ConvApparel: Измерение и преодоление разрыва в реализме в пользовательских симуляторах.
Мы представляем ConvApparel, новый набор данных для анализа диалогов между человеком и ИИ, а также комплексную систему оценки, разработанную для количественной оценки «разрыва в реализме» в пользовательских симуляторах на основе LLM и улучшения обучения надежных диалоговых агентов.
Быстрые ссылки
- Бумага
- Делиться
Современные разговорные ИИ-агенты, как правило, способны справляться со сложными многоэтапными задачами, такими как задавание уточняющих вопросов и проактивная помощь пользователям. Однако они часто испытывают трудности с длительными взаимодействиями, нередко забывая об ограничениях или генерируя нерелевантные ответы. Улучшение этих систем требует постоянного обучения и обратной связи, но полагаться на «золотой стандарт» тестирования с участием живых людей — это непомерно дорого, трудоемко и, как известно, сложно масштабируемо.
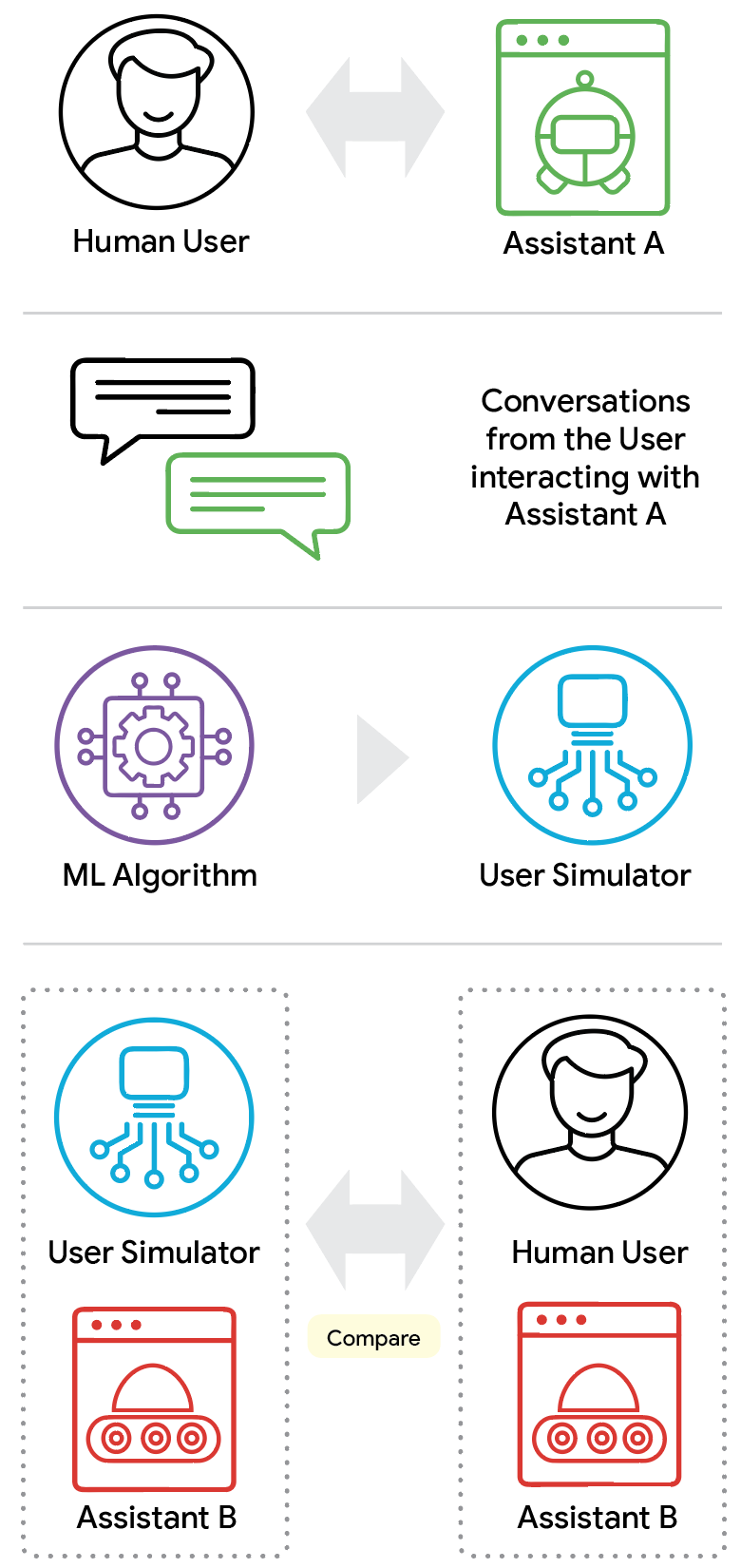
В качестве масштабируемой альтернативы исследовательское сообщество в области ИИ все чаще обращается к пользовательским симуляторам — агентам на основе LLM, которым явно предписано играть роль человека. Однако современные симуляторы на основе LLM все еще могут страдать от значительного разрыва в реализме , демонстрируя нетипичный уровень терпения или нереалистичные, иногда энциклопедические знания в предметной области. Представьте себе пилота, использующего авиасимулятор: лучшие симуляторы максимально реалистичны, с непредсказуемой погодой, внезапными порывами ветра и даже случайными птицами, врезающимися в двигатель. Чтобы сократить разрыв в реализме для пользовательских симуляторов на основе LLM, нам необходимо количественно оценить его.
В нашей недавней статье мы представляем ConvApparel — новый набор данных о диалогах человека и ИИ, разработанный именно для этой цели. ConvApparel выявляет скрытые недостатки современных методов моделирования поведения пользователей и открывает путь к созданию надежных тестировщиков на основе ИИ. Чтобы охватить весь спектр человеческого поведения — от удовлетворения до глубокого раздражения — мы использовали уникальный протокол сбора данных с участием двух агентов, где участники случайным образом направлялись либо к полезному «хорошему» агенту, либо к намеренно бесполезному «плохому» агенту. Эта схема в сочетании с трехкомпонентной стратегией валидации, включающей статистику на уровне популяции, оценку человекоподобия и контрфактическую валидацию, позволяет нам выйти за рамки простого поверхностного подражания.
Задача
Пользовательские симуляторы на основе LLM часто демонстрируют поведение, систематически отклоняющееся от подлинного человеческого взаимодействия, такое как чрезмерная многословность, отсутствие последовательной личности, неспособность выражать связные предпочтения, нереалистичные «знания» и неоправданное терпение. Поскольку большинство LLM обучены быть полезными помощниками, неудивительно, что они плохо справляются с ролью несовершенных, легко раздражающихся пользователей. Если мы обучим наших разговорных агентов взаимодействовать только с этими нереалистичными симуляторами, они могут потерпеть неудачу при работе с реальными пользователями в реальном мире.
Использование реального поведения пользователей для обучения симулятора может быть эффективным. Однако по-настоящему реалистичный симулятор должен не только отражать поведение, полученное из обучающих данных, но и правдоподобно реагировать на новые, ранее не встречавшиеся ситуации (например, новые стратегии диалогового агента). Это крайне важно, поскольку одна из основных целей симуляторов — улучшение работы агента, что часто включает в себя экспериментирование с новыми агентами, которые ведут себя совершенно иначе, чем тот, который использовался для генерации обучающих данных симулятора. Симулятор, переобученный на своих обучающих данных, бесполезен для тестирования новых, непроверенных агентов ИИ. Это приводит к критической методологической проблеме: как проверить способность симулятора к адаптации?
Для решения этой проблемы мы вводим концепцию контрфактуальной валидации , которая задает вопрос: как бы отреагировал смоделированный пользователь, если бы столкнулся с системой, вызывающей разочарование, которая совершенно не похожа на полезные системы, у которых он обучался во время своего (симулятора пользователя) обучения ? Оценивая, как симуляторы обрабатывают неожиданно плохих или вызывающих разочарование диалоговых агентов, мы можем определить, действительно ли они усвоили правдоподобное человеческое поведение или просто слепо повторяют шаблоны обучения.

Проверка методом контрфактуального анализа позволяет оценить способность симулятора пользователя реалистично адаптироваться к неожиданному поведению ассистента, выходящему за рамки стандартной конфигурации.
Набор данных ConvApparel и система оценки
Одним из наиболее перспективных применений разговорных ИИ-агентов являются разговорные рекомендательные системы (РРС), где ИИ-агент выступает в качестве сложной системы поддержки принятия решений, способной к сложным рассуждениям и персонализированным рекомендациям. Для установления базового уровня поведения человека в РРС и обеспечения возможности проведения этого нового типа контрфактической проверки мы создали ConvApparel — набор данных, включающий более 4000 многоходовых диалогов между человеком и ИИ (в общей сложности почти 15 000 ходов) в сфере покупок одежды.
Уникальная мощь ConvApparel заключается в протоколе сбора данных с использованием двух агентов. Участники не знали, что их запросы на покупки случайным образом направлялись к одному из двух различных рекомендательных систем на основе искусственного интеллекта:
- «Хороший» агент : Проявляет себя как полезный и эффективный помощник в покупках, используя мощные возможности поиска.
- «Плохой» агент : специально разработан для того, чтобы быть бесполезным, слегка отклоняющимся от темы и сбивающим с толку. Он незаметно неправильно интерпретирует ключевые слова и намеренно использует заниженные параметры поиска.
Пример стенограммы разговора с сайта ConvApparel.
Ключевой особенностью ConvApparel является использование двух агентов. Это обеспечивает две различные, контролируемые среды, позволяющие зафиксировать широкий спектр пользовательского опыта, от восторга до глубокого раздражения. Кроме того, ConvApparel включает в себя подробные пошаговые аннотации. Мы попросили участников ретроспективно сообщать о своем внутреннем состоянии — таком как удовлетворенность, разочарование и вероятность покупки — на каждом этапе разговора, предоставив редкий набор данных о пользовательском опыте от первого лица, необходимый для проверки как нашей экспериментальной установки, так и смоделированного поведения.
Используя этот обширный набор данных, мы разработали комплексную, основанную на данных систему, состоящую из трех основных компонентов, для оценки точности симулятора. Мы сравниваем три разных симулятора: Prompted, ICL и SFT (подробности ниже).
- Статистическое соответствие на уровне популяции : Мы проверяем, соответствуют ли смоделированные разговоры разговорам людей по различным агрегированным статистическим показателям, таким как длина разговора, количество слов в реплике или типы совершаемых диалоговых действий (например, отклонение рекомендации).
Статистическое сопоставление на уровне популяции сравнивает совокупные поведенческие распределения, такие как многословность пользователей, с результатами моделирования взаимодействий.
2. Оценка человекоподобия : Чтобы уловить тонкие стилистические различия, мы обучили автоматизированный дискриминатор на смеси человеческих и смоделированных разговоров, чтобы получить единый вероятностный показатель, отражающий, насколько «человечным» кажется разговор.
Показатель человекоподобия (HLS) использует обученный дискриминатор для выявления тонких стилистических различий между реальными и синтезированными разговорами.
3. Контрфактуальная проверка : Используя наши данные по двум агентам, мы обучаем симулятор исключительно на разговорах с «хорошим» агентом, а затем заставляем его взаимодействовать с невидимым «плохим» агентом. Высокоточный симулятор должен естественным образом адаптироваться, демонстрируя всплеск фрустрации и снижение удовлетворенности, аналогичные тем, которые наблюдаются у людей.
Фреймворк ConvApparel: протокол сбора данных с участием двух агентов в сочетании со стратегией валидации, основанной на трех компонентах, для эффективного измерения реалистичности симулятора.
Эксперименты
Мы применили нашу трехкомпонентную систему оценки к трем репрезентативным пользовательским симуляторам на базе LLM, созданным с использованием семейства моделей Gemini: (1) симулятор на основе подсказок, который опирался на высокоуровневые поведенческие инструкции без какого-либо специального обучения; (2) симулятор контекстного обучения (ICL), который использовал генерацию с дополненным поиском для предоставления модели семантически похожих примеров человеческих разговоров из диалогов ConvApparel на каждом этапе; и (3) симулятор контролируемой тонкой настройки (SFT), созданный путем обучения модели Gemini 2.5 Flash непосредственно на стенограммах диалогов человека и ИИ ConvApparel для глубокого согласования ее поведения с целевой аудиторией.
Каждому симулятору было поручено сгенерировать 600 диалогов: 300 с «хорошим» агентом и 300 с «плохим» агентом, что позволило нам сравнить их производительность с базовым уровнем, достигнутым человеком.
Для обеспечения этической целостности нашего исследования мы обеспечили полную прозрачность и справедливую компенсацию всем участникам. Оценщики были оплачиваемыми подрядчиками, которые подписали форму согласия и получили стандартную оговоренную в контракте заработную плату, превышающую прожиточный минимум в стране их трудоустройства. Кроме того, оценщикам было прямо поручено использовать рекомендательную систему так, как если бы они намеревались совершить покупку; мы проинформировали всех участников о том, что они взаимодействуют с экспериментальным прототипом, находящимся в настоящее время в разработке, и прямо отметили, что система может демонстрировать неоптимальное поведение.
Результаты
В результате наших экспериментов были получены несколько интересных результатов:
1. Разрыв в реализме легко обнаружить.
На основе нашей оценки сходства с человеком, обученный дискриминатор уверенно определил почти все смоделированные разговоры как синтетические. Даже наши лучшие модели SFT все еще создают едва заметные артефакты — безупречную грамматику и чрезмерно предсказуемую смену реплик — которые их выдают.
2. Методы, основанные на данных, выигрывают по статистическому согласованию.
В наших тестах на уровне популяции симуляторы, основанные на данных (ICL и SFT), неизменно превосходили простой базовый вариант с подсказками, точно отражая распределение поведения людей по уровню многословности и показателям принятия рекомендаций; однако строгие статистические тесты выявляют сохраняющийся разрыв в реализме даже для этих более совершенных симуляторов.
3. Контрфактуальная проверка демонстрирует устойчивость.
Когда симуляторам ICL и SFT, созданным на основе данных, было предложено взаимодействовать с раздражающим «плохим агентом», их базовый уровень поведения в значительной степени не смог адаптироваться, оставаясь неестественно вежливыми и терпеливыми. Однако симуляторы ICL и SFT, основанные на данных, продемонстрировали замечательную обобщающую способность вне распределения. Несмотря на то, что они никогда не видели «плохого агента» в своих обучающих данных, они реалистично изменили свое поведение, демонстрируя заметно более высокий уровень имитируемого разочарования и отторжения.
Заключение
Создание надежных симуляторов пользователей — это основополагающий шаг на пути к разработке следующего поколения надежных, полезных и эффективных разговорных ИИ. Наше исследование показывает, что, хотя потенциал симуляторов пользователей на основе LLM огромен, слепое полагание на них сопряжено со значительными рисками. «Разрыв в реализме» сохраняется, и оптимизация агентов ИИ для соответствия нереалистичным симуляторам может навредить их работе в реальных условиях.
Представляя набор данных ConvApparel и нашу трехкомпонентную систему валидации, мы предоставляем сообществу инструменты, необходимые для тщательного измерения и, в конечном итоге, преодоления этого разрыва. Контрфактуальная валидация доказывает, что мы должны выходить за рамки поверхностного подражания, чтобы гарантировать, что наши симуляторы смогут реалистично адаптироваться к новым динамикам разговора. Мы приглашаем исследователей и разработчиков изучить набор данных ConvApparel и использовать нашу систему для создания надежных синтетических пользователей, необходимых для будущего разговорного ИИ.
Что дальше?
Хотя наши эксперименты показывают, что симуляторы, основанные на данных, значительно превосходят симуляторы, использующие подсказки, создание высокореалистичного искусственного пользователя остается сложной задачей. Наша система успешно измеряет разрыв в реализме, но определение точной степени достоверности, необходимой для эффективного обучения надежного разговорного агента, остается открытым вопросом.
Дальнейшая работа должна быть сосредоточена на использовании этих высокоточных симуляторов для обучения и совершенствования агентов CRS с нуля, а также на измерении результирующей производительности в реальных условиях. Замыкание этого цикла наконец позволит нам количественно оценить степень «человекоподобия», необходимую для создания эффективных, готовых к использованию систем искусственного интеллекта.
Благодарности
Данное исследование было проведено в сотрудничестве с нашими соавторами: Кристианом Балогом, Ави Качиулару, Гаем Тенненхольцем, Дживаном Чжоном, Амиром Глоберсоном и Крейгом Бутилье.
Источник: research.google
Оцените материал:

