Нетривиальные сетевые решения, лежащие в основе обучающей архитектуры OpenAI с 131 000 графических процессоров.
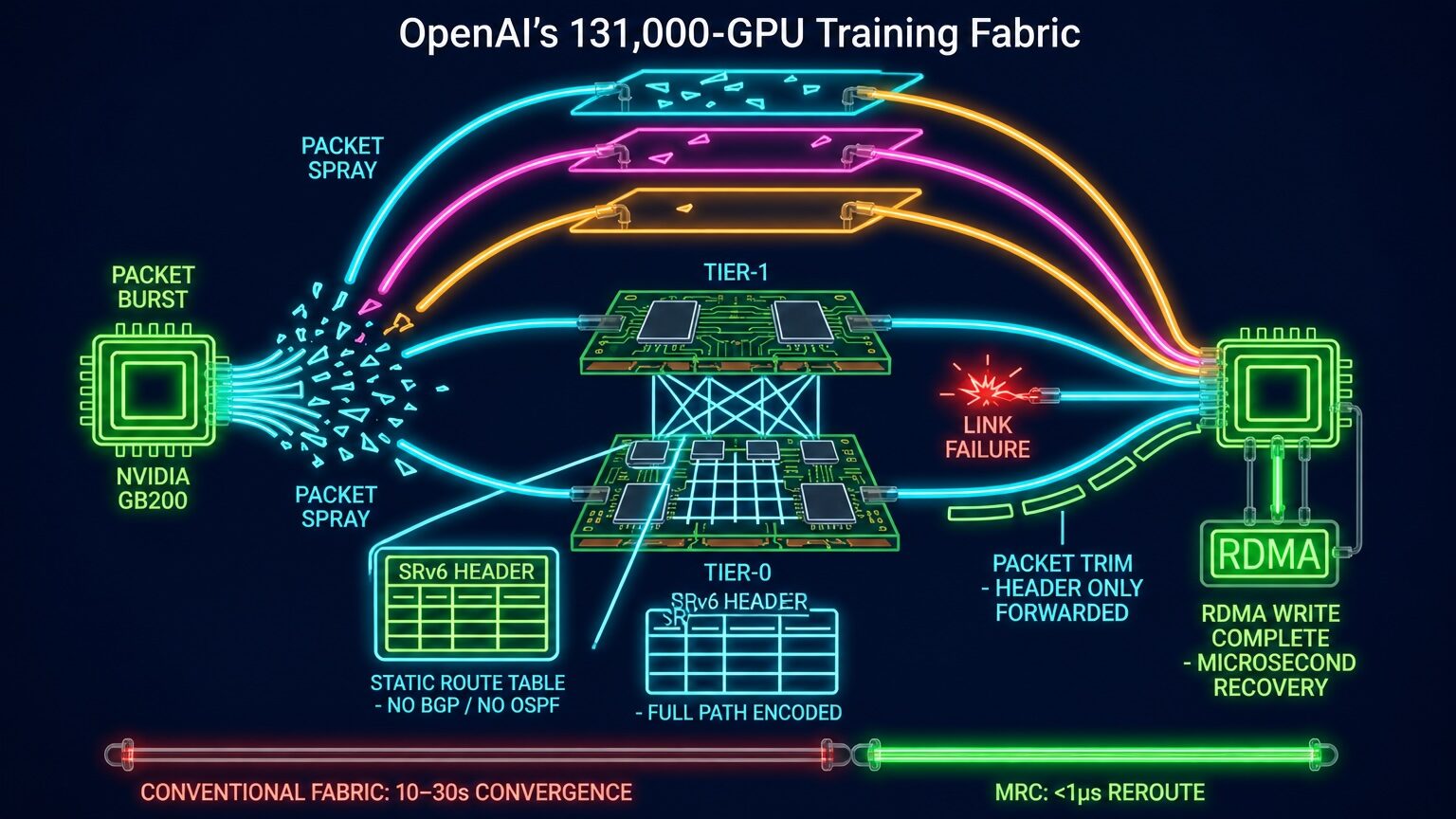
Статические маршруты. Ethernet с потерями. Отсутствие протоколов маршрутизации. Подробности архитектурных решений, обеспечивающих работу обучающей платформы OpenAI с 131 000 графических процессоров. Пять проектных решений, каждое из которых само по себе противоречит интуиции, в совокупности объясняют, как вообще стало возможным синхронное обучение в таком масштабе.
Делиться

Отключите все протоколы маршрутизации. Намеренно смиритесь с потерей пакетов. Распределяйте каждую передачу по сотням случайных путей. Если бы вам вручили этот список проектных решений для сети, соединяющей 131 000 графических процессоров, вы бы предположили, что его написал человек, никогда не работавший в производственной сети.
Консорциум, в состав которого вошли OpenAI, AMD, Broadcom, Intel, Microsoft и NVIDIA, создал именно это — и незаметно перевернул с ног на голову существовавшее три десятилетия мнение о том, как должны работать высокопроизводительные сети центров обработки данных.
Протокол называется MRC, сокращение от Multipath Reliable Connection (многопутевое надежное соединение). Он был выпущен 5 мая 2026 года в рамках проекта Open Compute Project. В сопроводительной исследовательской статье (Araujo et al., 2026) подробно описывается его развертывание на крупнейших суперкомпьютерах NVIDIA GB200 компании OpenAI, включая площадку Stargate с облачной инфраструктурой Oracle в Абилине, штат Техас, и суперкомпьютеры Fairwater компании Microsoft. MRC использовался для обучения новейших моделей, лежащих в основе ChatGPT и Codex.
Наиболее поразительным при внимательном прочтении статьи является то, что не было освещено в прессе: MRC фактически полностью исключает плоскость управления уровня 3 из инфраструктуры центра обработки данных. Нет OSPF. Нет BGP. Нет IS-IS. Нет FIB. Коммутаторы в развертывании поддерживают нулевое состояние динамической пересылки. Насколько известно автору, это наиболее агрессивное исключение динамической маршрутизации в любой производственной среде для обучения ИИ, публично задокументированное на сегодняшний день.
Основной аргумент статьи заключается в том, что при масштабе более 100 000 графических процессоров задержка в конце цепочки событий, вызванная перегрузкой сети и сбоями, доминирует над производительностью обучения, и традиционный сетевой стек не может решить эту проблему без фундаментальных изменений в способе перемещения пакетов между графическими процессорами. MRC — это именно те фундаментальные изменения, реализованные в сетевых картах 800 Гбит/с от трех разных производителей микросхем и внедренные в производство.
Заслуживает пристального изучения MRC не столько скорость, сколько то, что лежащие в его основе проектные решения противоречат нескольким принципам, которые сетевое сообщество считало устоявшимися на протяжении десятилетий. Понимание того, почему эти решения работают в таком масштабе, а где они могут не работать, важно для любого, кто создает или эксплуатирует инфраструктуру искусственного интеллекта.
Слева : обычная схема RoCE с однопутевой маршрутизацией. Перегрузка канала T1 запускает PFC PAUSE, которая распространяется в обратном направлении, блокируя GPU 2, даже если его собственный путь был свободен. Все 100 000 GPU простаивают до завершения передачи данных GPU 2. Справа : MRC распределяет пакеты по 8 независимым плоскостям. При отказе канала на плоскости 2 сетевая карта обнуляет значение энтропии и перераспределяет трафик на оставшиеся 7 плоскостей за микросекунды. Ни один GPU никогда не зависает. Пять пронумерованных проектных решений внизу являются предметом данной статьи.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Каждое из решений MRC по отдельности знакомо любому, кто следил за исследованиями в области сетевых технологий. Радикальным является именно их сочетание. Сетевое сообщество изучало каждую из этих идей по отдельности — многоуровневые сети, маршрутизация от источника, распыление пакетов, передача данных с потерями и выборочной повторной передачей, ECN в качестве сигнала балансировки нагрузки. Что делает MRC достойным тщательного изучения, так это то, что консорциум OpenAI взял на себя обязательство реализовать все эти решения одновременно, в производственной среде с использованием 131 000 графических процессоров.
Проблема: один отстающий блокирует 100 000 графических процессоров.
Синхронное предварительное обучение выполняется синхронно. Каждый этап обучения включает миллионы передач данных между тысячами графических процессоров, использующих комбинацию тензорного параллелизма, конвейерного параллелизма, параллелизма данных и экспертного параллелизма. Этап не может перейти к следующему, пока не завершится самая медленная передача. При 100 000 графических процессоров длительность каждого раунда связи определяется хвостом распределения задержки передачи, а не средним значением.
В статье это четко сформулировано: «По мере масштабирования вычислений связь все больше зависит от выбросов». Один перегруженный канал, одно столкновение потоков, одно переполнение буфера коммутатора могут привести к остановке тысяч графических процессоров на миллисекунды. При почасовой стоимости 100 000 графических процессоров класса H100 (примерно 300 000 долларов в час по облачным тарифам) 10-миллисекундная задержка, которая происходит один раз за шаг обучения и повторяется на протяжении тысяч шагов, — это не ошибка округления. Это статья расходов.
Сбои в сети усугубляют проблему. В таких масштабах сбои в работе каналов связи, отказы оптических устройств и перезагрузки коммутаторов — не редкие события. Это статистически неизбежные явления, происходящие несколько раз в день в сети с сотнями тысяч каналов. В статье описывается производственный инцидент, когда оптический трансивер на коммутаторе T0 «вышел из строя и вызвал сбои во всех четырех своих каналах связи в быстрой последовательности», что одновременно затронуло три активных обучающих узла. В обычной сети это привело бы к сбою процесса обучения.
Целью разработки MRC было не просто увеличение пропускной способности. Речь шла о предсказуемой пропускной способности даже при наличии сбоев, а также о достаточно простой плоскости управления, позволяющей небольшой команде одновременно управлять несколькими суперкомпьютерами.
Топология: 131 000 графических процессоров в двух коммутационных узлах.
Первое проектное решение касается архитектуры, а не протокола. Вместо того чтобы рассматривать сетевую карту 800 Гбит/с как один большой канал, MRC разделяет его на восемь каналов по 100 Гбит/с, каждый из которых подключается к отдельному коммутатору. Это создает восемь параллельных сетевых плоскостей, каждая из которых работает независимо.
Рассмотрим традиционный подход. Самые быстрые коммутаторы Ethernet для центров обработки данных сегодня обеспечивают коммутационную способность 51,2 Тбит/с, что дает 64 порта со скоростью 800 Гбит/с. В стандартной топологии Clos с «толстым деревом» каждый коммутатор уровня 0 (T0) подключается к 32 сетевым картам и до 32 коммутаторам уровня 1 (T1). Каждый коммутатор T1 подключается к 64 узлам (pods). Это дает трехуровневую сеть, поддерживающую примерно 64 000 графических процессоров (GPU) при полной пропускной способности. Для достижения 100 000 требуется четвертый уровень, что увеличивает задержку, стоимость и количество доменов отказов.
Теперь разделим сетевые карты. Тот же коммутатор 51,2 Тбит/с со скоростью 100 Гбит/с на порт дает вам 512 портов вместо 64. Каждый коммутатор T0 подключается к 256 портам сетевых карт и к 256 коммутаторам T1. Каждый коммутатор T1 подключается к 512 коммутаторам T0. Одна двухуровневая плоскость поддерживает 131 072 графических процессора при полной пропускной способности по принципу бисекции.
В статье приводится количественная оценка экономии:
Conventional 3-tier (800 Gb/s): - 3 switch tiers, 64-port switches - Max ~64K GPUs at full bisection BW - 5-hop or 7-hop worst-case path Multi-plane 2-tier (8 × 100 Gb/s): - 2 switch tiers, 512-port switches - 131K GPUs at full bisection BW - 3-hop worst-case path - 2/3 the optics of a 3-tier network - 3/5 the number of switches
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Математические расчеты отказоустойчивости не менее убедительны. Потеря одного канала NIC-to-T0 в одноплоскостной сети 800 Гбит/с обходится в 3% пропускной способности этого NIC. В многоплоскостной сети 100 Гбит/с аналогичный сбой обходится в 0,4%. Что еще важнее, при наличии восьми независимых плоскостей NIC может продолжать работу на оставшихся семи, пока восстанавливается неисправный канал. Процесс обучения не должен останавливаться.
Этот компромисс не дается бесплатно. Восемь отдельных плоскостей означают в восемь раз больше каналов для мониторинга, в восемь раз больше потенциальных точек отказа в совокупности и транспортный протокол, который должен интеллектуально распределять нагрузку между всеми ними. Вот тут-то и вступает в дело MRC.
Распыление пакетов с использованием значений энтропии
Традиционные протоколы RDMA (RoCEv2, InfiniBand RC) привязывают каждое соединение к одному сетевому пути. Путь выбирается путем хеширования пятикомпонентной кортежи потока (IP-адрес источника/назначения, порт источника/назначения, протокол) на каждом коммутаторе. После привязки каждый пакет в этом соединении следует по этому же пути до тех пор, пока соединение не будет разорвано.
Этот метод работает в умеренном масштабе. Он дает сбой при количестве графических процессоров более 100 000 из-за коллизий потоков. Когда два соединения хешируют данные по одному и тому же пути через одно и то же узкое место, страдают оба. Вероятность коллизии возрастает с увеличением масштаба, и влияние на задержку в конце цепочки непропорционально велико.
MRC полностью исключает привязку потоков. Вместо этого, при установлении соединения каждой паре очередей (QP) присваивается набор из 128–256 значений энтропии (EV). Каждое значение EV кодирует определенный путь через определенную плоскость сети. Отправитель последовательно обрабатывает свой набор значений EV пакет за пакетом, распределяя последовательные пакеты по сотням различных путей во всех восьми плоскостях. Никакие два последовательных пакета из одной и той же передачи не проходят по одному и тому же маршруту.
EV — это 32-битное значение, разделенное между исходным UDP-портом и меткой потока IPv6 в каждом MRC-пакете. Коммутаторы хешируют данные по этим полям, поэтому изменение EV меняет путь. Отправителю не нужно знать топологию. Ему нужно знать только то, что разные значения EV приводят к разным путям.
Per-QP state: EV set: 128-256 entropy values (32-bit each) Per-EV health: {active, congested, suspected_failed, confirmed_failed} Packet sending: for each packet in transfer: ev = next_active_ev(qp.ev_set) packet.udp_src_port = ev[0:15] packet.ipv6_flow_label = ev[16:31] send(packet)
Каждый EV содержит несколько битов информации о состоянии работоспособности. Когда приемник обнаруживает перегрузку на пути (посредством маркировки ECN от коммутаторов), он передает эту информацию отправителю, который временно избегает использования данного EV. Если пакет действительно потерян (не обрезан), MRC предполагает, что путь неисправен, и немедленно прекращает использование данного EV. Фоновые проверки периодически проверяют выведенные из эксплуатации EV, чтобы определить, был ли сбой временным, и восстанавливают их, если проверки проходят успешно.
Качество балансировки нагрузки в этой схеме высокое. Поскольку разные отправители независимо генерируют случайные наборы EV, совокупное распределение трафика по путям практически равномерное. Небольшие дисбалансы сглаживаются с помощью обратной связи ECN: если один путь накапливает немного больше трафика, метки ECN на этом пути увеличиваются, и отправители перераспределяют трафик на менее загруженные альтернативы.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Статическая маршрутизация источников с использованием SRv6
Это самое нелогичное решение в статье. В каждой производственной сети центра обработки данных используются динамические протоколы маршрутизации (BGP, OSPF, IS-IS), которые вычисляют таблицы пересылки, реагируют на изменения топологии и обеспечивают сходимость после сбоев. MRC отключает все эти протоколы.
Вместо этого MRC использует сегментную маршрутизацию IPv6 (SRv6) для кодирования полного пути, по которому должен следовать каждый пакет. Отправитель встраивает последовательность идентификаторов коммутаторов непосредственно в адрес назначения пакета. Каждый коммутатор на пути проверяет наличие своего идентификатора, удаляет его путем сдвига адреса и пересылает пакет следующему узлу. Отсутствует поиск в таблице маршрутизации. Отсутствует база информации о пересылке. Отсутствует сходимость плоскости управления.
В статье объясняется логика: «Мы заняли необычную позицию, отключив динамическую маршрутизацию в коммутаторах, потому что не хотели, чтобы два адаптивных механизма маршрутизации взаимодействовали друг с другом, а динамическая маршрутизация ничего не добавляла».
Адаптация транспортного уровня MRC (управление EV, обратная связь ECN, проверка пути) уже обрабатывает сбои в микросекундном масштабе времени. Динамические протоколы маршрутизации сходятся за секунды или минуты. Запуск обоих протоколов создает риск противоречивых решений: MRC избегает сбоя пути на транспортном уровне, пока протокол маршрутизации еще сходится к новому состоянию пересылки, что потенциально может привести к образованию петель или колебаний маршрутизации.
Полностью исключив динамическую маршрутизацию, MRC получает три операционных преимущества:
Во-первых, детерминированная пересылка. Каждый пакет следует по известному, заранее рассчитанному пути. Если что-то пойдет не так, можно точно отследить, через какие коммутаторы прошел пакет. В статье отмечается, что это «обеспечивает очень хорошую наблюдаемость», поскольку путь закодирован в самом пакете.
Во-вторых, устранены сбои сходимости. Динамические протоколы маршрутизации могут вызывать неправильную конфигурацию, зацикливание или разделение сети во время сходимости. При использовании статических маршрутов SRv6 эти режимы сбоев отсутствуют. Коммутаторы являются пересыльщиками пакетов без сохранения состояния.
В-третьих, упрощение операций. В статье подчеркивается, что «очень небольшим группам людей необходимо уметь управлять сетями, состоящими из нескольких суперкомпьютеров». Исключение протоколов маршрутизации устраняет целую категорию операционной сложности, дрейфа конфигурации и проблем с отладкой.
Компромисс заключается в том, что вычисление пути переносится на сетевую карту. Сетевая карта MRC должна обладать достаточными знаниями о топологии, чтобы генерировать допустимые пути SRv6 для своего набора EV. В развертывании OpenAI это обрабатывается во время настройки QP с использованием простой базы данных топологии. Пути являются статическими и предварительно вычисленными. Адаптация во время выполнения происходит на уровне выбора EV, а не на уровне маршрутизации.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Работа с потерями: почему MRC отключает PFC
Это решение удивит большинство специалистов по сетевым технологиям. В сетях RDMA традиционно используется приоритетное управление потоком (PFC) для создания сетей Ethernet без потерь. Когда буфер коммутатора заполняется, PFC отправляет кадр паузы вверх по потоку, предотвращая передачу отправителем до тех пор, пока буфер не опустеет. В InfiniBand используется аналогичный механизм управления потоком на основе кредитов. Вся парадигма «сети без потерь» существует для того, чтобы поддерживать предположение RDMA о том, что пакеты не теряются.
MRC явно отключает коррекцию коэффициента мощности (PFC) и работает в стандартном режиме Ethernet с наилучшими усилиями (с потерями).
Причина кроется в блокировке в начале очереди. Когда кадр паузы PFC срабатывает на одном порту, он может блокировать трафик, предназначенный для других портов, использующих тот же входящий буфер. В большом кластере для обучения, работающем одновременно с несколькими коллективами, пауза PFC, вызванная входящим сообщением одного коллектива, может задерживать передачу данных от совершенно не связанного коллектива. Эта межколлективная интерференция создает именно те аномальные значения задержки, которые призван устранить MRC.
Предложенное в статье решение представляет собой комбинацию трех механизмов:
Во-первых, выборочная повторная передача. MRC отслеживает, какие пакеты были получены, используя выборочные подтверждения (SACK). При обнаружении потери повторно передаются только отсутствующие пакеты, а не всё окно целиком. Это быстрее, чем повторная передача с возвратом N пакетов, используемая в некоторых реализациях RoCE.
Во-вторых, обрезка пакетов. Когда коммутатор отбрасывает пакет из-за переполнения буфера, он вместо этого обрезает полезную нагрузку и пересылает только заголовок в качестве приоритетного пакета. Приемник получает обрезанный заголовок, распознает пробел и отправляет NACK для запуска немедленной повторной передачи. Это устраняет задержку по времени между обнаружением потери и повторной передачей. Это также позволяет MRC различать отбрасывание пакетов из-за перегрузки (обрезанные пакеты) и сбои в работе канала связи (отсутствие пакета вообще), что позволяет использовать различные стратегии восстановления для каждого случая.
В-третьих, размещение данных в памяти вне порядка следования. Каждый пакет данных MRC содержит виртуальный адрес RDMA и удаленный ключ. Принимающая сетевая карта может записывать каждый пакет непосредственно в его конечное местоположение в памяти независимо от порядка поступления. Это критически важно, поскольку распространение пакетов по сотням путей гарантирует, что пакеты будут поступать вне порядка следования. Без прямого размещения получателю потребовались бы буферы переупорядочивания, что привело бы к увеличению задержки и накладных расходов на память.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
ECN перепрофилирована: балансировка нагрузки, а не управление перегрузками.
В традиционных сетях явное уведомление о перегрузке (ECN) сигнализирует отправителю о перегрузке, на что тот реагирует снижением скорости передачи (аналогично управлению перегрузкой в TCP). В MRC ECN используется совершенно по-новому.
В многоплоскостной топологии MRC с полной пропускной способностью, обеспечиваемой методом бисекции, при нормальной работе суммарной перегрузки быть не должно. Общая доступная пропускная способность превышает общую потребность. Однако существует локальный дисбаланс путей: некоторые пути могут быть немного более загружены, чем другие, из-за случайного выбора EV (эквивалентных элементов) у разных отправителей.
MRC использует ECN в качестве сигнала нагрузки для каждого пути. Коммутаторы помечают пакеты метками ECN стандартным случайным образом, но MRC отключает маркировку ECN на последнем узле до приемника (чтобы избежать путаницы между внутрисетевым трафиком на последнем узле и перегрузкой коммутационной сети). Приемник отправляет отправителю ответные метки ECN, помеченные конкретным EV, который был помечен. Затем отправитель временно избегает этого EV, перенаправляя трафик на менее загруженные пути.
Это превращает ECN из механизма управления скоростью в сигнал балансировки нагрузки на уровне маршрутизации. Отправитель не замедляет работу. Он перенаправляет. Это различие важно, потому что снижение скорости приводит к трате времени графического процессора (передача занимает больше времени), в то время как перенаправление поддерживает пропускную способность, сглаживая дисбаланс.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Что показывают данные о производстве
В статье представлены результаты, полученные в двух контекстах: обучение модели производственной границы и контролируемые эксперименты на испытательном полигоне.
В производственной среде MRC позволял обучающим задачам работать без сбоев сети, которые ранее привели бы к сбою. В статье описывается упомянутый ранее сбой оптического приемопередатчика: четыре канала связи быстро сбились один за другим на трех активных обучающих узлах. MRC обнаружил сбои в каналах связи, прекратил использование затронутых EV и перераспределил трафик по оставшимся каналам. Обучающая задача продолжилась без перерыва. В обычной конфигурации RoCE это событие вызвало бы штормы PFC, тайм-ауты NCCL и перезапуск задачи, что привело бы к многочасовому использованию графического процессора.
Эксперименты на испытательном стенде позволяют количественно оценить рабочие характеристики MRC:
Пропускная способность «точка-точка»: MRC обеспечивает пропускную способность, близкую к скорости линии связи, на каналах 800 Гбит/с с использованием метода «распыления пакетов». В статье приводится сравнение со стандартным RoCE, демонстрирующее преимущество MRC в сценариях с многопутевой передачей.
Восстановление после сбоя канала связи: при обрыве канала MRC обнаруживает это и перераспределяет трафик за десятки микросекунд. Отсутствуют тайм-ауты на стороне отправителя. Отсутствует сходимость протокола маршрутизации. EV, сопоставленный с отказавшим путем, немедленно выводится из эксплуатации, а оставшиеся EV поглощают трафик.
Балансировка нагрузки между электромобилями: в статье измеряется распределение трафика по плоскостям и маршрутам, демонстрируя практически равномерное использование при производственных нагрузках.
Коллективная производительность NCCL в масштабе: в статье оценивается производительность MRC при выполнении операций сокращения (all-reduce), которые являются доминирующим шаблоном обмена данными в параллельном обучении. Распыление пакетов в MRC устраняет проблему коллизий потоков, которая ухудшает производительность операций сокращения в масштабе при использовании традиционного хеширования ECMP.
Эксплуатационные данные подтверждают правильность решения о статической маршрутизации. В статье сообщается, что коммутаторы ядра T1 перезагружались во время активных тренировочных запусков без нарушения работы сети. В обычной сети с динамической маршрутизацией перезагрузка коммутатора ядра запускает повторную конвергенцию в сети. При статической маршрутизации SRv6 коммутатор просто перезагружает свое статическое состояние пересылки и возобновляет работу. Транспортный уровень MRC обрабатывал временную потерю путей через этот коммутатор, перераспределяя трафик на другие уровни.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Там, где эти проектные решения наиболее эффективны.
MRC был разработан для конкретного профиля рабочей нагрузки: синхронное предварительное обучение с использованием обмена данными, полностью основанного на алгоритме Reduce, работающее на однопользовательской сети с полной пропускной способностью по принципу бисекции. В рамках этих ограничений три проектных решения хорошо соответствуют поставленной задаче:
Статическая маршрутизация работает, потому что топология фиксирована и известна на момент развертывания. В обучающих кластерах во время обучения не добавляются и не удаляются коммутаторы. Режимы отказов происходят на уровне каналов связи (обрабатываются системой управления EV MRC), а не на уровне топологии (что потребовало бы повторной сходимости протокола маршрутизации).
Работа сети Ethernet с потерями данных обусловлена тем, что механизмы выборочной повторной передачи и обрезки пакетов восстанавливаются быстрее, чем распространяются кадры паузы PFC. Межсетевая блокировка начала очереди, создаваемая PFC, оказывает большее негативное влияние на задержку в конце цепочки, чем случайные накладные расходы на повторную передачу.
ECN как механизм балансировки нагрузки работает благодаря многоплоскостной топологии, обеспечивающей полную пропускную способность по принципу бисекции, что гарантирует отсутствие перегрузки в совокупности. Локальные дисбалансы являются единственным источником перегрузки, а управляемое ECN предотвращение EV представляет собой точный механизм с низкими накладными расходами для их сглаживания.
[Источник: Автор (SVG создан с помощью Inkscape) – Ссылка: arXiv:2605.04333 (2026)]
Граничные условия: где метод MRC работает, а где нет.
MRC — это проверенный в производственной среде протокол для целевой рабочей нагрузки. Естественные вопросы для более широкого сообщества, занимающегося инфраструктурой ИИ, касаются граничных условий.
Во-первых, многопользовательский режим. Обучающие кластеры OpenAI запускают только одну задачу обучения за раз по всей сети. Большинство облачных провайдеров и корпоративных развертываний используют кластеры GPU совместно для нескольких рабочих нагрузок. Статическая маршрутизация MRC предполагает стабильную топологию на уровне сетевой карты. В многопользовательской среде, где рабочие нагрузки размещаются динамически, топология, видимая каждой сетевой карте, часто меняется. Адаптируется ли логика генерации пути к этому или требует модификаций — это открытый инженерный вопрос.
Во-вторых, рабочие нагрузки для вывода. MRC был разработан для синхронного обучения с использованием шаблона обмена данными, основанного на редукции: большие пакетные передачи между известными наборами графических процессоров. Рабочие нагрузки для вывода, особенно дезагрегированный вывод с передачей данных из кэша ключ-значение между пулами предварительного заполнения и декодирования, имеют другой профиль обмена данными: меньшие объемы передач, передача данных «точка-точка», а не коллективная, и чувствительность к задержке на уровне отдельных запросов, а не на уровне агрегированного шага. Распределение пакетов по сотням путей добавляет дрожание к задержке отдельных передач, что может иметь или не иметь значения в зависимости от требований SLO.
В-третьих, сети с перегрузкой. Механизм балансировки нагрузки ECN в MRC основан на полной пропускной способности, обеспечиваемой методом бисекции. В сетях с перегрузкой (распространенных в облачных средах, где оптимизация затрат определяет решения по топологии) совокупная перегрузка является реальной, а не просто локальным дисбалансом. В этом случае ECN должен функционировать как настоящий сигнал перегрузки, что изменяет динамику управления потоком в MRC.
В-четвертых, совместимость. В настоящее время MRC реализован в определенных сетевых адаптерах (NVIDIA ConnectX-8, AMD Pollara/Vulcano, Broadcom Thor Ultra) и определенных коммутационных платформах (NVIDIA Spectrum-4/5, Arista EOS на Broadcom Tomahawk 5). Выпуск спецификации OCP позволяет расширить ее внедрение, но разработка и проверка поддержки протокола на уровне микросхем займут 12-18 месяцев. В ближайшем будущем внедрение будет ограничено организациями, использующими эти конкретные аппаратные платформы.
Это не критика MRC. Это инженерные вопросы, которые естественным образом возникают, когда протокол, разработанный для конкретной, четко определенной среды, сталкивается с разнообразием более широкого рынка инфраструктуры. Тот факт, что MRC решил проблему задержки в хвосте распределения на масштабе 131 000 графических процессоров, является подлинным достижением. Вопрос для остального сообщества заключается в том, какие из его проектных решений являются общими, а какие — специфическими для ограничений однопользовательских обучающих сетей с полной пропускной способностью.
Что сигнализирует MRC о будущем сетевых технологий в области искусственного интеллекта
MRC представляет собой более масштабный сдвиг в том, как инфраструктура ИИ рассматривает сети. Традиционный подход рассматривает сеть как прозрачный канал: пакеты входят с одного конца и выходят с другого, а задача транспортного протокола — максимально эффективно заполнить этот канал. MRC рассматривает сеть как управляемый ресурс с наблюдаемыми сигналами состояния для каждого пути, которые транспортный протокол активно использует.
Это не новая идея в сетевых исследованиях. Multipath TCP, балансировка нагрузки Valiant и ECMP уже много лет изучают её вариации. Новым является масштаб, в котором работает MRC, агрессивность его проектных решений (отсутствие PFC, динамической маршрутизации, полное распыление пакетов) и подтвержденные результаты его работы на крупнейших в мире кластерах для обучения ИИ.
Для специалистов в области сетевых технологий MRC подтверждает тезис, который обсуждался в течение десяти лет: при достаточном масштабе интеллект конечных устройств превосходит интеллект сети. Умение сделать сетевую карту более интеллектуальной, а коммутатор — более простым, приводит к созданию более отказоустойчивой системы, чем простое упрощение коммутатора и сетевой карты. Независимо от того, согласны вы со всеми проектными решениями или нет, результаты производственных испытаний OpenAI и Microsoft делают этот аргумент менее убедительным, чем неделю назад.
Спецификация MRC доступна через OCP под открытой лицензией. В исследовательской работе представлены подробные экспериментальные результаты. Всем, кто занимается масштабным созданием кластеров GPU, стоит внимательно ознакомиться с обеими документами. Три правила, которые нарушает MRC, могут быть теми же тремя правилами, которые тормозят развитие вашей сети.
Гокул Чандра Пурначандра Редди. Все работы Гокула Чандры Пурначандры Редди.
Источник: towardsdatascience.com
Оцените материал:
