Разработка синтетических наборов данных для реального мира: проектирование механизмов и рассуждения, исходя из фундаментальных принципов.
Для решения проблемы нехватки данных, необходимых для специализированного ИИ, мы представляем Simula — фреймворк, который переосмысливает генерацию синтетических данных как проектирование механизмов на уровне наборов данных. Используя логические рассуждения для построения наборов данных на основе фундаментальных принципов, Simula обеспечивает точный контроль над охватом, сложностью и качеством, предоставляя масштабируемую генерацию для областей, чувствительных к конфиденциальности или испытывающих дефицит данных.
Быстрые ссылки
- Бумага
- Делиться
Быстрое развитие универсальных моделей ИИ обусловлено обилием данных в интернете. Однако для широкого внедрения ИИ потребуются модели, специализирующиеся на новых, редких и чувствительных к конфиденциальности приложениях, где данные по своей природе дефицитны или недоступны.
Для преодоления этого разрыва использование данных из реального мира накладывает существенные ограничения:
- Стоимость и доступность: Создание специализированных наборов данных вручную является непомерно дорогим, трудоемким и подверженным ошибкам процессом.
- Операционные издержки: Статичный характер реальных данных замедляет циклы разработки. В отличие от этого, подход, основанный на синтетических данных, позволяет создавать «программируемые рабочие процессы», где данные обрабатываются как код — версионированные, воспроизводимые и проверяемые.
- Готовность: Мы не можем позволить себе реактивный подход к таким вопросам, как безопасность, когда модели можно укрепить только после возникновения сбоев. Синтетические данные позволяют нам заблаговременно генерировать крайние случаи и проводить стресс-тестирование систем в условиях, которые еще не встречались в реальных условиях.
Хотя синтетические данные представляют собой многообещающую альтернативу, существующие методы генерации часто не обладают необходимой строгостью для внедрения в производственных масштабах. Многие из существующих подходов основаны на ручных запросах, эволюционных алгоритмах или обширных исходных данных из целевого распределения.
Эти методы ограничивают масштабируемость (из-за зависимости от начальных данных или человеческого фактора), объяснимость (из-за эволюционных этапов, напоминающих «черный ящик») и управляемость (из-за запутанных параметров генерации). Что наиболее важно, они, как правило, работают на уровне выборки — оптимизируя одну точку данных за раз — а не проектируя набор данных в целом.
Для решения этой проблемы нам необходимо переосмыслить генерацию синтетических данных как задачу проектирования механизмов. В производственных сценариях использования требуется подход, выходящий за рамки простого «большего количества данных»; необходимо детальное распределение ресурсов, где охват, сложность и качество являются независимо контролируемыми переменными.
Simula: структура, основанная на логическом рассуждении.
В нашей статье «Генерация и оценка синтетических данных на основе логического мышления», опубликованной в журнале Transactions on Machine Learning Research , мы представляем Simula. В отличие от методов, основанных на непрозрачных процессах, Simula использует методологию «сначала логическое мышление», создавая целые наборы данных из базовых принципов. Этот подход не требует начального значения и является агентным, что позволяет возможностям генерации естественным образом улучшаться по мере развития возможностей логического мышления базовых моделей.
Контроль над осями генерации данных
Simula разлагает процесс генерации на отдельные, управляемые оси, используя четыре этапа:
- Глобальная диверсификация: Вместо случайной выборки Simula использует модели рассуждений для отображения концептуального пространства целевой области в глубокие иерархические таксономии. Это действует как «основа для выборки». Определяя стратегии выборки на основе этих таксономий, мы можем контролировать глобальную диверсификацию , обеспечивая охват набором данных всего «хвоста» области, а не кластеризацию вокруг общих режимов.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Для построения карты концептуального пространства целевой области без использования исходных данных, полученных от человека, Simula применяет основанный на рассуждениях рекурсивный процесс расширения. На каждом уровне глубины система генерирует множество потенциальных подкатегорий (предложений), которые впоследствии оцениваются, объединяются и фильтруются с помощью модели критика. Этот итеративный цикл «предложение-уточнение» динамически строит плотную иерархическую таксономию — такую как дерево анализа киберугроз — которая служит основой для обеспечения глобального разнообразия набора данных.
Вооружившись набором глубоких таксономий, мы теперь можем начать составлять карту интересующего нас пространства охвата и оптимизировать (2) локальное разнообразие, (3) сложность и (4) качество:
2. Локальная диверсификация: Для обеспечения вариативности внутри конкретных концепций мы используем механизмы локальной диверсификации . Система генерирует «мета-подсказки» — сценарии, полученные из узлов таксономии, — а затем создает несколько различных вариаций этого сценария. Это предотвращает коллапс режимов, гарантируя, что такая концепция, как «SQL-инъекция», представлена в различных интерпретациях, а не в идентичных повторениях.
3. Усложнение: Сложность рассматривается как ортогональная ось. Мы используем этап «усложнения», в ходе которого настраиваемая доля мета-подсказок уточняется, становясь более сложной или трудной. Это позволяет специалистам изменять распределение сложности набора данных без изменения его семантического охвата.
4. Проверка качества: Для обеспечения корректности без вмешательства человека мы используем цикл «двойной критики», который независимо оценивает правильность или неправильность ответа. Такая двойная проверка помогает смягчить эффект подхалимства (когда модели склонны соглашаться с правдоподобно звучащими результатами) и обеспечивает высокое качество меток.
Simula рассматривает создание синтетических данных как задачу проектирования механизмов, разлагая этот процесс на отдельные, управляемые оси. Во-первых, глобальная диверсификация использует таксономии для обеспечения широкого охвата предметной области. Во-вторых, локальная диверсификация использует мета-подсказки типа «один из N» для создания различных сценариев и предотвращения коллапса режимов. В-третьих, усложнение опционально уточняет эти сценарии, повышая их сложность и детализацию. Наконец, проверки качества используют цикл с двумя критиками для подтверждения того, что все выходные данные соответствуют семантическим и структурным ограничениям.
Решение проблем в оценке
Оценка синтетических данных представляет собой принципиально сложную задачу из-за неоднозначности их основных целей и несоответствия между стандартными метриками и их практической полезностью. Стандартные метрики, такие как косинусное расстояние на основе эмбеддингов, дают общий сигнал, но предоставляют ограниченные возможности для практического применения.
Для повышения надежности оценок мы применяем здесь и наш подход, основанный на логическом обосновании. В частности, мы вводим основанные на логическом обосновании метрики — таксономический охват и калиброванную оценку сложности (которая использует пакетные сравнения на основе LLM для присвоения отдельным точкам данных рейтингов Эло в шахматном стиле) — чтобы лучше отразить нюансы разнообразия и сложности.
Универсального решения нет.
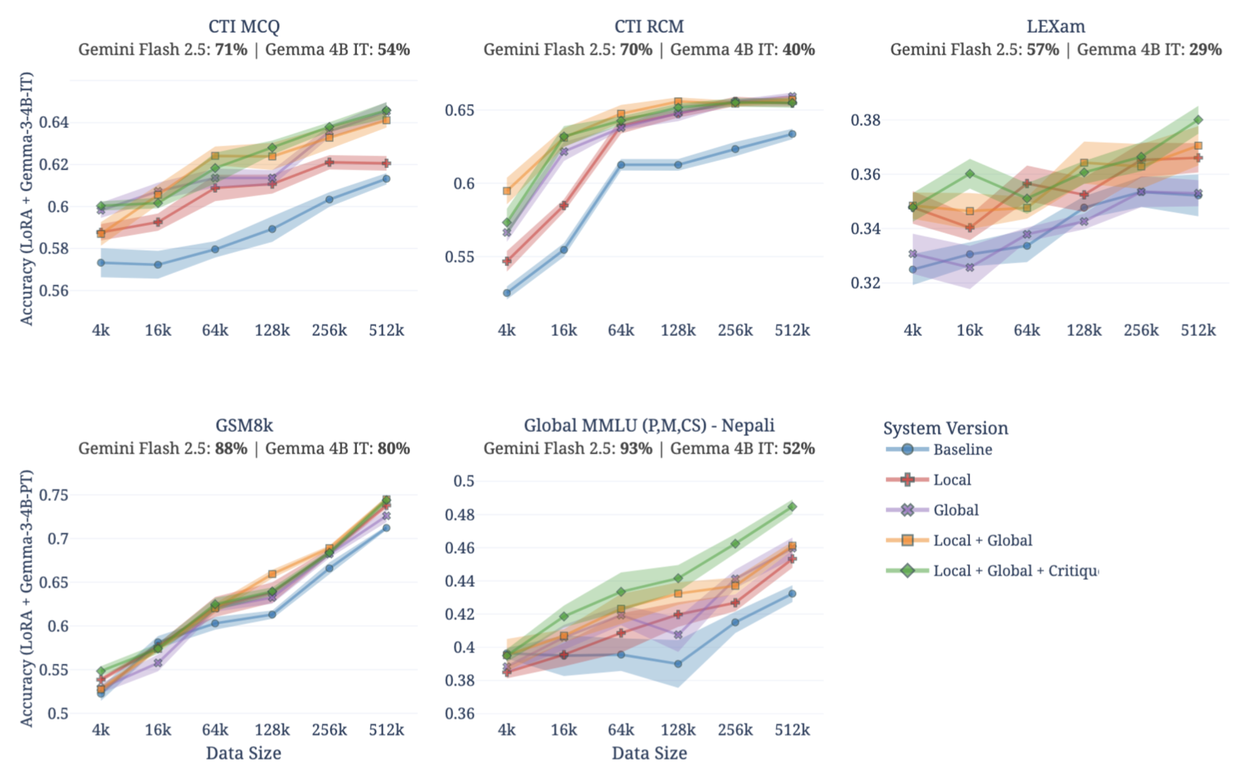
Мы использовали Gemini 2.5 Flash в качестве модели-учителя и Gemma-3 4B в качестве модели-ученика для оценки Simula в пяти различных областях — от кибербезопасности (CTI-MCQ, CTI-RCM из CTIBench) и юридического мышления (LEXam) до стандартных оценок моделей ИИ, таких как математика для начальной школы (GSM8k) и многоязычные академические знания (Global MMLU). Генерируя наборы данных, содержащие до 512 000 точек данных для каждой области, наши результаты подчеркивают важную реальность: не существует единого «оптимального» способа генерации данных, и взаимосвязь между «качественными» данными и последующей производительностью носит глубоко индивидуальный характер.
- Разработка механизма не подлежит обсуждению: во всех областях полная система Simula, сочетающая глобальный охват, локальное разнообразие и критический анализ, неизменно превосходила более простые базовые модели.
- Контекст имеет решающее значение: универсальных рецептов не существует. Хотя высокая сложность привела к повышению точности математических рассуждений на 10% (GSM8k), она фактически ухудшила производительность в задачах юридического анализа (LEXam), где модель-учитель оказалась слабее. Данные должны быть адаптированы к возможностям модели, которая их использует.
- Качество — это новая величина: лучшие данные лучше масштабируются. Simula показала более высокую производительность на последующих этапах обработки данных при меньшем количестве выборок по сравнению с базовыми подходами, подтверждая, что законы масштабирования определяются свойствами данных, а не только их объемом.
Хотя это была установка для дистилляции, выбранная для воспроизводимой, системной оценки, основные выводы, сделанные на её основе, выходят за рамки этой конкретной конфигурации.

Производительность на разных наборах данных.
От исследований к реальному влиянию
Simula была создана не только для оптимизации бенчмарков, но и служит основополагающим механизмом обработки данных для реальных, критически важных для бизнеса приложений в Google. В передовой области ИИ она стала ключевым фактором развития экосистемы Gemma, включая специализированные модели, такие как ShieldGemma, FunctionGemma и MedGemma, а также обеспечивает основную основу для синтетических данных как для классификаторов безопасности Gemini на устройствах, так и на серверах. Помимо базовых моделей, Simula сыграла важную роль в разработке функций защиты пользователей, включая обнаружение мошенничества с помощью ИИ для звонков Android и фильтрацию спама в Google Messages. Кроме того, Simula активно продвигает новые прикладные исследования, способствуя созданию фреймворков, которые демократизируют машинное обучение для корпоративной безопасности путем синтеза реалистичных сценариев атак, и обеспечивая такие прорывы, как обучение моделей ИИ чтению карт посредством структурированной генерации наборов данных на основе логического мышления.
Центральная роль синтетических данных в специализированном искусственном интеллекте.
Прогресс в области ИИ находится на переломном этапе. Специализированные данные, необходимые для следующей волны прорывов — в науке, безопасности и праве — вряд ли могут быть сгенерированы людьми в необходимом масштабе. Синтетические данные готовы сыграть центральную роль в этих прорывах, но только при условии тщательного подхода. В конечном итоге, ценность Simula заключается в демонстрации того, как разработка механизмов может сделать генерацию данных контролируемой наукой. Этот план предоставляет четкий путь к созданию высокоточных наборов данных, необходимых для следующей эры ИИ — будь то преобразование знаний в периферийные устройства, обучение агентов с помощью обучения с подкреплением или систематическое исследование сложных граничных случаев.
Благодарности
Данное исследование было проведено Тимом Р. Дэвидсоном, Бенуа Сегеном, Энрико Бачисом, Сезаром Ильхарко и Хамзой Харкусом. Разработка и руководство фреймворком Simula осуществлялись Хамзой и Бенуа. Особая благодарность Тиму за его значительный вклад в период работы в качестве студента-исследователя. Мы также благодарим Яна Келлера за поддержку в области TPM, а также Корана Корбетта и Нинни Ван за их важное техническое и продуктовое сотрудничество. Наконец, мы благодарим Нину Тафт, Аманду Уокер и Панкаджа Рохатги за их спонсорство и поддержку.
Источник: research.google
Оцените материал:
