Переход к эффективным токенам: решение проблемы агентского сжигания токенов
Почему агенты с жесткими ограничениями терпят неудачу и как разработать эффективные с точки зрения использования токенов самоадаптирующиеся рабочие процессы.
Делиться

Данная статья написана в соавторстве с Рахулом Виром и Реей Вир.
Переход от возможностей к эффективности токенов
Мы официально перешли от этапа прототипирования ИИ. Основываясь на концепциях, изложенных в книге «Выход из миража прототипов» [1], команды разработчиков и инженеров во всех отраслях теперь выпускают агентные приложения, которые решают задачи, ранее решавшиеся вручную. Создание этих автономных прототипов агентов теперь стало проще простого. Это так же просто, как использование ключевых концепций, таких как рекурсивные агентные циклы (наблюдение-мышление-действие) для выполнения, настройка безголовых шлюзов для подключения агентов через чат-приложения и использование сохраненного состояния, которое сохраняется после перезагрузки (как объяснено в [1]). Но превращение их в надежные продукты — это уже совсем другая история. Новая задача — не доказать, что агенты могут работать, а доказать, что они могут работать прибыльно.
В то же время, внутренние метрики предприятий, такие как «максимизация использования токенов» (неограниченное использование токенов для достижения наилучших результатов), которые были уместны на этапе прототипирования, смещаются в сторону измерения соотношения «стоимость/затраченные токены» по мере масштабирования агентных продуктов. В конце концов, большинство продуктов должны быть прибыльными и максимизировать маржу, поскольку они переходят от использования дешевых традиционных вычислительных ресурсов (TradCompute) для решения проблем пользователей к использованию искусственного интеллекта для тех же целей.
Однако моделям необходима свобода рассуждений, и недавние исследования показали, что исследовательские агентные рабочие процессы превосходят фиксированные пути, открывая новые возможности, создавая инструменты MCP и инфраструктуру для более эффективного решения проблемы в большинстве случаев. Это поднимает вопрос о балансе между потребностью модели в свободе действий и экономической реальностью затрат на вывод.
Почему агенты, находящиеся в условиях ограничений, не сходятся
В агентских системах контекст задачи и цели хранятся в файлах Markdown (*.md), которые, как правило, не отражают четкие рабочие процессы, а скорее описывают намерение или цель, которую вы хотите достичь.
Парадокс объективной неудачи: В исследованиях агентов, решающих сложные задачи, исследователи обнаружили, что предоставление строгих, сильно ограниченных правил, где каждое действие агента приближает его к цели, приводит к застреванию в локальном оптимуме и объективной неудаче. Пример из исследования профессора Джеффа Клуна по обучению агентов с открытым концом прекрасно это иллюстрирует: агент в лабиринте, постоянно вознаграждаемый исключительно за поиск прямого пути к выходу, будет неоднократно натыкаться на стены и попадать в локальный оптимум, никогда не достигая конца [2].
Сила неограниченных возможностей: Современные системы управления агентами, такие как Google Antigravity и Claude Code от Anthropic, оказались настолько эффективными, потому что позволяют агентам создавать, координировать и выполнять сложные задачи, а также создавать собственные инструменты без жесткого микроменеджмента со стороны человека. Они добиваются успеха, потому что им предоставляется свобода исследовать окольные пути.
Рассмотрим крайний случай в стандартном рабочем процессе приема пациента: если мы жестко ограничим медицинского агента следованием только заранее определенному алгоритму планирования, это приведет к сбою в реальном мире. Если пациент упоминает о боли в груди в середине стандартного приема, цикл работы агента должен обладать автономностью, чтобы мгновенно распознать срочность, отказаться от алгоритма планирования и запустить эскалацию ситуации в целях безопасности. Он должен использовать то, что мы ранее определили как «токен отсутствия ответа», чтобы подавить обсуждения по поводу записи на прием и направить контекст непосредственно к медсестре [1]. Жестко ограниченные прототипы с треском проваливают этот тест, потому что они не могут адаптироваться к критическому контексту, выходящему за рамки допустимого.
Бесконечный поиск целей обходится дорого.
Хотя предоставление возможности выбора имеет важное значение для первоначального поиска решения, проведение полного, неограниченного поиска по каждому запросу пользователя может привести к массивному и неустойчивому потреблению токенов. На этом этапе агент находит допустимый путь, и такой подход по своей сути позволяет ему повторно исследовать или «галлюцинировать» структуру рабочего процесса. Хотя это может самоисправляться, подобные последующие запуски аналогичных запросов разрушают экономику корпоративных токенов.
Например, алгоритмы обработки медицинских заявок и даже крайние случаи, требующие эскалации, могут быть освоены со временем. Рабочие процессы клиники или поставщика решений в большинстве случаев перейдут к детерминированным маршрутам, оставляя некоторую автономию исключительно для редких исключений и сложных крайних случаев.
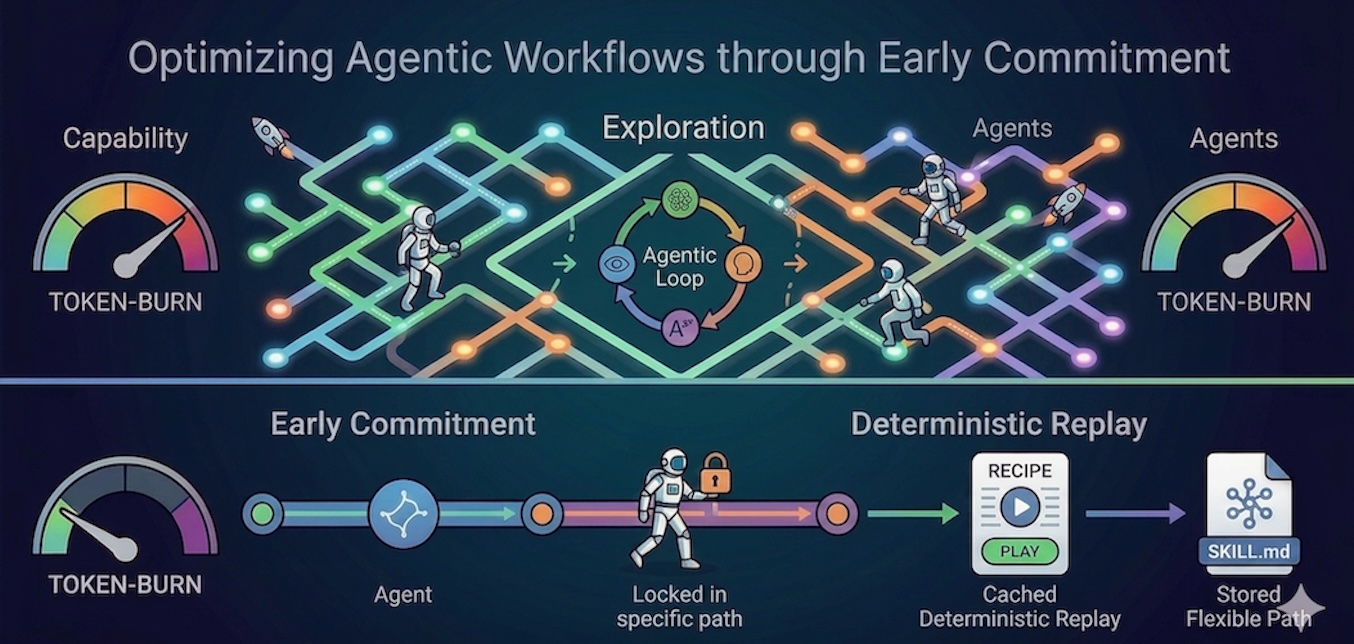
Архитектурные решения на ранних этапах и с использованием детерминированного воспроизведения.
Метод раннего принятия решений показал свою эффективность в структурированном решении проблем и может быть применен и к рабочим процессам агентов [3]. Он включает в себя предварительную классификацию проблемы, например, путем структурирования системного запроса таким образом, чтобы модель выдавала определенный тег классификации. Заставляя агента классифицировать тип проблемы и установить ограничения до того, как он сгенерирует логику выполнения, вы предотвращаете галлюцинации агента или исследование тупиковых путей. Это исключает шум и фокусирует агента исключительно на выполнении, а не на непрерывном исследовании.
Например, в процессе сортировки пациентов в рамках телемедицинской помощи мы можем обеспечить раннее подтверждение диагноза, потребовав от оператора однозначно классифицировать обращение как «плановое пополнение рецепта» до принятия каких-либо действий. После подтверждения этого условия оператор ограничивает свои обращения к базе данных аптеки, полностью обходя дорогостоящие и сложные пути диагностического анализа, по которым он мог бы пойти, пытаясь поставить диагноз пациенту.
В недавнем исследовании Ван, С. и др. представлена структура LOOP Skill Engine Framework, которая обеспечивает раннее подтверждение на уровне инфраструктуры с помощью парадигмы однократной записи и детерминированного воспроизведения [4]. Агент может автономно исследовать один раз, используя полное рассуждение, а затем система компилирует этот успешный трассировочный маршрут в рецепт без ветвлений. Для всех последующих запусков LLM может быть обойден, гарантируя детерминированность выполнения и сокращая использование токенов более чем на 93,3% для ежедневных задач и до 99,98% для высокочастотных запусков. Эта концепция может быть расширена на агентные рабочие процессы.
Рассмотрим создание ежедневных отчетов о соответствии требованиям клиники или стандартных сводных отчетов после выписки, что представляет собой высокостабильные, повторяющиеся задачи. Начиная с исследовательского подхода и быстро переходя к детерминированной структуре, агент должен выполнить сложную процедуру извлечения данных из электронной медицинской карты ровно один раз. Для следующих ста пациентов, выписанных с той же процедурой, система выполняет этот же алгоритм без ветвлений, надежно заменяя жизненно важные показатели и даты нового пациента без вызова LLM. Это гарантирует отсутствие ложных данных в повторяющихся задачах здравоохранения, одновременно максимизируя эффективность использования токенов.
Специалистам по машинному обучению необходимо сделать выбор между чисто детерминированным воспроизведением (например, циклом), которое максимизирует экономию токенов, и гибридным подходом (хранение исследованного пути в файле SKILL.md). Гибридный подход частично компенсирует эту экономию токенов за счет логического вывода по оптимальному, но при этом достаточно гибкому алгоритму, позволяющему адаптироваться к изменяющейся базовой структуре. Независимо от того, обновляется ли этот файл навыков вручную или с помощью автономного механизма самосовершенствования, сохранение этого запаса логического вывода обеспечивает адаптивность и долгосрочную надежность. Например, если структура базы данных изменится, агент сможет обновить SQL-запросы и извлечь информацию.
Заключение: Конвейер машинного обучения «Исследование-Подтверждение-Измерение»
Инженеры по машинному обучению и менеджеры по продуктам должны адаптировать свои приложения, чтобы использовать огромный интеллект автономных агентов и применять неограниченные возможности агентов для первоначального выявления проблем и сложных, разовых крайних случаев. Это позволяет получить оптимальные решения без запуска дорогостоящего цикла обучения с подкреплением (который часто блокируется недостатком опыта, ограничениями платформы, стоимостью обучения или закрытыми моделями).
После того как мы найдем почти оптимальный путь, токеновая экономика для структурированных и повторяющихся задач требует от нас обеспечения раннего подтверждения на этапе проектирования запросов, используя детерминированные архитектуры воспроизведения для кэширования пути выполнения.
По мере масштабирования агентских продуктов нам необходимо сместить акцент в операционных показателях с простых показателей успешности выполнения задач на показатели эффективности использования токенов и ценности каждого сгенерированного токена.
Ссылки
- Вир, Р., и Вир, Р. (2026, 4 марта). Выход из миража прототипов: почему корпоративный ИИ застопорился. На пути к науке о данных.
- Клун, Дж. (2025, 12 февраля). Гостевая лекция 6 CS329A профессора Джеффа Клуна: Открытое обучение агентов в эпоху базовых моделей [Видео]. YouTube.
- Вир, Р. (2026, 1 января). Почему раннее принятие решений помогает ИИ решать структурированные задачи. На пути к ИИ.
- Ван, С., Ю, К., Лян, С., Ван, Л., и Хан, С. (2026). Готов к работе: движок навыков LOOP, достигающий 99% успеха и сокращающий использование токенов на 99% за счет одноразовой записи и детерминированного воспроизведения. arXiv.
Рахул Вир Посмотреть все о Рахул Вир
Источник: towardsdatascience.com
Оцените материал:
