Небольшие модели, большие результаты: Достижение превосходного извлечения намерений посредством декомпозиции
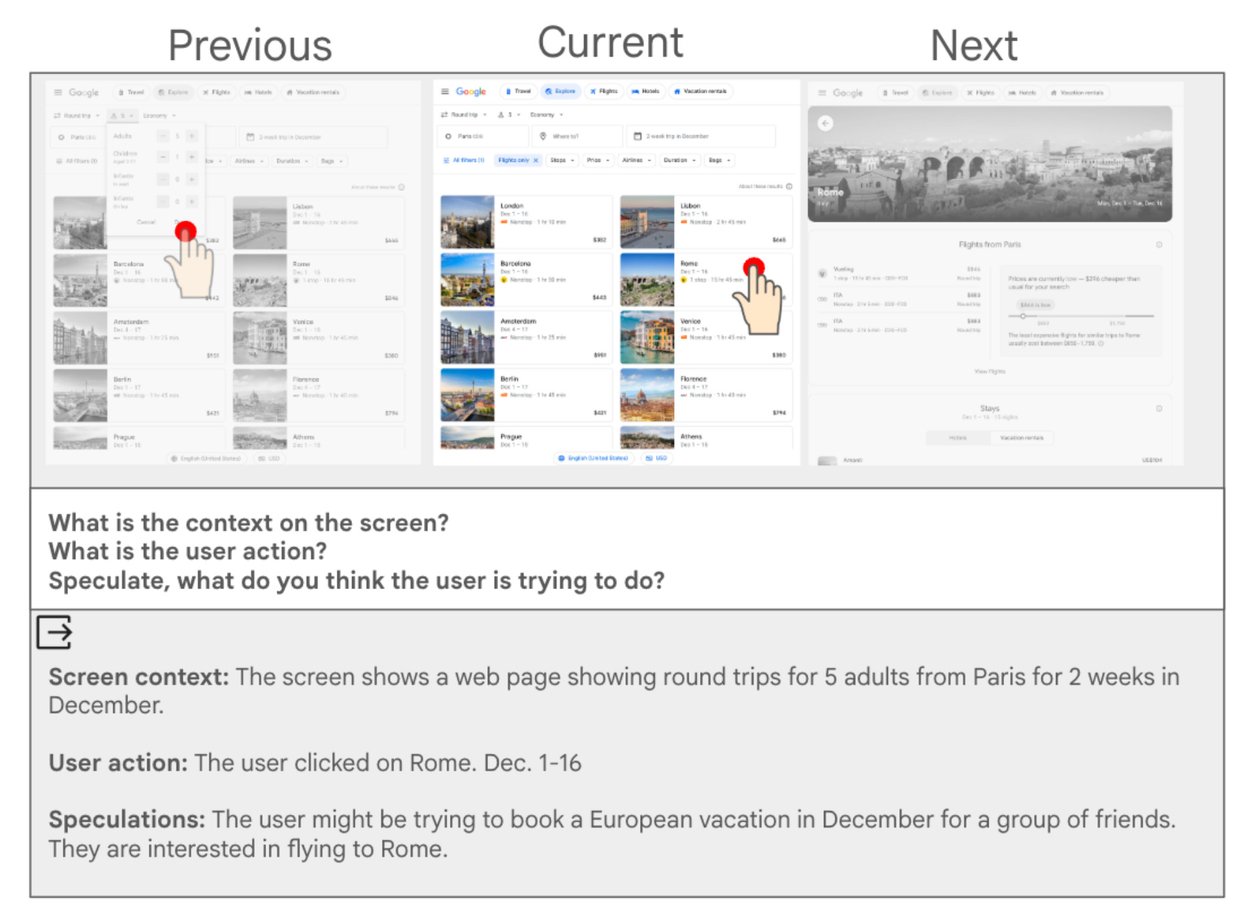
Мы представляем новый подход к решению задачи понимания намерений пользователя на основе траекторий взаимодействия с пользовательским интерфейсом с использованием небольших моделей, который демонстрирует лучшие результаты, чем значительно более крупные модели.
Быстрые ссылки
- Бумага
- Делиться
По мере развития технологий искусственного интеллекта, действительно полезные агенты смогут лучше предвидеть потребности пользователей. Для того чтобы взаимодействие с мобильными устройствами было по-настоящему полезным, базовые модели должны понимать, что пользователь делает (или пытается сделать), когда взаимодействует с ними. После того, как будут поняты текущие и предыдущие задачи, модель получит больше контекста для прогнозирования потенциальных следующих действий. Например, если пользователь ранее искал музыкальные фестивали по всей Европе, а теперь ищет рейс в Лондон, агент может предложить найти фестивали в Лондоне на эти конкретные даты.
Крупные мультимодальные LLM-модели уже достаточно хорошо понимают намерения пользователя на основе траектории взаимодействия с пользовательским интерфейсом (UI). Однако использование LLM-моделей для этой задачи обычно требует отправки информации на сервер, что может быть медленным, дорогостоящим и сопряжено с потенциальным риском раскрытия конфиденциальной информации.
Наша недавняя статья «Маленькие модели, большие результаты: достижение превосходного извлечения намерений посредством декомпозиции», представленная на EMNLP 2025, посвящена вопросу о том, как использовать небольшие мультимодальные линейные модели поведения (MLLM) для понимания последовательностей взаимодействий пользователей в интернете и на мобильных устройствах непосредственно на устройстве. Разделив понимание намерений пользователя на два этапа — сначала суммирование каждого экрана отдельно, а затем извлечение намерения из последовательности сгенерированных сводок — мы делаем задачу более выполнимой для небольших моделей. Мы также формализовали метрики для оценки производительности модели и показали, что наш подход дает результаты, сопоставимые с гораздо более крупными моделями, демонстрируя его потенциал для приложений на устройствах. Эта работа основывается на предыдущих исследованиях нашей команды по пониманию намерений пользователя.
Подробности
Мы представляем декомпозированный рабочий процесс для понимания намерений пользователя на основе его взаимодействий. На этапе вывода модель выполняет два основных шага. На первом шаге каждое отдельное взаимодействие на отдельном экране и элементе пользовательского интерфейса суммируется независимо. Затем эти сводки используются в качестве последовательности событий для прогнозирования общего намерения всей траектории взаимодействия с пользовательским интерфейсом.
Сводные данные по отдельным экранам
На первом этапе каждое отдельное взаимодействие обобщается с помощью небольшой мультимодальной LLM-модели.
Имея перед собой скользящее окно из трех экранов (предыдущий, текущий, следующий), задаются следующие вопросы:
- Какой контекст экрана имеет значение? Приведите краткий список наиболее важных деталей текущего экрана.
- Что только что сделал пользователь? Перечислите действия, которые пользователь совершил в ходе этого взаимодействия.
- Подумайте. Чего пользователь пытается добиться этим взаимодействием?

Первый этап декомпозированного рабочего процесса. Для каждой пары «скриншот — действие» мы рассматриваем окружающие экраны и задаем вопросы о контексте экрана, действиях пользователя и предположениях о том, что пользователь пытается сделать. Внизу мы показываем потенциальное резюме, сгенерированное LLM, отвечающее на три вопроса. Это резюме послужит входными данными для второго этапа декомпозированного рабочего процесса.
Извлечение намерений из кратких обзоров
На этом этапе используется тонко настроенная небольшая модель для извлечения одного предложения из сводных данных экрана.
Мы считаем, что следующие методы оказываются полезными.
- Тонкая настройка: Предоставление примеров того, как выглядит «хорошее» описание намерения, помогает модели сосредоточиться на важных частях резюме и отбросить бесполезные. В качестве обучающих данных мы используем общедоступные наборы данных для автоматизации, поскольку они содержат хорошие примеры, которые сопоставляют намерения с последовательностями действий.
- Подготовка меток: Поскольку в описаниях может отсутствовать информация, обучение модели с использованием полных намерений может привести к тому, что она непреднамеренно научится заполнять недостающие детали (например, галлюцинировать). Чтобы этого избежать, мы сначала удаляем из обучающих намерений любую информацию, отсутствующую в описаниях (используя отдельный вызов LLM).
- Отказ от предположений: указание модели конкретного места для вывода предположений о том, что пытается сделать пользователь, помогает создать более полное описание шага на первом этапе, но может запутать экстрактор намерений на втором этапе. Поэтому мы не используем предположения на втором этапе. Хотя это может показаться нелогичным — запрашивать предположения на первом этапе, а затем отбрасывать их на втором — мы обнаружили, что это помогает улучшить производительность.
На втором этапе декомпозированного рабочего процесса используется точно настроенная модель, которая принимает на вход сводки, сгенерированные на первом этапе, и выдает краткое описание намерений. На этом этапе мы отбрасываем все предположения из сводок и очищаем метки во время обучения, чтобы они не способствовали возникновению галлюцинаций.
Подход к оценке
Мы используем подход Bi-Fact для оценки качества прогнозируемого намерения по сравнению с эталонным намерением. В рамках этого подхода мы используем отдельный вызов LLM для разделения эталонного и прогнозируемого намерений на детали намерения, которые нельзя разбить дальше, — так называемые «атомарные факты». Например, «перелет в один конец» будет атомарным фактом, а «перелет из Лондона в Кигали» — двумя. Затем мы подсчитываем количество эталонных фактов, вытекающих из прогнозируемого намерения, и количество прогнозируемых фактов, вытекающих из эталонного намерения. Это позволяет нам определить точность (сколько прогнозируемых фактов верны) и полноту (сколько истинных фактов мы правильно предсказали) нашего метода, а также рассчитать F1-меру.
Анализ охвата фактов. Оценка того, были ли исходные факты успешно отражены в прогнозируемом намерении ( слева ) и подтверждаются ли прогнозируемые факты исходным намерением ( справа ).
Работа с атомарными фактами также помогает отслеживать, как различные этапы декомпозированного подхода способствуют возникновению ошибок. Ниже мы покажем, как мы анализируем поток фактов через систему, чтобы отслеживать упущенные детали и мнимые ошибки на каждом этапе.
Анализ ошибок распространения показателей полноты и точности на обоих этапах нашей модели.
Ключевые результаты
Декомпозированный подход, заключающийся в суммировании каждого экрана по отдельности и последующем извлечении намерения из последовательности сгенерированных сводок, полезен при использовании небольших моделей. Мы сравнили его со стандартными подходами, включая цепочку подсказок мыслей (CoT) и сквозную тонкую настройку (E2E), и обнаружили, что он превосходит оба. Этот результат подтверждается при тестировании как на мобильных устройствах, так и на веб-платформах, а также для базовых моделей Gemini и Qwen2. Мы даже обнаружили, что применение декомпозированного подхода с моделью Gemini 1.5 Flash 8B дает результаты, сопоставимые с использованием Gemini 1.5 Pro, при значительно меньших затратах и скорости. Дополнительные эксперименты описаны в статье.
Показатели Bi-Fact F1 сравнивают декомпозированный метод с двумя естественными базовыми моделями: методом подсказок по цепочке мыслей (CoT) и сквозной тонкой настройкой (E2E). Во всех условиях наш декомпозированный метод превосходит базовые модели, а на наборе данных для мобильных устройств он сопоставим с производительностью большой модели Gemini Pro.
Выводы и дальнейшие направления
Мы показали, что декомпозированный подход к суммированию траекторий может быть полезен для понимания намерений с помощью небольших моделей. В конечном итоге, по мере улучшения производительности моделей и увеличения вычислительной мощности мобильных устройств, мы надеемся, что понимание намерений на устройстве станет основой для многих вспомогательных функций мобильных устройств в будущем.
Благодарности
Благодарим наших соавторов статьи: Ноама Кахлона, Джоэла Орена, Омри Берковича, Сапира Кадури, Идо Дагана и Анатолия Эфроса.
Источник: research.google
Оцените материал:

