TurboQuant: переосмысление эффективности ИИ с помощью экстремального сжатия.
Мы представляем набор передовых, теоретически обоснованных алгоритмов квантования, которые позволяют осуществлять масштабное сжатие больших языковых моделей и векторных поисковых систем.
Быстрые ссылки
- TurboQuant
- Квантованный Джонсон-Линденштраус
- PolarQuant
- Делиться
Векторы — это основной способ, с помощью которого модели искусственного интеллекта понимают и обрабатывают информацию. Небольшие векторы описывают простые атрибуты, такие как точка на графике, в то время как «многомерные» векторы отражают сложную информацию, такую как характеристики изображения, значение слова или свойства набора данных. Многомерные векторы невероятно мощны, но они также потребляют огромные объемы памяти, что приводит к узким местам в кэше типа «ключ-значение» — высокоскоростной «цифровой шпаргалке», которая хранит часто используемую информацию под простыми метками, чтобы компьютер мог мгновенно ее получить, не прибегая к поиску в медленной и громоздкой базе данных.
Векторное квантование — это мощный классический метод сжатия данных, уменьшающий размер многомерных векторов. Эта оптимизация решает две критически важные задачи ИИ: она улучшает векторный поиск, высокоскоростную технологию, лежащую в основе крупномасштабных систем ИИ и поисковых систем, за счет ускорения поиска сходства; и помогает разгрузить узкие места кэша «ключ-значение», уменьшая размер пар «ключ-значение», что ускоряет поиск сходства и снижает затраты памяти. Однако традиционное векторное квантование обычно вносит свои собственные «накладные расходы на память», поскольку большинство методов требуют вычисления и хранения (с полной точностью) констант квантования для каждого небольшого блока данных. Эти накладные расходы могут добавлять 1 или 2 дополнительных бита на число, частично сводя на нет цель векторного квантования.
Сегодня мы представляем TurboQuant (который будет представлен на ICLR 2026), алгоритм сжатия, оптимально решающий проблему избыточных затрат памяти при векторном квантовании. Мы также представляем квантованный алгоритм Джонсона-Линденштрауса (QJL) и PolarQuant (который будет представлен на AISTATS 2026), используемые TurboQuant для достижения своих результатов. В ходе тестирования все три метода показали большие перспективы в снижении «узких мест» в сегменте «ключ-значение» без ущерба для производительности моделей ИИ. Это может иметь серьезные последствия для всех сценариев использования, требующих сжатия, включая и особенно области поиска и ИИ.
Как работает TurboQuant
TurboQuant — это метод сжатия, обеспечивающий значительное уменьшение размера модели без потери точности, что делает его идеальным для поддержки как сжатия кэша типа «ключ-значение» (KV), так и векторного поиска. Это достигается двумя ключевыми шагами:
- Высококачественное сжатие (метод PolarQuant) : TurboQuant начинает с произвольного вращения векторов данных. Этот продуманный шаг упрощает геометрию данных, что позволяет легко применять стандартный высококачественный квантизатор (инструмент, который отображает большой набор непрерывных значений, таких как точные десятичные дроби, на меньший дискретный набор символов или чисел, таких как целые числа: примерами являются квантизация звука и сжатие JPEG) к каждой части вектора по отдельности. На этом первом этапе используется большая часть мощности сжатия (большинство битов) для сохранения основной концепции и силы исходного вектора.
- Устранение скрытых ошибок : TurboQuant использует небольшое остаточное количество мощности сжатия (всего 1 бит) для применения алгоритма QJL к крошечной ошибке, оставшейся после первого этапа. Этап QJL действует как математический инструмент проверки ошибок, устраняющий предвзятость, что приводит к более точной оценке внимания.
Чтобы полностью понять, как TurboQuant достигает такой эффективности, мы более подробно рассмотрим, как работают алгоритмы QJL и PolarQuant.
QJL: Трюк с нулевыми накладными расходами и 1 битом
QJL использует математический метод, называемый преобразованием Джонсона-Линденштрауса, для уменьшения размера сложных многомерных данных при сохранении существенных расстояний и взаимосвязей между точками данных. Он сводит каждое результирующее число вектора к одному знаковому биту (+1 или -1). Этот алгоритм, по сути, создает высокоскоростную сокращенную запись, не требующую дополнительных затрат памяти. Для поддержания точности QJL использует специальный оценщик, который стратегически балансирует запрос с высокой точностью с упрощенными данными с низкой точностью. Это позволяет модели точно вычислять показатель внимания (процесс, используемый для определения того, какие части входных данных важны, а какие можно безопасно игнорировать).
PolarQuant: новый «подход» к сжатию данных.
PolarQuant решает проблему избыточного использования памяти, используя совершенно иной подход. Вместо того чтобы рассматривать вектор памяти с использованием стандартных координат (например, X, Y, Z), указывающих расстояние вдоль каждой оси, PolarQuant преобразует вектор в полярные координаты, используя декартову систему координат. Это сравнимо с заменой фразы «Пройти 3 блока на восток, 4 блока на север» на «Пройти всего 5 блоков под углом 37 градусов». В результате получаются два параметра: радиус, который показывает, насколько сильны основные данные, и угол, указывающий направление или значение данных. Поскольку закономерность углов известна и сильно сконцентрирована, модели больше не нужно выполнять дорогостоящий этап нормализации данных, так как она отображает данные на фиксированную, предсказуемую «круговую» сетку, границы которой уже известны, а не на «квадратную» сетку, границы которой постоянно меняются. Это позволяет PolarQuant устранить избыточное использование памяти, характерное для традиционных методов.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
PolarQuant выступает в качестве высокоэффективного моста сжатия, преобразуя декартовы входные данные в компактную полярную «сокращенную запись» для хранения и обработки. Механизм начинается с группировки пар координат из d-мерного вектора и отображения их в полярную систему координат. Затем радиусы объединяются в пары для рекурсивных полярных преобразований — процесс, который повторяется до тех пор, пока данные не будут сведены к одному конечному радиусу и набору описывающих углов.
Эксперименты и результаты
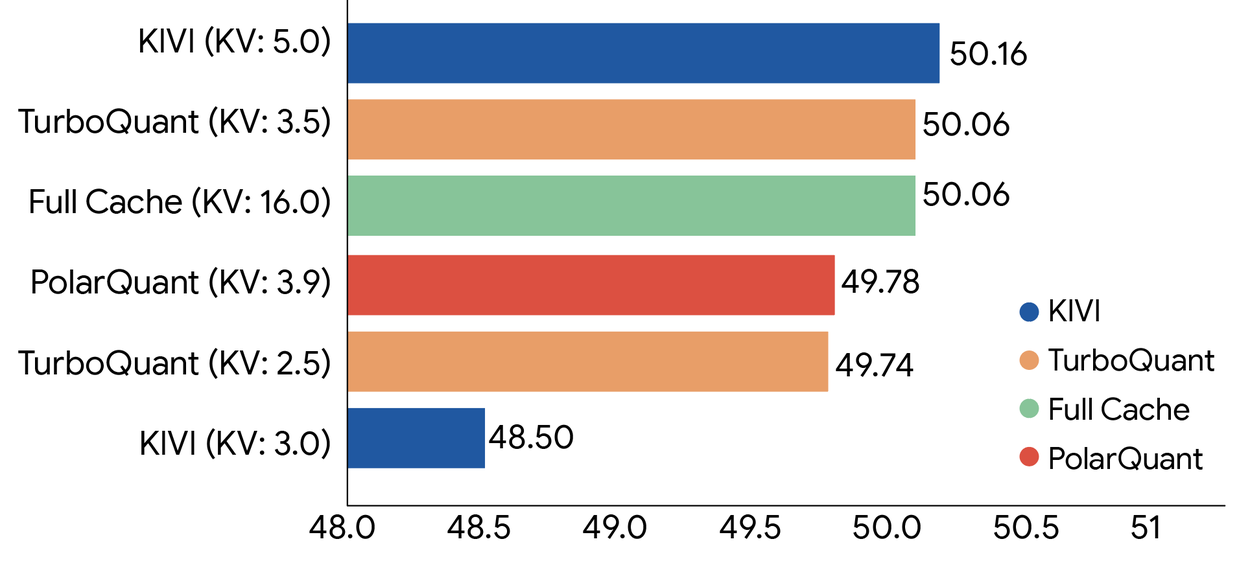
Мы провели тщательную оценку всех трех алгоритмов на стандартных тестах с длинным контекстом, включая LongBench, Needle In A Haystack, ZeroSCROLLS, RULER и L-Eval, используя открытые LLM-системы (Gemma и Mistral). Экспериментальные данные показывают, что TurboQuant достигает оптимальной производительности с точки зрения искажения скалярного произведения и полноты, одновременно минимизируя объем памяти, занимаемый ключом-значением (KV). На диаграмме ниже показаны суммарные показатели производительности по различным задачам, включая ответы на вопросы, генерацию кода и суммирование, для TurboQuant, PolarQuant и базовой модели KIVI.

TurboQuant демонстрирует высокую эффективность сжатия KV-кэша в бенчмарке LongBench при использовании различных методов сжатия на модели Llama-3.1-8B-Instruct (битовая ширина указана в скобках).
Результаты для задач поиска «иголки в стоге сена» с длинным контекстом (то есть тестов, предназначенных для проверки способности модели найти один конкретный, крошечный фрагмент информации, скрытый в огромном объеме текста) показаны ниже. И снова TurboQuant демонстрирует идеальные результаты во всех тестах, при этом уменьшая размер памяти для ключевых значений как минимум в 6 раз. PolarQuant также практически не теряет данные при решении этой задачи.
TurboQuant доказал свою способность квантовать кэш ключ-значение всего до 3 бит без необходимости обучения или тонкой настройки и без ущерба для точности модели, при этом обеспечивая более быстрое время выполнения, чем оригинальные LLM (Gemma и Mistral). Он исключительно эффективен в реализации и влечет за собой незначительные накладные расходы во время выполнения. Следующий график иллюстрирует ускорение вычисления логитов внимания с использованием TurboQuant: в частности, 4-битный TurboQuant обеспечивает до 8-кратного увеличения производительности по сравнению с 32-битными неквантованными ключами на графических ускорителях H100.
TurboQuant демонстрирует существенное повышение производительности при вычислении логитов внимания в кэше типа «ключ-значение» на различных уровнях разрядности, измеренное относительно высокооптимизированного базового алгоритма JAX .
Это делает его идеальным для поддержки таких сценариев использования, как векторный поиск, где он значительно ускоряет процесс построения индекса. Мы оценили эффективность TurboQuant в многомерном векторном поиске по сравнению с передовыми методами (PQ и RabbiQ), используя коэффициент полноты 1@k, который измеряет, как часто алгоритм находит истинный результат скалярного произведения среди своих k лучших приближений. TurboQuant неизменно демонстрирует более высокие коэффициенты полноты по сравнению с базовыми методами, несмотря на то, что эти базовые методы используют неэффективные большие кодовые книги и настройку, специфичную для набора данных (рисунок ниже). Это подтверждает надежность и эффективность TurboQuant для задач многомерного поиска.
TurboQuant демонстрирует высокую эффективность поиска, достигая оптимального коэффициента полноты 1@k на наборе данных GloVe (d=200) по сравнению с различными современными базовыми методами квантования .
TurboQuant демонстрирует революционный сдвиг в поиске в многомерном пространстве. Установив новый эталон достижимой скорости, он обеспечивает почти оптимальные показатели искажения, не зависящие от объема данных. Это позволяет нашим алгоритмам поиска ближайших соседей работать с эффективностью 3-битной системы, сохраняя при этом точность гораздо более ресурсоемких моделей. Подробнее см. в статье.
Взгляд в будущее
TurboQuant, QJL и PolarQuant — это не просто практические инженерные решения; это фундаментальные алгоритмические разработки, подкрепленные убедительными теоретическими доказательствами. Эти методы не просто хорошо работают в реальных приложениях; они доказано эффективны и работают вблизи теоретических нижних пределов. Именно эта строгая основа делает их надежными и заслуживающими доверия для критически важных крупномасштабных систем.
Хотя одним из основных применений является решение проблемы узкого места кэширования типа «ключ-значение» в таких моделях, как Gemini, влияние эффективного онлайн-квантования векторов простирается еще дальше. Например, современный поиск выходит за рамки простого поиска по ключевым словам и начинает понимать намерения и смысл. Это требует векторного поиска — способности находить «ближайшие» или наиболее семантически похожие элементы в базе данных, содержащей миллиарды векторов.
Для решения этой задачи крайне важны такие методы, как TurboQuant. Они позволяют создавать и запрашивать большие векторные индексы с минимальным объемом памяти, практически нулевым временем предварительной обработки и высочайшей точностью. Это делает семантический поиск в масштабах Google быстрее и эффективнее. По мере того, как ИИ все больше интегрируется во все продукты, от LLM до семантического поиска, работа над фундаментальными методами векторного квантования станет более важной, чем когда-либо.
Благодарности
Данное направление исследований проводилось в сотрудничестве с Пранитом Качамом, научным сотрудником Google; Маджидом Хадианом, ведущим инженером Google DeepMind; Инсу Ханом, доцентом KAIST; Маджидом Далири, аспирантом Нью-Йоркского университета; Ларсом Готтесбюреном, научным сотрудником Google; и Раджешем Джаярамом, научным сотрудником Google.
Источник: research.google
Оцените материал:
