На пути к развитию навыков, востребованных в будущем, с помощью генеративного искусственного интеллекта.
Наше новое исследование демонстрирует новаторский подход к оценке навыков, необходимых для «готовности к будущему», с использованием искусственного интеллекта. Результаты нашего исследования, проведенного совместно с Нью-Йоркским университетом, показали, что оценка ИИ сопоставима с оценкой экспертов-людей. Этот экспериментальный проект, Vantage, теперь доступен в Google Labs.
Быстрые ссылки
- Vantage на Google Labs
- Видео с обзором
- Технический отчет
- Делиться
Поскольку искусственный интеллект развивается беспрецедентными темпами, вновь уделяется внимание навыкам, востребованным в будущем, — устойчивым человеческим компетенциям, которые останутся ценными независимо от технологических изменений или автоматизации. Международные концепции, такие как «Учебный компас 2030» ОЭСР и доклад Всемирного экономического форума «Будущее рабочих мест», определили набор приоритетных навыков, в которых подчеркиваются одни и те же основные компетенции, включая критическое мышление, сотрудничество и креативное мышление. Хотя эти навыки считались необходимыми задолго до появления ИИ, сейчас они становятся важнее, чем когда-либо.
Сегодня мы представляем Vantage — исследовательский эксперимент по оценке навыков, необходимых для успешного будущего, с использованием генеративного ИИ для создания диалогов в смоделированных средах. Разработанный в сотрудничестве с экспертами в области педагогики и исследователями из Нью-Йоркского университета, Vantage призван предоставить старшеклассникам и студентам экспериментальную среду для практики и проверенной оценки, созданную с использованием той же систематической методологии, которая традиционно применяется для основных академических предметов, таких как математика или естественные науки. Vantage теперь доступен на английском языке для регистрации в Google Labs.
воспроизведение зацикленного видео пауза зацикленного видео включить звук видео отключить звук
Измерение того, что трудно измерить
В основе любого эффективного процесса обучения лежат обратная связь и оценка, которые необходимы как для личностного роста, так и для эффективного преподавания. В глобальных системах образования часто бывает так, что измеряется то, чему учат.
Однако навыки, необходимые в будущем, крайне сложно измерить. Типичные тесты слишком жёсткие, чтобы отразить мыслительные процессы и взаимодействие людей, и они далеки от того, как эти навыки используются в реальном мире. Хотя тестирование этих навыков в реальных человеческих взаимодействиях было бы идеальным вариантом, оно также слишком ресурсоёмко и сложно стандартизировать и оценивать последовательно для большого количества студентов. Например, как можно справедливо оценить умение разрешать конфликты, если группа никогда не расходится во мнениях, или способность творчески развивать идеи друг друга, если они остановились на первом предложенном варианте?
Наша исследовательская группа поставила перед собой задачу выяснить, как оценивать навыки, необходимые студентам для успешной адаптации к будущему, используя масштабируемый, проверенный подход, который позволил бы педагогам согласовывать уроки с этими навыками и поддерживать развитие учащихся.
Оценка навыков с помощью смоделированной команды на основе искусственного интеллекта.
Экспериментальная установка в Vantage помещает учащихся в динамичные многосторонние диалоги с аватарами ИИ, которые совместно выполняют задания. Такая установка позволяет контролировать среду оценки, имитируя взаимодействия, которые более аутентичны и репрезентативны для реальных сценариев, чем существующие стандартизированные тесты. Она предоставляет своего рода «песочницу» для решения сложных межличностных и ситуационных задач.
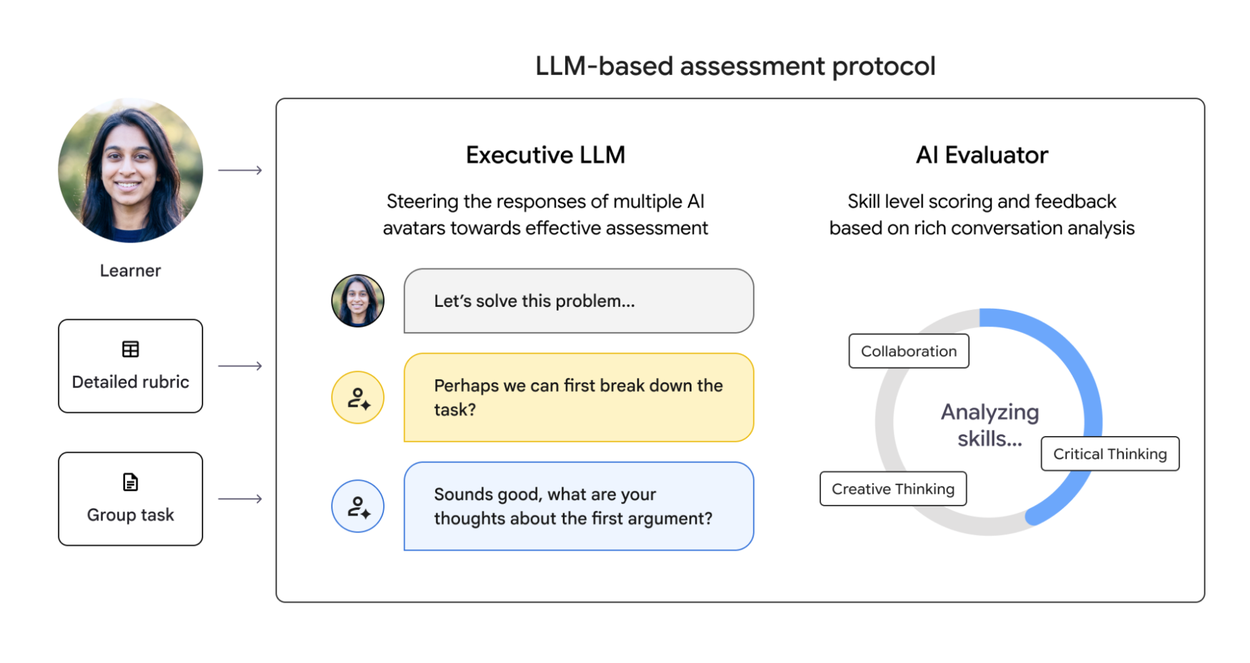
В ходе взаимодействия пользователей с ИИ-аватарами в открытых сценариях, таких как подготовка к дебатам или презентация креативной идеи, программа Executive LLM использует предоставленную оценочную рубрику, чтобы направлять ИИ-аватаров к эффективной оценке. Программа Executive LLM постоянно анализирует состояние разговора, чтобы динамически вводить конкретные задачи — например, возражать против идеи или создавать конфликт — предоставляя обучающемуся целенаправленные возможности для демонстрации своих навыков. Таким образом, она действует как адаптивный механизм оценки нового поколения, направляя диалог таким образом, чтобы к концу разговора была собрана вся необходимая информация для оценки пользователя.

Схема протокола оценки на основе LLM. Пока обучающийся выполняет задания открытого типа, специалист по оценке уровня владения английским языком (Executive LLM) использует рубрику для управления аватарами ИИ и создания динамических задач. Это позволяет получить целенаправленные данные об успеваемости обучающегося, которые затем анализируются оценщиком ИИ для оценки навыков в режиме реального времени и предоставления обратной связи.
По завершении задания ИИ-оценщик анализирует стенограмму разговора, используя ту же строгую оценочную шкалу, что и в программе Executive LLM, для выявления и измерения конкретных примеров применения навыков. Затем обучающийся получает подробную карту навыков, состоящую из визуальной оценки и качественной обратной связи, относящихся к навыкам, продемонстрированным им во время разговора. Это делает «невидимый» прогресс в развитии человеческих навыков видимым и позволяет применять полученные знания на практике.
Пример карты навыков и обратной связи, представленный пользователям, включая навыки и поднавыки, которые в настоящее время включены в Vantage.
Работа с партнерами для проверки методов оценки навыков.
Для обеспечения академической и педагогической строгости мы установили исследовательское партнерство с Нью-Йоркским университетом. Вместе мы провели обзор распространенных критериев оценки и согласовали их с рассматриваемыми задачами. Основная цель этого сотрудничества заключалась в разработке и проверке подхода к оценке. Мы сделали это посредством совместного исследования с участием 188 испытуемых в возрасте 18-25 лет из США, которые выполнили задания Vantage, оценивающие примеры навыков сотрудничества: разрешение конфликтов и управление проектами. Мы рассмотрели два основных исследовательских вопроса:
1. Можем ли мы направить разговор на проверку конкретных навыков?
Ключевым нововведением Vantage является использование Executive LLM для обеспечения адаптивной оценки. Мы оценили, насколько эффективно LLM могут направлять разговор на конкретную задачу, например, разрешение конфликтов или управление проектами. Мы измерили объем информации, связанной с навыком, продемонстрированной пользователем, по сравнению с обучающимся, работающим с независимыми ИИ-аватарами, которые не управляются в рамках той же задачи. Наши результаты показали, что Executive LLM успешно направляет диалог для получения большого объема информации и приводит к значительно большему объему информации об оцениваемых навыках, сохраняя при этом естественный ход разговора. Эта возможность подтвердилась в нескольких задачах моделирования. Дополнительные результаты и подробности о методологии можно найти в техническом отчете.
Доля информации в разговорах : Столбики показывают долю разговоров, содержащих достаточно информации для оценки уровня профессиональных навыков в области разрешения конфликтов и управления проектами. Сравнения показаны между стратегией Executive LLM ( синий ) и независимыми моделями аватаров ( оранжевый ), где ответы ИИ-аватаров генерируются независимо, без координации. Звездочка (*) обозначает статистически значимую разницу между стратегиями.
2. Насколько точно магистранты могут оценить навыки, необходимые для успешной карьеры в будущем?
Для проверки точности оценки ИИ мы сравнили ее результаты с оценками экспертов из Нью-Йоркского университета, используя те же педагогические критерии. Результаты показали, что согласованность между оценщиком ИИ и экспертами-людьми была аналогична согласованности между двумя экспертами-оценщиками. Это говорит о том, что оценки разговора, данные ИИ-оценщиком, сопоставимы с оценками экспертов-людей, что подтверждает эффективность Vantage как автоматизированной системы оценки навыков.
Согласованность оценок между экспертами при оценке навыков : сравнение согласованности оценок между экспертами (человек-человек) и между экспертом, имеющим степень магистра права (LLM), и экспертами (человек-LLM). Согласованность рассчитывается с использованием коэффициента Каппа Коэна с квадратичными весами для навыков разрешения конфликтов и управления проектами.
Мы также сотрудничали с OpenMic, стартапом, разрабатывающим инструменты на основе искусственного интеллекта для оценки устойчивых навыков. Вместе мы провели совместное исследование креативности и английского языка, чтобы протестировать ИИ-оценщик в другом контексте. Мы проанализировали работы 180 студентов, выполненные в рамках творческих мультимедийных заданий, таких как интервью с персонажами и статьи из СМИ, связанные с английской литературой, и сравнили оценки ИИ-оценщика с оценками внутренних экспертов OpenMic. И здесь также наблюдалась высокая корреляция между оценками ИИ-оценщика и экспертов-людей, что демонстрирует способность ИИ-оценщика предоставлять достоверные оценки даже в сложных, реальных творческих задачах.
Согласованность оценок креативности : оценка LLM по сравнению с оценками экспертов в сложной задаче на креативность. Оценки хорошо согласуются, коэффициент корреляции Пирсона составляет 0,88.
Взгляд в будущее на интеграцию в классах
В школьной среде подобная смоделированная среда может проложить путь к измеримому «слою навыков», который будет дополнять существующие школьные программы и интегрироваться в академические задания. Это позволит педагогам представить новые формы заданий, например, обсуждение темы социальных наук с участием аватаров ИИ или выполнение роли руководителя группы, планирующей лабораторный эксперимент. Учащиеся смогут получать обратную связь как по своему пониманию предмета (например, по научной стороне лабораторного эксперимента), так и по своим навыкам (например, по качеству их сотрудничества и критическому мышлению). Такой подход дополнит существующие групповые проекты с другими учениками и потенциально может способствовать развитию академических знаний и устойчивых навыков одновременно.
Обеспечение готовности к будущему в масштабах всего мира.
Данное исследование изучает, как мы могли бы преобразовать необходимые, перспективные и устойчивые навыки из трудноизмеримых в измеримые в масштабах. Таким образом, становится возможным более полное и точное представление о готовности к будущему. Этот эксперимент является шагом к подходу к оценке, более точно соответствующему будущим потребностям.
Мы также надеемся, что наша новая инфраструктура поддержит дальнейшие исследования и изучение эффективности в рамках всей экосистемы. Теперь исследователи смогут оценивать не только влияние новых инструментов на сохранение знаний, но и их непосредственное воздействие на развитие навыков. Потенциал таких исследований значителен, поскольку они позволяют лучше понять, как различные педагогические методы формируют человеческие компетенции с течением времени.
В перспективе мы расширяем наши исследования, чтобы решить важнейший вопрос переносимости — как навыки, продемонстрированные в смоделированной среде, переносятся в реальное взаимодействие людей. Кроме того, признавая, что человеческие навыки зависят от культуры, мы сосредоточимся на изучении эффективности в различных условиях, чтобы обеспечить инклюзивность и справедливость нашей технологии. Следующий этап, помимо оценки, — это переход к развитию навыков, углубление нашего понимания и измерение эффективности развития навыков посредством практики в смоделированных средах.
Благодарности
Благодарим членов команды Google, которые внесли свой вклад в эту работу: Алон Харрис, Алекс Мой, Амир Глоберсон, Аниша Чоудхури, Анна Юрченко, Айса Чакмакли, Бен Витт, Кэти Чунг, Диана Акронг, Элизабет Бауэр, Хайронг Му, Джулия Вилковски, Лев Боровой, Люсиль Мартини, Майя Альва, Нир Керем, Ноа Керрем Гило, Прити. Сингх, Раджви Кападиа, Рена Левитт, Рони Рабин, Ротем Юлзари, Шашанк Агарвал, Софи Олвейс, Тал Оппенгеймер , Тейлор Годду, Трейси Ли-Джо, Цвика Штайн, Янив Кармель, Ишай Мор, Йоав Бар Синай и Юрий Лев. Благодарим нашего сотрудника из Нью-Йоркского университета Йоава Бергнера и его команду, а также наших партнеров из OpenMic: Авиада Сегала, Элиада Карми, Хадас Гельбарт и Яэль Бар Моше. Мы благодарны за ценные замечания Кристин Легаре из Техасского университета в Остине и Джей Ди Ларока, президента и генерального директора Network for Teaching Entrepreneurship (NFTE). Особая благодарность нашим руководителям-кураторам: Ниву Эфрону, Авинатану Хассидиму, Эми Килинг, Кэтрин Чоу, Йосси Матиасу, Ронит Левави Морад, Крису Филлипсу и Бену Гомесу.
Источник: research.google
Оцените материал:


