Автоматизируйте написание тем для ваших магистерских диссертаций.
Используйте DSPy для автоматического создания, оценки и оптимизации ваших подсказок.
Делиться

Работая с магистрами права, мы, вероятно, все сталкивались с ситуациями, когда получали ответы, которые не совсем соответствовали нашим ожиданиям. Обычно мы несколько раз переформулируем вопросы, пока не получим что-то приемлемое. Иногда нам приходится быть более ясными, более точными, приводить примеры, описывать, почему нам нужен именно этот ответ, представлять портрет целевой аудитории или иным образом предоставлять достаточно контекста и информации, чтобы магистра права смог дать подходящий ответ.
Это может быть вполне приемлемо, когда мы работаем напрямую с LLM. Однако ситуация кардинально меняется, когда мы пишем приложение на основе LLM — программное обеспечение, которое будет выполняться самостоятельно и при этом взаимодействовать с одним или несколькими LLM. В этом случае программное обеспечение будет работать с предопределенными подсказками и передавать их LLM. Если что-то пойдет не так, у нас нет возможности переформулировать подсказки и попробовать снова. Это означает, что они должны быть изначально написаны таким образом, чтобы быть надежными и стабильными — нам нужны подсказки, в работе которых в производственной среде мы можем быть уверены.
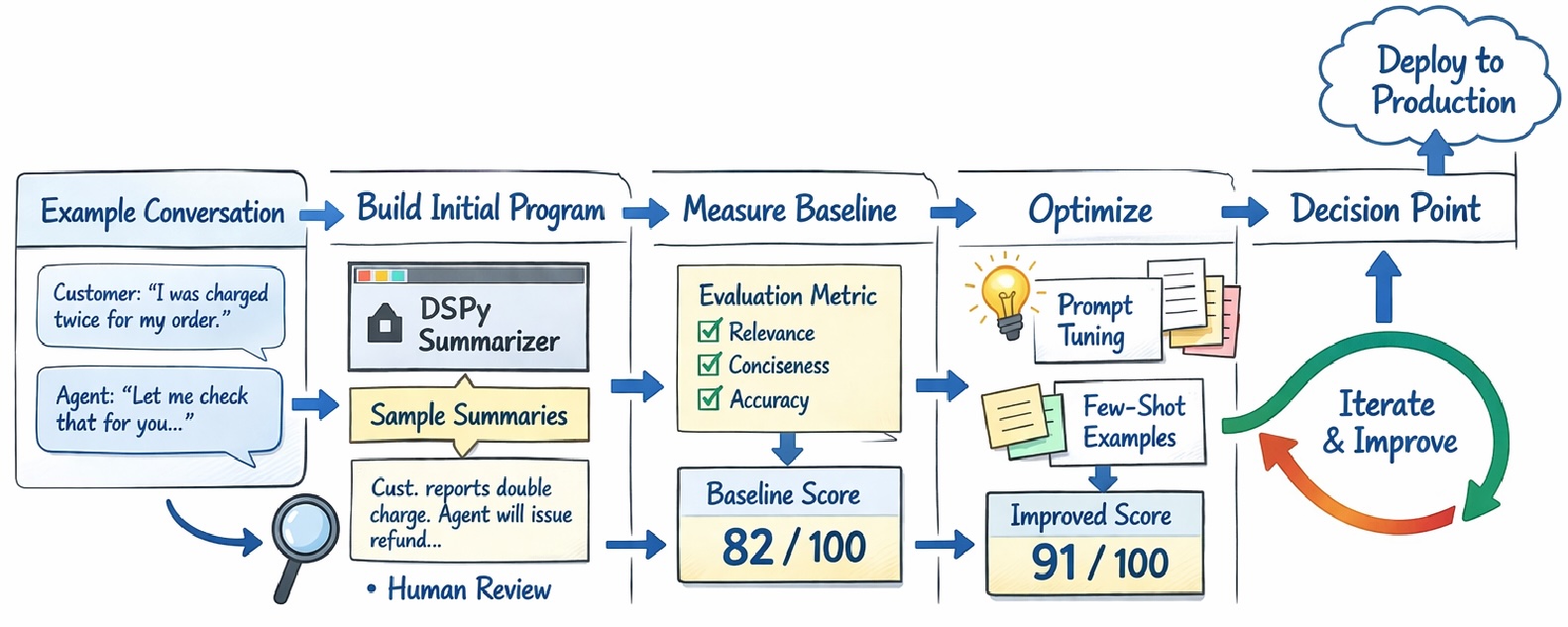
Создание подобных подсказок может быть непростой задачей. В этой статье мы рассмотрим, почему это так, а также как инструмент Python под названием DSPy может помочь в создании надежных подсказок. DSPy не только автоматически генерирует подсказки, но и тщательно их оценивает, поэтому вы можете быть уверены в том, насколько хорошо они будут работать в реальных условиях.
Я также приведу отрывок из своей последней книги, изданной Manning Publishing, «Создание приложений LLM с помощью DSPy», написанной в соавторстве с Сержем Смородинским. В ней содержится полное описание DSPy и того, как использовать его для создания приложений на основе LLM.
 Изображение обложки книги
Изображение обложки книги
Секрет создания подсказки, которая будет надежно работать в производственной среде.
Одна из сложностей создания надежного запроса заключается в том, что мы не можем полностью предсказать исходные данные для него. Допустим, мы создаем программное приложение, которое будет обрабатывать документы. Документы могут быть найдены в интернете или предоставлены пользователями программного обеспечения. В процессе обработки документов приложение может попросить магистра права (LLM) резюмировать их, перевести, извлечь ключевую информацию или выполнить какую-либо другую подобную задачу. В этом примере предположим, что программное обеспечение попросит магистра права оценить, насколько правдоподобным кажется содержание документов. Для этого мы можем написать запрос, например, такой:
prompt_text = f"Assess how plausible the following text is: {document_text}"
В этом случае для формирования запроса используется строка типа `f` в Python, с ячейкой для текста документа. Другие запросы могут иметь несколько ячеек для ввода, но для простоты мы будем предполагать, что каждый запрос имеет только один входной параметр — фрагмент контента, который вы хотите, чтобы LLM обработал (это та часть, которая непредсказуема).
Этот подход может сработать достаточно хорошо, но может и нет. Существует множество способов, которыми преподаватель может ответить так, как нам не понравится, по крайней мере, иногда. Мы можем обнаружить, что преподаватель обращает внимание на несущественные детали в документах. Или у него может быть иное представление о «правдоподобности», чем мы предполагали. Или он может указать, что почти каждый документ полностью правдоподобен (или наоборот, что почти ни один из них не является таковым). Или ответы могут быть оформлены не так, как нам хотелось бы.
Возможно, нам потребуется подкорректировать вопрос, чтобы постоянно получать ожидаемые ответы. Для начала можно попробовать этот и несколько других простых вопросов, но в итоге окончательный вариант может оказаться значительно длиннее и подробнее.
Обычно, по мере тестирования с большим количеством входных данных (в данном случае, документов), мы обнаруживаем больше случаев, когда текущий запрос плохо обрабатывает эти данные, поэтому мы корректируем запрос, чтобы он лучше справлялся с такими ситуациями. Иногда мы можем переформулировать запрос, чтобы сделать его более понятным, а иногда добавить несколько предложений для обработки этих конкретных случаев. Например: «Если в документе содержатся метафорические утверждения, оценивайте общий смысл, а не буквальное значение». В результате мы можем получить множество подобных дополнительных инструкций в запросе, которые могут помочь ему хорошо работать в этих случаях, но, конечно, могут также ухудшить его работу с другими входными данными.
И по мере того, как задания становятся длиннее и сложнее, их становится всё труднее корректировать. Становится всё менее и менее ясно, к какому эффекту приведут добавление, удаление, изменение порядка или формулировка фраз в задании.
Другие приложения, основанные на LLM, могут работать с другими типами текстовых данных: текстовыми сообщениями, электронными письмами, эссе, статьями из научных журналов, заявками на патенты и так далее. Или могут обрабатывать изображения, аудио, видео или другие форматы. Но независимо от типа входных данных, для нетривиального приложения конкретные входные данные, с которыми оно сталкивается (и которые передает в LLM), будут, по меньшей мере, несколько непредсказуемыми. Это означает, что нам потребуется надежный, четко определенный запрос для обработки широкого спектра реалистичных входных данных.
Возьмем, к примеру, электронную почту. Если приложение на основе LLM обрабатывает набор писем (с которыми оно столкнется в рабочей среде и которые мы не можем полностью предсказать), то среди них могут оказаться необычно длинные, сложные, многозначные, запутанные, сумбурные или иным образом не соответствующие нашим ожиданиям при формировании запроса. Единственный способ проверить надежность работы приложения в рабочей среде — это протестировать его на большом, разнообразном и реалистичном наборе входных данных (в данном случае, на большом, разнообразном наборе реалистичных писем).
Для каждого тестового случая нам необходимо тщательно изучить ответ LLM и убедиться в его пригодности. В некоторых случаях это несложно. Например, мы можем передать текст в LLM и попросить классифицировать его каким-либо образом. LLM может классифицировать текст по языку (английский, французский и т. д.), эмоциональной окраске, уровню токсичности и так далее. В этих случаях для каждого входного текста существует истинный класс, и существует класс, который возвращает LLM. Нам просто нужно проверить, совпадают ли они: если текст на испанском языке и LLM предсказывает испанский, это правильно; в противном случае — нет. Многие другие задачи LLM также дают результаты, которые легко оценить.
Однако в некоторых случаях оценка ответов не так проста. Например, когда мы просим студента-лингвиста сгенерировать более длинный ответ, такой как резюме, перевод, критика, предложения по дальнейшим действиям или любой другой подобный развернутый результат на основе входных данных. Если вы когда-либо рассматривали два или более разных ответа от студента-лингвиста (оба состоят из одного или нескольких полных предложений, а возможно, и намного длиннее) и пытались оценить, какой из них лучше, вы знаете, что это трудоемкий и чреватый ошибками процесс. Некоторые ответы могут быть более лаконичными, другие — более тонкими, третьи — более ясными. Тем не менее, как бы сложно ни было их оценивать, нам необходимо оценить их, чтобы понять, насколько хорошо работает каждый из предложенных нами вариантов. Одно из преимуществ DSPy заключается в том, что он позволяет автоматизировать эту оценку.
Оперативное проектирование
Чтобы оценить преимущества таких инструментов, как DSPy, полезно рассмотреть альтернативные варианты и проблему, которую решает DSPy. Обычно мы работаем с LLM-модулями, используя метод, известный как разработка подсказок. Для этого мы пишем одну подсказку, тестируем её (обычно с небольшим количеством входных данных и просто оценивая выходные данные визуально), пишем другую подсказку, тестируем её аналогичным образом и продолжаем.
В более простых случаях это может сработать, но у этого метода есть ряд ограничений. Одно из них: тестирование каждого варианта ответа с большим количеством входных данных занимает очень много времени. Поэтому на практике мы обычно тестируем каждый вариант ответа гораздо реже, чем следовало бы. Это может вызвать проблемы — тестирование каждого варианта ответа с очень небольшим количеством входных данных может дать нам плохое представление о том, какие варианты работают лучше.
Ситуация усложняется тем, что для каждого входного параметра нам действительно следует проверять запрос несколько раз (а не только один раз), поскольку LLM являются стохастическими. Если один и тот же запрос (включая одинаковые значения в ячейках) подается несколько раз, LLM может каждый раз выдавать разные ответы. И некоторые из них могут быть лучше других. Если у нас есть, скажем, 20 документов для тестирования (в примере, где LLM будет использоваться для оценки правдоподобности каждого документа), в идеале мы должны проверять каждый несколько раз. Если мы будем проверять каждый 3 раза, это будет означать в общей сложности 60 тестов. Что, в реальности, мы, вероятно, не сделаем. Даже близко не приблизимся к этому.
И, как уже указывалось, это еще сложнее в тех случаях, когда LLM-модели выдают более длинные результаты, поскольку их чтение занимает много времени, и практически невозможно обеспечить согласованность в их оценке.
Таким образом, тестирование каждого варианта ответа занимает много времени. Тестирование множества вариантов ответа требует гораздо больше времени. И неясно, можно ли их действительно объективно сравнить.
Всё это означает, что в целом разработка по запросу обладает интересным свойством: она одновременно трудоёмка и ненадёжна. Это очень медленный, утомительный и подверженный ошибкам процесс. Опытные разработчики часто тратят часы, а то и дни, на один запрос. И в итоге не могут быть уверены, что выбранный ими вариант действительно самый лучший.
Есть ли способ получше?
Давайте на минуту отвлечемся и посмотрим, как мы поступаем в аналогичной ситуации при работе с машинным обучением. Если мы создаем нейронную сеть, модель случайного леса, XGBoost (или что-то подобное), то при каждом обучении нам не нужно вручную тестировать каждый элемент в тестовом наборе по отдельности. На самом деле, сама идея этого кажется немного нелепой. Процесс автоматизирован; тестирование довольно простое. Мы просто пропускаем каждый элемент в тестовом наборе через модель, получаем для каждого предсказание и выполняем функцию для генерации общего балла.
Например, для задачи регрессии мы можем использовать среднеквадратичную ошибку (Mean Squared Error) или коэффициент детерминации R² (R²), а для задачи классификации — F1-меру (F1 Score), коэффициент корреляции Морриса (MCC) или AUROC. Используя такой инструмент, как scikit-learn, мы можем взять предсказания модели для тестового набора и соответствующие значения истинных значений и просто передать их функции для вычисления общей оценки. В результате мы получим одно число, указывающее на то, насколько хорошо сработала модель.
Далее, при желании, мы можем попробовать еще раз с другими характеристиками, другими гиперпараметрами, другими обучающими данными (или внести какие-либо другие изменения по сравнению с предыдущей моделью), переобучить модель и повторно провести тестирование, получив еще один результат.
Таким образом, в проектах машинного обучения у нас есть чистый и эффективный процесс. Но при работе с программами обучения на уровне магистратуры мы, как правило, поступаем совсем иначе, ближе к оперативной разработке — работаем без фреймворка, обеспечивающего согласованность, повторяемость и эффективность. По сути, мы игнорируем многолетний опыт разработки лучших практик в области разработки программного обеспечения.
Однако это необязательно. При работе с LLM-моделями существует ряд инструментов, позволяющих работать аналогично созданию моделей машинного обучения — эффективно, тщательно и воспроизводимо. DSPy, вероятно, является передовым инструментом в этой области, по крайней мере, на данный момент. С его помощью мы указываем тестовые данные и метод оценки качества ответа. На это требуется некоторое время, но после этого практически все остальное делается автоматически.
В примере, где мы просим магистра права оценить правдоподобность документов, мы могли бы собрать набор документов (возможно, 10, 20 или 30, хотя чем больше, тем лучше) в качестве тестового набора. И для каждого из них мы могли бы предоставить эталонное значение его правдоподобности. Это может быть числовое значение, скажем, по шкале от 0 до 10.
Нам также необходимо предоставить DSPy способ оценки качества ответа каждого LLM — в виде функции на Python. Эта функция будет принимать на вход LLM и ответ LLM и возвращать либо: 1) числовое значение (указывающее на качество ответа); либо 2) логическое значение (указывающее, хороший ответ или плохой). В этом примере функция может быть довольно простой, примерно такой:
def evaluate_answer(test_instance, model_prediction): return abs(test_instance.ground_truth - model_prediction)
Это не совсем синтаксис DSPy (я опускаю некоторые мелкие детали для простоты, но это дает общее представление). В данном случае мы предполагаем, что каждый тестовый экземпляр содержит документ, который можно отправить в LLM, и истинное значение (число от 0 до 10 — указывающее на его правдоподобность, вероятно, на основе оценки человека). И мы предполагаем, что предсказание модели также является числом от 0 до 10. Для оценки ответа мы просто берем разницу между этими двумя значениями, поэтому чем меньше разница, тем лучше ответ (чем ближе он к истинному значению).
Для проверки заданного запроса DSPy автоматически выполнит его на указанном LLM-файле, по одному разу для каждого тестового документа. В этом примере для каждого документа программа запросит оценку от 0 до 10, указывающую на его правдоподобность, и сравнит ответ с эталонным значением.
Затем это даст общий балл по тестовому набору (усредненный по всем тестовым примерам в тестовом наборе), который является нашей оценкой того, насколько сильна эта подсказка.
Затем, если мы захотим попробовать другую подсказку или другой LLM, мы можем просто повторно запустить процесс тестирования. Это сгенерирует еще один балл, указывающий на то, насколько эффективна данная комбинация LLM и подсказки. Если мы попробуем несколько подсказок (или несколько LLM), мы сможем определить, какая из них работает лучше всего, просто выбрав ту, которая имеет наилучший общий балл.
Это вполне логичный процесс. Он требует сбора достаточного количества тестовых данных, но это необходимо, если мы хотим в любом случае дать какую-либо оценку заданию. Также требуется написать функцию, которая, получив на вход LLM данные и ответ LLM, сможет оценить силу ответа. В некоторых случаях это может потребовать некоторой работы (мы объясняем, как это сделать, в книге!), но, после написания, мы сможем оценить любое количество ответов на любое количество заданий. И это позволит нам сделать это последовательно и беспристрастно.
Как уже указывалось, если LLM возвращает короткий ответ, например, в задаче классификации, написание функции будет очень простым. И, как мы только что видели, если LLM возвращает числовой балл, функция также может быть довольно простой.
Если LLM выдает более длинный ответ, часто (хотя и не всегда) мы используем подход «LLM как судья», когда один LLM оценивает ответ другого LLM. Это не идеальный вариант, но он исключает человеческие предубеждения и может быть автоматизирован. Это позволяет протестировать множество вариантов ответов и тщательно проверить каждый из них.
Таким образом, DSPy, по сути, делает за вас то, что вы, скорее всего, в итоге написали бы сами, если бы задумались о том, как автоматизировать этот процесс — как автоматизировать поиск подходящего задания. По крайней мере, вы, вероятно, написали бы это сами, если бы у вас было огромное количество свободного времени, и вы были бы единственным человеком в мире, решающим эту проблему — проблему создания и оценки множества вариантов заданий для каждого задания в рамках магистерской программы. Однако, учитывая, что многие из нас сталкиваются с одними и теми же проблемами, наличие инструментов, берущих на себя рутинную работу, по крайней мере, задним числом, кажется вполне естественным.
Что DSPy делает для вас
DSPy выполняет за вас большую часть работы, которую вам пришлось бы делать вручную при использовании подхода оперативного проектирования. Он делает как минимум три основные вещи (на самом деле, немного больше, но в этой статье мы рассмотрим только наиболее важные из них).
- Он автоматически генерирует для вас запрос. Вам нужно лишь кратко описать задачу на высоком уровне, используя строку (или другие форматы, но строки — самый простой вариант). В этом примере мы можем указать: «document -> assessment_of_plausibility». Другой пример: «journal_article -> summary, critique», что означает, что LLM должен взять статью из журнала и вернуть её краткое содержание и критический анализ. DSPy также позволяет нам предоставлять более подробную информацию о задаче, но, как правило, мы можем ограничиться общим описанием.
- Он автоматически оценивает запрос. Вам нужно будет предоставить тестовые данные и функцию Python для оценки каждого ответа, но, учитывая это, DSPy позволяет вам полностью и последовательно оценивать каждый запрос (и каждый LLM), который вы пытаетесь выполнить.
- Он автоматически оптимизирует приглашение к вводу. Это, пожалуй, самый мощный элемент DSPy. Я опишу это далее.
Оптимизация ваших подсказок
Для оптимизации ваших запросов DSPy, по сути, переходит в цикл, который выглядит следующим образом (это несколько упрощенное описание; мы подробно описываем его в книге, но это дает общее представление):
best_prompt = "" loop generate a new candidate prompt evaluate this candidate prompt if this is the best prompt so far: best_prompt = current prompt
Этот цикл длится столько, сколько вы укажете (чем дольше он ищет лучшие подсказки, тем более сильные подсказки он, как правило, находит, хотя, конечно, есть и убывающая отдача). В процессе цикла генерируются новые подсказки-кандидаты. Для этого DSPy использует метод, называемый мета-подсказкой, где одна LLM используется для генерации подсказки, используемой для другой LLM. Для каждой сгенерированной подсказки-кандидата DSPy затем оценивает её.
При использовании более слабых подсказок DSPy может фактически использовать раннюю остановку для повышения эффективности и, следовательно, может прекратить оценку раньше для любых подсказок, которые, по-видимому, показывают плохие результаты по сравнению с ранее протестированными кандидатами. То есть, если он генерирует какие-либо подсказки, которые показывают плохие результаты на части тестовых данных, нет необходимости тестировать эти подсказки на полном тестовом наборе. Однако он полностью оценит более перспективные подсказки и, следовательно, сможет с уверенностью определить самые сильные из протестированных подсказок.
DSPy включает в себя несколько различных процессов для генерации подсказок. Наиболее эффективные из них обучаются в процессе работы. По мере оценки каждой подсказки-кандидата DSPy может узнать, где каждая подсказка показывает хорошие, а где плохие результаты (она может видеть, какие тестовые случаи показывают хорошие, а какие плохие результаты, но DSPy также может понять, почему каждая подсказка показывает хорошие результаты в одних случаях и плохие в других). Затем она может использовать это для предложения все более перспективных подсказок-кандидатов, и таким образом подсказки, как правило, работают все лучше и лучше по мере продолжения процесса.
После запуска DSPy
После запуска DSPy вы получите запрос на определение задачи, а также оценку того, насколько хорошо она будет работать в производственной среде — на основе того, как она покажет себя на ваших тестовых данных. (Как и в машинном обучении, мы обычно делим имеющиеся у нас данные на обучающие, проверочные и тестовые, поэтому в идеале у нас будет контрольный набор данных, используемый только для окончательной оценки).
Это может послужить хорошей основой для решения вопроса о том, достаточно ли она эффективна для внедрения в производство. Если нет, вы можете уделить больше времени оптимизации запроса. Или вы можете рассмотреть другой LLM — после того, как ваш код будет настроен, для оценки другого LLM достаточно указать LLM и повторно выполнить код. Вам придется платить за вызовы LLM (если вы не используете размещенный LLM), но, скорее всего, вам не придется выполнять никакой дополнительной работы.
Пример кода
В большинстве случаев код, который вам потребуется написать для использования DSPy, будет довольно коротким и простым. Я приведу здесь пример, хотя и не буду объяснять его полностью (надеюсь, сделаю это в будущих статьях). Тем не менее, это должно дать вам общее представление о том, что включает в себя работа с DSPy. Для этого требуется установить DSPy через pip и импортировать некоторые компоненты. После этого все будет довольно просто.
import dspy OPENAI_API_KEY = [indicate your API key] lm = dspy.LM("openai/gpt-4o-mini", api_key=OPENAI_API_KEY) dspy.settings.configure(lm=lm) predictor = dspy.Predict("question, context -> answer, confidence") prediction = predictor(question="What is the capital of France?", context="") print(prediction.answer, prediction.confidence)
Этот код не включает в себя оптимизацию или вычисление (он просто выводит запрос и обрабатывает взаимодействие с LLM), но демонстрирует полностью работающую программу на DSPy. Сначала он импортирует dspy, затем указывает используемую модель LLM и ключ API для неё. В этом примере используется модель OpenAI, но DSPy поддерживает десятки различных поставщиков. Затем на высоком уровне описывается задача: получив вопрос и некоторый контекст, модель LLM должна вернуть ответ и степень уверенности в этом ответе. Затем задаётся конкретный вопрос (в этом примере: «Какова столица Франции?», без какого-либо дополнительного контекста) и отображается ответ. При тестировании мы постоянно получали следующие результаты:
Paris, High
Это указывает на то, что ответ — Париж, и что LLM очень уверена в этом ответе.
После некоторой оценки и оптимизации код станет немного длиннее, но не гигантски. Этот пример демонстрирует очень простую задачу, но для более сложных задач оценка и оптимизация обычно будут важны. Всё это вполне управляемо, поскольку DSPy скрывает большую часть сложности под капотом.
Выводы
DSPy не может гарантировать чрезвычайно эффективный запрос подсказок для каждой задачи и каждого LLM. Но он значительно экономит трудозатраты и, как правило, работает так же хорошо или даже лучше, чем профессиональный разработчик запросов подсказок. В будущих статьях я надеюсь рассказать о некоторых экспериментах, сравнивающих DSPy с ручным проектированием запросов подсказок, но вкратце, DSPy стабильно показывает лучшие результаты. Для любых приложений на основе LLM, которые мы создаем, обычно стоит использовать DSPy для создания и оценки запросов подсказок. Освоить фреймворк несложно, и как только вы это сделаете, вы будете готовы к работе над любыми проектами.
В реальности я не всегда буду использовать DSPy в ситуациях, когда мне не нужна строгая подсказка, или когда задача настолько проста для магистра права, что подойдёт любая базовая подсказка. Но всякий раз, когда возникает ситуация, в которой, кажется, мне может потребоваться разработка подсказок, я использую DSPy для автоматизации всей этой работы. Вместо того чтобы вручную создавать и тестировать каждую потенциальную подсказку, я могу просто написать код на DSPy и позволить ему сделать всю работу. Это как иметь собственного помощника по разработке подсказок.
Выполнение может занять некоторое время. Я часто запускаю программу на 20, 30 минут и более, чтобы получить хороший запрос. Но работу выполняет программа, а не я. Стоит обратить внимание на стоимость LLM, хотя DSPy позволяет отслеживать этот показатель. В большинстве случаев более качественные запросы в долгосрочной перспективе обходятся дешевле, хотя в некоторых случаях это может быть не так, и нам следует ограничить время, которое DSPy тратит на создание более качественных запросов.
Это довольно легко сделать — нам просто нужно указать, что следует потратить разумное количество времени на поиск наилучшего варианта ответа. Например, можно указать, чтобы программа протестировала лишь небольшое количество вариантов и выбрала самый лучший. В других случаях может быть целесообразно протестировать множество вариантов.
Я надеюсь, что в будущем опубликую ещё несколько статей, объясняющих работу DSPy.
У. Бретт Кеннеди. Все материалы от У. Бретта Кеннеди.
Источник: towardsdatascience.com
Оцените материал:
