От необработанных данных к классам риска
Практическое руководство по категоризации в кредитном скоринге
Делиться

Что если ваша модель оценки кредитоспособности потерпит неудачу не из-за слабости алгоритма, а из-за того, что переменные были подготовлены таким образом, что модель не сможет их корректно обработать?
В моделировании кредитного риска мы часто сосредотачиваемся на выборе модели, показателях эффективности, выборе признаков или валидации. Но прежде чем оценивать какой-либо коэффициент, следует обратить внимание на другой вопрос: как каждая переменная должна быть включена в модель?
Исходные данные переменной не всегда наилучшим образом отражают риск.
Непрерывная переменная может иметь нелинейную зависимость от значения по умолчанию. Категориальная переменная может содержать слишком много модальностей. Некоторые переменные могут включать выбросы, пропущенные значения, нестабильные распределения или категории с очень малым количеством наблюдений. Если эти проблемы игнорировать, модель может стать нестабильной, сложной для интерпретации и менее надежной в производственной среде.
Именно здесь категоризация приобретает важное значение.
Категоризация, также называемая грубой классификацией , группировкой , классификацией или разбиением на группы , заключается в преобразовании исходных значений переменных в меньшее количество осмысленных групп. В кредитном скоринге эти группы создаются не только для удобства. Они создаются для того, чтобы сделать взаимосвязь между переменной и риском дефолта более ясной, стабильной и простой в использовании в модели.
Этот шаг особенно полезен, когда итоговая модель представляет собой логистическую регрессию , которая по-прежнему широко используется в кредитном скоринге, поскольку она прозрачна, поддается интерпретации и легко преобразуется в скоринговую таблицу.
Для категориальных переменных категоризация помогает сократить количество модальностей. Для непрерывных переменных она помогает выявить нелинейные закономерности риска, уменьшить влияние выбросов, обработать пропущенные значения, улучшить интерпретируемость и подготовить переменные к преобразованию методом «веса доказательств».
В этой статье мы рассмотрим, почему категоризация является важным этапом в кредитном скоринге и как ее можно использовать для преобразования исходных переменных в стабильные классы риска.
В разделе 1 мы объясняем, почему категоризация полезна как для категориальных, так и для непрерывных переменных, особенно в контексте логистической регрессии.
В разделе 2 мы покажем, как анализировать взаимосвязь между непрерывными переменными и риском дефолта с помощью графического анализа монотонности.
В разделе 3 мы представляем основные методы категоризации, включая группировку с равными интервалами, группировку с равной частотой, группировку на основе критерия хи-квадрат и группировку на основе веса доказательств.
Наконец, в разделе 4 мы сосредоточимся на дискретизации непрерывных переменных с использованием метода «веса доказательств» и покажем, как этот подход помогает подготовить переменные для интерпретируемой модели кредитного скоринга.
1. Почему категоризация важна в кредитном скоринге
При построении модели кредитного скоринга переменные могут быть как категориальными, так и непрерывными.
Категоризация может быть полезна для обоих типов переменных, но мотивация для этого различна.
В случае категориальных переменных основная цель часто состоит в сокращении количества модальностей и группировке категорий со схожим рискованным поведением.
Для непрерывных переменных цель обычно состоит в преобразовании исходной числовой шкалы в меньшее число упорядоченных классов риска.
В обоих случаях цель одна и та же: создать переменные, которые являются статистически значимыми, экономически обоснованными и стабильными во времени.
1.1 Категоризация уменьшает размерность
Начнём с категориальных переменных.
Предположим, у нас есть переменная под названием industry_sector , и эта переменная принимает 50 различных значений.
Если мы используем эту переменную непосредственно в модели логистической регрессии, нам необходимо создать фиктивные переменные.
Вследствие коллинеарности, в качестве эталонной категории необходимо использовать одну из них. Следовательно, для 50 категорий нам потребуется:
50−1=49 фиктивных переменных.
Это означает, что модель должна оценить 49 параметров всего для одной переменной.
Это может быстро стать проблемой.
Категориальная переменная со слишком большим количеством модальностей может привести к нестабильным коэффициентам, переобучению, низкой устойчивости, трудностям в интерпретации и большей сложности при мониторинге.
Группируя схожие категории, мы сокращаем количество параметров, которые необходимо оценить.
Например, вместо того чтобы оставлять 50 отраслевых секторов, мы можем сгруппировать их в 5 или 6 классов риска. Эти группы могут быть основаны на наблюдаемых показателях дефолта, экспертных знаниях в бизнесе, ограничениях размера выборки или на сочетании этих критериев.
В результате получается модель, которая более компактна, стабильна и проще для интерпретации.
Таким образом, одним из первых преимуществ категоризации является уменьшение размерности .
1. 2. Категоризация помогает выявить нелинейные закономерности риска.
Для непрерывных переменных категоризация также может быть очень полезна.
Но прежде чем решать, следует ли классифицировать непрерывную переменную, нам следует сначала понять ее связь с риском дефолта.
Очень простой способ сделать это — построить график зависимости уровня дефолтов от переменной.
Например, если у нас есть непрерывная переменная, такая как person income , мы можем разделить ее на несколько интервалов и рассчитать уровень неплатежей в каждом интервале.
Затем мы строим график:
- Сгруппированные значения переменной по оси x,
- По оси Y отложена ставка дефолта.
Это позволяет нам визуально оценить структуру риска.
Если зависимость монотонна, то переменная уже имеет четко выраженное направление риска.
Например:
- По мере роста доходов уровень неплатежей снижается.
- По мере повышения процентной ставки по кредиту увеличивается и уровень невозврата кредитов.
В данном случае взаимосвязь легко понять.
Однако, если взаимосвязь немонотонная, ситуация усложняется.
Предположим, риск дефолта снижается при низком и среднем уровне дохода, но затем снова возрастает при очень высоком уровне дохода. Простая модель логистической регрессии может некорректно отразить эту закономерность, поскольку она оценивает линейный эффект между переменной и логарифмом отношения шансов дефолта.
Модель логистической регрессии имеет следующий вид:
log(P(Y=1|X)1−P(Y=1|X))=β0+β1Xlog left( frac{P(Y = 1 mid X)}{1 – P(Y = 1 mid X)} right) = beta_0 + beta_1 X
где Y=1 обозначает значение по умолчанию, а X — объясняющая переменная.
Это уравнение означает, что модель предполагает линейную зависимость между X и логарифмом вероятности дефолта.
Если влияние фактора X не является линейным, модель может упустить важную часть структуры риска.
Нелинейные модели, такие как нейронные сети, деревья решений, градиентный бустинг или машины опорных векторов, могут естественным образом воспроизводить сложные взаимосвязи.
Однако в системах кредитного скоринга логистическая регрессия по-прежнему широко используется, поскольку она проста, прозрачна и легко объяснима.
Разделив непрерывные переменные на группы риска, мы можем внести часть нелинейности в линейную модель.
Это одна из важнейших причин, почему группировка данных по группам так распространена в моделях оценки.
1.3. Категоризация снижает влияние выбросов.
Еще одно важное преимущество категоризации — это управление выбросами.
Непрерывные переменные часто содержат экстремальные значения.
Например:
- очень высокий доход,
- чрезвычайно крупные суммы кредитов,
- необычная продолжительность работы
- аномально высокие коэффициенты использования кредита.
Если эти значения используются непосредственно в логистической регрессии, они могут оказать сильное влияние на оцениваемые коэффициенты.
При классификации переменной выбросы помещаются в определенную ячейку.
Например, все значения дохода, превышающие определенный порог, могут быть объединены в одну категорию.
Это уменьшает влияние экстремальных наблюдений и делает модель более устойчивой.
Вместо того чтобы позволять экстремальному значению сильно влиять на модель, мы используем только информацию о риске, содержащуюся в соответствующей группе.
1.4. Категоризация помогает справиться с отсутствующими значениями.
Пропущенные значения очень часто встречаются в наборах данных для оценки кредитоспособности.
Клиент не имеет права предоставлять информацию о своих доходах.
Возможно, не указана продолжительность трудовой деятельности.
Переменная, отражающая кредитную историю, может быть недоступна.
Один из способов обработки пропущенных значений — создание для них отдельной категории.
Это позволяет модели изучать специфическое поведение отдельных особей с отсутствующими значениями.
Это очень важно, потому что пропущенные данные не всегда случайны.
В системе кредитного скоринга отсутствующее значение само по себе может содержать информацию о риске.
Например, клиенты, которые не сообщают о своих доходах, могут демонстрировать иное поведение по умолчанию по сравнению с клиентами, которые предоставляют информацию о своих доходах.
Создав категорию отсутствующих данных, мы позволяем модели учитывать это поведение.
1.5 Категоризация улучшает интерпретируемость
Интерпретируемость — одно из важнейших требований при оценке кредитоспособности.
Модель кредитного скоринга — это не просто «черный ящик» для прогнозирования.
Его часто используют:
- аналитики рисков,
- кредитные специалисты,
- группы проверки моделей,
- регулирующие органы,
- Лица, принимающие деловые решения.
Когда переменные классифицируются, модель становится гораздо проще объяснить.
Например, вместо того чтобы сказать:
Увеличение процентной ставки по кредиту на одну единицу повышает логарифм вероятности дефолта на определенную величину.
Можно сказать:
У клиентов с процентной ставкой выше 15% риск неплатежеспособности значительно выше, чем у клиентов с процентной ставкой ниже 10%.
Такая интерпретация более интуитивна.
Также это проще перевести в баллы по системе подсчета очков.
1.6. Категоризация повышает стабильность модели.
Хорошая модель кредитного скоринга должна не только хорошо работать на этапе разработки.
Он также должен оставаться стабильным в процессе производства.
Категоризация помогает сделать переменные менее чувствительными к небольшим изменениям в данных.
Например, если доход клиента незначительно изменится с 2990 до 3010, то и исходное числовое значение изменится.
Но если оба значения относятся к одной и той же категории дохода, то категоризированное значение остается тем же.
Это делает модель более стабильной с течением времени.
Категоризация также очень полезна для мониторинга.
После группировки переменных по классам мы можем легко отслеживать их распределение в процессе производства и сравнивать его с выборкой для разработки, используя такие показатели, как Индекс стабильности популяции.
Подводя итог первой части, следует отметить, что мы классифицируем переменные главным образом для уменьшения размерности, выявления нелинейных закономерностей риска, обработки пропущенных значений и выбросов, улучшения интерпретируемости и стабильности.
2. Графический анализ монотонности перед группировкой
Прежде чем классифицировать непрерывную переменную, необходимо понять ее взаимосвязь с уровнем неплатежей.
Этот шаг важен, потому что категоризация не должна быть произвольной.
Цель состоит не только в создании контейнеров. Цель состоит в создании контейнеров, которые имеют смысл с точки зрения оценки рисков.
Правильная сортировка по контейнерам должна отвечать на следующие вопросы:
- Существует ли четкая взаимосвязь между этой переменной и риском дефолта?
- Соотношение усиливается или ослабевает?
- Является ли эта зависимость монотонной или немонотонной?
Чтобы ответить на эти вопросы, начнём с графического анализа монотонности.
Переменная является монотонной по отношению к риску дефолта, если уровень дефолта изменяется в одном направлении при увеличении этой переменной.
Например, если доход увеличивается, а риск неплатежеспособности уменьшается, то зависимость является монотонно убывающей.
Если процентная ставка повышается, а риск дефолта возрастает, то эта зависимость является монотонно возрастающей.
Монотонность важна в кредитном скоринге, поскольку она упрощает интерпретацию модели.
Монотонная переменная имеет четкое значение, связанное с риском.
Например:
- Более высокий доход означает меньший риск.
- Более высокая кредитная нагрузка означает более высокий риск.
- Более высокая процентная ставка означает более высокий риск.
- Чем дольше стаж работы, тем ниже риск.
Эти взаимосвязи легко объяснить, и они, как правило, соответствуют деловой интуиции.
Однако, если зависимость не является монотонной, переменная может потребовать более тщательного анализа.
Немонотонный паттерн может указывать на следующее:
- реальный нелинейный эффект риска,
- зашумленные данные,
- редкие интервалы,
- выбросы,
- взаимодействие с другими переменными,
- нестабильность в разных наборах данных.
Вот почему перед тем, как решать, как распределить переменную по группам, всегда следует изучать кривую уровня дефолта.
2.1 Равноинтервальное бинарное разбиение для визуальной диагностики
Простой первый подход заключается в разделении переменной на интервалы равной ширины. Это называется интервальным разбиением на равные интервалы .
Предположим, переменная принимает следующие значения:
1000, 1200, 1300, 1400, 1800, 2000
Минимальное значение — 1000, максимальное — 2000.
Если мы хотим создать два контейнера одинаковой ширины, то ширина будет следующей:
2000–10002=500frac{2000–1000}{2} = 500
Таким образом, получаем:
Bin 1: 1000 to 1500 Bin 2: 1500 to 2000
Затем для каждого интервала мы рассчитываем процент дефолта:
В результате мы получаем таблицу следующего вида:
Затем мы строим график уровня дефолтов по интервалам.
Этот сюжет дает первое представление о структуре взаимоотношений.
Метод разбиения на интервалы с равными значениями прост и понятен. Однако он может создавать интервалы с очень разным количеством наблюдений, особенно когда переменная имеет сильно асимметричное распределение.
По этой причине для исследовательского анализа монотонности часто предпочтительнее использовать группировку по частоте.
2.2 Равночастотное разбиение на интервалы для кривых риска
Метод равномерного частотного разбиения делит переменную на интервалы, содержащие приблизительно одинаковое количество наблюдений.
Например, децильное разбиение на интервалы делит выборку на 10 групп, каждая из которых содержит около 10% наблюдений.
Этот подход полезен, поскольку в каждом интервале достаточно данных для расчета более надежного уровня неплатежей.
В Python это можно сделать с помощью pd.qcut .
Однако важно отметить разницу:
-
pd.cutвыполняет разбиение на интервалы равной ширины; -
pd.qcutвыполняет разбиение на интервалы с одинаковой частотой.
Это различие важно, потому что интерпретация данных по этим категориям не одинакова.
В нашем случае мы используем группировку по частоте для изучения характера изменения непрерывных переменных.
2.3 Набор данных и выбранные переменные
В предыдущих статьях мы выполнили несколько важных шагов на одном и том же наборе данных.
Мы уже это обсудили:
- разведочный анализ данных,
- предварительный отбор переменных,
- анализ устойчивости,
- анализ монотонности во времени,
- Сравнение обучающего, тестового и несинхронизированного наборов данных.
После выполнения этих шагов мы отобрали наиболее релевантные переменные для моделирования.
В данной статье мы сосредоточимся на категоризации непрерывных переменных. Качественные переменные уже имели ограниченное количество модальностей, и, исходя из предыдущего анализа, их стабильность и монотонность были приемлемыми.
Таким образом, наша цель здесь — графически изучить непрерывные переменные, понять их взаимосвязь с риском дефолта и определить соответствующую стратегию дискретизации.
Выбранные непрерывные переменные:
- доход человека
- person_emp_length
- loan_int_rate
- loan_percent_income
2.4 Код на Python для построения кривых процентных ставок по дефолтам
В pandas и scikit-learn нет встроенной функции, которая бы выполняла полную диагностику монотонности кредитного скоринга именно так, как это требуется для моделирования скоринговых карт.
Таким образом, нам необходимо либо самостоятельно запрограммировать эту процедуру, либо использовать специализированную библиотеку для создания оценочных таблиц.
Здесь мы пишем код вручную с помощью pandas и matplotlib .
import pandas as pd import matplotlib.pyplot as plt def plot_default_rate_ax(data, variable, target, bins=10, ax=None): """ Plot default rate by binned numerical variable on a given matplotlib axis. """ df = data[[variable, target]].copy() # Create bins df[f"{variable}_bin"] = pd.qcut( df[variable], q=bins, duplicates="drop" ) # Compute default rate by bin summary = ( df.groupby(f"{variable}_bin", observed=True)[target] .mean() .reset_index() ) # Convert intervals to strings for plotting summary[f"{variable}_bin"] = summary[f"{variable}_bin"].astype(str) # Plot ax.plot( summary[f"{variable}_bin"], summary[target], marker="o" ) ax.set_title(f"Default rate by {variable}") ax.set_xlabel(variable) ax.set_ylabel("Default rate") ax.tick_params(axis="x", rotation=45) return ax variables = [ "person_income", "person_emp_length", "loan_int_rate", "loan_percent_income" ] fig, axes = plt.subplots(2, 2, figsize=(16, 10)) axes = axes.flatten() for ax, variable in zip(axes, variables): plot_default_rate_ax( train_imputed, variable=variable, target="def", bins=10, ax=ax ) plt.tight_layout() plt.show()
После построения кривых уровня дефолтов мы можем проанализировать направление риска для каждой переменной.
В случае с person_income, как правило, ожидаем, что уровень невозврата кредита будет снижаться при увеличении дохода.
Это логично, поскольку клиенты с более высоким доходом обычно имеют большую платежеспособность.
Что касается person_emp_length , мы также ожидаем, что уровень неплатежеспособности снизится при увеличении стажа работы.
Более длительный стаж работы может свидетельствовать о большей профессиональной стабильности.
Для loan_int_rate мы ожидаем, что уровень невозврата кредита увеличится при повышении процентной ставки.
Это вполне логично, поскольку более высокие процентные ставки часто связаны с более рискованными заемщиками.
Для loan_percent_income мы ожидаем, что уровень невозврата кредита увеличится, когда сумма кредита станет больше по отношению к доходу.
Этот показатель измеряет бремя кредита по сравнению с доходом заемщика. Более высокое значение обычно означает большее давление при погашении кредита.
Если наблюдаемые кривые подтверждают эти ожидания, то переменные являются согласованными с точки зрения бизнеса.
В нашем случае графический анализ показывает, что выбранные переменные имеют значимые монотонные закономерности.
Уровень невозврата кредитов снижается при увеличении значений person_income и person_emp_length . С другой стороны, уровень невозврата кредитов увеличивается при увеличении значений loan_int_rate и loan_percent_income .
Это именно то, чего мы ожидаем от моделирования кредитного риска.
3. Основные методы категоризации
Как только мы поймем взаимосвязь между каждой непрерывной переменной и уровнем неплатежей, мы сможем определить стратегию категоризации.
Существует множество способов классификации переменной.
Некоторые методы являются простыми и не требуют обучения под наблюдением. В них не используется целевая переменная:
- биннинг с равными интервалами,
- биннинг с равной частотой,
Другие работают под наблюдением. Они используют переменную по умолчанию для создания групп риска:
- Группировка на основе критерия хи-квадрат,
- Группировка на основе совокупности доказательств.
В кредитном скоринге часто предпочтение отдается методам с обучением под наблюдением, поскольку цель состоит не только в разделении переменной на интервалы. Цель состоит в создании интервалов, имеющих смысл с точки зрения риска дефолта.
В этом разделе мы более подробно рассмотрим два метода обучения с учителем.
3.1 Группировка на основе критерия хи-квадрат
Это метод контролируемого группирования. Идея проста. Мы начинаем с множества начальных групп. Затем сравниваем соседние группы. Если две соседние группы имеют схожее поведение по умолчанию, мы объединяем их.
Для двух смежных ячеек i и j мы строим таблицу сопряженности:
Затем мы применяем критерий хи-квадрат.
Критерий хи-квадрат равен:
χ2=∑(O−E)2Echi^2 = sum frac{(O – E)^2}{E}
где:
- O — наблюдаемая частота,
- E — ожидаемая частота при условии независимости.
Нулевая гипотеза звучит так:
H0: Оба контейнера имеют одинаковое распределение по умолчанию.
Альтернативная гипотеза такова:
H1: У двух групп данных разные распределения по умолчанию.
Если оба контейнера имеют схожее поведение по умолчанию, мы можем их объединить.
Процедура повторяется до тех пор, пока не будет получено меньшее количество стабильных классов.
Преимущество этого метода заключается в том, что он использует переменную по умолчанию напрямую.
Таким образом, итоговые группы в большей степени соответствуют уровню риска.
Однако этот метод следует применять с осторожностью.
При очень больших выборках небольшие различия могут стать статистически значимыми. При очень малых выборках тест может быть ненадежным.
Именно поэтому статистическая группировка всегда должна сочетаться с деловой стратегией.
3.2 Вес группировки, основанной на доказательствах
Еще один очень распространенный метод в кредитном скоринге основан на показателе «веса доказательств», также называемом WoE. WoE измеряет относительное распределение событий и несобытий в каждой категории.
В данной статье мы определяем:
- Плохо = значение по умолчанию (def = 1) = События
- Хорошо = не по умолчанию (по умолчанию = 0) = Не события
Для заданной категории i значение WoE определяется следующим образом:
WoE=ln(%Events%NonEvents)WoE = ln left( frac{%Events}{%NonEvents} right)
При соблюдении этой конвенции:
- Положительное значение WoE означает более высокую концентрацию событий/дефолтов;
- Отрицательный показатель WoE означает более высокую концентрацию неблагоприятных событий/хороших результатов.
- Если значение WoE близко к нулю, то уровень риска для этого сектора близок к среднему уровню риска для населения.
Группировка на основе WoE заключается в объединении смежных групп с похожими значениями WoE. Цель состоит в создании стабильных групп с четким порядком рисков.
На практике процедура обычно начинается с разделения непрерывных переменных на первоначальные точные интервалы, часто с использованием интервалов равной частоты. Затем смежные интервалы постепенно объединяются, когда их значения WoE близки или когда один из них не обеспечивает достаточной дифференциации риска.
Идея заключается не только в сокращении количества классов. Идея состоит в создании классов, которые предоставляют полезную информацию о рисках.
Например, если значение WoE для ячейки очень близко к нулю, это может не обеспечивать достаточной дифференциации. В этом случае ее иногда можно объединить с соседней ячейкой, при условии, что такое объединение остается согласованным с точки зрения бизнеса и рисков.
Для максимальной дифференциации рисков между конечными классами также полезно убедиться, что показатели дефолта достаточно разнесены. Практическое правило заключается в поддержании относительной разницы в риске между соседними классами на уровне не менее 30%, при этом обеспечивая, чтобы каждый конечный класс содержал не менее 1% населения.
Эти пороговые значения не следует применять механически, но они обеспечивают полезные гарантии:
- Избегайте создания слишком маленьких классов;
- избегайте сохранения классов с практически одинаковым уровнем риска;
- избегайте переобучения на выборке для разработки;
- Сохраните итоговую группировку в интерпретируемом и стабильном виде.
Этот метод особенно полезен, когда итоговая модель представляет собой логистическую регрессию, поскольку переменные, преобразованные с помощью WoE, хорошо согласуются со структурой логарифмических шансов модели.
4. Реализация категоризации на основе WoE на Python.
Теперь перейдём к реализации на Python.
Цель состоит в создании простой и прозрачной системы для анализа переменных, сгруппированных по категориям, и поддержки принятия окончательного решения о категоризации.
Нам нужны три основных инструмента.
Первый инструмент вычисляет значение WoE для переменной, заданной заданным числом интервалов.
Второй инструмент суммирует количество наблюдений и процент неплатежей для каждого дискретизированного класса.
Третий инструмент анализирует динамику уровня дефолтов по классам с течением времени. Это поможет нам оценить как монотонность, так и стабильность.
Это важно, потому что группировка данных неэффективна только на обучающей выборке. Она также должна оставаться стабильной с течением времени и на разных наборах данных для моделирования, таких как обучающая, тестовая и выборки, полученные вне временного интервала.
Иными словами, хорошая категоризация должна удовлетворять трём условиям:
- Это должно быть статистически значимо;
- Она должна быть согласованной с точки зрения кредитного риска.
- Оно должно быть стабильным с течением времени.
def iv_woe(data, target, bins=5, show_woe=False, epsilon=1e-16): """ Compute the Information Value (IV) and Weight of Evidence (WoE) for all explanatory variables in a dataset. Numerical variables with more than 10 unique values are first discretized into quantile-based bins. Categorical variables and numerical variables with few unique values are used as they are. Parameters ---------- data : pandas DataFrame Input dataset containing the explanatory variables and the target. target : str Name of the binary target variable. The target should be coded as 1 for event/default and 0 for non-event/non-default. bins : int, default=5 Number of quantile bins used to discretize continuous variables. show_woe : bool, default=False If True, display the detailed WoE table for each variable. epsilon : float, default=1e-16 Small value used to avoid division by zero and log(0). Returns ------- newDF : pandas DataFrame Summary table containing the Information Value of each variable. woeDF : pandas DataFrame Detailed WoE table for all variables and all groups. """ # Initialize output DataFrames newDF = pd.DataFrame() woeDF = pd.DataFrame() # Get all column names cols = data.columns # Run WoE and IV calculation on all explanatory variables for ivars in cols[~cols.isin([target])]: # If the variable is numerical and has many unique values, # discretize it into quantile-based bins if (data[ivars].dtype.kind in "bifc") and (len(np.unique(data[ivars].dropna())) > 10): binned_x = pd.qcut( data[ivars], bins, duplicates="drop" ) d0 = pd.DataFrame({ "x": binned_x, "y": data[target] }) # Otherwise, use the variable as it is else: d0 = pd.DataFrame({ "x": data[ivars], "y": data[target] }) # Compute the number of observations and events in each group d = ( d0.groupby("x", as_index=False, observed=True) .agg({"y": ["count", "sum"]}) ) # Rename columns d.columns = ["Cutoff", "N", "Events"] # Compute the percentage of events in each group d["% of Events"] = ( np.maximum(d["Events"], epsilon) / (d["Events"].sum() + epsilon) ) # Compute the number of non-events in each group d["Non-Events"] = d["N"] - d["Events"] # Compute the percentage of non-events in each group d["% of Non-Events"] = ( np.maximum(d["Non-Events"], epsilon) / (d["Non-Events"].sum() + epsilon) ) # Compute Weight of Evidence # Here, WoE is defined as log(%Events / %Non-Events) # With this convention, positive WoE indicates higher default/event risk d["WoE"] = np.log( d["% of Events"] / d["% of Non-Events"] ) # Compute the IV contribution of each group d["IV"] = d["WoE"] * ( d["% of Events"] - d["% of Non-Events"] ) # Add the variable name to the detailed table d.insert( loc=0, column="Variable", value=ivars ) # Print the global Information Value of the variable print("=" * 30 + "n") print( "Information Value of variable " + ivars + " is " + str(round(d["IV"].sum(), 6)) ) # Store the global IV of the variable temp = pd.DataFrame( { "Variable": [ivars], "IV": [d["IV"].sum()] }, columns=["Variable", "IV"] ) newDF = pd.concat([newDF, temp], axis=0) woeDF = pd.concat([woeDF, d], axis=0) # Display the detailed WoE table if requested if show_woe: print(d) return newDF, woeDF def tx_rsq_par_var(df, categ_vars, date, target, cols=2, sharey=False): """ Generate a grid of line charts showing the average event rate by category over time for a list of categorical variables. Parameters ---------- df : pandas DataFrame Input dataset. categ_vars : list of str List of categorical variables to analyze. date : str Name of the date or time-period column. target : str Name of the binary target variable. The target should be coded as 1 for event/default and 0 otherwise. cols : int, default=2 Number of columns in the subplot grid. sharey : bool, default=False Whether all subplots should share the same y-axis scale. Returns ------- None The function displays the plots directly. """ # Work on a copy to avoid modifying the original DataFrame df = df.copy() # Check whether all required columns are present in the DataFrame missing_cols = [col for col in [date] + categ_vars if col not in df.columns] if missing_cols: raise KeyError( f"The following columns are missing from the DataFrame: {missing_cols}" ) # Remove rows with missing values in the date column or categorical variables df = df.dropna(subset=[date] + categ_vars) # Determine the number of variables and the required number of subplot rows num_vars = len(categ_vars) rows = math.ceil(num_vars / cols) # Create the subplot grid fig, axes = plt.subplots( rows, cols, figsize=(cols * 6, rows * 4), sharex=False, sharey=sharey ) # Flatten the axes array to make iteration easier axes = axes.flatten() # Loop over each categorical variable and create one plot per variable for i, categ_var in enumerate(categ_vars): # Compute the average target value by date and category df_times_series = ( df.groupby([date, categ_var])[target] .mean() .reset_index() ) # Reshape the data so that each category becomes one line in the plot df_pivot = df_times_series.pivot( index=date, columns=categ_var, values=target ) # Select the axis corresponding to the current variable ax = axes[i] # Plot one line per category for category in df_pivot.columns: ax.plot( df_pivot.index, df_pivot[category], label=str(category).strip() ) # Set chart title and axis labels ax.set_title(f"{categ_var.strip()}") ax.set_xlabel("Date") ax.set_ylabel("Default rate (%)") # Adjust the legend depending on the number of categories if len(df_pivot.columns) > 10: ax.legend( title="Categories", fontsize="x-small", loc="upper left", ncol=2 ) else: ax.legend( title="Categories", fontsize="small", loc="upper left" ) # Remove unused subplot axes when the grid is larger than the number of variables for j in range(i + 1, len(axes)): fig.delaxes(axes[j]) # Add a global title to the figure fig.suptitle( "Default Rate by Categorical Variable", fontsize=10, x=0.5, y=1.02, ha="center" ) # Adjust layout to avoid overlapping elements plt.tight_layout() # Display the final figure plt.show() def combined_barplot_lineplot(df, cat_vars, cible, cols=2): """ Generate a grid of combined bar plots and line plots for a list of categorical variables. For each categorical variable: - the bar plot shows the relative frequency of each category; - the line plot shows the average target rate for each category. Parameters ---------- df : pandas DataFrame Input dataset. cat_vars : list of str List of categorical variables to analyze. cible : str Name of the binary target variable. The target should be coded as 1 for event/default and 0 otherwise. cols : int, default=2 Number of columns in the subplot grid. Returns ------- None The function displays the plots directly. """ # Count the number of categorical variables to plot num_vars = len(cat_vars) # Compute the number of rows needed for the subplot grid rows = math.ceil(num_vars / cols) # Create the subplot grid fig, axes = plt.subplots( rows, cols, figsize=(cols * 6, rows * 4) ) # Flatten the axes array to make iteration easier axes = axes.flatten() # Loop over each categorical variable for i, cat_col in enumerate(cat_vars): # Select the current subplot axis for the bar plot ax1 = axes[i] # Convert categorical dtype variables to string if needed # This avoids plotting issues with categorical intervals or ordered categories if pd.api.types.is_categorical_dtype(df[cat_col]): df[cat_col] = df[cat_col].astype(str) # Compute the average target rate by category tx_rsq = ( df.groupby([cat_col])[cible] .mean() .reset_index() ) # Compute the relative frequency of each category effectifs = ( df[cat_col] .value_counts(normalize=True) .reset_index() ) # Rename columns for clarity effectifs.columns = [cat_col, "count"] # Merge category frequencies with target rates merged_data = ( effectifs .merge(tx_rsq, on=cat_col) .sort_values(by=cible, ascending=True) ) # Create a secondary y-axis for the line plot ax2 = ax1.twinx() # Plot category frequencies as bars sns.barplot( data=merged_data, x=cat_col, y="count", color="grey", ax=ax1 ) # Plot the average target rate as a line sns.lineplot( data=merged_data, x=cat_col, y=cible, color="red", marker="o", ax=ax2 ) # Set the subplot title and axis labels ax1.set_title(f"{cat_col}") ax1.set_xlabel("") ax1.set_ylabel("Category frequency") ax2.set_ylabel("Risk rate (%)") # Rotate x-axis labels for better readability ax1.tick_params(axis="x", rotation=45) # Remove unused subplot axes if the grid is larger than the number of variables for j in range(i + 1, len(axes)): fig.delaxes(axes[j]) # Add a global title for the full figure fig.suptitle( "Combined Bar Plots and Line Plots for Categorical Variables", fontsize=10, x=0.0, y=1.02, ha="left" ) # Adjust layout to reduce overlapping elements plt.tight_layout() # Display the final figure plt.show() 4.1 Пример с person_income
Применим эту процедуру к переменной person_income .
Первый шаг заключается в выполнении первоначальной дискретизации с использованием WoE. Мы решаем разделить переменную на три класса и вычислить WoE для каждого класса.
Результаты показывают, что WoE является монотонным.
Заемщики с низким доходом, особенно те, чей доход ниже примерно 45 000, имеют положительный показатель WoE (Woen Overseas Entry). Согласно нашей методике, это означает, что у них выше концентрация неплатежей.
Заемщики с более высоким доходом, особенно те, чей доход превышает примерно 71 000, имеют самый низкий показатель WoE (значение вероятности неплатежеспособности). Это указывает на меньшую концентрацию неплатежей.
Этот результат согласуется с интуицией в области кредитного риска: более высокий доход, как правило, связан с большей платежеспособностью и, следовательно, с меньшим риском неплатежа.
Затем мы можем применить эту сегментацию для создания дискретизированной переменной под названием person_income_dis .
Группировка по группам полезна только в том случае, если она остается стабильной.
Переменная может демонстрировать благоприятную модель риска в обучающей выборке, но со временем стать нестабильной.
Именно поэтому мы также анализируем динамику уровня неплатежей по категориям с течением времени:
Также полезно визуализировать для каждой категории следующее:
- доля населения;
- стандартная ставка.
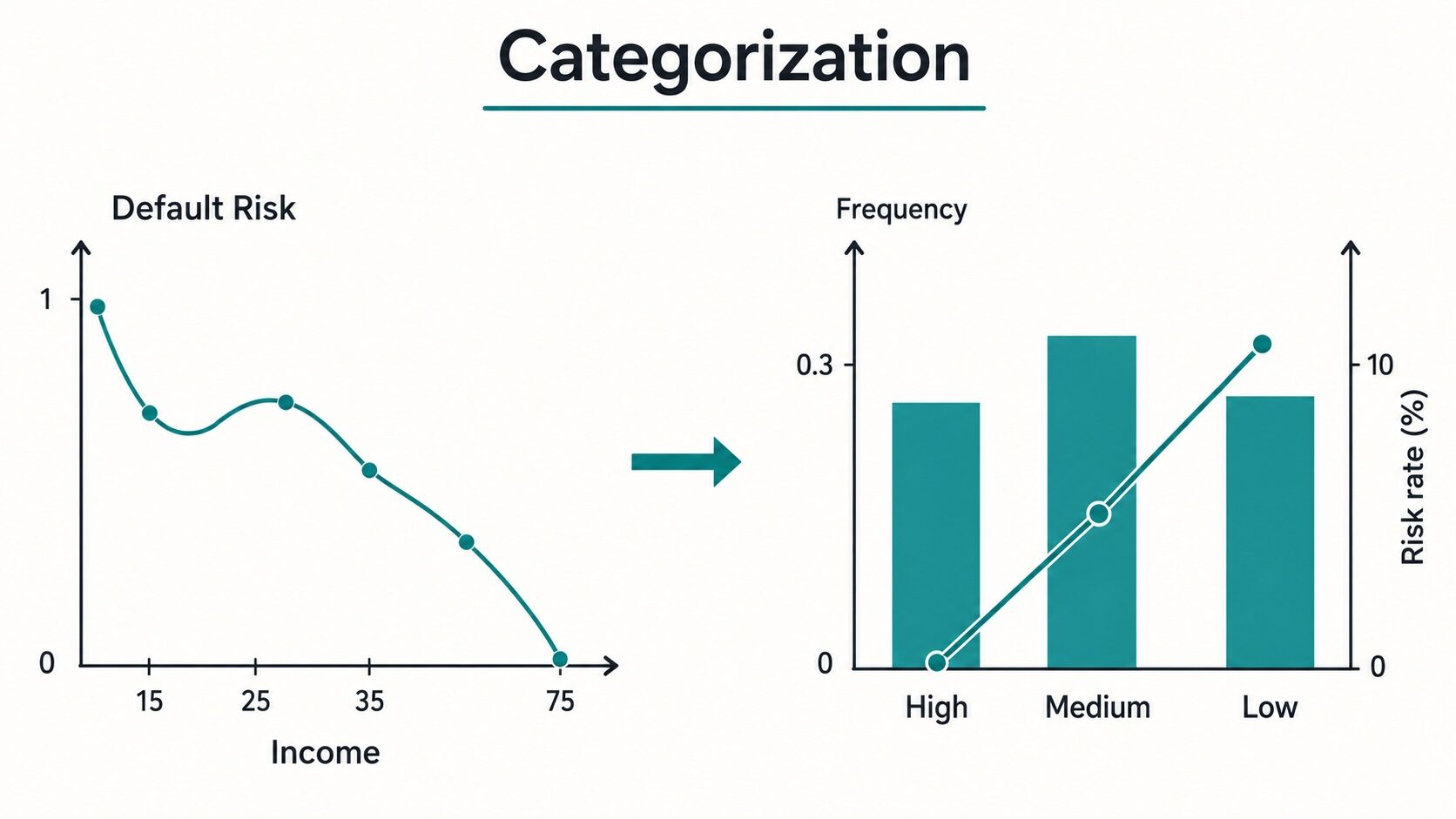
Это можно сделать, используя комбинацию столбчатой диаграммы и линейного графика.
Эта диаграмма полезна, потому что она одновременно отображает два вида информации.
Гистограмма показывает, достаточно ли наблюдений в данной категории.
Линейный график показывает, имеет ли данная категория согласованный уровень дефолтов.
Для качественного окончательного распределения по группам необходимо обеспечить как достаточный размер популяции, так и значимую структуру риска.
Те же самые пороговые значения затем необходимо применить к тестовым данным и данным, полученным вне временной области.
Этот момент важен.
Группировка данных по интервалам должна быть определена для обучающей выборки, а затем применена без изменений к проверочным выборкам. В противном случае мы допускаем утечку данных и снижаем надежность проверки.
Заключение
В этой статье мы изучили, почему категоризация является ключевым этапом в разработке модели кредитного скоринга.
Категоризация применяется как к категориальным, так и к непрерывным переменным.
Для категориальных переменных это помогает уменьшить количество модальностей и упрощает оценку и интерпретацию модели.
Для непрерывных переменных это помогает выявлять нелинейные закономерности риска, уменьшать влияние выбросов, обрабатывать пропущенные значения, повышать стабильность и подготавливать переменные к преобразованию методом взвешенных доказательств.
Мы также обсудили несколько методов категоризации, включая группировку с равными интервалами, группировку с равной частотой, группировку на основе критерия хи-квадрат и группировку на основе совокупности доказательств.
На практике категоризацию не следует рассматривать как механический этап предварительной обработки. Хорошая категоризация должна удовлетворять статистическим, коммерческим требованиям и требованиям стабильности.
Необходимо создать классы, достаточно многочисленные, четко упорядоченные по степени риска, стабильные во времени и легко объяснимые.
Это особенно важно, когда итоговая модель представляет собой оценочную таблицу логистической регрессии. В этом контексте категоризация на основе WoE помогает преобразовать исходные переменные в стабильные классы риска, которые естественным образом соответствуют логарифмической структуре шансов модели.
Главный вывод таков:
Надежность модели кредитного скоринга зависит от качества используемых в ней переменных.
Если переменные содержат шумы, нестабильны, плохо сгруппированы или сложны для интерпретации, даже хороший алгоритм может создать слабую модель.
Но когда переменные тщательно классифицируются, модель становится более надежной, более интерпретируемой и ее легче контролировать в производственной среде.
А как насчет вас? В каких ситуациях вы классифицируете переменные, по каким причинам и используя какие методы?
JUNIOR JUMBONG Посмотреть все товары от JUNIOR JUMBONG
Источник: towardsdatascience.com
Оцените материал:

