Обучение магистров права рассуждать по принципу байесовского подхода.
Мы обучаем студентов магистратуры байесовскому мышлению, тренируя их имитировать предсказания оптимальной байесовской модели.
Быстрые ссылки
- Бумага
- Делиться
Системы искусственного интеллекта, основанные на больших языковых моделях (БЛМ), все чаще используются в качестве агентов, взаимодействующих с пользователями и окружающим миром. Для успешного выполнения этой задачи БЛМ должны создавать внутренние представления об окружающем мире и оценивать вероятность точности каждого из этих представлений. Возьмем, к примеру, персонализированные рекомендации: БЛМ должна постепенно определять предпочтения пользователя на основе его выбора в ходе многочисленных взаимодействий.
Байесовский вывод определяет оптимальный способ выполнения таких обновлений. Реализуя эту стратегию, LLM-ы могут оптимизировать взаимодействие с пользователем, обновляя свои оценки предпочтений пользователя по мере поступления новой информации о нём. Однако без специального обучения LLM-ы часто по умолчанию используют простые эвристики — например, предполагают, что все хотят самый дешёвый вариант — вместо того, чтобы выводить уникальные предпочтения конкретного пользователя.
В статье «Байесовское обучение позволяет применять вероятностные рассуждения в больших языковых моделях» мы обучаем большие языковые модели рассуждать байесовским методом, тренируя их имитировать предсказания байесовской модели, которая определяет оптимальный способ рассуждения о вероятностях. Мы обнаружили, что этот подход не только значительно улучшает производительность большой языковой модели в конкретной задаче рекомендаций, на которой она обучается, но и позволяет обобщать результаты на другие задачи. Это говорит о том, что данный метод учит большую языковую модель лучше аппроксимировать байесовские рассуждения. В более общем плане, наши результаты показывают, что большие языковые модели могут эффективно усваивать навыки рассуждения на примерах и обобщать эти навыки на новые области.
Оценка байесовских возможностей программ магистратуры в области права
Как и в случае с людьми, для эффективного взаимодействия LLM с пользователем требуется постоянное обновление вероятностных оценок предпочтений пользователя на основе каждого нового взаимодействия. Здесь мы задаемся вопросом: действуют ли LLM так, как если бы их вероятностные оценки обновлялись в соответствии с ожиданиями, основанными на оптимальном байесовском выводе? В какой степени поведение LLM отклоняется от оптимальной байесовской стратегии, как мы можем минимизировать эти отклонения?
Для проверки этого предположения мы использовали упрощенную задачу по подбору рейсов, в которой LLM-ы взаимодействуют в качестве помощников с имитированным пользователем в течение пяти раундов. В каждом раунде пользователю и помощнику предлагались три варианта рейсов. Каждый рейс определялся временем отправления, продолжительностью, количеством пересадок и стоимостью. Каждый имитированный пользователь характеризовался набором предпочтений: для каждой характеристики он мог иметь сильное или слабое предпочтение высоким или низким значениям характеристики (например, он мог предпочитать более длинные или более короткие рейсы) или не иметь предпочтений в отношении этой характеристики.
Мы сравнили поведение моделей LLM с поведением модели, байесовского помощника , которая следует оптимальной байесовской стратегии. Эта модель поддерживает распределение вероятностей, отражающее ее оценки предпочтений пользователя, и использует правило Байеса для обновления этого распределения по мере поступления новой информации о выборе пользователя. В отличие от многих реальных сценариев, где сложно задать и реализовать байесовскую стратегию вычислительными методами, в этой контролируемой среде ее легко реализовать, и это позволяет нам точно оценить, насколько модели LLM отклоняются от нее.
Цель ассистента заключалась в том, чтобы порекомендовать рейс, соответствующий выбору пользователя. В конце каждого раунда пользователь указывал ассистенту, правильно ли он выбрал рейс, и предоставлял ему правильный ответ.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Как байесовский ассистент может обновлять свои оценки предпочтений пользователя в отношении рейсов в ответ на наблюдаемые данные (т.е. выбор пользователя), доступные после каждого раунда. Важно отметить, что ассистент не может напрямую получить доступ к предпочтениям пользователя, что делает эту задачу сложной с точки зрения вероятностного рассуждения.
Мы оценили ряд моделей LLM и обнаружили, что все они показали значительно худшие результаты, чем оптимальный байесовский помощник. Что наиболее важно, в отличие от байесовского помощника, который постепенно улучшал свои рекомендации по мере получения дополнительной информации о выборе пользователя, производительность моделей LLM часто стабилизировалась после одного взаимодействия, что указывает на ограниченную способность адаптироваться к новой информации и демонстрирует ограниченное или полное отсутствие улучшения при многократном взаимодействии с пользователем.
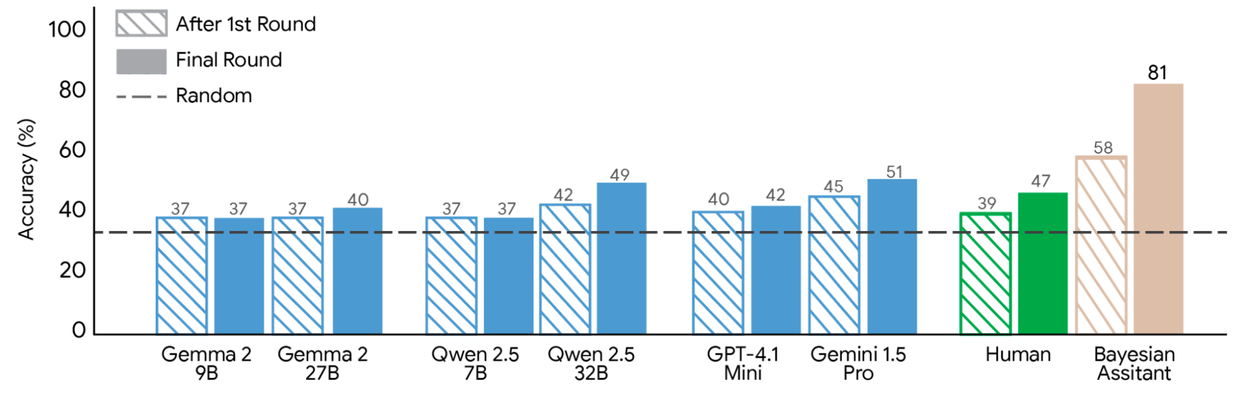
Мы сравнили готовые модели LLM из разных семейств моделей с участием людей и байесовским помощником. Модели LLM показали значительно худшие результаты, чем байесовский помощник. Участники эксперимента продемонстрировали большее улучшение, чем большинство моделей LLM, по мере получения большего объема информации, но все же не достигли точности, характерной для оптимальной байесовской стратегии.

Мы сравнили точность рекомендаций байесовского помощника с рекомендациями человека и различных готовых моделей LLM после первого и заключительного раундов трех наборов взаимодействий с 624 пользователями.
Байесовская педагогическая модель
В байесовской модели агент поддерживает априорное представление о состоянии мира. Для модели с линейной моделью это «состояние мира» представляет собой её внутреннее представление фактов, взаимосвязей и концепций. По мере того, как модель сталкивается с новой информацией (доказательствами), ей необходимо преобразовать своё априорное представление (или «априорное» — первоначальное предположение или вероятность чего-либо до появления новых доказательств) в «апостериорное представление» (обновлённую вероятность после включения новых данных), которое служит новым априорным представлением для следующего доказательства. Этот циклический процесс позволяет агенту постоянно уточнять своё понимание мира.
Задача состоит в том, чтобы научить модель выполнять эти вероятностные обновления. Мы сделали это с помощью контролируемой тонкой настройки, в ходе которой модель обновляла свои параметры на основе большого количества взаимодействий с пользователями, которые она наблюдала.
Мы исследовали две стратегии создания данных для контролируемой тонкой настройки. В первой стратегии, которую мы называем обучением с помощью оракула, мы предоставили модели LLM взаимодействие между смоделированными пользователями и помощником-«оракулом», который обладает полным знанием предпочтений пользователя и, следовательно, всегда рекомендует вариант, идентичный выбору пользователя.
Вторая стратегия, которую мы называем байесовским обучением, предусматривала взаимодействие LLM с байесовским помощником и пользователем. В этой ситуации помощник часто выбирал рейсы, которые не соответствовали предпочтительному выбору пользователя, особенно на ранних этапах, когда существовала значительная неопределенность относительно предпочтений пользователя. Мы предположили, что имитация наилучших предположений байесовского помощника научит LLM поддерживать неопределенность и обновлять свои убеждения более эффективно, чем обучение с помощью оракула, где LLM обучается на правильных вариантах выбора. Этот подход можно рассматривать как форму дистилляции, когда модель обучается путем имитации другой системы.
Результаты
Контролируемая тонкая настройка обучает LLM-ы аппроксимировать вероятностный вывод. Мы исследовали точность после первого и заключительного (пятого) раундов с использованием разных помощников. Мы сравнили исходные LLM-ы, LLM-ы, доработанные на основе взаимодействия пользователя с байесовским помощником, и LLM-ы, доработанные на основе взаимодействия пользователя с оракулом, который всегда давал правильный ответ. Оба типа тонкой настройки значительно улучшили производительность LLM-ов, и байесовское обучение оказалось неизменно более эффективным, чем обучение с использованием оракула.
Тонко настроенные LLM с использованием байесовского обучения лучше согласовывались с байесовским помощником и обобщали результаты за пределами задачи, использованной для тонкой настройки. Мы продемонстрировали согласованность между LLM и байесовским помощником, измеренную долей испытаний, в которых LLM делали те же прогнозы, что и байесовский помощник. Тонкая настройка на основе прогнозов байесовского помощника сделала LLM более байесовскими, при этом байесовские версии каждого LLM достигли наивысшего согласования с байесовским помощником. Мы также рассмотрели точность в последнем раунде для LLM в области веб-шопинга, которая не наблюдалась во время тонкой настройки. Зеленая пунктирная линия на рисунке ниже показывает производительность LLM, когда она была тонко настроена непосредственно на данных веб-шопинга, так что обобщение на предметную область не требовалось, но которое могло быть сложнее получить.
Точность рекомендаций Джеммы и Квен после тонкой настройки на основе взаимодействия пользователей с байесовским помощником или с оракулом.

Доля испытаний, в которых LLM-модели и байесовский помощник сделали одинаковые прогнозы ( слева ), и точность рекомендаций в области веб-шопинга, не наблюдавшаяся во время обучения ( справа ).
Байесовский подход к обучению значительно превзошел подход, основанный на алгоритме Oracle, позволив моделям соответствовать математическим идеалам в 80% случаев. Эти точно настроенные модели развили реалистичную чувствительность к информации, научившись придавать большее значение конкретным решениям пользователя, когда эти решения выявляли более очевидные предпочтения.
Важно отметить, что эти вновь приобретенные навыки не были специфичными для конкретной задачи. Модели, обученные на синтетических данных о полетах, успешно перенесли свою «вероятностную логику» в совершенно другие области, такие как рекомендации отелей и реальные онлайн-покупки. Это говорит о том, что модели с линейной логикой могут усваивать основные принципы байесовского вывода, превращаясь из статических алгоритмов сопоставления шаблонов в адаптивных агентов, способных к междоменному рассуждению.
Что ждет байесовское обучение в будущем?
Мы протестировали ряд моделей LLM и обнаружили, что им сложно формировать и обновлять вероятностные убеждения. Кроме того, мы выяснили, что продолжение обучения моделей LLM посредством взаимодействия между пользователями и байесовским помощником — моделью, реализующей оптимальную стратегию обновления вероятностных убеждений — значительно улучшило способность моделей LLM к аппроксимации вероятностных рассуждений.
Хотя результаты нашего первого эксперимента указывают на ограничения отдельных моделей LLM, положительные результаты последующих экспериментов по тонкой настройке можно рассматривать как демонстрацию силы парадигмы «пост-обучения» моделей LLM в целом. Обучая модели LLM на примерах оптимальной стратегии выполнения задачи, мы смогли значительно улучшить их производительность, что говорит о том, что они научились аппроксимировать вероятностную стратегию рассуждения, иллюстрируемую примерами. Модели LLM смогли обобщить эту стратегию на области, где ее трудно явно закодировать в символической модели, демонстрируя возможности преобразования классической символической модели в нейронную сеть.
Источник: research.google
Оцените материал:
