Представляем TabFM: базовую модель для табличных данных, не требующую предварительного обучения.
С момента запуска TimesFM мы наблюдаем масштабные изменения в подходах к прогнозированию временных рядов. Теперь мы применяем ту же самую логику «нулевого старта» к табличным данным.
Мы представляем TabFM, новую базовую модель для табличных данных, интегрированную непосредственно в BigQuery ML, для упрощения рабочих процессов классификации и регрессии.
Быстрые ссылки
- Обнимающее лицо
- GitHub
- Делиться
Табличные данные составляют основу корпоративной инфраструктуры данных и лежат в основе значительной части критически важных приложений машинного обучения для прогнозирования. От прогнозирования оттока клиентов до выявления финансового мошенничества — задачи регрессии и классификации на основе табличных данных повсеместно распространены. В течение многих лет алгоритмы на основе деревьев решений с учителем, такие как AdaBoost, XGBoost и случайные леса, исторически доминировали в этой области, демонстрируя высокую производительность на структурированных данных.
Однако жизненный цикл развертывания этих традиционных моделей представляет собой существенное узкое место. Подгонка модели XGBoost к новому набору данных — это не просто вопрос одного шага .fit() ; это неизменно требует утомительных ручных усилий. Специалистам по анализу данных приходится тратить бесчисленные часы на обширную оптимизацию гиперпараметров и разработку признаков, специфичных для предметной области, просто чтобы извлечь надежный сигнал из необработанных данных.
С другой стороны, недавние достижения в более широкой области машинного обучения — в частности, эволюция больших языковых моделей (LLM) — изменили то, как мы взаимодействуем с новыми задачами. LLM продемонстрировали замечательную мощь прогнозирования без предварительного обучения с помощью контекстного обучения (ICL). Этот метод позволяет предварительно обученной модели изучать новую задачу, предоставляя примеры и инструкции во входном контексте, без обновления каких-либо базовых весов модели.
Сегодня мы представляем TabFM, базовую модель, разработанную специально для классификации и регрессии табличных данных. Рассматривая прогнозирование табличных данных как задачу ICL (Integrated Data Classification), TabFM устраняет необходимость в ручном обучении модели, настройке гиперпараметров и сложной разработке признаков. Мы рады рассказать, как этот подход позволяет пользователям получать высококачественные прогнозы для ранее не встречавшихся таблиц за один прямой проход. TabFM теперь доступен в наших репозиториях Hugging Face и GitHub.
Как это работает
Традиционная парадигма машинного обучения основана на обновлении параметров модели, специфичных для распределения заданного набора данных. В отличие от неё, парадигма ICL полностью обходит этот подход. Вместо традиционного этапа обучения для каждой новой задачи, TabFM берёт весь набор данных — включающий как исторические обучающие примеры, так и целевые тестовые строки — в качестве единого унифицированного запроса. Модель учится интерпретировать взаимосвязи между столбцами и строками непосредственно из этого контекста во время вывода.
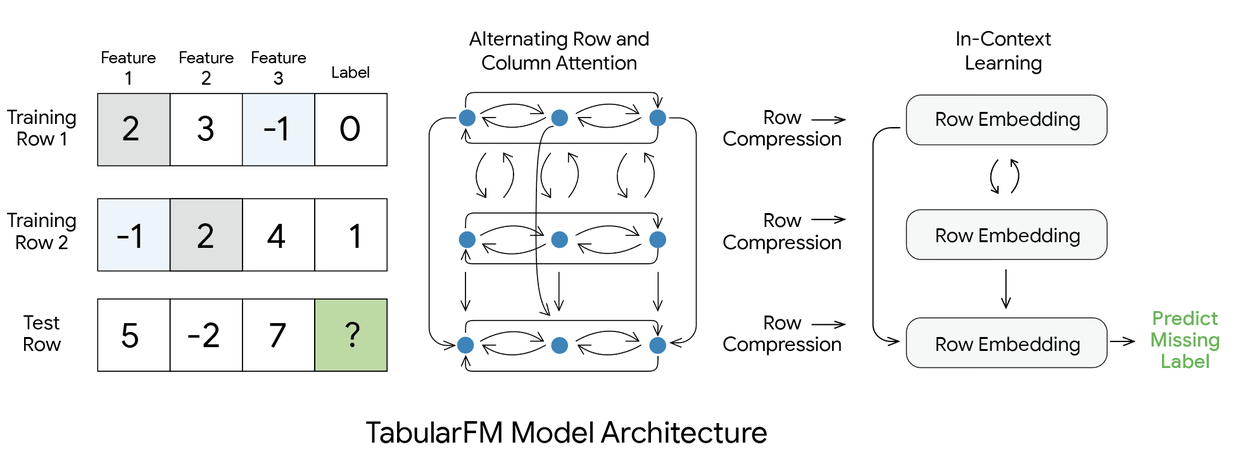
Однако применение ICL к табличным данным не так просто, как токенизация естественного языка. Стандартные языковые модели обрабатывают одномерные упорядоченные последовательности, но таблицы по своей сути двумерны и не имеют порядка: замена двух строк или двух столбцов не меняет основного смысла данных. Для эффективной обработки этих разнообразных табличных структур и обеспечения масштабируемого прогнозирования без предварительного обучения, TabFM объединяет сильные стороны таких архитектур, как TabPFN и TabICL, в новую гибридную конструкцию. Эта архитектура, представленная ниже, основана на трех ключевых механизмах:
- Чередование внимания к строкам и столбцам : Сначала исходная таблица обрабатывается многослойным модулем внимания. Подобно TabPFN, на этом этапе применяется чередование внимания как к столбцам (признакам), так и к строкам (примерам). Непрерывное внимание к этим двум измерениям позволяет модели обучаться созданию богатых представлений, которые изначально отражают сложные взаимодействия и зависимости между признаками. Эта глубокая контекстуализация эффективно выполняет основную работу, которая в противном случае потребовала бы утомительной ручной обработки признаков специалистами по анализу данных.
- Сжатие строк : После такой контекстуализации обширная информация, привлекаемая внимание нескольких пользователей к каждой отдельной строке, сжимается в единое плотное векторное представление.
- Обучение в контексте (ICL) : Наконец, специальный трансформер работает с этой последовательностью сжатых эмбеддингов. Применение высокоэффективного подхода TabICL, осуществляющего механизм внимания над этими сжатыми векторными строками, а не над исходной несжатой сеткой, значительно снижает вычислительные затраты. Это гарантирует высокую вычислительную эффективность этапа прогнозирования даже для гораздо больших наборов данных.
Архитектура модели TabFM.
Обучение на синтетических данных в больших масштабах.
Типичный подход к построению базовых моделей заключается в использовании высокопроизводительной нейронной сети, обученной на огромных массивах разнообразных данных. Однако серьезной проблемой в табличном машинном обучении является критическая нехватка высококачественных, разнообразных табличных наборов данных — особенно массивных таблиц, необходимых для отражения реального анализа промышленных данных, — в пространстве открытого исходного кода. Промышленные таблицы часто содержат проприетарные схемы и конфиденциальную информацию, что делает их недоступными для широкого предварительного обучения.
Поскольку синтетические таблицы могут быть сгенерированы произвольно больших размеров, они фактически являются единственным жизнеспособным вариантом для предварительного обучения базовой модели в таком масштабе. В результате TabFM обучается исключительно на сотнях миллионов синтетических наборов данных. Эти наборы данных генерируются динамически с использованием структурных причинно-следственных моделей (SCM), которые включают в себя широкий спектр случайных функций. Эта масштабная генерация синтетических данных позволяет учесть большое разнообразие распределений и сложные взаимосвязи признаков, характерные для реальных табличных данных. В результате модель хорошо обобщается на ранее не встречавшиеся реальные таблицы, как мы демонстрируем в наших тестах ниже.
Производительность и сравнительный анализ
Для тщательного тестирования TabFM в сравнении с существующими передовыми методами мы оценили его на TabArena, постоянно обновляемой системе бенчмаркинга, которая рассчитывает рейтинг Эло на основе показателей выигрыша в личных встречах. Эта всесторонняя оценка охватывает 38 наборов данных для классификации и 13 наборов данных для регрессии, размер которых варьируется от 700 до 150 000 выборок.
Как показано на графике производительности ниже, мы протестировали две различные конфигурации нашей модели:
- TabFM : Это представляет собой стандартные возможности модели. Прогнозы генерируются за один прямой проход, не требуя настройки или перекрестной проверки.
- TabFM-Ensemble : Эта конфигурация дополнительно повышает производительность за счет использования перекрестных признаков и признаков сингулярного разложения (SVD). Мы вычисляем оптимальные веса для ансамбля из 32 элементов, используя метод наименьших квадратов с неотрицательными значениями. Для задач классификации этот вариант также включает масштабирование Платта в качестве дополнительного этапа калибровки.
Для получения полных результатов сравнительного анализа TabArena, включая подробные метрики по каждому варианту прохождения и показатели выигрыша в сравнении с конкретными базовыми моделями, посетите нашу страницу на GitHub.

Рейтинги ELO (↑) для 10 лучших моделей в классификации TabArena (верхняя строка) и регрессии (нижняя строка). (D) = по умолчанию; (T+E) = настроенная + ансамблевая. Более высокие баллы указывают на превосходную производительность.
Заключение
Переосмысливая табличное прогнозирование как задачу контекстного обучения, TabFM использует гибридную архитектуру внимания и огромные массивы синтетических обучающих данных для непосредственного учета сложных взаимодействий признаков. Этот подход успешно устраняет традиционные узкие места ручной разработки признаков, оптимизации гиперпараметров и многократного обучения модели, и неизменно превосходит тщательно настроенные, стандартные для отрасли алгоритмы обучения с учителем. TabFM переносит удобство современных базовых моделей непосредственно в рабочие процессы табличного машинного обучения, позволяя специалистам получать высокоточные прогнозы за один прямой проход.
Чтобы сделать это доступным, TabFM интегрируется непосредственно в Google BigQuery. В ближайшие недели пользователи смогут выполнять расширенную регрессию и классификацию, используя простую команду SQL AI.PREDICT в BigQuery — без необходимости обладать специальными знаниями в области машинного обучения.
Благодарности
Этот проект — совместная работа с Эрезом Луидором Иланом, Таманом Нараяном, Шусином Ни, Раджатом Сеном, Иченом Чжоу, Джо Тотом, Децином Фу и Саметом Оймаком. Мы благодарим Кимберли Шведе за разработку графического оформления.
Источник: research.google
Оцените материал:
