Материализованные виды озер в Microsoft Fabric: когда ваш Medallion подходит для оператора SELECT
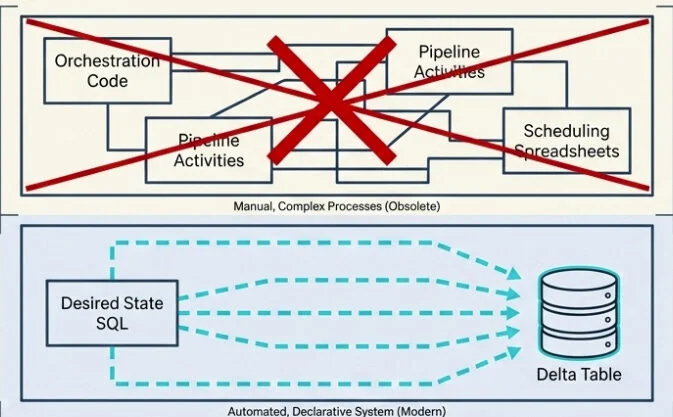
Пять поверхностей слились в один декларативный слой.
Делиться
Долгое время создание архитектуры Medallion в Microsoft Fabric означало объединение множества движущихся частей: блокнотов для преобразований, конвейеров для оркестровки, расписаний обновления, пользовательского кода для проверки качества данных и Monitor Hub для отслеживания работоспособности всего процесса. Каждый слой работал — до тех пор, пока что-то не переставало работать, и тогда приходилось выяснять, какой слой сломался, почему и какие нижестоящие слои были затронуты.
Если вы когда-либо пытались отладить слой Silver, который не обновился из-за сбоя в работе ноутбука Bronze три часа назад, вы точно знаете, о чём я говорю.
Затем, на FabCon Atlanta в марте 2026 года, материализованные изображения озер (MLV) стали общедоступными. И суть их истории проста: что, если весь ваш конвейер обработки медальонов можно будет свести к нескольким операторам SELECT?
Позвольте мне подробно рассказать обо всем этом — что это такое, как они работают, что изменилось между предварительной версией и общедоступной версией, и где они вписываются (и где не вписываются) в вашу архитектуру.
Реализованный вид на озеро – ЧТО?
Материализованное представление озера — это сохраняемое, автоматически обновляемое представление, определенное в Spark SQL или PySpark. Вы пишете запрос SELECT, описывающий желаемое преобразование, а Fabric берет на себя выполнение, хранение, обновление, отслеживание зависимостей и обеспечение качества данных.
Результат сохраняется в вашей системе хранения данных (Lakehouse) в виде таблицы Delta. Таким образом, конечные пользователи, такие как Power BI Direct Lake, блокноты Spark, SQL-конечные точки, могут запрашивать ее так же, как и любую другую таблицу Delta. Никакой специальной обработки, никакого особого синтаксиса.
Проще говоря: MLV — это не что иное, как оператор SELECT, который научился материализовываться, управлять собственными зависимостями, планировать собственное обновление и проверять качество собственных данных.

Хорошо, это неплохо. Но что это на самом деле заменяет?
Это вполне резонный вопрос. До появления MLV-преобразователей построение единого процесса от «бронзы» к «серебру» и «золоту» выглядело примерно так: вы писали блокнот для каждого преобразования, настраивали конвейер Data Factory для вызова их в правильном порядке, конфигурировали расписания, создавали собственную логику проверки, а затем подключали Monitor Hub для отслеживания сбоев. Пять разных интерфейсов, пять разных вещей для отладки, когда что-то ломается.
С MLV-файлами все это сводится к декларативному SQL. Вы описываете, что вам нужно, а Fabric разбирается с остальным.
Четыре этапа жизни многоцелевого летательного аппарата
Каждый MLV-файл проходит четыре этапа. Согласно документации Microsoft, понимание этих этапов является основой для всего остального:
- Создание – Вы пишете SQL-запрос Spark (или PySpark), определяющий преобразование. Fabric сохраняет это определение и материализует исходный результат в виде таблицы Delta.
- Обновление — при изменении исходных данных Fabric выбирает оптимальную стратегию: инкрементальное (обрабатывает только изменения), полное (перестраивает) или пропуск (изменения не обнаружены).
- Запрос – любое приложение или инструмент считывает материализованный результат. Они не знают – и им не нужно знать – что это MLV-файл.
- Мониторинг – история обновлений, статус выполнения, показатели качества данных и происхождение данных отслеживаются и визуализируются непосредственно в Fabric.
Теперь давайте рассмотрим каждый фрагмент подробнее.
Создание: синтаксис
Вот полный синтаксис псевдокода Spark SQL для создания MLV, взятый непосредственно из справочника Microsoft Learn:
CREATE [OR REPLACE] MATERIALIZED LAKE VIEW [IF NOT EXISTS] [workspace.lakehouse.schema].MLV_Identifier [(CONSTRAINT constraint_name CHECK (condition) [ON MISMATCH DROP | FAIL], ...)] [PARTITIONED BY (col1, col2, ...)] [COMMENT “description”] [TBLPROPERTIES (”key1”=”val1”, ...)] AS select_statement
Реальный пример – очистка данных заказов, объединенных из данных о товарах и заказах, с учетом ограничений по качеству данных и секционирования:
CREATE OR REPLACE MATERIALIZED LAKE VIEW silver.cleaned_order_data ( CONSTRAINT valid_quantity CHECK (quantity > 0) ON MISMATCH DROP ) PARTITIONED BY (category) COMMENT “Cleaned order data joined from products and orders” AS SELECT p.productID, p.productName, p.category, o.orderDate, o.quantity, o.totalAmount FROM bronze.products p INNER JOIN bronze.orders o ON p.productID = o.productID
Сразу же стоит обратить внимание на два момента. Во-первых, имена MLV нечувствительны к регистру ( MyView становится myview ). Во-вторых, имена схем, написанные только заглавными буквами (например, MYSCHEMA ), не поддерживаются, поэтому используйте либо смешанный регистр, либо нижний.
Вам также потребуется Lakehouse с поддержкой схем и Fabric Runtime версии 1.3 или выше. Если в вашем Lakehouse схемы не включены, MLV-файлы недоступны — это самое первое необходимое условие.
Обновление: мозг MLV
Вот тут-то MLV перестают быть просто умными и начинают проявлять смекалку.
Когда исходные данные изменяются, механизм оптимального обновления Fabric анализирует каждый MLV-файл в цепочке изменений и задает ряд вопросов: Действительно ли что-то изменилось? Могу ли я обработать только изменения? Или мне нужно перестроить все с нуля?
Возможны три исхода:
- Пропустите обновление — исходные данные не изменились. Не тратьте вычислительные ресурсы. Переходите к следующему шагу.
- Постепенное обновление — обработка только новых или измененных строк. Быстро, недорого, идеально.
- Полное обновление — перестройка всего. Самый медленный способ, используемый, когда инкрементальное обновление небезопасно или невозможно.

Но, и это важно, инкрементальное обновление не бесплатно. Для его выполнения необходимы следующие условия:
- Для каждой исходной таблицы, на которую ссылается MLV, необходимо включить передачу данных об изменениях (Delta change data feed, CDF) (
delta.enableChangeDataFeed=true). - Источником должна быть таблица типа Delta. Источники, не являющиеся таблицей Delta, всегда обновляются полностью.
- Данные должны быть доступны только для добавления. Если в вашем источнике происходят обновления или удаления, Fabric переключается на полное обновление.
- В запросе должны использоваться только поддерживаемые конструкции SQL (подробнее об этом чуть позже).
Без включенного CDF оптимальное обновление может выбирать только между пропуском и полным обновлением. При включенном CDF открывается путь полного инкрементного обновления. Включение CDF для исходных таблиц не оказывает заметного влияния на объем хранилища или производительность при рабочих нагрузках с добавлением данных, поэтому практически нет причин не включать его:
ALTER TABLE bronze.orders SET TBLPROPERTIES (delta.enableChangeDataFeed = true); ALTER TABLE bronze.products SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
Может ли быть что-то лучше? На самом деле, да! И именно здесь история GA по-настоящему начинается.
Что нового на этапе общедоступности?
MLV-файлы были представлены в предварительной версии на конференции Build 2025. В период с момента выпуска до официального релиза в марте 2026 года Microsoft устранила наиболее важные недостатки. Пять основных изменений превратили MLV-файлы из «интересных» в «готовые к использованию в производстве»:
- Поддержка нескольких расписаний
- Более широкое покрытие поэтапного обновления
- Разработка контента с помощью PySpark (предварительная версия)
- Обновление на месте с помощью функции «Замена»
- Более строгий контроль качества данных
Давайте я разберу их по одному.
1. Поддержка нескольких расписаний.
В предварительной версии можно было обновлять все MLV-файлы в одном объекте недвижимости только по одному расписанию. Нужно было обновлять финансовые данные ежечасно, а аналитические — каждые шесть часов? Приходилось использовать блокноты, что нарушало распознавание зависимостей, отчеты об ошибках и логику повторных попыток. Обновления, запускаемые блокнотами, не отображают подробную информацию об ошибках MLV. Сбои отображаются только в выводе ячеек, и зависимые представления о них не знают. Ошибки могут сохраняться неделями, и никто не будет знать о сбое в конвейере обработки данных.
Теперь вы можете определять именованные расписания в рамках одного проекта Lakehouse, каждое из которых нацелено на определенный набор представлений. Финансовый поток — ежечасно. Аналитика — каждые шесть часов. Маркетинг — каждые 15 минут. Все в одном проекте Lakehouse, без написания пользовательского кода.

При выполнении именованного расписания Fabric по-прежнему обновляет все вышестоящие зависимости в правильном порядке, запускает независимые представления параллельно и централизованно отображает ошибки. Если при запуске расписания уже выполняется какое-либо другое задание, новое задание пропускается, и следующее окно выполняется как положено — поэтому вам не нужно беспокоиться о том, что перекрывающиеся задания будут мешать друг другу.
2. Более широкое поэтапное обновление
Раньше при инкрементальном обновлении часто происходил возврат к полному, поскольку список «поддерживаемых» конструкций SQL был ограничен. В версии GA этот список значительно расширился. Теперь MLV-файлы обновляются инкрементально, если определение включает в себя:
- Агрегированные операции, такие как
COUNTиSUMс использованиемGROUP BY - Левые внешние соединения и левые полусоединения
- Общие табличные выражения (CTE)
Это существенное изменение. Большинство реальных конвейеров обработки данных Medallion, с которыми я работал, используют именно эти шаблоны, и теперь они подходят для инкрементальной обработки без переписывания кода. При оптимальном обновлении встроенный механизм принятия решений анализирует каждое обновление, оценивает объем измененных данных по сравнению со стоимостью полного пересчета и автоматически выбирает более быстрый путь.
Я вас понимаю, я вас понимаю: Никола, что произойдет, если мой запрос будет использовать что-то, что движок не может обработать инкрементально? Не волнуйтесь, это гораздо проще, чем кажется 🙂 Использование неподдерживаемых конструкций не мешает вам создать MLV. Это лишь означает, что Fabric использует полное обновление вместо инкрементального. Оптимальное обновление автоматически переключается на полное при необходимости, поэтому обычно вам не нужно принудительно его выполнять. Если вы все же хотите принудительно выполнить его (например, для повторной обработки данных после исправления), для этого есть всего одна строка кода:
REFRESH MATERIALIZED LAKE VIEW silver.cleaned_order_data FULL;
3. Создание контента с помощью PySpark (предварительная версия)
Это очень важно! SQL отлично подходит до тех пор, пока ваша логика преобразования не включает в себя пользовательскую библиотеку Python, вызов функции вывода машинного обучения или пользовательскую функцию, которая инкапсулирует сложные бизнес-правила. Тогда вы столкнетесь с препятствием, поскольку MLV-файлы работают только с SQL.
Благодаря PySpark Authoring теперь можно создавать, обновлять и заменять MLV-файлы из блокнотов Fabric, используя PySpark и знакомый API DataFrameWriter. Модуль fmlv предоставляет шаблон на основе декораторов, описанный в официальной справочной документации PySpark по MLV:
import fmlv from pyspark.sql import functions as F @fmlv.materialized_lake_view( name=”LH1.silver.customer_silver”, comment=”Cleaned & enriched customer silver MLV”, partition_cols=[”year”, “city”], table_properties={”delta.enableChangeDataFeed”: “true”}, replace=True ) @fmlv.check(name=”non_null_sales”, condition=”sales IS NOT NULL”, action=”DROP”) def customer_silver(): df = spark.read.table(”bronze.customer_bronze”) cleaned_df = df.filter(F.col(”sales”).isNotNull()) enriched_df = cleaned_df.withColumn(”sales_in_usd”, F.col(”sales”) * 1.0) return enriched_df
Несколько важных нюансов работы с PySpark, о которых стоит знать:
- На момент написания статьи MLV-файлы PySpark все еще находятся в стадии предварительного просмотра.
- Сегодня MLV-файлы, созданные в PySpark, всегда обновляются полностью. Оптимальное обновление для PySpark запланировано, но пока не реализовано.
- Декоратор
@fmlvне поддерживает динамические параметры или переменные. Все параметры должны быть заданы жестко. - Создать MLV-файл из временного представления PySpark (
createOrReplaceTempView) невозможно — движок не видит представления, ограниченные областью действия сессии. Используйте физические таблицы Delta или другие MLV-файлы в качестве источников. - Не удаляйте блокнот, в котором определен MLV-файл. Без него запланированное обновление завершится неудачей.
Таким образом, если ваше преобразование можно четко выразить в SQL, SQL по-прежнему остается лучшим выбором с точки зрения производительности. MLV-файлы PySpark открывают возможности в тех случаях, когда одного SQL недостаточно.
4. Обновления на месте (Замена)
Бизнес-логика меняется. Фильтр изменяется. В объединении появляется новый столбец. В агрегации добавляется метрика. В предварительной версии обновление определения MLV требовало его удаления и повторного создания, что приводило к потере истории обновлений и вынуждало конечных потребителей переподключаться.
Теперь, благодаря функции «Заменить», вы обновляете определение MLV непосредственно на месте. Fabric проверяет новую логику, заменяет её и сохраняет идентичность представления, метаданные и происхождение. Зависимости от нижестоящих компонентов остаются неизменными. Работает как для SQL ( CREATE OR REPLACE ), так и для PySpark ( replace=True ).
Это одна из тех незаметных функций общего доступа, которая не попадает в заголовки, но имеет огромное значение в повседневной работе. Если вам когда-либо приходилось координировать удаление и повторное создание сильно загруженной таблицы во время работы производственной среды, вы знаете, насколько это сложно. С этой функцией такая проблема исчезнет.
5. Более высокое качество данных
Ограничения качества данных в MLV-файлах — не новость, но в версии GA они получили серьезное обновление. Теперь вы можете:
- Используйте логику на основе выражений, которая объединяет несколько столбцов.
- Применяйте арифметические операции и встроенные функции в рамках одного правила.
- Для проверки логики, реализуемой на Python, а не на SQL, используйте определяемые пользователем функции, ограниченные областью действия сессии.
В сочетании с автоматически генерируемыми отчетами о качестве данных это дает практически встроенный уровень мониторинга данных. Вы можете быстро определить, какие правила чаще всего дают сбой, на какие представления они влияют и как меняются тенденции с течением времени, без необходимости создания отдельного конвейера мониторинга.
Отображение происхождения зависимостей — бесплатно.
Когда один MLV-файл ссылается на другой (или на таблицу), Fabric автоматически определяет взаимосвязь. Никакой ручной настройки, никаких внешних инструментов оркестрации. Зависимости определяются на основе ваших SQL-запросов.
Этот граф зависимостей становится визуальной родословной в вашем доме на берегу озера. Каждый узел представляет собой преобразование. Стрелки показывают порядок выполнения. Fabric гарантирует, что когда поступают данные о бронзе, сначала выполняется MLV-преобразование из бронзы в серебро, а затем MLV-преобразование из серебра в золото выполняется для только что обновленных данных о серебре.

Вот где декларативный подход действительно окупается. Вы не пишете конвейеры. Вы не определяете оркестровку. Вы описываете, как должен выглядеть каждый слой, а Fabric сам определяет порядок. В этом и заключается прелесть декларативного подхода 🙂
Несколько полезных моделей поведения, о которых стоит знать:
- Независимые точки зрения развиваются параллельно.
- Ошибки отображаются централизованно, а не теряются в выводе ячеек блокнота.
- Отображение истории происхождения автоматически обновляется каждые две минуты во время выполнения задания.
- В представлении происхождения все ярлыки рассматриваются как исходные сущности.
- Вы можете подключить пользовательскую среду Spark к цепочке создания материализованных представлений Lake View, чтобы оптимизировать производительность и использование ресурсов во время обновления.
Качество данных – заявлено!
Я уже упоминал об этом выше, но это заслуживает отдельного раздела, потому что это одна из вещей, которая отличает MLV-конвейеры от конвейеров, созданных вручную.
К каждому MLV-файлу может быть прикреплено одно или несколько ограничений качества данных:
CREATE OR REPLACE MATERIALIZED LAKE VIEW silver.valid_orders ( CONSTRAINT positive_quantity CHECK (quantity > 0) ON MISMATCH DROP, CONSTRAINT valid_date CHECK (orderDate >= '2020-01-01') ON MISMATCH FAIL ) AS SELECT * FROM bronze.orders
Два типа действий:
- DROP – строки, нарушающие правила, удаляются, количество записей регистрируется в представлении происхождения данных, и конвейер обработки продолжается.
- FAIL – обновление останавливается при первом нарушении. Это также значение по умолчанию, если вы его не укажете.
Если присутствует несколько ограничений и настроены оба варианта поведения, приоритет имеет параметр FAIL.
Нарушения отображаются в представлении происхождения данных и подробностях выполнения. Хорошо, но как это выглядит на практике? В отчете о качестве данных вы увидите количество ошибок по ограничениям, по представлениям, за определенный период времени. Так, если ограничение, которое обычно приводит к ошибке в 0,1% строк, внезапно приводит к ошибке в 15%, вы увидите всплеск и точно узнаете, какое правило не сработало и к какому представлению оно относится. Это сигнал качества, который в противном случае пришлось бы формировать вручную.
В документации Microsoft также отмечается, что новые ограничения на основе выражений поддерживают встроенные функции Spark/SQL, такие как UPPER() , LOWER() , TRIM() , COALESCE() , INITCAP() и DATE_FORMAT() , поэтому ваши условия CHECK могут быть более сложными, чем простое сравнение.
Когда многослойные жидкие хлопья проявляют себя с лучшей стороны, а когда нет.
MLV-файлы — это не универсальное решение. В документации Microsoft довольно прямо указано, где они уместны, а где нет.

Используйте MLV-файлы, если у вас есть:
- Часто используемые агрегированные данные (суточные итоги, ежемесячные показатели), где предварительно рассчитанные результаты превосходят повторный запуск дорогостоящих запросов.
- Сложные операции объединения данных из нескольких больших таблиц, которые должны быть согласованы для всех потребителей.
- Правила качества данных, которые вы хотите применять единообразно и декларативно.
- Отчетные наборы данных, объединяющие данные из нескольких источников и использующие функцию автоматического обновления.
- Шаблон проектирования «Медальон» — от бронзы к серебру и к золоту, определяемый с помощью SQL-преобразований.
Не используйте многослойные жидкие аммониевые соединения в следующих случаях:
- Запрос выполняется один раз или очень редко – предварительные вычисления не помогут.
- Преобразования и так просты и быстры.
- Если вам нужна не-SQL логика, например, вывод результатов машинного обучения, вызовы API или сложная обработка данных на Python, то ноутбуки по-прежнему лучше (хотя MLV-файлы PySpark начинают заполнять этот пробел).
- Для потоковой передачи данных необходима задержка менее секунды — это область применения технологий интеллекта в реальном времени.
Добавлю здесь личное замечание. Сейчас я активно участвую в проекте Microsoft Fabric, где активно обсуждается выбор между «серебряным слоем» — Warehouse или Lakehouse с MLV. И я постоянно возвращаюсь к следующему: MLV не конкурируют с Warehouse в том смысле, в каком это представляют некоторые. Они конкурируют с запутанной сетью блокнотов и конвейеров, которые вы бы иначе создавали внутри Lakehouse. Если ваша команда уже свободно владеет SQL, и ваши преобразования естественным образом реализуются в операторах SELECT, то аргументы в пользу MLV как «серебряного слоя» в архитектуре на основе Lakehouse действительно убедительны.
Важная информация – что нужно знать, прежде чем начать.
Я бы оказал вам медвежью услугу, если бы представил многослойные кровельные материалы как панацею. У них есть существенные ограничения, некоторые из которых будут иметь значение для вашей архитектуры:
- Отсутствие межсетевого взаимодействия и выполнения — все источники, MLV-файлы и зависимости должны находиться в одном и том же хранилище данных. Если вы используете таблицу Fabric Data Warehouse в качестве источника, вам необходимо сначала создать ярлык к ней в вашем хранилище данных.
- В MLV-файлах нельзя использовать операторы DML — нельзя
INSERT,UPDATEилиDELETEданные. Данные — это то, что генерирует оператор SELECT. - В определении не допускаются запросы, связанные с путешествиями во времени –
VERSION AS OFиTIMESTAMP AS OFзапрещены. - В определении SQL отсутствуют пользовательские функции (UDF) , хотя PySpark, используя интерфейс PySpark, восполняет этот пробел с помощью пользовательских функций, ограниченных областью действия сессии.
- Временные представления не могут использоваться в качестве источников — оператор SELECT может ссылаться на физические таблицы и другие MLV-объекты, но не на временные представления. Это относится и к PySpark: результаты вызова
createOrReplaceTempView()не видны механизму MLV. - Свойства Spark на уровне сессии не применяются во время запланированного обновления — вместо этого задавайте их на уровне хранилища данных или рабочей области.
- Регистр букв в имени схемы имеет значение — имена схем, написанные только заглавными буквами, не поддерживаются. Используйте смешанный регистр или строчные буквы.
- Доступность в регионе – на момент написания статьи MLV недоступны в южно-центральном регионе США.
Ни одна из этих проблем не является критической для большинства конвейеров обработки данных. Но о них стоит знать, прежде чем вы выберете архитектуру, основанную на MLV-файлах, и обнаружите это ограничение на полпути.
Подводя итоги
Если вы создавали шаблоны проектирования Medallion в Fabric с помощью блокнотов и конвейеров, то MLV-файлы заслуживают серьезного внимания. Они объединяют пять поверхностей в один декларативный слой. Управление зависимостями происходит автоматически. Качество данных заложено изначально. Прослеживаемость происхождения данных видна. И, начиная с FabCon Atlanta, они готовы к использованию в производственной среде.
План Microsoft ясен: оптимальное обновление MLV-файлов, созданных с помощью PySpark, появится в будущем, больше SQL-операторов станут доступны для инкрементального обновления, а также планируется более глубокая интеграция с другими рабочими нагрузками Fabric. Это лишь этап, а не финишная линия, и мне любопытно посмотреть, как будут развиваться MLV-файлы в течение следующих нескольких кварталов, особенно в отношении инкрементального обновления PySpark и любых межсистемных разработок, о которых может рассказать Microsoft.
Два главных вывода, которые я бы запомнил:
- Теперь писать, планировать и доверять термину «T» в вашем ELT стало намного проще – если этот «T» – SQL.
- MLV-файлы не заменяют каждый блокнот, каждый конвейер или каждое хранилище данных. Но для декларативных преобразований, требующих отслеживания происхождения данных, обновления и обеспечения качества данных, они теперь являются допустимым вариантом по умолчанию в Microsoft Fabric.
Спасибо за чтение!
Никола Илич. Все работы Николы Илича.
Источник: towardsdatascience.com
Оцените материал:
