ИИ-ассистент с долговременной памятью, агентами и vision. Проблемы с Персональными Данными
Оглавление:
-
История
-
Память: факты, embeddings и забывание
-
Разные модели под разные задачи
-
Tool calling
-
Планировщик и proactive
-
Агенты и мультиагентский пайплайн
-
Vision, который знает контекст
-
Персональные данные и GigaChat
-
Что делать дальше
История
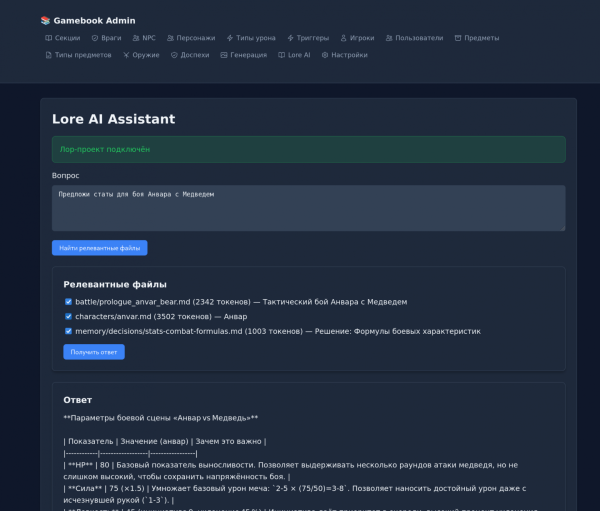
Изначально ничего общего с ассистентом не было. Мы с женой делали текстовую браузерную игру: выборы, немного тактики, бои. Она автор, я помогал адаптировать её тексты под формат игры и собирал бэкенд. Чтобы ей было удобно генерировать лор, я поднял отдельный репозиторий, прикрутил интеграцию с Claude и китайской GLM моделью, собрал админку игры на Symfony. Контента она наделала много, и он был нужен и мне: характеристики персонажей, описания боёв. Запросы вроде «покажи бой Анвара с Медведем» или «какая воля у Кид» решались через локальную LLM (Ollama).
Там же появилась первая связка, которая потом стала основой: Ollama на игровом ПК плюс Postgres с pgvector.
Эмбеддинги по лору игры — и простые запросы начинают работать быстро и бесплатно. Получился простенький RAG.
Вторая проблема выросла из иллюстраций. Для игры их нужно было много. Сначала генерация промптов для Stable Diffusion жила в админке, потом я вынес это в отдельное приложение — я уже писал про него (https://habr.com/ru/articles/1030628/). Но главное не это. Главное, что пока я всё это собирал, я постоянно и подолгу общался с ИИ. И ловил себя на том, что раз за разом пишу одно и то же: «у меня RTX 4070 Ti Super, 16 ГБ VRAM, мне надо вот это …».
И в какой-то момент пришёл к логичному: «Если ИИ и так всё это знает обо мне, почему я должен повторять?» Так родилась идея ассистента, который помнит тебя между разговорами, умеет работать с документами и реально что-то делает, а не просто отвечает на вопросы.
Что я хотел получить:
-
память: ассистент сам вытаскивает факты из диалога и хранит их;
-
ассистенты: чаты с готовым промптом, по сути агенты;
-
база знаний: прикрепляешь ссылку или файл, и ИИ работает прямо в этом контексте;
-
и конкретные мои «хотелки»: «прочитай статью и перескажи коротко», «найди салонный фильтр для моей машины» (именно моей), «найди простую чёрную майку на маркетпйлесах» (без допроса про рост и размер), «напомни в 15:00 о …», «какие у меня планы на завтра?».
Стек выбрал такой: бэкенд на Go, фронт на Vue 3 как PWA и Capacitor для сборки APK под Android, в базе PostgreSQL с расширением pgvector (потому что уже было), LLM через облачные провайдеры. Об этом далее.

Память делится на две части, и это важно их не смешивать.
Первая часть — это векторный поиск по контексту. Когда приходит сообщение пользователя, я собираю промпт: системный шаблон, профиль, последние сообщения истории и релевантные куски из базы знаний через RAG. История и база знаний живут на pgvector. Я выбрал pgvector, а не отдельную векторную базу типа Qdrant или Weaviate, по простой причине (выше писал): у меня и так PostgreSQL, профиль и факты там же.
Вторая часть — это факты. Это не просто «история переписки», а структурированные утверждения про пользователя, которые ассистент сам вытаскивает из диалога. После каждого сообщения работает extraction: отдельный вызов модели читает пару последних сообщений и возвращает JSON с фактами. «У пользователя Toyota Camry 2019 года», «аллергия на пыльцу», «работает ночью».
Пример — как это выглядит под капотом. Представим, что пользователь написал:
У меня Toyota Camry 2019 года. В среду был на медосмотре, всё нормально, но врач сказал сдавать кровь каждые полгода. И напомни завтра в 15:00 забрать заказ из пункта выдачи.
Что extraction вытаскивает из этого сообщения:
{ “facts”: [
{“fact”: “У пользователя Toyota Camry 2019 года”, “category”: “personal”, “kind”: “fact”},
{“fact”: “Пользователь должен сдавать кровь каждые полгода”, “category”: “health”, “kind”: “fact”}
],
“tasks”: [ {“description”: “Забрать заказ из пункта выдачи”, “deadline”: “2026-06-23T12:00:00Z”}
],
“completed_tasks”: []
}
Обратите внимание на дедлайн: «завтра в 15:00» превратилось в 2026-06-23T12:00:00Z — конкретная дата и 12:00 UTC.
Факты потом подмешиваются в системный промпт при следующем разговоре. И тут выясняется, что просто копить их нельзя: их становится слишком много, они устаревают, начинают конфликтовать — один факт говорит одно, а другой, добавленный через неделю, почти противоположное. Память без управления быстро превращается в помойку, и качество ответов падает.
Поэтому поверх накопления пришлось строить ещё несколько механизмов. Сначала нормализация времени: «сегодня», «вчера», «ночью» в тексте факта заменяются на конкретную дату, иначе через неделю факт теряет смысл. Потом веса: у каждого факта есть вес. При сохранении нового факта система ищет похожий по смыслу (similarity выше 0.70) и, если находит, считает это повтором — вес старого факта растёт, а дубль не плодится. В обратную сторону вес падает сам: планы старше 30 дней и события старше 14 дней постепенно уменьшаются до нуля. Факт с весом 0 физически не удаляется, но в промпт больше не попадает. Не всё стареет одинаково: имя и семью важно держать вечно, а «что ел на обед неделю назад» можно смело забывать. Дальше — summary: старые факты периодически агрегируются и сжимаются, чтобы не тянуть в промпт всё подряд.
И всё равно весов и summary мало: иногда факт нужно выкинуть сознательно и сразу. Для этого есть забывание прямо из чата. Пишешь «забудь про носовое кровотечение» — модель вытаскивает суть («носовое кровотечение»), и система удаляет все похожие факты.
Про нос — пример реальный. Я разбил нос и попросил чат «Фитнес-тренер» подстроить мне тренировку на сегодня. Проблема всплыла позже: чат запомнил про нос и стал постоянно его учитывать — уменьшать нагрузки «чтобы не было проблем с давлением» и раз за разом спрашивать: «Как сегодня твой нос?». Пришлось написать «забудь про носовое кровотечение» — и вопросы закончились.
Изоляция памяти (space)
С играми всплыла и вторая проблема — утечка контекста. Однажды фитнес-тренер посоветовал мне «не брать большие веса после вчерашнего удара топором по голове». Удар топором был в чате-игре D&D, а попал в советы по тренировкам. Поэтому факты разделили по пространствам (space): у некоторых чатов своя локальная память, и, к примеру, игровые факты в ней и остаются, не смешиваясь с основным профилем. Глобальное живёт отдельно от того, сколько HP у моего орка.
Кстати, про игры. Играть с ИИ — отдельный кайф: контекст держится, и сюжет меняется прямо в диалоге. Моя ситуация: играю орком в D&D, захожу в очередную комнату, на меня кидается маг с ножиком. Вместо того чтобы сразу бить, я заговорил с ним: «Мы прошли кучу комнат и завалили куда более страшных противников, ты будешь просто очередной жертвой; давай лучше выберемся, я познакомлю тебя с прекрасными девами и угощу вином, только умойся, а то от тебя плохо пахнет (я использовал другое слово)». Маг сел, загрустил и сказал, что с ним ещё никто так не говорил, и отдал ключ от следующей комнаты.

Разные модели под разные задачи
Первоначально у меня была одна модель на всё.
Дело в том, что задачи очень разные по требованиям. Чат должен быть умным и быстрым. Extraction — это вообще не чат: модели скармливают короткий промпт и просят вернуть строгий JSON, тут важна дешевизна и следование формату, а не глубина рассуждений. Vision — отдельный класс моделей. Пихать одну дорогую vision-модель на extraction — дороже.
Поэтому в архитектуре появилось разделение: chat-модель, extraction-модель и vision-модель, каждая со своим назначением. В конфиге провайдера это просто три поля, и у каждой свой модельный ID.
Для ориентира — цены у одного из агрегаторов (не буду писать какой) на момент написания:
|
Задача |
Модель |
Input / Output, ₽ за 1M токенов |
|
Чат (основная) |
Gemini 2.5 Flash |
33 / 276 |
|
Чат (эконом) |
Qwen 3.5 Flash |
4 / 44 |
|
Extraction |
GPT-5 Nano |
4 / 31 |
|
Vision |
Qwen3 VL Flash |
3 / 33 |
|
Embeddings |
text‑embedding-3-small |
3 |
Extraction гоняется на дешёвой Nano, основное общение — на Gemini, и только когда в чате появляется фото, работает vision-модель. Себестоимость среднего пользователя при такой схеме получается вменяемой.
Важный момент про саму интеграцию. Я не стал привязываться к одному провайдеру. Все LLM-вызовы идут через единый OpenAI-совместимый клиент, а провайдеры лежат в таблице с приоритетами. Если основной падает или отдаёт 5xx, запрос уходит на следующий в цепочке. Это спасает и при сбоях, и при перегрузке.
Tool calling
Чтобы ассистент не просто говорил, а действовал, нужен tool calling. Я использую стандартный OpenAI-формат: описываю функции, модель сама решает их вызвать, tool_choice выставляется в auto, когда функции переданы.
Зачем это нужно. В чат-играх (D&D, детектив, выживалка на острове) ассистент поначалу запоминал состояние персонажа как факт: «здоровье 3/30 HP». Но HP в бою меняется каждый ход, и сохранённый факт мгновенно устаревал — в новом бою модель приписывала персонажу старое здоровье и путалась. Запоминать через extraction то, что постоянно меняется, нельзя.
Tool calling чинит это иначе: модель не хранит HP как факт, а вызывает функцию и получает актуальное состояние персонажа. Точное значение по запросу — без устаревшей памяти и без угадывания. В этом и суть tools: давать модели доступ к живым данным вместо того, чтобы она их тащила из фактов.
Планировщик и proactive
Следующая ступень после «отвечает, когда спросили» — ассистент, действует сам. Хорошо работает с чатом «Планировщик» (но не только там). Он не привязан к одному чату: собирает факты из всех разговоров и видит задачи пользователя, поэтому картина у него цельная, а не обрывок текущего диалога.
Работает в двух режимах.
Проактивный: утром планировщик сам пишет планы на день, а в течение дня напоминает о задаче, время которой подошло.
Реактивный: на «какие у меня планы на завтра?» отвечает по реальным задачам, а на «добавь задачу на завтра» или «для такого-то факта укажи время» — вносит правки. Задачи и факты можно не только читать, но и менять прямо из чата.
Ассистенты в моём понимании — это чаты с готовым системным промптом. Завёл чат «травник», задал ему роль — и он придерживается её в ответах, опираясь на твою память и базу знаний.
Но интереснее, когда агенты работают не поодиночке, а в цепочке. Возьмём пример: приложением пользуется моя жена. Она выращивает травы и делает из них натуральную хендмейд-косметику. Допустим, нужно сделать контент про какое-то растение. Сначала используем чат «травник» — он вытаскивает суть и факты по теме. Его результат уходит копирайтеру, который превращает это в читаемый текст. Затем подключается SMM-стратег и адаптирует текст под конкретную площадку: заголовок, тон, формат. Плюс она обучила модель своему стилю письма (по примеру своих же статей). На выходе — не один ответ модели, а готовый материал, прошедший через трёх специалистов и сохранивший стиль автора.
Мультиагентский пайплайн можно применить и для других задач:
-
обучение и экзаменация;
-
генератор идей → критик → финализатор;
-
вопрос, прошедший через разных советчиков и критиков;
-
шопинг: ищем девайс — один агент собирает характеристики, другой подбирает примеры, третий сверяет с бюджетом.
Придумать можно ещё многое. Близкая аналогия — то, как агенты работают в разработке ПО: архитектор -> кодер -> ревьюер.
Только что пока я пишу статью прибежала радостная жена и говорит: смотри, я задала вопрос, а он мне написал что написал:


Тот же принцип работает и в поиске по маркетплейсам. Когда я говорю «найди салонный фильтр для моей машины», в запрос уходит не абстрактное «модель и год», а конкретно мой автомобиль из памяти. Профиль инжектируется в поиск, и результат получается под меня, а не усреднённый. Разница с обычным «найдите фильтр» колоссальная.
Vision, который знает контекст
Vision-модели работают куда интереснее, когда им не просто показываешь картинку, а даёшь контекст из памяти.
Если просто кинуть фотографию в модель, она опишет, что видит. А если в тот же промпт положить факты про пользователя и его окружение, модель начинает «узнавать». На фото семья — и ассистент не просто видит «несколько человек», а может соотнести их с тем, что знает: кто есть кто. Это уже не распознавание, а понимание.
Технически это мультимодальный контент в OpenAI-формате: текст плюс image_url. Никакой магии, просто правильная сборка промпта. Но эффект заметный.
Персональные данные и GigaChat
Технически всё описанное работает. Но на иностранной модели или на локальной Ollama: и чат, и vision, и embeddings, и tool calling. Проблемы начались, когда я решил выложить всё это в общий доступ.
Проблема в персональных данных. Многие российские агрегаторы юридически находятся в РФ, но физически у них нет своих GPU, и запросы уходят за рубеж даже к простым моделям. Какие точно я не могу сказать и они то не раскроют, как я понимаю. Для продукта, который помнит про пользователя всё, это означает, что все эти данные уезжают в другую страну. С учётом 152-ФЗ это не та ситуация, в которую хочется добровольно лезть.
Логичная мысль — перейти на отечественные модели, чья инфраструктура реально в РФ. Попробовал GigaChat, как самая известная и (наверное) умная. И тут начались проблемы.
GigaChat не OpenAI-совместимый. У него своя авторизация, свой формат промптов, свой формат vision, свои короткие embeddings. По уровню рассуждений он примерно соответствует GPT-4o-mini (как мне показалось). Техническую несовместимость ещё можно докрутить, но основных проблем оказалось несколько.
Extraction фактов не отработал так, как мне нужно. Summary, на котором держится агрегация и сжатие памяти, тоже не зашло. Tool calling на момент моего тестирования в моём сценарии не отработал адекватно. И цены: самая простая модель Lite стоит ~19 тыс. рублей за 300 млн токенов — GigaChat сильно дороже.

Самое наглядное получилось с vision. Я сфотографировал мак без цветка — в таком состоянии растение узнать непросто.
.")
")
Qwen3 VL Flash определил, что это за растение. GigaChat увидел просто «какое-то растение». И это не придирка к частному примеру, а разница в пригодности под задачу.
Что делать дальше
Коротко: Проект готов технически. Поэтому прежде чем вкладывать ещё месяцы в допиливание GigaChat или в свою GPU-инфраструктуру, я хочу понять одно — нужна ли вообще кому-то такая штука.
Вот и сам вопрос. Как по-вашему, что мне делать с этим проектом (не нашел, как сделать опрос):
-
Добить и выложить в опенсорс, пусть живёт как есть. Бэкенд можно использовать как для работы через агрегаторы, так и с локальной Ollama.
-
Тянуть в «серую зону»: остаться на зарубежных моделях через агрегатор, оформить согласие на обработку и не париться. Как я понимаю куча ИИ-чатов в русторе так и живут.
-
Не нужно. Ниша занята, продукт не взлетит, оставить как опыт.
-
Свой вариант в комментариях.
Если кому-то интересно или есть мысли — напишите. Выкинуть жалко: сейчас используем только для себя, а лезть туда, где я не силён, — не буду.
Источник: habr.com
Оцените материал:

