Развертывание многоступенчатой многомодальной рекомендательной системы на Amazon Elastic Kubernetes Service.
Включает в себя фильтры Блума, кэширование признаков, контекстное ранжирование и сквозной конвейер от подготовки данных до развертывания модели.
Делиться

Создание многоступенчатой, многомодальной рекомендательной системы для промышленного применения — задача нетривиальная, особенно когда необходимо обеспечить масштабируемость, адаптацию практически в реальном времени и надежную работу в облаке.
В этом посте я подробно расскажу о своем опыте проектирования и развертывания подобной системы от начала до конца, включая подготовку данных, обучение модели и запуск моделей в производственной среде.
Мы рассмотрим весь конвейер обработки данных, включая поиск, фильтрацию, оценку и ранжирование, а также инфраструктуру и важные решения, обеспечивающие его работу. Это включает в себя хранилища признаков, фильтры Блума, Kubeflow, адаптацию предпочтений практически в реальном времени и значительное снижение задержки благодаря кэшированию признаков в оперативной памяти.
Это довольно объемная статья, но если вы занимаетесь разработкой или масштабированием рекомендательных систем, вы найдете здесь практические примеры, которые сможете напрямую применить в своих проектах.
Основные разделы этого поста
- Некоторая информация о системе.
- Почему был выбран именно этот дизайн?
- Компоненты системы
- Источник данных
- Полный цикл обучения и внедрения.
- Конвейер непрерывной тонкой настройки
- Обработка запросов через 14 моделей на сервере NVIDIA Triton Inference.
- Снижение задержки поиска характеристик элементов за счет кэширования в оперативной памяти.
- Автоматическое масштабирование сервера Triton Inference Server на EKS
- Проверка контекстных рекомендаций, фильтрация по фильтру Блума и обновление рекомендаций практически в режиме реального времени (с демонстрацией).
- Ограничения и дальнейшая работа
- Заключение
- Ресурсы
Некоторая информация о системе.
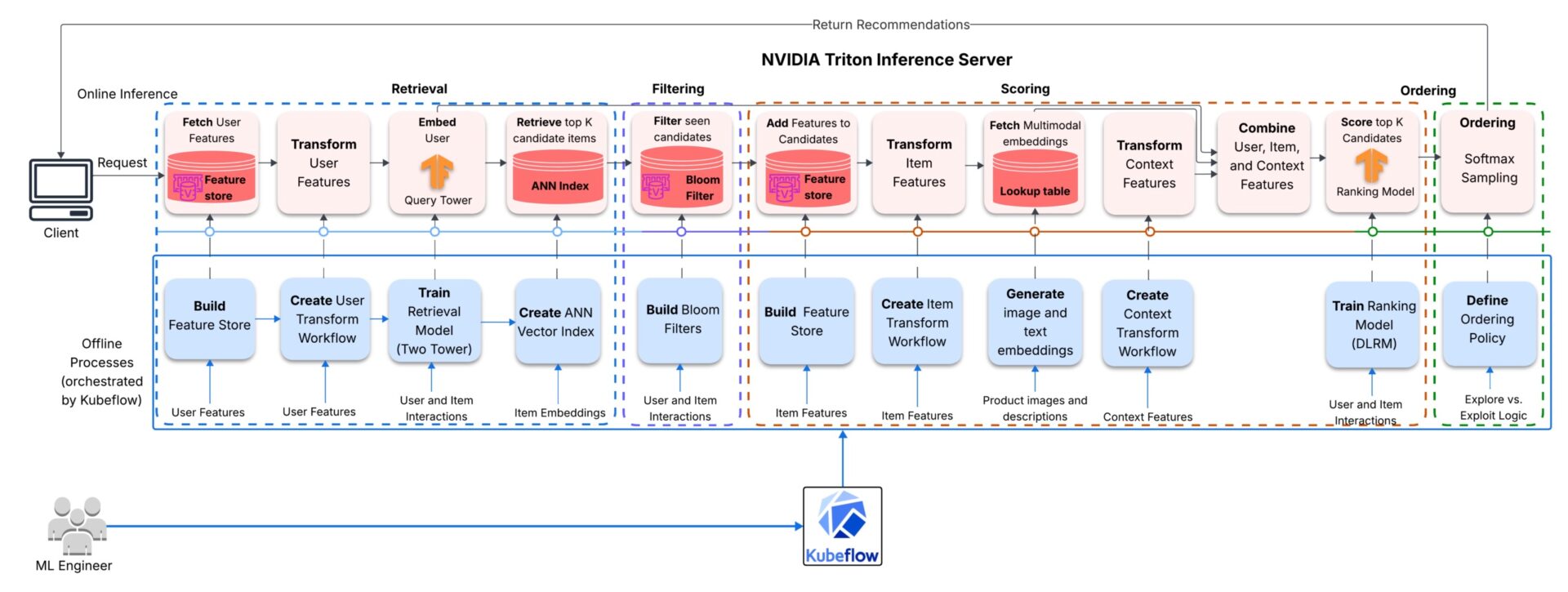
Система рекомендаций состоит из четырех основных этапов: модель «Двух башен» генерирует кандидатов, фильтр Блума временно скрывает элементы, с которыми пользователь недавно взаимодействовал, ранжировщик DLRM оценивает оставшиеся элементы, используя характеристики пользователя, элемента и контекста, и заключительный этап переранжирования упорядочивает и отбирает образцы на основе этих оценок для получения окончательных рекомендаций. Модели используют как табличные коллаборативные признаки, так и предварительно вычисленные векторные представления изображений CLIP и текстовые векторные представления Sentence-BERT.
В модели поиска эти предварительно обученные эмбеддинги подаются в башню кандидатов вместе с изученными признаками элементов, предоставляя башне кандидатов как семантические сигналы, основанные на содержании, так и сигналы взаимодействия. Скалярное произведение выходных данных башни запроса и башни кандидатов затем используется в качестве изученного показателя релевантности в этом общем пространстве эмбеддингов.
В алгоритме ранжирования DLRM предварительно обученные векторные представления изображений и текста участвуют в слое взаимодействия скалярного произведения. Затем эти парные взаимодействия передаются в верхний многослойный перцептрон (MLP), что позволяет сигналам, основанным на содержании, из предварительно обученных векторных представлений дополнять сигналы взаимодействия и контекстные сигналы, используемые для прогнозирования кликов.
Почему был выбран именно этот дизайн?
Целевой сценарий использования — платформа электронной коммерции, которой необходимо рекомендовать релевантные товары сразу после того, как пользователи попадают на главную страницу. Платформа обслуживает как зарегистрированных пользователей, так и анонимных посетителей, и поведение пользователей может существенно различаться в зависимости от контекста запроса, например, типа устройства, времени суток или дня недели. Это означает, что сервис рекомендаций должен предоставлять разумные рекомендации для новых пользователей и адаптировать их к контексту текущего запроса.
Решение также должно быть масштабируемым. По мере подключения новых ритейлеров каталог товаров может вырасти до миллионов позиций. В этот момент оценивать весь каталог при каждом запросе становится нецелесообразно. Многоэтапная архитектура решает эту проблему, используя облегченный этап поиска для быстрого получения кандидатов и более сложный этап ранжирования для оценки этих кандидатов.
Кроме того, модели рекомендаций должны постоянно обновляться с учетом новых взаимодействий, однако перестраивать весь стек поиска каждый день нецелесообразно. По этой причине определены два конвейера Kubeflow. Первый конвейер настраивает рабочие процессы предварительной обработки, обучает модели с нуля, создает индекс ANN и развертывает сервер Triton и модели. Второй конвейер управляет ежедневной тонкой настройкой, которая в основном обновляет башню запросов и ранжировщик; модели обновляются с учетом новых сигналов взаимодействия, но векторные представления элементов не перегенерируются.
Компоненты системы
Все компоненты системы работают совместно, чтобы обеспечить достижение общей цели — быстрое и в разумных масштабах предоставление актуальных рекомендаций.
- Kubeflow Pipelines управляет как полным процессом обучения, так и процессом ежедневной тонкой настройки в системе на базе Kubernetes.
- Стек NVIDIA Merlin обеспечивает ускоренную на графическом процессоре обработку признаков, предварительную обработку, поиск обучающих данных и ранжирование моделей. Сервер Triton Inference размещает многоэтапный граф обслуживания в виде единой ансамблевой модели.
- FAISS служит приблизительным индексом ближайших соседей для поиска кандидатов.
- Feast управляет признаками пользователей и элементов на этапах обучения и показа. ElastiCache для Valkey (Redis) обеспечивает работу онлайн-хранилища признаков, управляет фильтром Блума для каждого пользователя, позволяя фильтровать уже просмотренные элементы из списка рекомендаций пользователя, и хранит глобальную и категорийную информацию о популярности элементов на основе количества взаимодействий. Amazon Athena (с S3 и Glue ) обеспечивает работу офлайн-хранилища признаков.
- Amazon Elastic Kubernetes Service (EKS) запускает контейнеризированные рабочие процессы машинного обучения и масштабирует вычислительные ресурсы для удовлетворения меняющихся потребностей рабочей нагрузки.
Источник данных
Данные для обучения получены из модифицированной версии генератора взаимодействий AWS Retail Demo Store. Количество пользователей было уменьшено до 300 000 , а каталог товаров остался неизменным — 2465 позиций, включая изображения и описания. Набор данных содержит 13 миллионов взаимодействий за 14 дней, хранящихся в виде ежедневно разделенных файлов Parquet (day_00.parquet — day_13.parquet).
Полный цикл обучения и внедрения.
Первый конвейер Kubeflow выполняет первоначальное копирование данных, предварительную обработку данных, обучение модели, индексирование FAISS и развертывание сервера вывода Triton.
Копия данных
Процесс начинается с копирования всех входных данных, необходимых для последующих задач, из хранилища S3 в постоянный том, смонтированный по локальному пути. К ним относятся данные о взаимодействиях, таблицы характеристик, изображения продуктов, предварительно обученные модели CLIP и Sentence-BERT.
Предварительная обработка
На этапе предварительной обработки данные о взаимодействии объединяются с таблицами характеристик пользователей и элементов, затем определяются и подгоняются три рабочих процесса NVTabular: один для характеристик пользователей [перейти к CODE], один для характеристик элементов [перейти к CODE] и один для характеристик контекста [перейти к CODE]. Также происходит компиляция подграфов в полный рабочий процесс. Разделение рабочих процессов упростило создание отдельных моделей Triton для преобразования характеристик, которые могут обновляться независимо друг от друга.
Ещё один этап предварительной обработки имитирует условия холодного старта (см. фрагмент кода ниже) во время обучения. В 5% строк обучающей выборки идентификатор пользователя, пол и признаки top_category заменяются контрольными значениями, после чего выполняется отдельное случайное маскирование 5% значений типа устройства. Преобразование с помощью рабочих процессов NVTabular сопоставляет контрольные значения с индексом, отсутствующим в словаре (OOV).
#MASK some users and context features in train data with 5% probability ANONYMOUS_USER = -1 OOV_GENDER = -1 OOV_TOP_CATEGORY = -1 OOV_DEVICE = -1 masked_train_dir = os.path.join(input_path, "masked_train") os.makedirs(masked_train_dir, exist_ok=True) for i in range(train_days): day = cudf.read_parquet(os.path.join(input_path, f"train_day_{i:02d}.parquet")) n=len(day) user_mask = cupy.random.random(n) < 0.05 day.loc[user_mask, "user_id"] = ANONYMOUS_USER day.loc[user_mask, "gender"] = OOV_GENDER day.loc[user_mask, "top_category"] = OOV_TOP_CATEGORY device_mask = cupy.random.random(n) < 0.05 day.loc[device_mask, "device_type"] = OOV_DEVICE day.to_parquet(os.path.join(masked_train_dir, f"train_day_{i:02d}.parquet"), index=False) del day gc.collect() masked_train_paths = [os.path.join(masked_train_dir, f"train_day_{i:02d}.parquet") for i in range(train_days)] masked_train_ds = Dataset(masked_train_paths) full_workflow.transform(masked_train_ds).to_parquet(os.path.join(output_path, "train")) full_workflow.transform(valid_raw).to_parquet(os.path.join(output_path, "valid"))
Для получения мультимодальных характеристик товаров изображения продуктов кодируются с помощью OpenAI CLIP, а описания товаров — с помощью Sentence-BERT. Оба эмбеддинга сводятся к 64-мерным векторам с помощью PCA и сохраняются в виде таблиц поиска, ключами которых являются преобразованные в NVTabular идентификаторы товаров. Средний возраст, вычисленный в процессе работы пользователя, сохраняется для последующего внедрения в конфигурацию модели feast_user_lookup. На следующем этапе подготавливаются артефакты характеристик для офлайн- и онлайн-среды. На этом этапе к характеристикам пользователя и товара добавляются временные метки, полученные характеристики записываются в офлайн-хранилище, а затем материализуются в онлайн-хранилище для предоставления. Одновременно с этим, глобальная и специфичная для категорий информация о популярности вычисляется на основе данных о взаимодействии и записывается в базу данных Valkey (db=3).
Обучение модели поиска
Модель Two-Tower [перейти к CODE ] обучается только на признаках пользователя и товара, с использованием отрицательных значений в пакете и контрастной функции потерь. Башня запросов обрабатывает признаки пользователя, а башня кандидатов — признаки товара вместе с предварительно вычисленными векторными представлениями изображения и текста. См. рисунки 5 и 6 для получения информации о предварительной обработке NVTabular и этапах обработки входных блоков для каждой башни.
Для обучения используются данные о взаимодействиях за первые 9 дней; для оценки — данные за дни с 10 по 12. После обучения кодировщик-кандидат обрабатывает весь каталог элементов для вычисления векторных представлений элементов. Для этого пользовательский оператор LookupEmbeddings (основанный на BaseOperator из библиотеки Merlin) обрабатывает поиск многомодальных векторных представлений при пакетной загрузке признаков элементов с помощью загрузчика данных Merlin. Эти векторные представления элементов используются для построения индекса FAISS для приблизительного поиска ближайших соседей. Кодировщик запросов сохраняется отдельно для онлайн-вывода.
Обучение модели ранжирования
Ранжировщик DLRM [перейти к коду ] обучен на тех же данных о взаимодействии, но с расширенным набором признаков. Набор признаков включает в себя признаки товара, признаки пользователя, признаки контекста запроса (такие как тип устройства и циклические признаки времени суток и дня недели). Целью обучения является бинарная метка клика. Эти контекстные признаки представляют собой ситуационные факторы, которые могут влиять на выбор клиента. Например, пользователь может больше взаимодействовать с определенными товарами при просмотре на телефоне, чем на компьютере, или демонстрировать разные предпочтения в зависимости от времени суток или дня недели.
Подготовка и развертывание модели
После обучения обеих моделей конвейер собирает необходимые для Triton артефакты обслуживания. К ним относятся сохраненная структура запросов, ранжировщик DLRM, модели преобразования NVTabular, индекс FAISS и таблицы поиска для мультимодальных векторных представлений элементов. Репозиторий моделей Triton структурирован заранее, поэтому для каждого развертывания достаточно скопировать артефакты модели в свой каталог с указанием версии и внедрить в файлы конфигурации модели значения, такие как средний возраст пользователя (для холодного запуска по умолчанию), topK для поиска, topK для ранжирования и режим разнообразия.
Helm-диаграмма развертывает Triton Inference Server на EKS, запускает сервер в явном режиме, а затем загружает все модели (см. скрипт запуска).
#Triton starting script set -e MODELS_DIR=${1:-"/model/triton_model_repository"} echo "Starting Triton Inference Server" echo "Models directory: $MODELS_DIR" tritonserver --model-repository="$MODELS_DIR" --model-control-mode=explicit --load-model=nvt_user_transform --load-model=nvt_item_transform --load-model=nvt_context_transform --load-model=multimodal_embedding_lookup --load-model=query_tower --load-model=faiss_retrieval --load-model=dlrm_ranking --load-model=item_id_decoder --load-model=feast_user_lookup --load-model=feast_item_lookup --load-model=filter_seen_items --load-model=softmax_sampling --load-model=context_preprocessor --load-model=unroll_features --load-model=ensemble_model
Конвейер непрерывной тонкой настройки
Этот конвейер Kubeflow обрабатывает ежедневные обновления модели. Конвейер использует некоторые артефакты, созданные в ходе полного процесса обучения, поэтому его компоненты монтируют один и тот же постоянный том, содержащий сохраненные артефакты.
Копирование инкрементальных данных
В начале этого этапа конвейер копирует последние данные о взаимодействиях из Amazon S3 вместе с меньшим набором воспроизведенных более старых взаимодействий. Часть, отвечающая за воспроизведение, обеспечивает более широкий контекст поведения для задачи тонкой настройки и предотвращает переобучение моделей только на основе новейших шаблонов.
Предварительная обработка данных
На этом этапе исторические характеристики пользователей и элементов объединяются с новыми данными о взаимодействиях, а затем данные преобразуются с использованием подобранных рабочих процессов NVTabular из недавнего полного обучающего задания.
Тонкая настройка моделей
Этот шаг обновляет структуру запросов и ранжировщик. Он инициализирует модель Two-Tower из предыдущей контрольной точки, но с замороженным кодировщиком кандидатов, так что обучаемыми становятся только параметры структуры запросов. Это позволяет модели адаптироваться к недавнему поведению пользователя, сохраняя при этом векторные представления элементов, используемые существующим индексом ANN. Краткое описание модели Two-Tower с замороженными слоями можно найти здесь.
Конвейер также инициализирует ранжировщик DLRM на основе предыдущей контрольной точки, но обучает все параметры с меньшей скоростью обучения и за меньшее количество эпох.
После завершения обучения программа сохраняет доработанную структуру запросов и алгоритм ранжирования DLRM в новые папки версий в существующем репозитории модели Triton.
Продвигайте усовершенствованные модели.
На этом этапе Triton запрашивает загрузку новых моделей. Triton обрабатывает запросы к существующим версиям моделей, одновременно загружая новые модели в фоновом режиме. Затем он выполняет «горячую» замену на последние версии моделей, как только они будут готовы.
Обработка запросов через 14 моделей на сервере NVIDIA Triton Inference.
Репозиторий моделей содержит 14 моделей, использующих два бэкэнда. Бэкэнды на Python используются для поиска признаков, преобразования признаков и фильтрации; бэкэнды на TensorFlow — для построения иерархии запросов и ранжирования DLRM. Ансамблевая конфигурация объединяет все эти модели в направленный ациклический граф (DAG), который обрабатывается сервером NVIDIA Triton Inference.
Как подготавливаются контекст и пользовательские функции
Каждый запрос поступает с идентификатором пользователя, необязательным типом устройства и меткой времени запроса. Если какой-либо контекст отсутствует, context_preprocessor заменяет его значениями по умолчанию. Например, для отсутствующей метки времени заменяется текущее время сервера, а для отсутствующего типа устройства — значение OOV sentinel. Рабочий процесс контекста преобразует данные контекста в категоризированный индекс устройства и четыре временных признака (синус/косинус часа, синус/косинус дня недели).
В пути пользователя функция feast_user_lookup извлекает характеристики пользователя из онлайн-хранилища характеристик (используемого ElastiCache для Valkey), затем функция nvt_user_transform преобразует характеристики, используя рабочий процесс пользователя, прежде чем передать их в блок запросов (query_tower). Блок запросов создает векторные представления пользователя, которые функция faiss_retrieval использует для поиска сходства, возвращая K лучших идентификаторов элементов.
Обработка холодного запуска пользователя
Если идентификатор пользователя не найден в онлайн-хранилище признаков, функция feast_user_lookup использует значения по умолчанию, а именно: user_id = -1, age = среднее значение в обучающей выборке, gender = -1 и top_category = -1. Функция nvt_user_transform сопоставляет эти идентификаторы user_id, gender и top_category с их индексами OOV, а средний возраст — с нормализованным значением и категориальным возрастным диапазоном. Затем функция query_tower генерирует векторное представление пользователя из преобразованных признаков. Хотя функция faiss_retrieval возвращает те же кандидаты с учетом популярности для неизвестных пользователей, ранжировщик DLRM все еще может персонализировать порядок кандидатов, используя доступный контекст.
Фильтрация просмотренных элементов с помощью фильтра Блума
Идентификаторы элементов-кандидатов проверяются с помощью фильтра Блума в ElastiCache для Valkey. Этот шаг может отсеять значительное количество кандидатов, поэтому важно обеспечить избыточную выборку на этапе получения данных, поскольку это гарантирует, что ранжировщик получит достаточное количество кандидатов для создания осмысленного списка рекомендаций.
Отфильтрованные идентификаторы элементов поступают в конвейер обработки признаков элементов, где функция feast_item_lookup извлекает признаки элементов из онлайн-хранилища признаков, функция nvt_item_transform преобразует эти признаки, используя рабочий процесс пользователя, а функция multimodal_embedding_lookup возвращает предварительно обученные эмбеддинги CLIP (изображение) и Sentence BERT (текст) для элементов.
Ранжирование и упорядочивание
Модель unroll_features разбивает пользовательские и контекстные характеристики на блоки в соответствии с размером списка кандидатов для поиска. Затем ранжировщик DLRM (dlrm_ranking) оценивает кандидатов. В функции softmax_sampling, если DIVERSITY_MODE отключен, модель возвращает топ-K кандидатов в порядке убывания оценок; если он включен, модель использует взвешенную выборку на основе оценок без замещения для выбора разнообразного топ-K, при этом отдавая предпочтение элементам с более высокими оценками. Наконец, item_id_decoder сопоставляет упорядоченные идентификаторы кандидатов (индексы NVTabular) с исходными идентификаторами элементов, и Triton возвращает выбранные идентификаторы элементов вместе с соответствующими оценками.
Снижение задержки поиска характеристик элементов за счет кэширования в оперативной памяти.
Профилирование сервера с помощью Triton Performance Analyzer при размере запроса 300 показало, что feast_item_lookup потребляет 195 мс, что составляет примерно 52% от общей задержки запроса при concurrency=1. Под нагрузкой время ожидания в очереди увеличилось с 36 мс (при concurrency=1) до 988 мс (при concurrency=4). Это ограничило пропускную способность на уровне 2,9 операций вывода в секунду независимо от количества одновременно выполняемых запросов.
Узким местом было то, что функция feast_item_lookup при каждом запросе извлекала характеристики для 300 кандидатов из онлайн-хранилища Feast. Для решения этой проблемы вызовы Feast для получения характеристик предметов были заменены внутрипроцессным кэшем массивов NumPy. По сути, при инициализации feast_item_lookup все характеристики предметов извлекаются из Feast один раз и сохраняются в виде массивов NumPy, индексированных по идентификатору предмета, поэтому каждый запрос считывает характеристики из памяти, а не выполняет сетевые вызовы к онлайн-хранилищу характеристик. Эта оптимизация привела к улучшению задержки feast_item_lookup примерно на 99,7% и улучшению сквозной задержки на 54% (при параллелизме=1). Кроме того, пропускная способность (при параллелизме=4) улучшилась на 310%. Единственным компромиссом является то, что кэшированные характеристики обновляются только при перезапуске Triton, однако для каталога с достаточно статичными атрибутами предметов это не является проблемой.
После этого изменения три модели преобразования NVTabular — nvt_user_transform (72 мс), nvt_item_transform (41 мс) и nvt_context_transform (39 мс) — стали отвечать примерно за 88% оставшейся задержки. Дальнейшая оптимизация моделей отложена до следующей версии этого проекта.
Автоматическое масштабирование сервера Triton Inference Server на EKS
В этом проекте сервер вывода Triton масштабируется автоматически с помощью Kubernetes Horizontal Pod Autoscaler (HPA) на основе пользовательской метрики — среднего времени (в миллисекундах), которое каждый запрос провел в очереди за последние 30 секунд. Когда эта задержка превышает целевое значение, HPA масштабирует развертывание Triton, увеличивая желаемое количество реплик подов. Если новый под Triton не может быть запланирован, поскольку ни один узел с графическим процессором не имеет достаточной мощности для нового пода, Karpenter выделяет новый узел с графическим процессором и добавляет его в кластер. Как только узел становится доступным, планировщик Kubernetes размещает на нем под Triton. Как только новый под будет готов, балансировщик нагрузки может начать маршрутизацию трафика к нему.
Проверка контекстных рекомендаций, фильтрация с помощью фильтра Блума и обновление рекомендаций практически в режиме реального времени.
Для проверки системы режим разнообразия был отключен во время развертывания, чтобы изолировать его влияние от влияния типов контекста, фильтрации по фильтру Блума и изменения предпочтений в рекомендациях.
Проверка контекстных рекомендаций
Для проверки контекстных рекомендаций я экспериментировал с различными типами запросов, включая запросы только с идентификатором пользователя и запросы, которые объединяли идентификатор пользователя с контекстными характеристиками, такими как тип устройства и временная метка. Эти тесты показали, что рекомендации для неизвестных пользователей различаются в зависимости от контекста. Пользователь, впервые использующий сервис, может получать разные списки элементов в зависимости от типа устройства и времени запроса. Для существующих пользователей влияние контекста было менее выраженным. Общий рейтинг оставался в основном стабильным во всех контекстах, хотя выходные оценки различались.
Проверка фильтрации элементов с помощью фильтра Блума
Для проверки исключения просмотренных элементов с помощью фильтра Блума было нажато несколько кнопок на элементы из карусели «Рекомендовано для вас». Эти элементы были исключены из последующих рекомендаций фильтром Блума. Чтобы избежать изменения предполагаемых предпочтений пользователя и искажения результатов проверки фильтра Блума, нажимайте на элементы из разных категорий.
В видеоролике, демонстрирующем фильтрацию с помощью фильтра Блума, мы видим, что такие товары, как «Декадентский шоколадный торт мечты» и «Винтажный холщовый рюкзак исследователя», исключаются из следующих рекомендаций пользователя 12345678.
Проверка обновлений рекомендаций практически в режиме реального времени.
Для проверки возможности обновления рекомендаций в режиме, близком к реальному времени, для существующих пользователей, тест начинается с получения рекомендаций для пользователя, чтобы определить его текущие предпочтения. Затем пользователь кликает на несколько товаров из одной категории, например, только на товары из категорий «Аксессуары», «Мебель» или «Продукты питания», и ждет около пяти секунд, пока обновления вступят в силу. Повторные взаимодействия с товарами одной категории могут изменить предполагаемые предпочтения пользователя, если эта категория отличается от его текущей категории top_category. Параметр top_category представляет собой доминирующую категорию среди товаров, с которыми пользователь взаимодействовал в течение последних 24 часов, и пересчитывается после каждого взаимодействия. При следующем запросе модель может повысить рейтинг товаров из этой новой категории интересов и отобразить их в числе лучших рекомендаций.
В видеоролике, демонстрирующем изменения в рекомендациях в режиме реального времени, мы видим, что лучшие рекомендации пользователя 1003 меняются с «Аксессуары» на «Декор для дома (и мебель)» из-за многократного взаимодействия с товарами в категории «Мебель».
Однако следует отметить, что функция top_category представляет собой грубое приближение к краткосрочным интересам, используемое для демонстрации способности системы адаптироваться к поведению пользователя в режиме реального времени. Для более детального моделирования краткосрочных интересов в следующей итерации этого проекта статическая база запросов будет заменена кодировщиком-трансформатором на основе сессий.
Ограничения и дальнейшая работа
В текущей архитектуре контекст запроса, такой как тип устройства и характеристики, полученные на основе временной метки, используется только ранжировщиком. Это было сделано для упрощения процесса извлечения, поскольку добавление контекста во время извлечения потребовало бы вычисления дополнительных характеристик в процессе генерации кандидатов. Однако, если контекст запроса влияет на то, какие элементы должны быть извлечены, релевантные кандидаты могут быть отфильтрованы до того, как ранжировщик их увидит.
Одно из направлений развития — добавление контекстных характеристик запроса к иерархии запросов, чтобы и поиск, и ранжирование учитывали контекст. Другое направление — замена текущей иерархии запросов на кодировщик сессий, который будет более точно фиксировать краткосрочное поведение пользователя, чем текущая аппроксимация поведенческих характеристик (например, top_category).
Заключение
В этой статье рассматривается многоступенчатая мультимодальная рекомендательная система для сценария использования в электронной коммерции, развернутая на Amazon EKS. Система сочетает в себе поиск кандидатов по алгоритму «Двух башен», контекстно-ориентированное ранжирование DLRM и ранжирование по разнообразию на основе оценок. Система использует табличные характеристики пользователей и товаров, мультимодальные встраивания на основе изображений товаров и текстовых описаний, а также контекстную информацию.
Проблема «холодного старта» решается с помощью маскирования признаков во время обучения, что заставляет модели полагаться на изученное векторное представление OOV и контекстные сигналы, когда пользователь новый или неизвестный. Это означает, что анонимные и новые пользователи получают рекомендации, которые адаптируются к типу их устройства и времени запроса, а не к статическому резервному списку. Фильтры Блума предотвращают повторное появление уже просмотренных элементов в повторных сессиях, а кэширование признаков элементов в памяти помогло устранить узкое место задержки на этапе поиска признаков элементов. Кроме того, адаптация системы в реальном времени к изменяющимся поведенческим сигналам демонстрируется с помощью признака top_category.
Со стороны MLOps жизненный цикл системы управляется двумя конвейерами Kubeflow. Один конвейер отвечает за полное обучение и развертывание, а другой — за ежедневную тонкую настройку базы запросов и ранжировщика без перестроения индекса встраивания элементов. Karpenter и Kubernetes HPA отвечают за масштабирование вычислительных ресурсов в зависимости от нагрузки запросов.
Представленная система демонстрирует рекомендательные системы производственного типа, в которых этап поиска, оптимизированный по скорости и полноте, сочетается с этапом ранжирования, оптимизированным по точности, и инфраструктурным уровнем, предназначенным для обновления моделей без полной переобучения на каждом цикле. Полный код можно найти в этом репозитории: MustaphaU/multistage-recommender-system-on-kubernetes
Надеюсь, вам понравилось читать! С нетерпением жду ваших вопросов.
Вы можете связаться со мной через LinkedIn .
Ресурсы
- Мустафа Унуби Момох, Многоступенчатая многомодальная рекомендательная система на Kubernetes, репозиторий GitHub. Доступно по адресу: https://github.com/MustaphaU/multistage-recommender-system-on-kubernetes
- Эвен Олдридж и Карл Байлин-Хигли, «Рекомендательные системы, а не просто модели рекомендаций», NVIDIA Merlin (Medium), апрель 2022 г. Доступно по адресу: https://medium.com/nvidia-merlin/recommender-systems-not-just-recommender-models-485c161c755e
- Радек Осмульски, «Изучение готовых к внедрению рекомендательных систем с помощью Merlin», NVIDIA Merlin (Medium), июль 2022 г. Доступно по адресу: https://medium.com/nvidia-merlin/exploring-production-ready-recommender-systems-with-merlin-66bba65d18f2
- Джакопо Тальябуэ, Уго Боун-Андерсон, Ронай Ак, Габриэль де Соуза Морейра и Сара Рабхи, «NVIDIA Merlin встречается с экосистемой MLOps: создание готового к производству конвейера RecSys в облаке», NVIDIA Merlin (Medium), февраль 2023 г. Доступно по адресу: https://medium.com/nvidia-merlin/nvidia-merlin-meets-the-mlops-ecosystem-building-a-production-ready-recsys-pipeline-on-cloud-1a16c156166b.
- Бенедикт Шифферер, «Решение проблемы холодного старта с помощью двухбашенных нейронных сетей для систем рекомендаций электронной почты NVIDIA», NVIDIA Merlin (Medium), январь 2023 г. Доступно по адресу: https://medium.com/nvidia-merlin/solving-the-cold-start-problem-using-two-tower-neural-networks-for-nvidias-e-mail-recommender-2d5b30a071a4.
- Цзию «Юджин» Ян, «Системный дизайн для рекомендаций и поиска», eugeneyan.com, июнь 2021 г. Доступно по адресу: https://eugeneyan.com/writing/system-design-for-discovery/.
- Хаоран Юань и Алехандро А. Эрнандес, «Проблема холодного старта пользователя в рекомендательных системах: систематический обзор», IEEE Access, том 11, стр. 136958–136977, 2023. Доступно по адресу: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10339320
- Джастин Вортц и Джастин Тоттен, «Масштабирование глубокого поиска с помощью рекомендательных систем TensorFlow и механизма сопоставления Vertex AI», блог Google Cloud, 19 апреля 2023 г. Доступно по адресу: https://cloud.google.com/blog/products/ai-machine-learning/scaling-deep-retrieval-tensorflow-two-towers-architecture
- Сэм Парти, Тайлер Хатчерсон и Натан Стивенс, «От офлайна к онлайну: хранение признаков для систем рекомендаций в реальном времени с помощью NVIDIA Merlin», Технический блог NVIDIA, 1 марта 2023 г. Доступно по адресу: https://developer.nvidia.com/blog/offline-to-online-feature-storage-for-real-time-recommendation-systems-with-nvidia-merlin/
Мустафа Момох Посмотреть все материалы от Мустафы Момоха
Источник: towardsdatascience.com
Оцените материал:
