Последовательная подгонка: иной взгляд на спектральную предвзятость нейронных сетей.
Что упускает анализ Фурье
Делиться

Конор Роуэн и Финн Мерфи-Бланшар
Введение
Как показывают результаты их успешного решения сложных задач, таких как классификация изображений [1], автономность [2] и моделирование языка [3], нейронные сети демонстрируют впечатляющие результаты в аппроксимации многомерных нелинейных функций на основе данных. Фактически, нейронные сети обладают настолько мощными репрезентативными возможностями, что могут достичь нулевой ошибки обучения на изображениях со случайными метками классов, то есть в обучающих данных отсутствует структура, которую сеть могла бы использовать [4]. Несмотря на эту гибкость, класс моделей нейронных сетей, по-видимому, обеспечивает полезную индуктивную предвзятость для многих реальных задач, поскольку нейронные сети часто лучше обобщают данные на неизвестные тестовые данные, чем другие типы моделей [5]. Однако регрессия с использованием нейронных сетей имеет серьезный недостаток, известный в литературе как «спектральная предвзятость».
Популяризированная в 2019 году концепция спектрального смещения утверждает, что нейронные сети подгоняют целевые значения регрессии от низких частот к высоким [6]. Как показано на рисунке 1, нейронная сеть сначала изучает низкочастотное содержание функции, прежде чем уточнять подгонку для захвата более высоких частот. Как принято в этой литературе, мы понимаем «частотное содержание» целевой функции регрессии как результат ее преобразования Фурье.
Поскольку сети подгоняют целевую функцию в порядке возрастания частоты, обучение высокочастотным функциям часто происходит довольно медленно, требуя большого количества эпох обучения. Последующие работы подтвердили трудности, с которыми сталкиваются сети при подгонке высокочастотных функций, и предложили объяснения этого интригующего явления. Некоторые авторы объяснили спектральную предвзятость, изучая спектр Фурье популярных функций активации (например, ReLU, гиперболический тангенс, сигмоидная функция и т. д.), отмечая, что их спектры быстро затухают на высоких частотах, и, следовательно, сеть по своей природе предвзята в отношении обучения низким частотам [7,8].
Влиятельный подход, называемый нейронным касательным ядром (NTK), предлагает элегантное объяснение спектрального смещения, показывая, что в пределе сети бесконечной ширины выход сети эволюционирует в соответствии с линейной динамической системой. Используя теорию линейных динамических систем для разложения выхода сети на ортогональные моды, авторы в [9] показывают, что скорость сходимости обратно пропорциональна частотному составу моды. Эта работа предложила убедительное теоретическое объяснение спектрального смещения нейронных сетей.
Ряд других работ исследовал спектральное смещение в различных сетевых архитектурах и алгоритмах оптимизации. Например, в одной работе было показано, что для широких двухслойных сетей с активацией ReLU процесс обучения можно интерпретировать как задачу оптимизации с ограничениями, в которой высокочастотные компоненты решения штрафуются сильнее [10]. В [11], отмечая, что в исходном анализе NTK предполагается, что обучение проводится с использованием градиентного спуска, авторы уточняют, что спектральное смещение наблюдается и с другими оптимизаторами.
Совсем недавно с эмпирической и теоретической точек зрения было показано, что стратегии оптимизации квазиньютоновского типа второго порядка — то есть стратегии, основанные на аппроксимации матрицы Гессе функции потерь — могут уменьшить спектральное смещение для нейронных сетей, используемых в научных приложениях машинного обучения [12]. Здесь, опираясь на анализ NTK, показано, что предварительная обработка с помощью матрицы Гессе помогает выровнять скорость сходимости мод разных частот, тем самым ускоряя процесс обучения.
Хотя много внимания уделяется пониманию происхождения спектрального смещения, ряд исследователей предложил стратегии для его устранения. Использование оптимизации второго порядка является одной из таких стратегий, другие включают модификации архитектуры сети. Замена стандартных активаций периодическими функциями, такими как синусоиды, — это одна из архитектурных модификаций, известная как сеть SIREN [13]. Другая популярная архитектура — это сеть признаков Фурье, которая вместо модификации функций активации поднимает входные данные в многомерное пространство с периодическими вложениями на случайных частотах [14,15]. В контексте научного машинного обучения было показано, что признаки Фурье улучшают производительность для многомасштабных дифференциальных уравнений в частных производных [16].
Успех стандартных архитектур нейронных сетей (многослойные персептроны, сверточные сети и т. д.) в основном направлении машинного обучения свидетельствует о том, что аппроксимация высоких частот не является узким местом для многих областей применения. Однако неспособность надежно или эффективно аппроксимировать высокочастотные функции может стать проблемой в научных приложениях, где многомасштабные задачи и задачи распространения волн в значительной степени зависят от осциллирующих полей решений. Хотя оптимизация второго порядка, сети SIREN и фурье-функции представляют собой успешные способы решения проблемы спектрального смещения, мы считаем, что спектральное смещение само по себе является интересной проблемой.
Хотя спектр Фурье функции активации дает некоторое представление о происхождении спектрального смещения для общих задач обучения нейронных сетей, а NTK предоставляет объяснение в случае сетей бесконечной ширины, мы считаем, что возможно более интуитивное понимание спектрального смещения. В этой статье мы утверждаем, что во многих случаях спектральное смещение многослойных перцептронов (MLP) с активацией в виде гиперболического тангенса можно понять с точки зрения того, что мы называем «последовательной подгонкой». Мы определяем последовательную подгонку как процесс подгонки нейронными сетями целевой функции, начиная с границы и затем продвигаясь в область определения, создавая по одному колебанию целевой функции за раз. Мы показываем, что такое поведение сохраняется на ряде примеров задач в одном и двух пространственных измерениях, а также находим доказательства «граничного эффекта», при котором процесс обучения зависит не только от частотного состава целевой функции, но и от ее поведения вблизи границ.
Наконец, мы интерпретируем эти результаты, используя «базис», изученный нейронной сетью, а именно набор функций, определяемых последним слоем сети. Мы показываем, что при аппроксимации высокочастотных функций эти сети итеративно строят базис типа ступенчатой функции, который, по нашему мнению, дает дополнительное представление о спектральном смещении.
Одномерная регрессия
Последовательная подгонка
В следующих примерах мы работаем с двухслойными многослойными нейронными сетями с функциями активации в виде гиперболического тангенса. Сеть можно записать в явном виде следующим образом:
[ u(mathbf x; boldsymbol theta ) = mathbf w^3 cdot tanh( mathbf w^2 ( tanh(mathbf w^1 mathbf x + mathbf b^1)) + mathbf b^2 ), quad boldsymbol theta=[ mathbf w^3 , mathbf w^2 , mathbf b^2 , mathbf w^1 , mathbf b^1] ,]
где (boldsymbol theta) — совокупность всех обучаемых параметров (весов и смещений) сети, (mathbf x in Omega) — пространственная координата (одномерная или двумерная), а (Omega) — вычислительная область. Ширина двух скрытых слоев считается одинаковой, и мы обозначаем эту ширину как ( H ). Мы называем целевую функцию (v(mathbf x)) и определяем целевую функцию обучения как
[ underset{boldsymbol theta}{text{argmin }} frac{1}{2} int Big( u(mathbf x ; boldsymbol theta) – v(mathbf x) Big)^2 dOmega. ]
Для демонстрации явления, которое мы называем последовательной подгонкой, начнем с одномерной задачи регрессии в единичной области, например, ( Omega =[0,1] ), с целевой функцией, заданной как ( v(x) = sin(26 pi x) ). Ширина сети составляет ( H=100 ), а задача регрессии решается с помощью оптимизации ADAM с использованием скорости обучения ( 5 times 10^{-3}). Интеграл в целевой функции аппроксимируется методом средней точки на равномерной сетке с (500) точками. Если не указано иное, все последующие одномерные примеры будут решаться с использованием этой архитектуры сети и правила интегрирования, а также этих параметров оптимизации. Количество эпох обучения будет отображаться на графиках, показывающих ход подгонки, и, следовательно, указываться в каждом конкретном случае. Результаты решения этой первой задачи представлены на рисунке 2. Нейронная сеть инициирует процесс подгонки вблизи границ, а затем итеративно продвигается к центру области, подгоняя по одному колебанию высокочастотной целевой частоты за раз. Это явление мы называем последовательной подгонкой. Отметим, что этот рисунок, как и все последующие рисунки, был создан авторами.
Второй пример показывает, как огибающая осцилляторной функции влияет на процесс обучения. Если последовательная подгонка начинается на границах, мы предполагаем, что поведение функции вблизи границ области может влиять на обучение. В частности, мы проверяем случай, когда функция огибающей обнуляет амплитуду колебаний на одном конце области. Наша целевая функция — (v(x)=sqrt{x} sin(26 pi x)), где огибающая (sqrt{x}) подавляет колебания на левом конце области. Результаты показаны на рисунке 3. Процесс последовательной подгонки начинается на правой стороне области, где колебания имеют большую амплитуду. Как и прежде, сеть подгоняет по одному колебанию за раз, за исключением того, что теперь процесс является односторонним в результате подавления колебаний на левой границе. Этот пример мотивирует дальнейшее исследование влияния поведения целевой функции вблизи границы, что является предметом рассмотрения в следующем разделе.
Граничные эффекты
Предыдущий пример показал, что на процесс подгонки может влиять не только частотный состав, но и поведение целевой функции вблизи границы. Яркая демонстрация влияния поведения границы наблюдается при подгонке целевой функции (v(x)=4x(1-x)sin(26 pi x)). Здесь параболическая огибающая функция приводит к затуханию колебаний до нулевой амплитуды на обоих концах области. На рисунке 4 показана подгонка нейронной сетью за (7500) эпох обучения. Удивительно, но сеть не продвигается в направлении представления целевой функции, очевидно, из-за малых амплитуд колебаний на обеих границах. Сравните это с подгонкой (v(x)=4(x-1/2)^2 sin(26 pi x)), очень похожей целевой функции, но подавляющей колебания в центре области, а не на концах. На рисунке 5 показано, что последовательная подгонка теперь ведет себя, как и ожидалось: сеть начинает работу с двух концов области, а затем симметрично движется внутрь, создавая одно колебание за раз, пока целевая функция обучения не станет приблизительно равной нулю.
В литературе стандартные представления о спектральном смещении рассматривают сложность задачи регрессии как зависящую в первую очередь от частотного состава целевой функции, а не от других характеристик, таких как её поведение вблизи границы области определения. Два приведённых выше примера показывают, что поведение целевой функции на границе области определения действительно существенно влияет на сложность задачи регрессии, измеряемую количеством эпох, необходимых для получения малой ошибки обучения. Однако читатель может возразить против этого утверждения, аргументируя это тем, что две огибающие функции существенно изменяют частотный состав целевой функции, хотя обе умножают одну и ту же осцилляционную функцию ((sin(26 pi x))). Чтобы показать, что это не так, мы используем дискретное преобразование Фурье (ДПФ) для вычисления спектров Фурье двух целевых функций. ДПФ целевой функции представляет собой
[ F[m] = sum_{j=0}^{499} v(x_j) exp( -i 2pi mj/500), ]
где (F[m]) — комплексные коэффициенты Фурье, а (x_j) — точки интегрирования. Заметим, что, поскольку целевая функция является вещественной, коэффициенты Фурье обладают эрмитовой симметрией, то есть (F[m] = overline{F[500-m]}). Напомним, что величина коэффициента Фурье дает вклад синусоиды со сдвигом фазы и частотой (2pi m) в разложение Фурье целевой функции. Интересуясь этой величиной как мерой частотного содержания целевой функции, эрмитова симметрия показывает, что только половина частотного спектра является независимой, поскольку сопряженное комплексное число имеет ту же величину.
Таким образом, на рисунке 6 сравнивается величина первой половины спектра ДПФ для двух целевых функций. Их спектры различаются только величиной коэффициента Фурье при (m=13), что отражает тот факт, что две функции отличаются лишь на множитель (sin( 26 pi x)), что можно увидеть, разложив квадрат во второй из двух огибающих функций. Этот пример показывает, что частотный состав целевой функции регрессии может быть не единственным фактором, определяющим сложность процесса подгонки. Мы называем это явление «граничным эффектом», указывая на то, что две функции с похожими спектрами Фурье могут вести себя по-разному в качестве целевых функций регрессии из-за их поведения вблизи границ областей.
Перспектива базисной функции
Другой аспект спектрального смещения, который, насколько нам известно, не рассматривался в литературе, связан с базисными функциями, построенными сетью. Возвращаясь к сети с двумя скрытыми слоями, мы принимаем базис (mathbf h(mathbf x) = { h_i(mathbf x) }_{i=1}^{H}) за функции, определенные последним скрытым слоем сети:
[ mathbf h(mathbf x ) = tanh( mathbf w^2 ( tanh(mathbf w^1 mathbf x + mathbf b^1)) + mathbf b^2 ). ]
Нас интересует, как эти функции изменяются в процессе обучения. Возвращаясь к примеру, показанному на рисунке 2 (целевая функция (v(x) = sin(26 pi x))), мы строим график набора базисных функций на дискретных эпохах обучения, при этом прозрачность пропорциональна коэффициенту, соответствующему каждой базисной функции. Другими словами, представление сети задается формулой (u(x) = sum_{i=1}^{H} w^3_i h_i(x)), поэтому при построении графика (h_i(x)) мы устанавливаем его прозрачность пропорциональной (|w^3_i|). Наша цель с помощью этих графиков — визуализировать базисные функции, которые вносят наибольший вклад в выходные данные сети, и мы называем их соответствующими базисными функциями. Эволюция соответствующего набора базисных функций показана на рисунке 7.
На этом графике видно, что каждая базисная функция представляет собой сглаженную ступенчатую функцию, отражающую одно колебание целевой функции. Фактически, это позволяет понять процесс последовательной подгонки: сеть строит ступенчатые базисные функции, начиная сначала с границ, а затем, по мере необходимости, сдвигая и увеличивая крутизну базисных функций для представления колебаний внутри области. Интересно, что сами базисные функции не обладают никаким колебательным поведением, несмотря на то, что сеть с двумя скрытыми слоями способна это представить.
Чтобы понять это, отметим, что базисные функции сети с двумя скрытыми слоями определяются сетью с одним скрытым слоем, которая, как известно, является универсальным аппроксиматором. Мы считаем, что подход с использованием базисных функций дает следующее понимание спектрального смещения: если базис, изучаемый сетью, состоит из сглаженных ступенчатых функций, то каждое колебание в целевом сигнале должно быть представлено как комбинация двух базисных функций. И, как показывает явление последовательной подгонки, если это происходит итеративно, то есть сеть может работать только с одним колебанием за раз, неудивительно, что стандартные многослойные перцептроны крайне медленно подгоняют высокочастотные функции.
В заключение, касательно примера одномерной регрессии, отметим, что архитектурные модификации сети исключают процесс последовательной подгонки. Например, если мы переключимся на сеть SIREN, заменив активацию (tanh(cdot)) на (sin(2(cdot))), сами базисные функции будут иметь осциллирующее поведение, и последовательная подгонка не будет происходить. См. рисунок 8, где показаны базисные функции, полученные из сети SIREN с той же целевой функцией регрессии.
Двумерная регрессия
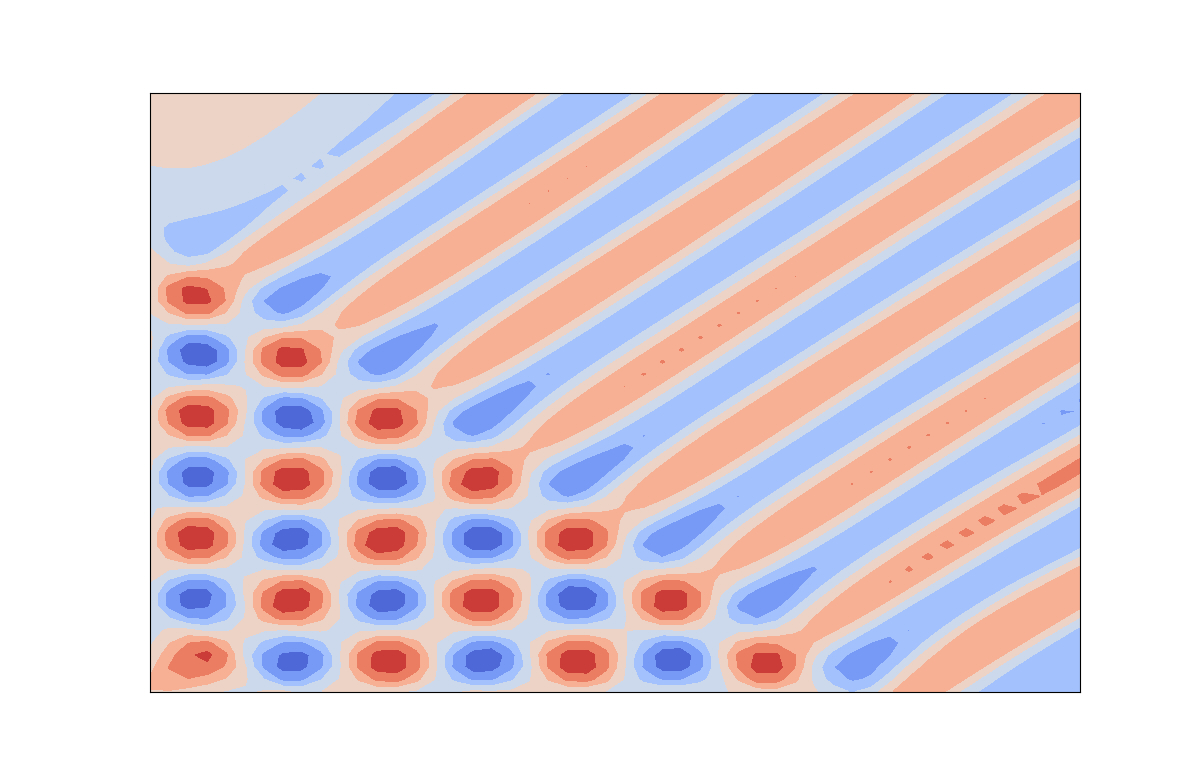
Теперь мы расширяем наше исследование спектрального смещения на двумерные задачи регрессии. В частности, мы исследуем, сохраняется ли явление последовательной подгонки также в двух пространственных измерениях. Для этого мы устанавливаем нашу вычислительную область в виде единичного квадрата (Omega=[0,1]^2) и выполняем интегрирование по средней точке с (2500) равномерно расположенными точками интегрирования. Архитектура сети эквивалентна, с функциями активации гиперболического тангенса и двумя скрытыми слоями шириной (H=100), за исключением того, что входной слой модифицирован для приема входного значения (mathbf x in mathbb R^2). Мы выбираем целевую функцию регрессии как (v(x_1,x_2) = sin( 10 pi x_1 ) sin(10 pi x_2)). Снова используя оптимизацию ADAM с темпом обучения (5 times 10^{-3}), мы обучаем сеть, минимизируя квадрат ошибки с целевой функцией. На рисунке 9 представлена визуализация целевой функции и эволюции выходных данных сети в процессе обучения.
Во-первых, отметим, что сеть тратит более 3000 эпох на представление только среднего значения целевой функции, которое в данном случае равно нулю. После начала подгонки мы наблюдаем аналогичное поведение последовательной подгонки, как и в одномерных примерах, где сеть сначала становится ненулевой вблизи границы, а затем итеративно движется внутрь. Интересно, что процесс последовательной подгонки перемещается по диагонали через область и сначала представляет одномерные колебания в этом диагональном направлении координат. Примерно на 5000-й эпохе, начиная с границы, сеть начинает перемещаться по области в перпендикулярном диагональном направлении, корректируя одномерные колебания до двумерных, как и предполагает целевая функция обучения. Этот пример показывает, что последовательная подгонка может происходить и в более высоких пространственных измерениях.
Как и прежде, мы исследуем поведение набора базисных функций, построенных сетью. В этом случае мы не можем наложить несколько базисных функций на один график, поэтому мы выбираем для построения графика только сходящиеся базисные функции. В частности, мы находим (25) наибольших элементов из вектора коэффициентов (|mathbf w^3|) и строим график соответствующих базисных функций. На рисунке 10 показано, что, как и в одномерном случае, базисные функции представляют собой сглаженные ступенчатые функции.
Заключение
После обзора некоторых стандартных взглядов на спектральное смещение из литературы мы предложили альтернативное понимание этого явления. Наш аргумент заключается в том, что многослойные перцептронные нейронные сети (MLP) аппроксимируют высокочастотные функции от границ, обучаясь представлять по одному колебанию за раз. Мы показали, что поведение целевой функции вблизи границы может оказывать существенное влияние на процесс обучения, независимо от частотного состава целевой функции, что, по нашему мнению, является новым открытием. Кроме того, мы показали, что исследованные нами MLP-сети итеративно строили ступенчатые базисные функции, что резко контрастирует с колебательным поведением базиса, построенного сетью SIREN. Перспектива базисных функций интересна, поскольку она показывает, что даже обучение относительно широких сетей ((H=100)) находится в режиме «обучения признакам». Другими словами, эти ступенчатые базисные функции отсутствуют при инициализации сети — параметры сети необходимо настраивать для тщательного позиционирования и увеличения крутизны ступенчатых базисных функций.
Наконец, мы показали, что последовательное подгоночное поведение наблюдается также в задачах двумерной регрессии, где сеть теперь перемещается по области в двух перпендикулярных направлениях для получения соответствия. Наша визуализация сходящихся базисных функций показала, что последовательное поведение снова является следствием итеративной подгонки ступенчатых базисов.
Предварительные исследования показывают, что более глубокие сети могут строить осциллирующие базисные функции, даже при активации гиперболическим тангенсом. В будущих исследованиях можно было бы изучить влияние глубины сети и функции активации на последовательную подгонку, а также на устойчивость наблюдаемого граничного эффекта. Наш пример граничного эффекта показывает, что две функции с почти идентичными спектрами Фурье ведут себя совершенно по-разному в качестве целевых функций регрессии, очевидно, в результате их поведения вблизи границ областей. Мы считаем, что ценным вкладом в научную литературу по машинному обучению в будущем было бы более убедительно продемонстрировать, что частотный состав целевой функции не является единственным определяющим фактором успешной регрессии с помощью нейронных сетей.
Конор Роуэн. Все материалы от Конора Роуэна.
Источник: towardsdatascience.com
Оцените материал:
