Один универсальный инструмент лучше сотни специализированных.
Почему серверы MCP постоянно проигрывают запросам CLI после того, как агент получает доступ к терминалу?
Делиться

В начале 2026 года, если вы хотели, чтобы агент LLM взаимодействовал с системой, по умолчанию устанавливался сервер MCP.
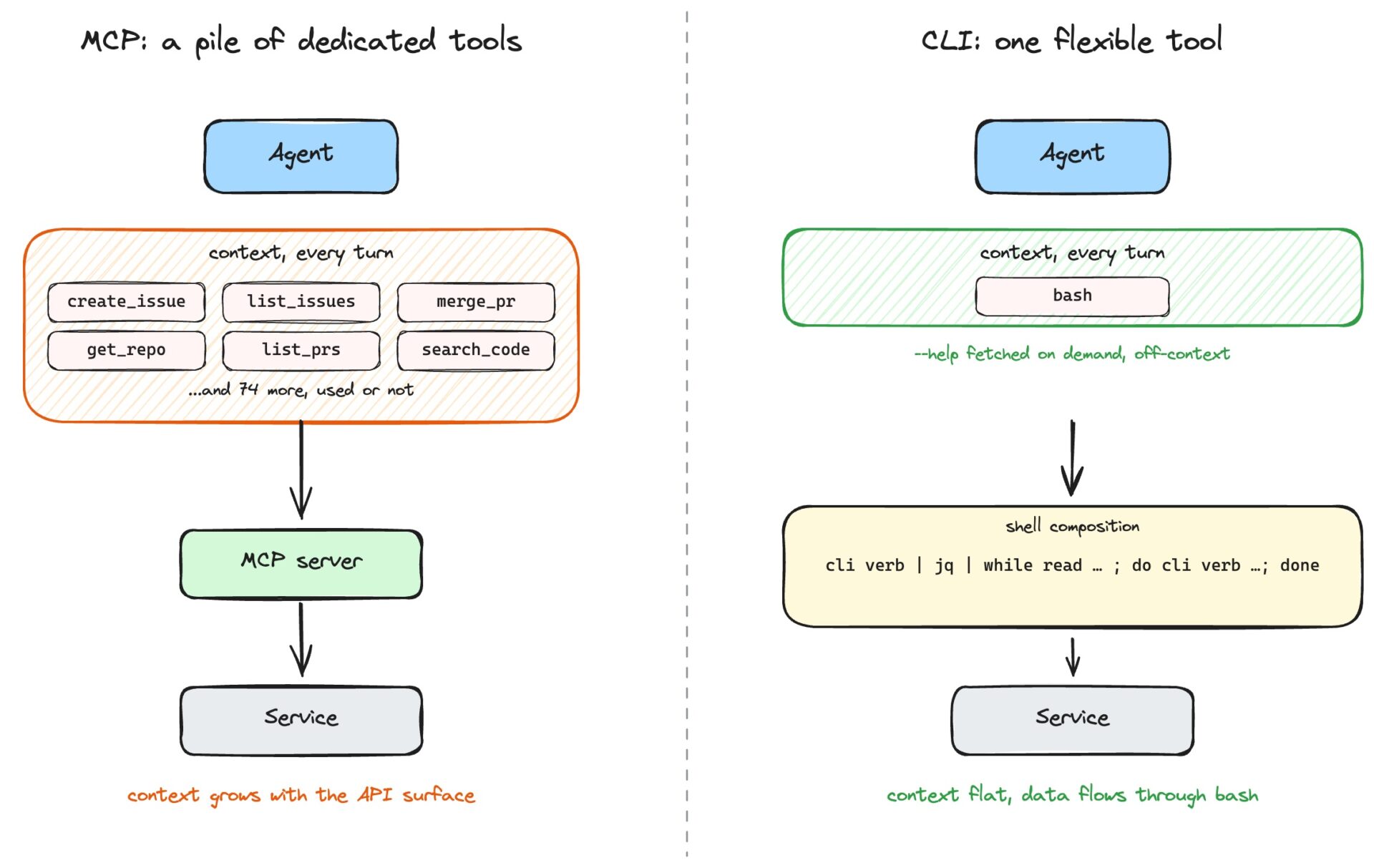
GitHub. Jira. Slack. Linear. Postgres. Neo4j. Каждая из них поставляется с сервером, который предоставляет удобное меню инструментов: create_issue , list_pull_requests , merge_pull_request , get_repository , search_code и так далее, и вы направляете на него свой агент.
Это отличный процесс адаптации. Однако, для удивительно большого количества реальных рабочих задач, это совершенно неподходящая структура.
Основной тезис краток: в проектах MCP каждая служба обычно представлена набором специализированных инструментов; интерфейс командной строки предоставляет агенту один действительно гибкий инструмент. В современных моделях побеждает именно гибкий инструмент.
Две формы инструментов требуют от модели выполнения разных задач. Имея набор специализированных инструментов, агенту достаточно выбрать нужный из меню. С гибким инструментом же ему приходится самостоятельно разбираться, как собрать все части воедино. Раньше именно вторая часть была самой сложной. Модели могли «заблуждаться» относительно флагов, терять нить выполнения в длинных конвейерах, неправильно понимать текст справки, поэтому использование готовых инструментов для каждой операции было разумной защитой. Сейчас это уже не так. Современные модели читают справочную страницу --help ) или файл SKILL.md когда это необходимо, знают канонические CLI из обучения, самостоятельно создают команды bash и повторяют попытку, если неправильно определяют флаг. Сложная часть стала легкой, а легкая всегда оставалась легкой, и все эти аккуратно упакованные инструменты в основном только раздувают контекст модели, не принося никакой пользы.
Конечно, не всё так радужно. Предоставление агенту терминала также значительно увеличивает радиус его поражения. Та же гибкость, которая позволяет ему составлять gh | jq | xargs во что-то полезное, также позволяет внедрению подсказки заставить его сделать нечто гораздо хуже, чем враждебный запрос Cypher. Так что да, есть компромисс, и вам действительно нужно об этом подумать (песочница, список разрешенных пользователей, отдельный пользователь ОС, роль только для чтения в базе данных, обычные вещи).
Но если вы можете предоставить агенту терминал достаточно безопасным способом, то гибкость все равно окажется преимуществом.
В чём преимущества CLI
Та же самая схема «обернуть сервис в виде набора специализированных инструментов» встречается везде, где используется MCP. MCP для PostgreSQL против psql . MCP для Kubernetes против kubectl . MCP для файловых систем против cat , ls , mv , grep объединенных конвейерами. Каждый раз один и тот же инстинкт, каждый раз один и тот же аналог в командной строке. И те же три режима отказа, потому что они на самом деле не связаны с каким-либо одним продуктом.
В спецификации MCP на самом деле нет ничего, что требовало бы такого подхода к созданию множества специализированных инструментов. Протокол запрашивает только типизированные инструменты, и ничего больше; в нем ничего не говорится о том, насколько узкоспециализированным должен быть каждый инструмент. Реализации просто тяготеют к множеству небольших узкоспециализированных инструментов по историческим причинам. Можно создавать гибкие инструменты, которые принимают один выразительный входной сигнал, который агент обрабатывает по своему усмотрению, и в большинстве случаев это, вероятно, следует делать.
Для наглядности рассмотрим пример, в котором сервер Neo4j MCP будет сравниваться с Neo4j CLI.
Сразу оговорюсь: я работаю в Neo4j. Выбор обусловлен лишь удобством, но полученные знания применимы к большинству других CLI.
Сервер Neo4j MCP — это официальный сервер, предоставляющий агентам доступ к Neo4j через MCP, и он включает в себя ряд специализированных инструментов, таких как чтение запросов, запись запросов и получение схемы. neo4j.sh — это официальный интерфейс командной строки для Neo4j, единый исполняемый файл, который запускается в терминале с профилями учетных данных для каждой базы данных, с которой вы взаимодействуете. Чтобы сравнение было корректным, мы будем сравнивать только пару «чтение запроса» и «схема» на стороне MCP с эквивалентным вызовом query в neo4j.sh . Те же операции, та же база данных, тот же Cypher, передаваемый по сети. Единственное изменение заключается в том, обращается ли агент к ним через типизированную схему инструмента или через строку, передаваемую в оболочку.
Выполнение запросов в разных средах
Мы уже видели, как множество специализированных инструментов занимает контекстное окно описаниями, и что некоторые серверы теперь поставляют отложенные инструменты, чтобы перенести эти затраты на потом, когда агент действительно к ним обратится. Но есть второй фактор, о котором никто не говорит: что происходит, когда вы хотите взаимодействовать с несколькими экземплярами одной и той же службы. В MCP количество инструментов растет не только с увеличением функциональности, но и с увеличением количества сред.
Агент запрашивает количество узлов из среды разработки, тестирования и продакшена. С помощью MCP вы развертываете neo4j-mcp-server для каждой среды, и каждый из них переносит свои четыре схемы инструментов в контекст агента на каждом шагу. Три базы данных — это двенадцать схем в окне модели, одни и те же четыре схемы три раза подряд, прежде чем агент что-либо сделает.
В командной строке это цикл for :
$ for c in dev staging prod-ro; do neo4j-cli query -c $c --format toon "MATCH (n) RETURN count(n) AS nodes" done
Один исполняемый файл, три профиля учетных данных, нулевая стоимость контекста за цикл. Добавление четвертой среды — это еще одно credential dbms add , а не еще один процесс сервера MCP. Та же схема применима к любому рабочему процессу «обращения к N аналогичным объектам», который вам может понадобиться: создание снимка производственной среды перед рискованным развертыванием, сравнение схем между тестовой и производственной средами, проверка работоспособности каждой базы данных, о которой знает агент.
Последовательное выполнение запросов
Допустим, агент расследует дело о мошенническом счете: используя одно начальное значение, найти все счета, с которыми он совершал операции, а затем определить, с какими другими счетами эти контрагенты совершали операции чаще всего. Два запроса к одной и той же базе данных, где параметры второго запроса являются результатом первого.
В рамках MCP модель должна выступать в роли канала связи. Она вызывает функцию read-cypher , в результате чего возвращается список, скажем, из 80 идентификаторов контрагентов. Эти 80 идентификаторов теперь находятся в контексте модели, модель форматирует их в параметр для второго вызова read-cypher , и только после этого может выполнить запрос. Промежуточный список дословно повторяет диалог, и каждый дополнительный идентификатор — это еще одна строка контекста, за которую агент платит независимо от того, будет ли он когда-либо читать его снова или нет.
В командной строке символ » | используется в буквальном смысле.
$ neo4j-cli query -c prod-ro --format json --param "seed=acct_19f3" "MATCH (:Account {id: $seed})-[:TRANSACTED]-(c:Account) WHERE c.id <> $seed RETURN collect(DISTINCT c.id) AS counterparties" | neo4j-cli query -c prod-ro --params-from-stdin "MATCH (a:Account)-[:TRANSACTED]-(b:Account) WHERE a.id IN $counterparties AND NOT b.id IN $counterparties + ['acct_19f3'] RETURN b.id, count(DISTINCT a) AS edges_into_cluster ORDER BY edges_into_cluster DESC LIMIT 20"
--params-from-stdin считывает результат JSON предыдущего запроса и передает его в качестве параметра следующему. Список контрагентов никогда не попадает в контекст модели, стоимость токена агента одинакова независимо от того, имеет ли кластер 5 контрагентов или 500.
Здесь оболочка начинает восприниматься как совершенно другой инструмент. Агент больше не выбирает операции из меню, он формирует конвейеры, и промежуточные данные никогда не появляются. Двухэтапный запрос становится оператором | . Разветвление становится циклом for . Объединение двух баз данных становится одним query передаваемым по конвейеру в другую с --params-from-stdin . Каждый из этих случаев потребовал бы трех или четырех обращений к контекстному окну, при этом каждый промежуточный результат передавался бы через контекстное окно, и к этому моменту агент потратил бы больше токенов на перетасовку строк, чем на их обдумывание.
Передача данных между различными интерфейсами командной строки.
Та же проблема, но в большем масштабе. Допустим, агент хочет материализовать недавние задачи проекта на GitHub в Neo4j: узел :Issue для каждого тикета, узел :User для каждого автора, связь :TAGGED для каждой метки. Данные хранятся в одном CLI ( gh ), требуют преобразования ( jq это делает), и попадают в другой CLI ( neo4j-cli ). Три разных инструмента в одной строке. Через MCP вы обращаетесь к серверу MCP GitHub за списком задач, каждое тело задачи попадает в контекст модели, модель извлекает нужные поля, и write-cypher срабатывает один раз для каждой задачи. Сотни обращений к модели, каждое тело задачи остается в диалоге по пути.
Через интерфейс командной строки три программы работают в одном потоке:
$ gh issue list --repo neo4j/neo4j --limit 100 --json number,title,author,labels | jq -c '.[]' | while read issue; do neo4j-cli query --rw -c prod --param "data=$issue" "WITH apoc.convert.fromJsonMap($data) AS i MERGE (n:Issue {number: i.number}) SET n.title = i.title MERGE (u:User {login: i.author.login}) MERGE (u)-[:OPENED]->(n) FOREACH (label IN i.labels | MERGE (l:Label {name: label.name}) MERGE (n)-[:TAGGED]->(l))" done
gh извлекает проблемы, jq преобразует каждую из них в одну строку JSON, а цикл while передает каждую строку в neo4j-cli в качестве параметра Cypher. Модель пишет этот скрипт один раз, а затем переходит к следующему шагу; данные передаются через bash, а не через агента. Независимо от того, сто проблем или десять тысяч, стоимость токена для агента одинакова.
Эта структура хорошо адаптируется не только к GitHub. Замените gh на любой другой CLI, который генерирует JSON ( jira issue list , linear , curl для веб-хука, ваша собственная внутренняя команда dump ), замените шаблон Cypher на любую базу данных, которую вы создаете, и конвейер будет работать. Два инструмента MCP не могут передавать данные друг другу по конвейеру; два CLI могут, и десять тоже.
Управление терминалом обладает мощными возможностями, и в этом-то и загвоздка.
Терминал — это не стационарная поверхность, это самый универсальный инструмент, который можно передать агенту, поскольку он сочетается со всем остальным оборудованием на устройстве.
В этом и заключается подвох. Гибкий инструмент, используемый неправильно, наносит гибкий ущерб. При наличии отличного доступа к терминалу возникает очевидная ответственность: изолировать оболочку, добавить в список разрешенных команд только те действия, которые вам действительно нужны, запускать агента от имени отдельного пользователя ОС, привязывать учетные данные к ролям, которые физически не могут совершить деструктивные действия. Ничего нового в этом нет, это просто правила администрирования системы, применяемые к пользователю с магистерской степенью, который быстро печатает. А если вы ничего из этого сделать не можете, сервер MCP с небольшой фиксированной поверхностью по-прежнему остается правильным решением; гарантия на уровне протокола, что агент не сможет выполнить команду cat ~/.ssh/id_rsa — это реальная вещь.
Основной тезис остается в силе, даже если вы полностью остаетесь внутри MCP. Причина, по которой терминал выигрывает, заключается не в том, что bash особенный, а в том, что bash — это один инструмент с очень гибким вводом. Каналы, переменные, подстановка, циклы. Именно такую структуру стоит перенять. Воспринимайте терминал как предельный случай MCP и проектируйте в соответствии с ним: меньше инструментов, каждый из которых принимает выразительный ввод, агент выполняет компоновку, вместо того чтобы вы заранее предугадывали каждую комбинацию. Большинство серверов MCP представляют собой длинный список узких конечных точек, потому что так уже был устроен базовый API, а не потому, что агент работает лучше таким образом. Серверы, которые хорошо себя зарекомендуют, будут теми, которые намеренно выбрали меньшую, но более выразительную поверхность.
Все изображения в этом посте созданы автором.
Tomaz Bratanic Посмотреть все от Tomaz Bratanic
Источник: towardsdatascience.com
Оцените материал:

