Большинство агентов искусственного интеллекта терпят неудачу в производстве, потому что они созданы не по стандартной схеме.
Хорошие модели не спасают плохую архитектуру, и большинство команд убеждаются в этом на собственном горьком опыте.
Делиться

Когда я впервые увидел серьёзный сбой многоагентной системы в производственной среде, это не было чем-то драматичным. Не было ни сбоя, ни сообщения об ошибке. Система просто продолжала работать и выдавать результаты, которые выглядели вполне разумными, пока кто-то внимательно их не прочитал и не заметил, что что-то не так.
Когда мы решили разобраться в этом, нам потребовалось два дня на отладку, чтобы понять, что происходит. Как ни странно, модель не выдавала ошибок, и инструменты ввода-вывода показывали правильные результаты.
Когда мы наконец обнаружили проблему, она оказалась архитектурной. Модель и инструменты были настроены правильно, но предполагалось, что логическое мышление свяжет всё воедино, что, как вы можете догадаться, очевидно, не сработало.
Оказывается, рассуждения так не работают.
Именно к этому опыту я постоянно возвращаюсь, когда думаю о том, почему так много агентов искусственного интеллекта, работающих в демонстрациях, на самом деле не выдерживают суровой реальности при использовании в реальных условиях.
Проблема не в возможностях.
Это вопрос архитектуры.
А если вы читали мою предыдущую статью здесь, на TDS, «Почему инженеры ИИ переходят от LangChain к нативным архитектурам агентов», то эта схема должна показаться вам знакомой: системы строятся сверху вниз, от цели к инструментам и моделированию, с неявным предположением, что интеллектуальное поведение заполнит пробелы.
Именно такое предположение и означает «построение с нуля». И это встречается гораздо чаще, чем кажется большинству команд, пока что-нибудь не сломается.
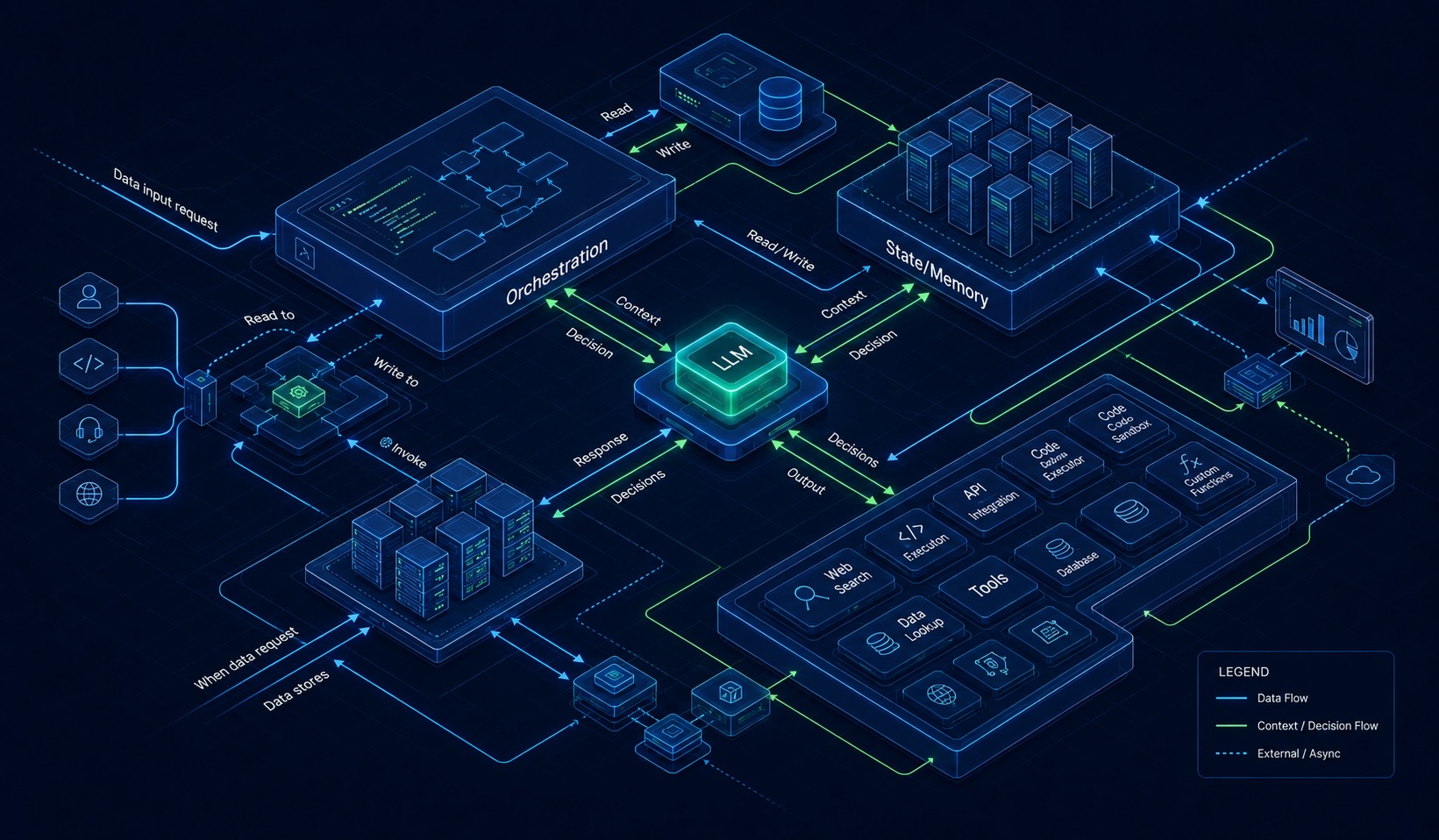
Агенты — это не сущности. Это системы.
Производственный ИИ-агент не представляет собой единое разумное существо.
Скорее, это набор взаимодействующих элементов с различными обязанностями, режимами отказов и уровнями наблюдаемости.
LLM — это лишь один из компонентов, а не вся система целиком. Это всего лишь её часть.
На первый взгляд, это может показаться очевидным. Но концепция «автономного агента», доминировавшая в 2023 и большей части 2024 года, постоянно подталкивала инженеров к иной ментальной модели: одна сущность, один цикл рассуждений, всё обрабатывается моделью.
Всё, что вам нужно, это инструменты, хорошая подсказка от системы и надежда на то, что всё само собой встанет на свои места.
Напротив, инженеры, которые уже выпустили реальные продукты на основе ИИ, редко описывают свои системы таким образом. То, что они описывают на самом деле, гораздо больше похоже на архитектуру распределенных систем.
Не потому, что они читали книгу о шаблонах проектирования, а потому, что достаточно часто обжигались, чтобы начать более серьезно структурировать свой рабочий процесс.
Построение модели «сверху вниз», начиная с вопроса «что должен делать этот агент» и двигаясь в обратном направлении к инструментам и подсказкам, позволяет быстро приступить к работе.
Именно так в итоге получается система, в которой модель отвечает за слишком многое, и отладка отдельных элементов становится невозможной.
Архитектурный замысел определялся поставленной целью, а не инженерными требованиями.
Вот тут-то и начинается обратное.
Так что же на самом деле входит в производственную систему?
Абстрактную версию легко понять и принять. А вот как она выглядит на самом деле.
В каждой работающей системе искусственного интеллекта, которую я видел, есть что-то вроде слоя принятия решений , независимо от того, как команда его назвала. Это та часть, где модель существует и выполняет свою основную работу.
Инстинктивно кажется, что все задачи нужно перенести в этот слой: анализ запросов, управление памятью, обработка повторных попыток, устранение сбоев инструментов.
Это нормально, если вы работаете в блокноте Jupyter. В производственной среде, под нагрузкой, с реальными пользователями, это становится той частью вашей системы, где во всем виноваты все, и в большинстве случаев ничего нельзя отладить.
Уровень принятия решений должен хорошо справляться с одной задачей: определять дальнейшие действия, исходя из уже подготовленного контекста.
В этом и заключается вся работа.
Кто готовит контекст? Это что-то другое. Кто принимает решение? Это тоже что-то другое.
Это «нечто ещё» — это уровень оркестровки, и в большинстве хорошо построенных систем это действительно просто код: условные операторы, асинхронные исполнители, обработка повторных попыток, маршрутизация очередей, возможно, даже конечный автомат, в зависимости от сложности рабочего процесса.
Многие команды обращаются к фреймворкам, потому что простой код оркестровки кажется слишком примитивным, как будто инфраструктура должна быть гораздо сложнее.
Обычно нет.
Чем меньше магии содержится в этом слое, тем быстрее вы обнаружите ошибки, когда они появятся. А они обязательно появятся.
Из собственного опыта я убедился в этом на горьком опыте в проекте, где оркестровка осуществлялась внутри модели выполнения фреймворка. Что-то повторяло вызовы инструментов таким образом, что это приводило к искажению состояния на последующих этапах.
Мы потратили два дня на поиск проблемы. Два дня на ошибку, которую можно было бы исправить в мгновение ока, если бы логика повторных попыток была написана тремя строками кода на Python, которые я написал сам.
Это подводит нас к уровню инструментов и выполнения, где происходит вся коммуникация.
Теперь, слой инструментов и выполнения — это то, где всё взаимодействует с внешним миром. У этого слоя обычно всего одна задача: принять чётко определённые входные данные и затем выдать предсказуемые выходные.
Но чаще всего я сталкивался и, честно говоря, повторял одну и ту же ошибку: инструменты пытались быть полезными, выполняя несколько задач одновременно. Одна-единственная функция, которая вызывает API, обновляет кэш и делает что-то ещё.
В такой системе, когда что-то ломается, вы не знаете, где именно. Даже если вы пытаетесь заменить API, вы распутываете логику, которая вообще не должна была быть запутанной.
Я бы уделил особое внимание памяти и состоянию , потому что именно к этому аспекту большинство команд наименее подготовлены.
Большинство команд рассматривают память как «то, что знает модель». Более важный вопрос заключается в том, что знает система и являются ли эти знания актуальными.
Помню, как однажды мне потребовался целый день, чтобы отладить, казалось бы, простую «модельную галлюцинацию». Модель постоянно ссылалась на пользовательские настройки, которые, однако, были обновлены двадцать минут назад.
Это не проблема модели.
Это системная проблема.
И это на удивление распространенное явление.
В многоагентных системах, в частности, именно в общем состоянии зарождаются скрытые сбои. Один агент что-то обновляет, а другие об этом не знают.
Каждый уверенно движется в немного разных направлениях. Результат выглядит почти правильным, что почти хуже, чем выглядеть неправильным.
А еще есть оценка и наблюдаемость , которые почти все откладывают до тех пор, пока что-нибудь не пойдет не так. Я тоже в этом грешил.
Разница, которую я учитываю, заключается в том, что логирование показывает, что произошло. Наблюдаемость показывает, было ли произошедшее корректным. В детерминированной системе это практически одно и то же.
В системе искусственного интеллекта это не так. Необходимо уметь отслеживать конкретный запрос от начала до конца, включая информацию, которую модель должна была учесть, какое решение она приняла, какой внешний API-вызов она использовала и как она отреагировала на полученный ответ.
Строим это правильно
Начинается все с подхода «сверху вниз»: я хочу, чтобы агент сделал X, поэтому я дам ему инструменты, приятную системную подсказку, и если модель достаточно умна, все будет в порядке.
Именно это люди и используют для создания прототипов, и почему бы им этого не делать? В этом нет ничего плохого.
Но вот в чем дело: проблема в том, что архитектура рассматривается как следствие поставленной цели, а не как нечто, что вы проектируете целенаправленно.
Затем система разрастается. Появляется больше инструментов, больше рабочих процессов, больше нестандартных ситуаций, больше пользователей, и внезапно под всем этим исчезает реальная основа.
Подход «снизу вверх» занимает больше времени, но гораздо удобнее.
Начинаете с основных элементов и убеждаетесь, что они действительно работают. Затем определяете, что должна передавать каждая часть, какие данные она хранит и за что отвечает.
В конечном итоге, система формируется естественным образом в результате взаимодействия её частей.
Это не аргумент в пользу того, что «настоящие инженеры создают всё с нуля». На самом деле, дело даже не в инструментах. Дело в той ментальной модели, которую вы используете при разработке.
Я видел, как инженеры использовали сложные фреймворки и создавали чистые системы, потому что понимали, что должен делать каждый слой.
Я также видел, как инженеры писали код на чистом Python и создавали неотлаживаемый беспорядок, потому что они всё ещё мыслили категориями «агент решает всё». Инструменты же вытекают из модели, которая у вас в голове, а не наоборот.
Самая надёжная многоагентная система, с которой мне довелось тесно работать, практически не имела инфраструктуры, специально предназначенной для ИИ. Когда я впервые увидел этот репозиторий, я честно предположил, что смотрю не на тот код.
Очередь сообщений, рабочие процессы с различными областями видимости, общее хранилище состояния с явно выраженными контрактами на чтение/запись и координатор, принимающий решения о маршрутизации.
Запросы к языковой модели выполнялись самими работниками, каждый из которых получал набор контекста, созданный на предыдущем этапе различным процессом.
В общей сложности, всё это состояло примерно из тысячи строк кода на Python. Я видел демонстрационные агенты с гораздо большим количеством кода. Каждая часть была отслеживаемой.
Когда что-то вел себя неожиданно, мы обычно находили проблему менее чем за час, потому что не нужно было ничего особенного искать. Просто код с четким описанием пути выполнения.
Эта система была построена снизу вверх. Цель была определена, но архитектура не была выведена из неё. Сначала были спроектированы компоненты, оценены по отдельности, а затем скомпонованы для реализации желаемой функциональности. Последний аспект является наиболее важным, а не первый.
Как мне кажется, к чему это всё ведёт.
Насколько я могу судить, направление, в котором мы движемся, постепенно смещается от «агентных фреймворков» к полноценной инфраструктуре с системами для оценки, маршрутизации моделей, резервных вариантов и управления состоянием.
По крайней мере, часть этого уже существует. Большая часть еще появится, поскольку люди будут решать сложные производственные задачи в этой области.
Я постоянно наблюдаю, что люди, создающие самые надежные системы, редко используют даже лучшие модели. Вместо этого у них есть четкое понимание всего, что происходит внутри их систем.
В такой системе может использоваться модель GPT-4, но это также может быть и небольшая локальная модель. Это не имеет большого значения, если всё остальное работает исправно.
Мы переходим от подхода, при котором модель рассматривается как продукт, к подходу, при котором продуктом рассматривается система. Модель важна, но это лишь один из многих компонентов.
Большинство агентов терпят неудачу не потому, что модель была недостаточно хороша. Они терпят неудачу потому, что система, лежащая в основе этой модели, была спроектирована наоборот, исходя из того, что должен делать агент, и предполагая, что архитектура сама собой наладится.
Нет.
Правильный подход к построению системы, начиная с компонентов и заканчивая поведением, отличает надежные системы от тех, которые выглядят впечатляюще, пока не рушатся.
Перед уходом!
Я пишу подробнее о реальных инженерных решениях, лежащих в основе систем искусственного интеллекта, о том, где абстракции помогают, где они вредят и что необходимо для создания надежных систем.
Вы можете подписаться на мою рассылку, если хотите получать больше подобных материалов.
Свяжитесь со мной
- Подстек
Бенджамин Нвеке Посмотреть все работы Бенджамина Нвеке
Источник: towardsdatascience.com
Оцените материал:
