Планирование в меняющемся мире: максимизация пропускной способности при изменяющейся во времени мощности.
Мы представляем новые, доказано эффективные алгоритмы для планирования заданий без перебоев в облачной инфраструктуре в условиях постоянных колебаний доступности машин.
Быстрые ссылки
- Бумага
- Делиться
В мире алгоритмического планирования задач вычислительные ресурсы часто рассматриваются как статичные: сервер имеет фиксированное количество процессоров, а кластер — постоянное количество доступных машин. Однако реальность современных крупномасштабных облачных вычислений гораздо более динамична. Ресурсы постоянно колеблются из-за сбоев оборудования, циклов технического обслуживания или ограничений по энергопотреблению.
Что еще более важно, в многоуровневых системах планирования задачи с высоким приоритетом часто требуют ресурсов по запросу, оставляя изменяющийся во времени объем «свободных» ресурсов для пакетных заданий с более низким приоритетом. Представьте себе ресторан, где столики зарезервированы для VIP-клиентов в разное время; планирование рассадки обычных клиентов за оставшимися столиками может стать сложной задачей.
Когда эти низкоприоритетные задачи не подлежат прерыванию — то есть их нельзя приостановить и возобновить позже — ставки высоки. Если выполнение задачи прерывается из-за снижения производительности, весь прогресс теряется. Планировщик должен решить: начать ли эту длительную задачу сейчас, рискуя будущим снижением производительности? Или подождать более безопасного момента, потенциально не уложившись в срок?
В докладе «Максимизация пропускной способности без вытеснения при изменяющейся во времени пропускной способности», представленном на SPAA 2025, мы начинаем исследование максимизации пропускной способности (общего веса или количества успешно выполненных заданий) в средах, где доступная пропускная способность колеблется во времени. Наше исследование предоставляет первые алгоритмы аппроксимации с постоянным коэффициентом (т.е. «разница» между ответом алгоритма и оптимальным ответом гарантированно является фиксированным, стабильным числом независимо от размера задачи) для нескольких вариантов этой задачи, предлагая теоретическую основу для создания более надежных планировщиков в нестабильных облачных средах.
Определение проблемы планирования
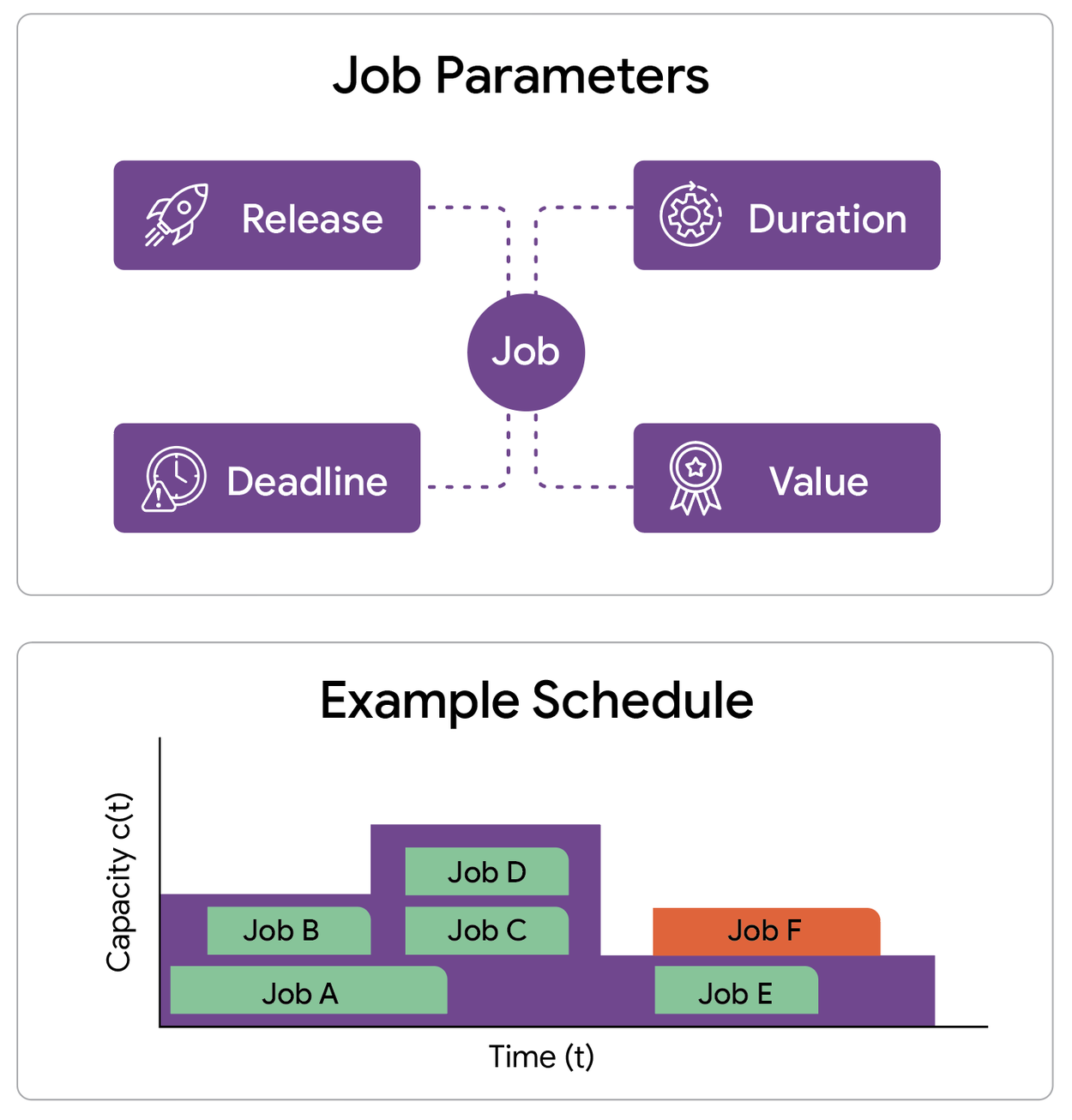
Наша работа сосредоточена на разработке модели планирования, учитывающей ряд ключевых ограничений. Мы рассматриваем одну машину (или кластер) с профилем производительности, изменяющимся со временем. Этот профиль определяет максимальное количество заданий, которые могут выполняться параллельно в любой момент времени. Нам дан набор потенциальных заданий, каждое из которых характеризуется четырьмя ключевыми атрибутами:
- Время выпуска : Когда задание станет доступно для выполнения.
- Крайний срок : Жесткий срок, к которому работа должна быть завершена.
- Время обработки : продолжительность, в течение которой машина должна работать над заданием.
- Вес : выгода, получаемая в случае успешного завершения работы.

Примером задачи максимизации пропускной способности является набор заданий, каждое из которых имеет время начала выполнения, крайний срок, продолжительность и стоимость, а также профиль производительности машины. Профиль производительности определяет максимальное количество заданий, которые могут обрабатываться одновременно в любой заданный момент времени.
Цель состоит в том, чтобы выбрать подмножество заданий и запланировать их выполнение таким образом, чтобы каждое выбранное задание выполнялось непрерывно в течение допустимого временного окна. Ключевое ограничение заключается в том, что в любой момент времени общее количество выполняющихся заданий не должно превышать текущую пропускную способность. Наша задача — максимизировать пропускную способность, то есть общий вес всех завершенных заданий.
Мы решаем эту проблему в двух различных условиях:
- Офлайн : Когда заранее известны будущие поступления рабочих мест и изменения производственных мощностей.
- Онлайн-режим : задания поступают в режиме реального времени, и планировщик должен принимать необратимые решения, не зная о будущих поступлениях. При этом ситуация с производственными мощностями по-прежнему известна заранее.
Результаты для офлайн-настройки
В автономном режиме, где мы можем планировать заранее, мы обнаруживаем, что простые стратегии показывают удивительно хорошие результаты. Поскольку поиск оптимального расписания в этом случае считается «NP-трудной задачей» (т.е., не существует известного короткого пути для нахождения идеального ответа), мы фокусируемся на алгоритмах со строгими гарантиями аппроксимации. Мы анализируем близорукую стратегию, называемую «жадной», которая итеративно планирует задание, которое завершится раньше всего, и доказываем, что эта простая эвристика достигает аппроксимации 1/2 (в данном контексте, часто наилучшего результата), когда задания имеют единичную прибыль. Это означает, что даже в худшем случае с заданиями и профилями производительности, выбранными враждебно, наш простой алгоритм гарантированно запланирует по крайней мере половину оптимального числа заданий. Это соответствует гарантиям, которыми обладает «жадная» стратегия на более простых машинах с единичной производительностью, которые могут выполнять только одну задачу за раз. Когда разные задания могут иметь разную связанную с ними прибыль, мы используем двойственную структуру для достижения аппроксимации 1/4.
Результаты для онлайн-настройки
Реальная сложность заключается в онлайн-режиме, где задания поступают динамически, и планировщик должен принимать немедленные, необратимые решения, не зная, какие задания поступят следующими. Мы количественно оценили производительность онлайн-алгоритма с помощью его коэффициента конкурентоспособности, который представляет собой сравнение в наихудшем случае пропускной способности нашего онлайн-алгоритма с пропускной способностью оптимального алгоритма, который заранее знает обо всех заданиях.
Стандартные алгоритмы без вытеснения полностью терпят здесь неудачу, поскольку их коэффициент конкурентоспособности приближается к нулю. Это происходит потому, что одно неверное решение о планировании длинной задачи может свести на нет возможность планирования множества будущих более мелких задач. В этом примере, если представить, что каждая выполненная задача имеет одинаковый вес, независимо от ее длины, выполнение множества коротких задач гораздо выгоднее, чем выполнение одной длинной задачи.
Чтобы сделать онлайн-задачу решаемой и отразить гибкость, характерную для реального мира, мы изучили две модели, которые позволяют прерывать активную задачу, если появляется более выгодная возможность (хотя успешными считаются только задачи, перезапущенные и впоследствии завершенные без прерывания).
Прерывание работы с перезапусками
В этой модели алгоритму, работающему в режиме реального времени, разрешается прерывать выполняющуюся в данный момент задачу. Хотя частично выполненная работа над прерванной задачей теряется, сама задача остается в системе и может быть повторена.
Мы обнаружили, что гибкость, обеспечиваемая возможностью перезапуска заданий, очень полезна. Вариант алгоритма «жадный алгоритм», который итеративно планирует выполнение задания, завершающегося раньше, продолжает достигать коэффициента конкурентоспособности в 1/2 раза, что соответствует результату в автономном режиме.
Прерывание работы без перезапусков
В этой более строгой модели вся работа, выполненная над прерванным заданием, теряется, а само задание навсегда отбрасывается. К сожалению, мы обнаружили, что в этой строгой модели любой онлайн-алгоритм может столкнуться с последовательностью заданий, которая вынуждает его принимать решения, препятствующие выполнению большего объема работы в будущем. Вновь коэффициент конкурентоспособности всех онлайн-алгоритмов приближается к нулю. Анализ вышеуказанных сложных случаев привел нас к рассмотрению практического сценария, где все задания имеют общий крайний срок (например, вся обработка данных должна завершиться к ночному пакетному запуску). Для таких случаев с общим крайним сроком мы разработали новые алгоритмы с постоянной конкурентоспособностью. Наш алгоритм очень интуитивно понятен, и мы описываем его здесь для простой задачи с единичным профилем производительности, то есть мы можем запланировать выполнение одного задания в любое время.
В данной ситуации наш алгоритм поддерживает предварительное расписание , распределяя уже поступившие задания по непересекающимся временным интервалам. Когда поступает новое задание, алгоритм изменяет предварительное расписание, выбирая первое подходящее действие из следующих четырех:
1. Добавьте задание в предварительное расписание, поместив его в пустой интервал.
2. Если новый проект значительно меньше по объему, замените его другим будущим проектом из предварительного графика.
3. Прервите выполняющуюся в данный момент задачу, если время выполнения новой задачи меньше оставшегося времени выполнения текущей задачи.
4. Отклонить вновь поступившее задание.
Наш основной результат показывает, что обобщение этого алгоритма на произвольные профили производительности дает первое постоянное соотношение конкурентоспособности для данной задачи. Формально мы получаем соотношение конкурентоспособности 1/11. Хотя гарантия планирования лишь ~9% от оптимального числа заданий звучит как слабая гарантия, это гарантия наихудшего случая, которая выполняется даже в самых неблагоприятных ситуациях.
Заключение и дальнейшие направления
По мере того как облачная инфраструктура становится все более динамичной, предположение о статической пропускной способности в алгоритмах планирования перестает быть верным. В данной статье начинается формальное исследование максимизации пропускной способности при изменяющейся во времени пропускной способности, что позволяет преодолеть разрыв между теоретическими моделями планирования и изменчивой реальностью центров обработки данных.
Хотя мы и устанавливаем надежные приближения постоянного коэффициента, потенциал для роста все еще существует. Разрыв между нашим коэффициентом конкурентоспособности 1/11 для онлайн-среды и теоретической верхней границей 1/2 предполагает, что могут существовать более эффективные алгоритмы. Изучение рандомизированных алгоритмов или сценариев с неполным знанием будущих мощностей может дать еще лучшие результаты для реальных приложений.
Благодарности
Это результат совместной работы с Аникетом Мурхекаром (Иллинойский университет в Урбана-Шампейн), Зоей Свиткиной (Google Research), Эриком Ви (Google Research) и Джошуа Ваном (Google Research).
Источник: research.google
Оцените материал:
