Последовательное внимание: повышение эффективности и скорости работы моделей ИИ без ущерба для точности.
Мы представляем алгоритм выбора подмножества для повышения эффективности крупномасштабных моделей машинного обучения.
Быстрые ссылки
- Бумага
- Делиться
Выбор признаков — это процесс выявления и сохранения наиболее информативного подмножества входных переменных при отбрасывании нерелевантного или избыточного шума. Выбор признаков, являющийся фундаментальной задачей как в машинном обучении, так и в глубоком обучении, относится к NP-трудным задачам (то есть, это задача, которую математически «невозможно» решить идеально и быстро для больших групп данных), и поэтому остается крайне сложной областью исследований.
В современных глубоких нейронных сетях выбор признаков дополнительно усложняется сложными нелинейными взаимодействиями признаков. Признак может казаться статистически незначимым сам по себе, но становится критически важным в сочетании с другими признаками в нелинейных слоях сети. И наоборот, вклад признака может казаться значительным сам по себе, но становится избыточным при учете других признаков. Основная задача заключается в выявлении существенных признаков для сохранения при эффективном удалении избыточности в сложных архитектурах моделей.
В более широком смысле, многие задачи оптимизации машинного обучения можно рассматривать как задачи выбора подмножества , частным случаем которых является выбор признаков. Например, настройку размерности эмбеддингов можно рассматривать как выбор подмножества фрагментов эмбеддингов, а обрезку весов — как выбор подмножества элементов из матрицы весов. Поэтому разработка общего решения для задачи выбора подмножества, применимого к современным задачам глубокого обучения, может оказать существенное влияние на создание наиболее эффективных моделей.
Сегодня мы рассмотрим наше решение проблемы выбора подмножества, называемое последовательным вниманием (Sequential Attention). Sequential Attention использует жадный механизм выбора для последовательного и адаптивного выбора наилучшего следующего компонента (например, слоя, блока или признака) для добавления в модель. Хотя известно, что адаптивные жадные алгоритмы обеспечивают надежные гарантии для различных задач выбора подмножества, таких как субмодулярная оптимизация, наивное применение таких алгоритмов увеличило бы стоимость обучения на несколько порядков. Для решения этой проблемы масштабируемости мы интегрируем выбор непосредственно в процесс обучения модели, выполняя выбор в рамках одного обучения модели. Это гарантирует, что Sequential Attention может применяться к крупномасштабным моделям машинного обучения с минимальными накладными расходами без ущерба для точности или сложности. Здесь мы проанализируем, как работает Sequential Attention, и покажем, как он используется в реальных сценариях для оптимизации структуры моделей глубокого обучения.
Как работает последовательное внимание
Последовательное внимание использует весовые коэффициенты механизма внимания для пошагового формирования подмножества. В отличие от стандартного «одноразового» внимания, при котором все кандидаты взвешиваются одновременно, последовательное внимание решает NP-трудную задачу выбора подмножества, рассматривая её как последовательный процесс принятия решений. Это особенно эффективно для выявления нелинейных взаимодействий высокого порядка, которые часто упускаются «фильтрующими методами», предоставляющими простейший способ выбора подмножества, фокусируясь только на достоинствах каждого отдельного элемента.

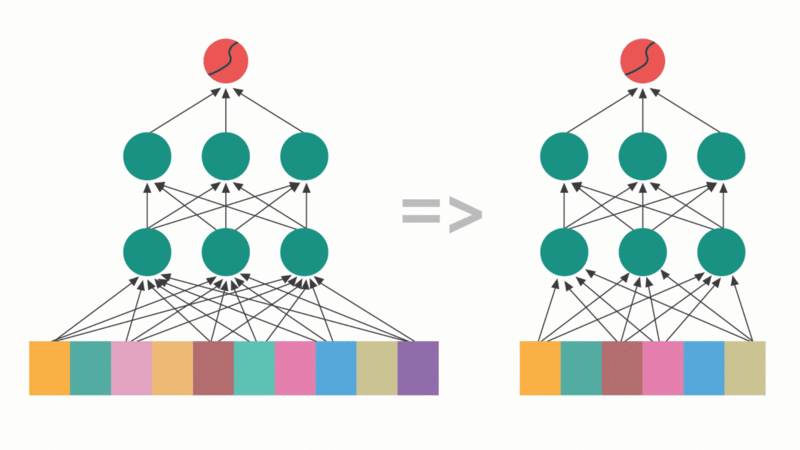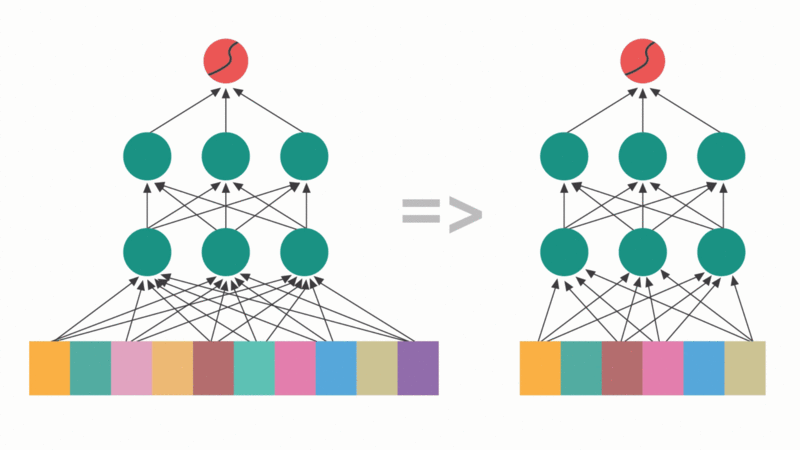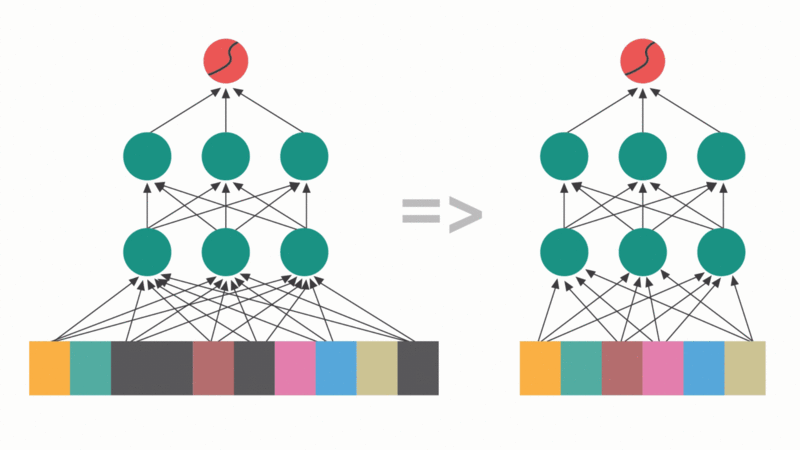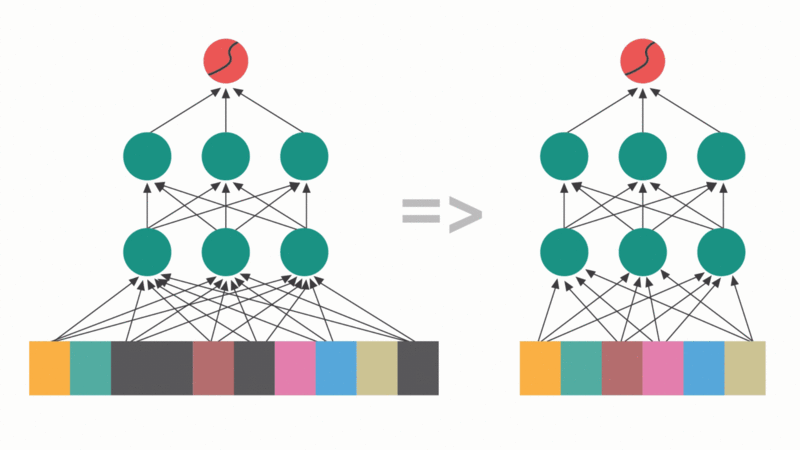
Выбор признаков в нейронных сетях: избирательное отсечение входных признаков для оптимизации производительности. «Отключая» малополезные признаки, модель упрощает задачу обучения и снижает риск переобучения.
Основная идея заключается в поддержании набора выбранных кандидатов и использовании их в качестве контекста для поиска следующего наиболее информативного кандидата. Это достигается двумя основными методами: жадным отбором, который позволяет модели принимать локально оптимальное решение о том, какой элемент включить на каждом шаге, и оценкой важности, которая использует «показатели внимания» (числовые значения, указывающие на важность или релевантность различных входных частей) для количественной оценки важности каждого кандидата в дополнение к уже выбранным кандидатам. Как и механизм внимания, последовательное внимание использует softmax в качестве ранжирования важности различных компонентов. Однако, в отличие от механизма внимания, оно работает последовательно, а не однократно, что позволяет алгоритму отбора адаптироваться к предыдущим выборам — важнейшее свойство для высококачественного ранжирования важности.
Преимущества последовательного внимания
Основные преимущества последовательного внимания заключаются в следующем:
- Эффективность и точность : Благодаря возможности параллельной обработки кандидатов (после вычисления показателей внимания), их можно оценивать быстрее, чем при традиционном последовательном отборе.
- Интерпретируемость : Сами по себе показатели внимания представляют собой мощный диагностический инструмент. Исследователи могут изучить показатели внимания, чтобы точно определить, каким частям входных данных модель отдавала приоритет при принятии конкретного решения или генерации конкретного токена. Это делает внутренние рассуждения модели более интерпретируемыми, чем у модели типа «черный ящик».
- Масштабируемость : Способность эффективно обрабатывать большое количество кандидатов имеет решающее значение для крупномасштабного отбора признаков в современных нейронных сетях.
Последовательное внимание в действии
Выбор функций
Стандартный метод отбора признаков, то есть жадный отбор, является вычислительно затратным, поскольку требует переобучения или переоценки модели для каждого потенциального признака на каждом шаге. В работе «Последовательное внимание для отбора признаков» мы стремились заменить этот дорогостоящий метод гораздо более дешевым аналогом: внутренними весами внимания модели.
На каждом шаге алгоритм последовательного внимания вычисляет весовые коэффициенты внимания для всех оставшихся, невыбранных признаков и навсегда добавляет к подмножеству признак с наивысшим показателем внимания (тот, которому модель «уделяет наибольшее внимание»). Затем алгоритм повторно запускает процесс отбора (процесс послойной подачи входных данных в нейронную сеть от входа к выходу для генерации прогноза) и пересчитывает весовые коэффициенты внимания для оставшихся признаков. Этот перерасчет естественным образом отражает предельный выигрыш (насколько признак способствует повышению производительности с учетом уже выбранных признаков), позволяя модели эффективно выявлять и избегать добавления избыточных признаков.
Эффективность выбора признаков. Точность прогнозирования предлагаемого подхода (оранжевым цветом) по сравнению с базовыми методами. Наш метод демонстрирует конкурентоспособные или лидирующие результаты в тестах на протеомику, распознавание изображений и активности, подтверждая свою надежность.
Алгоритм последовательного внимания (Sequential Attention) продемонстрировал передовые результаты в нескольких тестах нейронных сетей. В частности, он значительно повысил эффективность, обеспечив быструю однопроходную реализацию жадного выбора без необходимости дорогостоящих явных вычислений предельного выигрыша. Исследование также показало, что при применении к простой модели линейной регрессии алгоритм последовательного внимания математически эквивалентен известному алгоритму ортогонального сопоставления (Orthogonal Matching Pursuit, OMP). Эта эквивалентность имеет решающее значение, поскольку OMP обладает доказуемыми гарантиями надежности и производительности.
Блочное разреживание
Уменьшение размера нейронной сети имеет важное значение для эффективного развертывания больших моделей, поскольку оно сокращает размер модели за счет удаления ненужных весов. В предыдущих исследованиях использовались два в значительной степени разных подхода: дифференцируемое уменьшение размера, при котором обучаемые параметры используются в качестве аппроксимации важности, и комбинаторная оптимизация, при которой алгоритмы используются для поиска наилучшей разреженной структуры.
Разреживание матричных блоков: выявление и обнуление несущественных блоков параметров для оптимизации памяти и скорости. В отличие от неструктурированного удаления, разреженность на основе блоков использует аппаратное ускорение для повышения производительности вывода.
В работе «SequentialAttention++ для блочного разреживания: дифференцируемое отсечение в сочетании с комбинаторной оптимизацией» мы стремились объединить эти два подхода в целостную структуру для структурированного отсечения весов в нейронных сетях, которая удаляет целые блоки или каналы весов для достижения реальных улучшений на аппаратных ускорителях, таких как GPU и TPU.
Полученный алгоритм SequentialAttention++ предоставляет новый способ обнаружения наиболее важных блоков матриц весов и демонстрирует значительное повышение эффективности и сжатия модели без ущерба для точности в задачах машинного обучения, например, в классификации ImageNet.
Будущее последовательного внимания
Поскольку все более широкое внедрение моделей ИИ в науку, технику и бизнес делает эффективность моделей более актуальной, чем когда-либо, оптимизация структуры модели имеет решающее значение для создания высокоэффективных и одновременно экономичных моделей. Мы определили выбор подмножества как фундаментальную проблему, связанную с эффективностью модели в различных задачах оптимизации глубокого обучения, и последовательный механизм внимания (Sequential Attention) стал ключевым методом решения этих проблем. В дальнейшем мы стремимся расширить применение выбора подмножества на все более сложные области.
Разработка признаков с учетом реальных ограничений
Последовательное внимание продемонстрировало значительное повышение качества и экономию средств при оптимизации слоя встраивания признаков в больших моделях встраивания (LEM), используемых в рекомендательных системах. Эти модели, как правило, имеют большое количество гетерогенных признаков с большими таблицами встраивания, поэтому задачи выбора/отсечения признаков, перекрестного поиска признаков и оптимизации размерности встраивания оказывают существенное влияние. В будущем мы хотели бы позволить этим задачам проектирования признаков учитывать реальные ограничения вывода, что позволит обеспечить полностью автоматизированное и непрерывное проектирование признаков.
Отсечение больших языковых моделей (LLM)
Парадигма SequentialAttention++ представляет собой перспективное направление для сокращения LLM-моделей. Применяя эту структуру, мы можем обеспечить структурированную разреженность (например, блочную разреженность), удалить избыточные элементы внимания, измерения встраивания или целые блоки трансформеров, а также значительно уменьшить размер модели и задержку вывода, сохраняя при этом точность прогнозирования.
Разработка лекарств и геномика
Выбор признаков имеет решающее значение в биологических науках. Механизм последовательного внимания может быть адаптирован для эффективного извлечения влиятельных генетических или химических признаков из многомерных наборов данных, повышая как интерпретируемость, так и точность моделей в разработке лекарств и персонализированной медицине.
Текущие исследования сосредоточены на масштабировании механизма последовательного внимания для более эффективной обработки огромных наборов данных и сложных архитектур. Кроме того, ведутся работы по выявлению превосходных структур усеченных моделей и распространению строгих математических гарантий на реальные приложения глубокого обучения, что укрепляет надежность фреймворка в различных отраслях.
Выбор подмножества — ключевая задача, лежащая в основе множества задач оптимизации в глубоком обучении, а последовательное внимание — важный метод решения этих задач. В будущем мы рассмотрим больше применений выбора подмножества для решения более сложных задач в более широких областях.
Заключение
Последовательное внимание — это эффективный метод для решения множества крупномасштабных задач выбора подмножеств в глубоком обучении, играющий ключевую роль в оптимизации архитектуры модели. По мере развития этих методов они будут определять будущее машинного обучения, гарантируя, что мощный ИИ останется точным и доступным на долгие годы.
Благодарности
Мы хотели бы выразить благодарность нашим коллегам-исследователям: Тайсуке Ясуде, Лин Чену, Мэтью Фарбаху, Мохаммаду Хоссейну Батени и Вахабу Миррокни, чьи усилия способствовали развитию механизма последовательного внимания . Эта работа опирается на фундаментальные исследования в области выбора дифференцируемых подмножеств и комбинаторной оптимизации для создания более эффективных и доступных моделей искусственного интеллекта.
Источник: research.google
Оцените материал:

