особая благодарность нашим коллегам: Яниву Кармелю, Эдит Коэн, Рудраджиту Дасу, Крису Дибаку, Вадиму Дорошенко, Алессандро Эпасто, Прему Эрувбетину, Дему Геролему, Бадиху Гази, Мигелю Геваре, Стиву Хе, Питеру Кайрузу, Притишу Каматху, Ниру Керему, Рави Кумару, Итану Лиману, Пасину Манурангси, Шломи Пастернаку, Михаилу Правилову, Адаму Сеалфону, Юрию Сушко, Да Ю, Чиюаню Чжану.
Источник: research.google
Оцените материал:
