Skill of the Week: Spring Data JDBC — качество Opus на модели за копейки
Ранее в рубрике Skill of the Week мы уже разбирали Skill для Spring Data JPA. И, что предсказуемо, в комментариях нашлись те, кто увидел в нём лишнее доказательство простого тезиса: «вот видите, JPA не нужна, она слишком сложная». Аргумент понятный — у AI Agent-а с JPA действительно регулярно случаются «пожары»: ошибки в настройке связей между сущностями, странности с конфигурацией базовых типов, путаница с контекстом персистентности и разными состояниями сущности. Что характерно, ровно на этих же местах спотыкаются и живые разработчики — так что претензия скорее к технологии, чем к модели.
Раз JPA такая сложная — почему бы не взять что-нибудь попроще? Чистый JDBC многим кажется слишком низкоуровневым, и взгляд естественным образом падает на Spring Data JDBC: те же репозитории и сущности, но без прокси, lazy loading и кэша первого уровня. Технология проще — значит, и никакой Skill тут не нужен, верно?
А вот и нет. Умение AI «пользоваться» той или иной технологией зависит не столько от её когнитивной сложности, сколько от того, сколько кода с её использованием модель видела на этапе обучения. Spring Data JDBC объективно проще JPA, но кода с ней в открытом доступе на порядки меньше. Парадокс, но именно для технологий «с малым количеством кода» Skill даёт наибольший эффект: он закрывает ровно тот пробел, который модели нечем заполнить самостоятельно.
В сегодняшнем эпизоде еженедельной рубрики Skill of the Week разберёмся, как, используя Spring Data JDBC Skill, научить своего агента важным навыкам при работе со Spring Data JDBC.
Этот Skill входит в состав набора скиллов для Spring-разработчика. Исходный код всех скиллов доступен на GitHub. Рекомендую поставить звёздочку, чтобы не потерять.
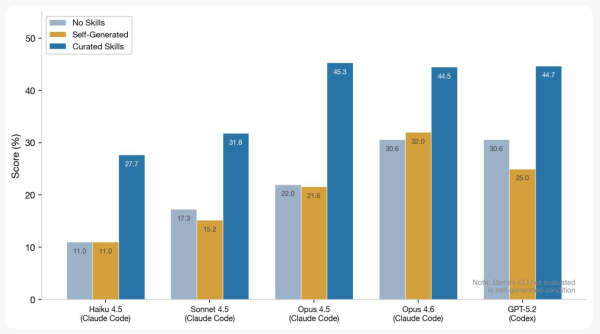
Качество модели в AI-агенте
Открывая очередной пост с описанием того, как улучшить поведение агента, можно обнаружить, как автор, используя Claude Code 20x Max-подписку, не обращая внимания на лимиты и ограничения, настраивает Harness. Однако реальность немного отличается.
Реальное рабочее окружение накладывает свои ограничения. Начиная со стоимости самих подписок, например, работодатель выдает Claude Code на 20$ или же базовую подписку на Cursor, и заканчивая разрешением использовать только те модели, что доступны в контуре организации. Такие ограничения приводят разработчика к необходимости использовать в качестве основных модели среднего класса: Sonnet, Haiku, OpenAI OSS 120b, MiniMax… Я буду использовать Haiku/Sonnet далее в примерах.
Использование Skill, которые улучшают понимание фреймворков для AI-агентов с моделями среднего класса, имеет критически важное значение для получения качественного результата. Такой Skill может легко поднять качество генерации в отдельных задачах с Haiku до Opus.
Spring Data JDBC
Spring Data JDBC Skill решает одну задачу — дать агенту представление о том, как разработка на Spring Data JDBC ведётся на самом деле, а не как её достраивает модель по обрывкам данных. В основе всего лежат базовые понятия DDD, на которых стоит сам фреймворк: что такое агрегат, чем корень агрегата отличается от его владеемого компонента. Skill объясняет агенту, как эти понятия выражаются средствами фреймворка: где сущность входит в состав агрегата, а где соседний агрегат подключается типизированной ссылкой. Из тех же понятий выводятся и связи (one-to-one, one-to-many, many-to-one, many-to-many): важен не только способ их описать, но и направление — связь должна быть устроена так, чтобы не нарушать границу чужого агрегата. Сюда же относятся репозитории, которые создаются только для корня агрегата, проекции, кастомные запросы и прочее.
Уникальностью данного Skill является тот факт, что он учитывает особенности/соглашения при работе с JDBC именно в вашем/текущем проекте (естественно, если это в явном виде не порождает ошибки). Делает он это, выполняя анализ в несколько шагов. Данный анализ может быть сохранен в память проекта; как результат, повторный вызов Skill пропустит этот шаг.
Как установить
Установить Spring Skills глобально во все обнаруженные агенты:
npx skills add Amplicode/spring-skills -g
Установить только для конкретных агентов (пример — Claude Code + Codex + Gemini CLI):
npx skills add Amplicode/spring-skills -g -a claude-code -a codex -a gemini-cli
С более подробной инструкцией можно ознакомиться тут.
Явная/ручная активация
Для начала разберемся, как воспользоваться Skill в ручном режиме. Необходимо это в ситуации, когда вы, например, занимаетесь моделированием доменной области, проектируя агрегаты и их корни.
В идеальном мире агент должен из контекста задачи понять, что необходимо выполнить активацию Skill, и выполнить ее. К сожалению, это не всегда так, особенно на моделях среднего класса, поэтому приходится указывать активацию непосредственно в чате или, например, в плане, если вы используете режим планирования.
В качестве примера сгенерируем чистый Spring Boot-проект, используя start.spring.io и добавив в него только два модуля: Spring Data JDBC. Далее попросим Claude Code с Haiku создать сущности ветеринара, домашнего животного и визита. Укажем, что домашнее животное является частью агрегата владелец, а визит является независимым рутом.
Как видно на видео, несмотря на использование Haiku, агент справился с задачей: создал агрегат Owner с владеемым Pet и независимый рут Visit. Важнее то, что произошло со связью Visit → Pet. Pet — не корень, а внутренний компонент агрегата Owner, и прямая ссылка на него нарушает границу агрегата. Агент это распознал по ходу работы и применил workaround — сохранил связь обычным полем-идентификатором вместо объектной ссылки. Решение компромиссное, но показательное: модель среднего класса не просто выполнила постановку дословно, а сама поймала нарушение DDD, которое без Skill почти наверняка осталось бы незамеченным.
Поле-идентификатор закрывает проблему формально, но с точки зрения DDD это всё ещё компромисс: связь между Visit и внутренним компонентом чужого агрегата никуда не делась, она лишь перестала быть объектной ссылкой. Напрашивается «простой» выход — затащить Visit внутрь агрегата Owner, сделав визиты владеемой коллекцией Pet. Но это ровно то, чего мы не хотим: Visit — самостоятельная сущность со своим жизненным циклом, его создают и запрашивают отдельно от владельца, и прятать его внутрь чужого агрегата значит раздувать границы и терять независимый рут. Правильное решение — перевернуть связь и хранить ссылку на стороне Pet: не Visit указывает на внутренний Pet, а Pet держит ссылку на Visit. Разница принципиальна: Visit — полноценный корень агрегата, и ссылаться на него можно, тогда как ссылка на внутренний Pet границу нарушала. Visit при этом остаётся независимым рутом, а агрегат Owner — нетронутым. Попросим агента перестроить связь именно так.
Как видно на видео, агент не пошёл по наивному пути и не повесил на Pet коллекцию AggregateReference напрямую — в Spring Data JDBC так нельзя, коллекция ссылок на другой агрегат фреймворком не поддерживается. Вместо этого он завёл отдельную владеемую сущность-связку PetVisitRef: каждый её экземпляр хранит ровно одну ссылку на Visit, а сама коллекция таких связок лежит внутри Pet. Это и есть канонический для Spring Data JDBC способ выразить «у Pet много визитов», не нарушая границ агрегатов.
Почему skill не делает так по умолчанию? По той же причине, по которой этого часто не делает и живой разработчик: в большинстве случаев проще пожертвовать концептуальной чистотой ради простоты — поставить прямую ссылку или сырой внешний ключ и не думать о границах.
Обратите внимание: всё это мы делали на Haiku — по сути, на нижней планке практически применимых моделей. И в этом весь смысл: если Skill вытягивает на нужный уровень даже её, то Sonnet, OpenAI OSS 120b, MiniMax и прочие модели среднего класса получат как минимум не меньший профит.
Использование в плане
Если вы разрабатываете, предварительно запуская режим планирования, то вы замечали, что агент не особо активирует Skill-ы в процессе выполнения плана. Мотивировать агента использовать Skill можно, указав его в плане явным образом. Для этого достаточно в начале шага плана указать на использование конкретного Skill.
**JDBC skill required (`amplicode-spring-skills:spring-data-jdbc`).** Before writing any entity code: activate the skill and verify the implementation against its rules (`references/entity-rules-impl.md`, `references/aggregate-rules-impl.md`). For any deviation — ask the developer before continuing.
Вот как это выглядит в конечном плане:

Явное указание на активацию Spring Data JDBC Skill в шаге плана
Если теперь попросить агента приступить к реализации плана, то он активирует его с высокой вероятностью.
Использование в других Skill
Постепенно, развивая собственный harness и добавляя новые скиллы, мы видим, как в наших коллекциях появляются скиллы, которые уже не просто отдельные действия, а являются полноценными сценариями, включающими создание сущностей, генерацию кода сервисов, описание новых endpoint и т.д. В такого рода Skill полезно использовать другие Skill, которые как раз помогают качественно выполнять отдельные специализированные шаги.
Ранее, рассматривая Spring Data JPA Skill, мы писали Skill, который при добавлении сущности сразу создаёт REST Endpoint и Service для получения элементов сущности по Id. Давайте адаптируем его для Spring Data JDBC.
— name: entity-service-rest description: > Scaffolds a full vertical slice for one domain entity in three steps: the Spring Data JDBC entity, a Spring service for it, and a REST controller with a find-by-id endpoint. The controller calls the repository ONLY through the service (controller → service → repository), never directly. Use this skill when the user asks to create an entity together with its service and controller, to build a feature/vertical slice around an entity, or to add an entity plus a service plus a REST endpoint that looks up by id — even when the skill is not named explicitly. — ## Step 1 — Entity Determine the entity name (and any fields) from the user’s prompt; infer reasonable defaults for anything not specified — do not ask. **Activate the `spring-data-jdbc` skill** and use it to create the Spring Data JDBC entity. Let it own the project’s entity conventions (`@Table`/`@Id`/`@Column` from `spring-data-relational`, `AggregateReference` links, `@MappedCollection` associations, `@PersistenceCreator`, etc.). If the entity already exists, this step just confirms it. Also make sure a Spring Data repository exists for the entity (e.g. `{Entity}Repository extends CrudRepository<{Entity}, {IdType}>`, or `ListCrudRepository` when list-returning finders are preferred). If none exists, create one following the same skill’s repository guidance. ## Step 2 — Service The service returns a DTO, so first make sure a DTO and an entity↔DTO mapper exist: **Activate the `dto-creator` skill**, telling it the DTO is **for a service / REST controller**. That skill creates the DTO and automatically delegates to `mapper-creator` for the mapper. Reuse an existing DTO/mapper if the project already has one. The mapper **must be a MapStruct mapper** — pass this to `dto-creator` / `mapper-creator` so the mapper type is MapStruct (not a custom converter). If `mapper-creator` needs MapStruct dependencies added to the build file, let it add them. Then create a `@Service` that injects the **repository** and the **mapper**, with a `findById(id)` method that calls `repository.findById(id)` and returns the entity mapped to the DTO. ## Step 3 — REST controller Create the controller: — annotate it `@RestController` with a request mapping like `/rest/{entities}` — inject **the service only** — never the repository — add `GET /{id}` that calls `service.findById(id)`, returns the DTO with 200, or 404 when absent — ## Done Before finishing, double-check the core invariant: the controller goes through the service, and only the service touches the repository.
Проверим его работу на практике. Решим ранее озвученную задачу с ветеринарами, домашними животными и визитами. Вызовем агента с той же формулировкой, но теперь будем использовать вновь созданный нами Skill. В этот раз будем использовать модель Sonnet 4.6.
Как видно на видео, в результате работы Agent с нашим новым Skill мы получили все ожидаемые компоненты: Entity, Service, RestController, Repository и связывающий их воедино код. Обратите внимание, что Agent не создал rest endpoint для pet — видимо, таким образом он трактовал понятие агрегата. Поправить это оставим читателю в качестве домашнего задания.
Если тебе интересно, как настроить свой Agent для разработки на Spring, а также ты не хочешь пропустить новые выпуски Skill of the Week и другие полезные материалы по разработке на Spring с AI Agent — подписывайся на наш канал в ТГК.
А больше полезных Skill для разработки на Spring/Spring Boot можно найти в нашем репозитории (звездочки приветствуются).
Предыдущий выпуск Skill of the Week: Spring Data JPA. Никто не знает JPA, даже AI

Источник: habr.com
Оцените материал:
