Корпоративная система управления документами: серия статей о поэтапном создании RAG-системы, от минимального масштаба до масштаба корпуса документов.
Для инженеров в области искусственного интеллекта, которые хотят понимать каждый шаг, а не просто обращаться в библиотеку.
Делиться

Примерно три года назад генеративный ИИ получил широкое распространение, и RAG (Registered Agile) стал стандартным ответом на вопрос: «У нас есть документы, мы хотим задать вопросы». Предложение звучало как чудо. Однако реализация, которую все описывали, была одной и той же, снова и снова:
- разбить документы на части.
- поместите фрагменты в векторное хранилище.
- вставьте вопрос,
- Получить k лучших результатов по косинусному сходству, при необходимости выполнить переранжирование.
- Отправьте эти данные магистрату права (LLM).
Поставщики услуг сосредоточились на этом. Консалтинговые компании сосредоточились на этом. Доклады на конференциях были посвящены этому.
Затем начались поставки готовой продукции, и результаты зачастую оказывались неутешительными.
- Пользователи не доверяли ответам.
- Ссылки были неточными или отсутствовали.
- Найденные фрагменты текста зачастую оказывались несущественными, хотя и полезными.
И каждый раз рефлекторной реакцией команды было использование дополнительных инструментов из того же набора:
- более мощная модель,
- более длительное контекстное окно,
- лучший инструмент для переранжирования,
- Больше MLOps для производственной стороны.
Формулировка всегда была одна и та же: «Это проблема ИТ. Более совершенная инфраструктура, лучшие инструменты, лучшие модели решат её».
Я начал изучать этот вопрос самостоятельно, на реальных корпоративных документах, в присутствии настоящих экспертов в данной области. Мой опыт не соответствовал такому подходу.
Настоящая работа, которая действительно принесла результаты, не была связана с инфраструктурой. Это была инженерная работа, плюс понимание предметной области бизнеса, плюс немного базовой математики. Не глубокая математика. Просто достаточно, чтобы понять, что на самом деле измеряет эмбеддинг, что на самом деле делает переранжировщик, почему тот или иной прием помогает в одних случаях и вредит в других. И затем, то, что большинство команд пропускают: знание документов, на основе которых система должна отвечать на вопросы. Кто их читает. Что они содержат. Какую лексику используют эксперты. Какие вопросы возникают неделя за неделей.
Большинство компаний — это не Google. Это также не исследовательские лаборатории. Они не проводят открытые исследования в области вопросов и ответов через открытый интернет. Они не обучают собственные модели встраивания. У них есть несколько основных типов документов, несколько десятков экспертов в предметной области, которые уже досконально знают корпус, и повторяющийся набор вопросов, на которые нужны ответы с цитатами и журналом аудита. Правильная архитектура для этого контекста — это не то, что предлагают поставщики, и не то, за чем гонятся научные статьи. Это архитектура, которая усиливает влияние экспертов и использует дешевый и предсказуемый поиск там, где это возможно.
Большинство систем RAG, которые я видел в корпоративной среде, хуже, чем стострочный скрипт на Python. Основы не работают, и добавление новых функций только усугубляет ситуацию. Эмбеддинги слишком расплывчаты по смыслу, чтобы выбрать нужный фрагмент, а синтаксический анализ настолько некачественный, что LLM получает «мусор на входе, мусор на выходе».
Когда подобная система начинает давать сбои, стандартная реакция — добавление дополнительных уровней:
- переранжировщик,
- тонко настроенная модель встраивания, о которой никто не может судить, приносит ли она пользу.
- агент перезаписи запросов,
- агент-оценщик,
- Структура оркестратора, которая превращает каждый вопрос в десять звонков LLM.
Каждый слой добавляет правдоподобности демонстрации. Ни один из них не исправляет фундамент: по-прежнему нет способа определить, являются ли полученные фрагменты правильными, и по-прежнему нет способа объяснить пользователю, почему была получена та или иная страница.
Скрипт, который мы создадим в первой статье, умещается примерно в сто строк и не содержит векторной базы данных, фреймворка и агентов.
Программа принимает PDF-файл и вопрос, анализирует их, извлекает три верхние страницы с помощью простого косинусного сходства, отправляет их в LLM-библиотеку с пидантической схемой и возвращает структурированный ответ с цитатами и выделенным исходным PDF-файлом.
Этот скрипт более проверяем и полезнее, чем многие из производственных систем, которые я видел вблизи. Разница между ними заключается не в оперативности разработки и не в улучшенном алгоритме поиска. Она проистекает из трех привычек, которые часто упускает отрасль: знание документов, знание того, что уже знают эксперты, и не путать алгоритм поиска с машинным обучением.
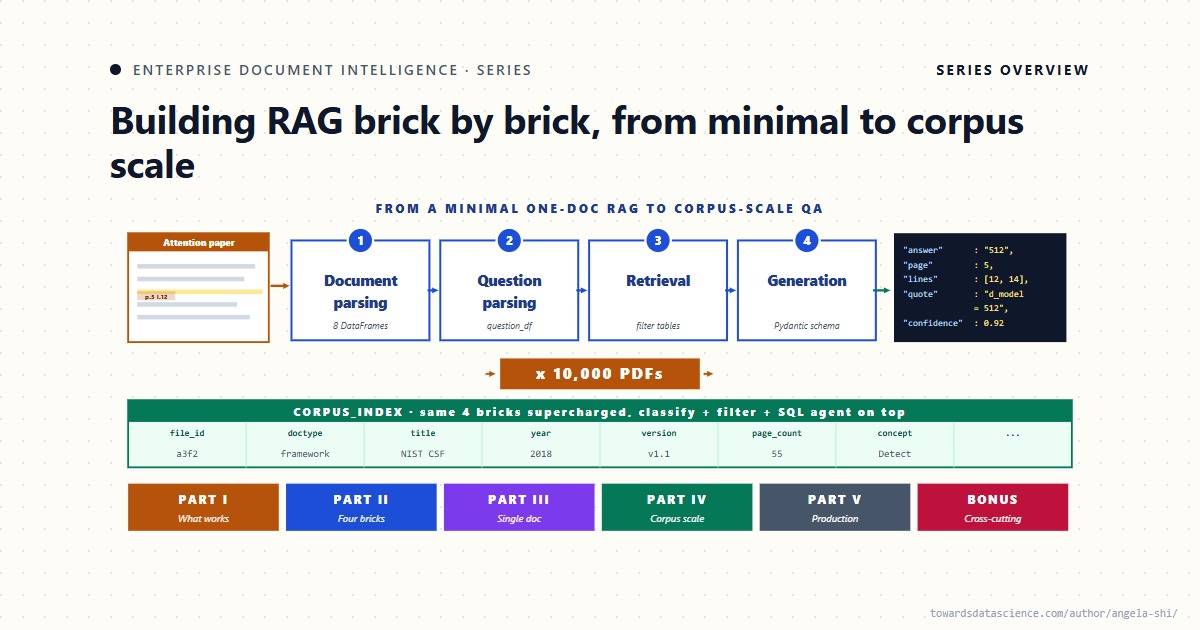
В этой серии статей эти навыки объединены в четырехэтапный процесс: анализ документа, анализ вопроса, поиск, генерация, а также дополнительный этап аннотирования PDF-файла, который возвращает цитату читателю.
1. Как используется RAG на предприятии
1.1 Статья 2020 года: поиск как контекст
В мае 2020 года Патрик Льюис и его коллеги из Facebook AI Research ввели этот термин в статье «Генерация с расширенными возможностями поиска для задач обработки естественного языка, требующих интенсивного использования знаний» (Lewis et al. 2020, препринт arXiv). В их аннотации прямо указаны три недостатка, которые должна была исправить эта архитектура:
Предварительно обученные модели «не могут легко расширять или пересматривать свою память, не могут напрямую предоставлять информацию о своих прогнозах и могут вызывать „галлюцинации“». Решение заключалось в объединении генератора (BART) с плотным векторным индексом Википедии, доступ к которому осуществлялся во время вывода. Важное архитектурное решение: извлечь фрагмент из корпуса, передать его модели LLM и позволить ей генерировать данные на основе этого контекста, а не только на основе памяти, полученной во время обучения.
Эти три недостатка четко соответствуют трем свойствам, за которые борется RAG в корпоративной среде: актуальность корпуса, цитируемость, обоснованные ответы. Серия является прямым продолжением этой линии рассуждений 2020 года, примененной к ограничениям в корпоративной среде.
1.2 Что означает «RAG» в этой серии
Для большинства разработчиков сегодня термин «RAG» сузился до одного конкретного рецепта: хранилище векторов, поиск сходства встраиваний и, в конце, LLM.
В сериале это слово будет по-прежнему использоваться, но в более широком первоначальном значении: извлечение информации, поиск информации и ответы на вопросы по массиву документов.
Механизм извлечения данных — это проектное решение, которое признает архитектура, но оно не является частью ее определения. Многие корпоративные конвейеры, которые рассматриваются в этой серии статей, вообще не используют векторное хранилище; некоторые используют его как один из нескольких каналов, никогда не в качестве основы. Когда в объявлении говорится «RAG», читайте это в более широком смысле.
1.3 В корпоративной среде извлечение информации стоит на первом месте.
Распространенное представление о RAG (LLM пишет гибкий ответ на естественном языке на основе полученного контекста) недостаточно точно описывает то, что предприятия на самом деле с ним делают.
Основная часть работы заключается в извлечении информации : вытягивании конкретных значений из документов, при этом магистр права выступает в роли структурированного читателя, а не автора.
- Страховщику необходима сумма страхового покрытия, размер франшизы и дата вступления покрытия в силу.
- Сотруднику, ответственному за соблюдение нормативных требований, необходим список пунктов договора, которые остаются в силе после его расторжения.
- Помощнику юриста необходимы данные о сторонах, указанных в договоре.
Программа LLM считывает полученный фрагмент текста, определяет ответ и возвращает его в виде типизированной схемы с построчными ссылками. Это извлечение информации с некоторой незначительной переформатировкой и очисткой. Это не создание в творческом смысле.
В тех случаях, когда в рамках корпоративной работы магистру права разрешается создавать новый текст, он делает это на основе контента, уже извлеченного и проверенного системой. Данная методика придерживается четкого разделения: на первом этапе извлекается соответствующая информация со ссылками, проводится ее проверка и аудит . На втором этапе, поверх набранного текста, может быть создан более длинный текст (черновик уведомления, краткий обзор отчета).
Два этапа, два вызова LLM, две поверхности аудита. Журнал аудита рушится, когда один вызов LLM смешивает поиск, извлечение и создание творческой композиции. Архитектура отвергает такое смешение.
1.4 Переход от дополненного к обоснованному подходу
В статье 2020 года был выбран термин «дополненная» (Augmented) вместо альтернативных вариантов, таких как «обоснованная» (Grounded) или «условная» (Conditioned). Выбор слова имеет значение. В рамках подхода 2020 года генератор может свободно смешивать свою параметрическую память с извлеченными фрагментами. Модель LLM продолжает использовать то, что она узнала во время предварительного обучения, и обращается к извлеченным данным. Две смешанные памяти. «Дополненная» предполагает, что что-то уже существует; извлеченные данные дополняют это. «Обоснованная» означала бы обратное: генерация опирается на извлеченные данные, привязана к ним, и модель ограничена в том, чтобы не отклоняться от того, что было извлечено.
В корпоративной среде это предположение перевернуто с ног на голову. Каждое фактическое утверждение должно быть подкреплено полученным фрагментом текста; параметрическая память LLM изгоняется из фактического содержания ответа и используется только для процедурных целей: грамматика, следование схеме, извлечение дословных фрагментов, арифметические операции над цитируемыми значениями, дедукция по полученным фактам. Переход от дополненного к обоснованному невелик в лексическом плане и велик в операционном. Когда LLM перефразирует полученное предложение в поле JSON coverage_amount: 50000 , перефразирование соответствует английской грамматике и синтаксису JSON: это процедурный процесс, и мы его сохраняем. Когда же поле valid_until: "2027-12-31" заполняется датой, которой нет в полученном тексте, это фактический процесс, и мы его блокируем.
В этой серии сохраняется архитектура из статьи 2020 года, но при этом сужаются возможности использования параметрической памяти в рамках программы LLM.
1.5. Длинный контекст не является заменой.
Окно, содержащее миллион токенов, не сводит корпоративный корпус к одному запросу. Корпус включает от тысяч до сотен тысяч документов, и поиск нужного документа всё равно должен произойти до любого вызова LLM. А ответ с длинным контекстом, полученный из массива в миллион токенов, не может подсказать пользователю, какая страница подтверждает какое утверждение. RAG с построчными ссылками это делает.
2. Почему «Enterprise Document Intelligence» (Интеллектуальная система управления документами предприятия), а не «Enterprise RAG» (Система анализа и отслеживания информации предприятия)?
Одно из возражений постоянно возникает при презентации сериала, и оно склоняет к более широкому названию. Два уточнения относительно масштаба дополняют картину: что на самом деле означает «Enterprise» как архитектурное ограничение и какой тип корпуса охватывает сериал.
2.1 RAG называет один из режимов произведения, а не весь.
RAG в строгом смысле — это поиск информации с последующим ответом на вопросы. Архитектура, которую защищает эта серия, охватывает гораздо больше. Классификация при загрузке данных, извлечение полей в больших масштабах, версионирование, агрегация SQL, оценка, безопасность: многие из этих аспектов не относятся к RAG в стандартном понимании. SQL-агент из статьи 17 вообще не является RAG; это точка, где поиск информации заканчивается и управление переходит к системам обработки данных. В последующем томе добавляются перевод, суммирование, сравнение бок о бок, редактирование; это также не относится к RAG. «Интеллектуальные документы» — это название более широкой работы; «RAG» — это один из ее режимов, а именно режим ответа на вопросы.
2.2 «Предприятие» как архитектурное ограничение
Квалификатор Enterprise — это не сегмент рынка, а ограничение. Контролируется корпус данных, а не открытый интернет. Эксперт вовлечен в процесс, и система усиливает его уже имеющиеся знания. Журнал аудита обязателен, поскольку каждый ответ может быть оспорен. Диспетчер детерминирован, поскольку важна воспроизводимость. Автоматические помощники в открытых областях принимают другие решения. Эта серия предназначена для инженеров, работающих в рамках этих ограничений, и каждое архитектурное решение в ней вытекает из них.
2.3 Форма корпуса, который обрабатывает серия
Основной пример в этой серии — корпус однородных, независимых документов : от нескольких тысяч до нескольких сотен тысяч PDF-файлов одного типа. Когда корпус содержит документы нескольких типов, первым шагом является их классификация по группам (статья 15), а затем запуск однородного конвейера обработки для каждой группы. Каждый документ читается отдельно; индекс корпуса располагается над всеми документами.
Дело (заявка на кредит, продление контракта, страховой случай) представляет собой небольшой набор разнородных PDF-файлов, относящихся к одному объекту. Вся серия документов состоит из PDF-файлов, поэтому несколько небольших файлов можно просто объединить и рассматривать как один документ. Именно здесь оглавление приносит свои плоды: несколько PDF-файлов, каждый со своим оглавлением, после объединения читаются как один большой документ с вложенными разделами, а блок поиска (статья 7) уже знает, как по нему перемещаться. В последующем томе представлена правильная маршрутизация дел с сигналами для каждого типа документа, когда набор документов становится слишком разнообразным или слишком большим для объединения.
Более сложная задача — это множество дел, множество типов документов в каждом деле : сотни дел, каждое из которых содержит от пяти до пятидесяти разнородных документов. Организация работы с ними выходит за рамки возможностей одного лишь корпусного индекса. В серии, из честности в отношении масштаба, название дела указывается отдельно, а полное рассмотрение вопроса откладывается до следующего тома; базовые принципы, разработанные в частях IV-V, используются и в этой серии.
Если ваш архив имеет однородную форму, то данная серия охватывает его от начала до конца. Если же он представляет собой делопроизводство, то эта серия проведет вас по большей части пути, а следующий том завершит работу.
3. Что представляет собой этот сериал?
Enterprise Document Intelligence — это пошаговая серия руководств для инженеров и специалистов по анализу данных, посвященная построению алгоритмов обработки корпоративных документов: контрактов, технических отчетов, документов регулирующих органов, где неверный ответ может привести к замечанию регулирующих органов, спору по контракту или возврату средств клиенту. Серия фокусируется на формате PDF как на доминирующем формате документов, которые предприятия действительно хотят обрабатывать. Другие форматы (Word, Excel, PowerPoint, электронная почта) требуют собственной логики анализа и структурирования и рассматриваются в последующих разделах.
Позиция «усилить мнение эксперта» находит отражение в конкретных архитектурных решениях, которые отстаивает сериал, и каждое из них связано с конкретными статьями:
- Детерминированные диспетчеры важнее автономных агентов. Эксперты могут проверить детерминированный поток. Они не могут проверить агента, который самостоятельно решает, какой инструмент вызвать, какой подвопрос задать и когда остановиться. Агент экономит инженерные усилия на демонстрации и компенсирует их при инцидентах, которые невозможно воспроизвести из-за недетерминированной маршрутизации. В серии статей отстаивается диспетчеризированная архитектура, где каждое решение о маршрутизации является явным, регистрируется и поддается проверке. Статья 13 описывает её реализацию.
- Векторные хранилища — это запасной вариант, а не основа. Эксперты уже знают ключевые слова. Векторные хранилища занимают своё место, когда поиск по ключевым словам не удаётся: перефразирование, межъязыковой поиск, полисемия, «транспортное средство припарковано ночью» в сравнении с «машина на ночь». Поиск не должен начинаться с векторного хранилища. В большинстве корпоративных корпусов поиск по структуре (оглавление, классификация, ключевые слова экспертов) превосходит поиск по косинусному сходству. В статьях 2 и 7 это подробно рассматривается.
- Словари экспертов превосходят более совершенные модели встраивания. Предметная лексика — это самый ценный артефакт в системе. Синонимы, разрешения неоднозначностей, эквивалентность перекрестных произведений («franchise = франшиза», «ShieldPro Elite = план страхования домовладельцев высшего уровня») невозможно восстановить с помощью формулы IDF или сходства встраивания; их необходимо получить от людей, которые используют эту лексику ежедневно. Статья 6 делает словарь центральным объектом анализа вопросов.
- В корпоративных системах ранжирования (RAG) переранжировщики в основном избыточны. Их затраты оправданы в одном узком случае (большой общий пул кандидатов, отсутствие тщательно отобранного конвейера обработки данных). Архитектурные решения, которые защищает данная серия статей (экспертный словарь, поиск с учетом структуры, классификация перед поиском), делают их избыточными в важных вопросах. Статья 2 bis проводит эмпирическую проверку.
- Откажитесь от шаблона «подключить всё к векторному хранилищу». Этот шаблон оптимизирован для бизнес-модели гипермасштабируемой компании, а не для точности клиента. Классифицируйте перед индексированием. Фильтруйте перед извлечением. Агрегируйте с помощью SQL, когда требуется статистический анализ. RAG обрабатывает поиск контента; SQL обрабатывает подсчет; корпусный индекс находится между ними. Статьи 14-17 делают это ядром архитектуры корпусного масштаба.
В основе этих решений лежат три позитивных принципа, которые повторяются в каждой статье. Работа прагматична и основана на экспертных знаниях : каждое решение оценивается по тому, насколько оно опирается на накопленные знания людей, которые уже разбираются в документах. Архитектура представляет собой пирамидальную структуру : четыре именованных блока (анализ, анализ вопросов, поиск, генерация), каждый из которых содержит несколько именованных функций с явными входными и выходными данными, так что опытный инженер может отследить запрос от начала до конца за считанные минуты. Данные на каждом блоке являются реляционными : анализ создает таблицы, анализ вопросов создает таблицы, поиск запрашивает их, генерация записывает типизированную строку обратно, никогда не используя необработанные строки на каком-либо этапе.
Из вышеизложенного вытекают три философские позиции, которые повторяются на протяжении всего текста: эмбеддинги — это не магия (статья 2), RAG — это не машинное обучение (статья 3), оценка проводится по каждому режиму отказа, а не в совокупности (статья 20).
Эти позиции возникли в результате формирования RAG (Registered Accountability and Regulatory — оценочная верность навыкам) в регулируемых отраслях: страхование, юриспруденция, финансовые услуги. Это не единственные допустимые позиции. Это те, которые доказали свою эффективность в производственной практике, где неправильный ответ влечет за собой возврат средств, штраф или судебный иск.
4. Что входит в сериал?
Часть I: Что работает, а что ломается
Создайте минимальный конвейер обработки данных, понаблюдайте за его недостатками, переосмыслите подход к делу, а затем найдите свой собственный пример, прежде чем двигаться дальше. Каждая статья подготавливает почву для следующей, поэтому все четыре можно прочитать за один раз, прежде чем использовать инструменты или фреймворки.
- Статья 1: Минимальный RAG-код, от PDF до выделенного ответа. Весь процесс занимает около 100 строк. PDF на входе, структурированный JSON на выходе, выделение строк исходного кода в PDF.
- Статья 2: Эмбеддинги — это не магия. Предсказуемые ошибки при поиске RAG: отрицание, точные значения, внутренние аббревиатуры, тематическая близость. Где начинает давать сбои минимальная версия.
- Статья 2 бис (дополнение): Переранжировщики тоже не волшебство. Переранжировщики, использующие разные кодировщики, исправляют ловушки, связанные с буквальными токенами, которые возникают при сбое эмбеддингов, но имеют те же структурные ошибки (отрицание, точные идентификаторы, перечисление, нерелевантная лексика). Позиция редакции: запасной вариант для узких случаев, а не основной этап.
- Статья 3: RAG — это не машинное обучение. Заблуждение, которое больше всего вредит проектам RAG. RAG — это поиск плюс слой генерации, а не модель для обучения.
- Статья 4: Какой метод RAG подходит для какой проблемы. Диагностический этап перед принятием любого технического решения. Разместите свою проблему на сетке 5×5 (сложность документа × контроль вопроса), затем выберите самый простой метод, который подходит.
Часть II: Четыре кирпича
Парсинг → парсинг вопроса → поиск → генерация. Четыре кирпичика, из которых состоит остальная часть серии. Что отличает эту архитектуру от стандартной RAG: каждый кирпичик генерирует реляционные структурированные данные (связанные DataFrames, типизированные строки), а не просто строки. Конвейер можно проверять, воспроизводить и аудитировать на каждом этапе.
- Статья 5: Богатый вывод хорошего RAG-парсера. Блок 1: строки, таблицы, изображения, столбцы, оглавление, перекрестные ссылки. Все, что потеряно при парсинге, невозможно восстановить на последующих этапах.
- Статья 5 bis (дополнение): Когда PyMuPDF не видит таблицу. Анализ с помощью Azure Document Intelligence. Те же восемь DataFrames, второй механизм. Azure добавляет собственные ячейки таблицы, текст OCR внутри рисунков, детерминированные подписи и оглавление, восстановленное из ролей абзацев, когда отсутствуют собственные закладки. Столбец
parsing_methodотслеживает происхождение каждой строки, поэтому адаптивный анализ может сочетать fitz и Azure в одном документе. - Статья 6: Анализ вопросов в RAG. Структура перед поиском. Блок 2: вопрос — это неструктурированный ввод, преобразованный в реляционный набор таблиц, симметричный анализу документов.
- Статья 7: Почему эмбеддинги используются в последнюю очередь при поиске RAG-данных в производственной среде. Шаг 3: поиск — это фильтрация структурированных DataFrames, а не поиск свободного текста. Эмбеддинги — это резервный вариант, а не вариант по умолчанию.
- Статья 8: Генерация как управляемое выполнение. Блок 4: ввод текста (тексты плюс вопрос), вывод текста (Pydantic). Схема является контрактом; один шаблон подсказки на каждую форму ответа.
Часть III: Конвейеры обработки одного документа
Весь конвейер, собранный из улучшений, внесенных во второй части, был расширен. В статье 1 был запущен минимальный конвейер от начала до конца; затем во второй части каждый его компонент был улучшен отдельно. Статья 9 замыкает этот цикл: та же демонстрация, что и в статье 1, на той же бумаге, со всеми улучшениями из второй части, объединенными в единую систему. В статьях 10-12 затем добавляются специфические шаблоны сложности: адаптивный синтаксический анализ (где генерация указывает синтаксическому анализу на необходимость повышения сложности), перекрестные ссылки, составление списков. Статья 13 объединяет каждый шаблон в оркестратор, связывает петли обратной связи, которые ограничивают итерации, и является хранилищем накопленного командой опыта.
- Статья 9: Полный конвейер от начала до конца, объединение части II. В статье 1 конвейер был запущен в минимальном виде. В части II было описано, как каждый компонент может быть улучшен в отдельности. В этой статье используется аналогичная демонстрация, что и в статье 1, на основе той же статьи о Transformer, с учетом всех улучшений из части II: более расширенный синтаксический анализ, анализ вопросов по ключевым словам экспертов с обработкой опечаток, комбинированные методы поиска (оглавление плюс ключевое слово плюс встраивание с объединением оценок и опциональный арбитр LLM), структурированная генерация с полной схемой. Разрыв между минимальным и интегрированным вариантами показан в сквозном режиме на одних и тех же вопросах.
- Статья 10: Адаптивный анализ PDF-файлов. Сначала простой анализ; расширенный анализ только там, где этого требует вопрос. Адаптивное повышение уровня сложности, основанное на обратной связи от генераций.
- Статья 11: Как RAG обрабатывает перекрестные ссылки в контрактах и стандартах. Настоящая проблема «сложных» документов заключается не в длине, а во взаимосвязи между ними. Двухэтапный поиск, следующий за ссылками.
- Статья 12: Когда RAG должен найти все ответы: Задания на составление списка. «Что представляют собой все X?» Ответ не содержится в одном отрывке, он распределен между множеством элементов. Необходимо проводить поиск, а не искать среди k лучших вариантов, с явными сигналами полноты.
- Статья 13: От одного RAG-конвейера ко многим: Паттерн составного конвейера. Объединение всех паттернов в единую работающую систему. Оркестратор и диспетчер — это накопленный командой опыт в программировании; здесь также присутствуют ограниченные петли обратной связи, обнаружение отклонений и полный журнал аудита.
Часть IV: От одного документа к целому архиву
Наивный поиск по тысячам документов терпит неудачу. Те же четыре принципа остаются в силе, но перед каждым из них необходим структурный индекс. Статья 14 формулирует тезис с помощью минимального конвейера обработки корпуса, запущенного на пяти PDF-файлах NIST, — своего рода базовый вариант, который приводит к потере четырех из пяти вызовов LLM, поскольку корпус не был предварительно отфильтрован. Статья 15 исправляет входную часть: иерархический каскад вопросов заполняет реляционный corpus_index , по одной строке на документ, столбцы для полей поиска. Статья 16 формализует онтологию, управляющую каскадом, в виде пяти небольших таблиц, вручную составленных экспертом, и объясняет, почему тщательно составленный реляционный слой превосходит граф знаний, извлеченный с помощью LLM, по всем операционным параметрам. Статья 17 настраивает сторону запросов: анализ вопроса, фильтрация индекса, запуск конвейера на уровне документа только для кандидатов, возвращенных агентом SQL.
- Статья 14: Ваш RAG работает с одним PDF-файлом. Теперь заставьте его работать с десятью тысячами. Часть IV. Пять режимов отказа наивного векторного RAG в масштабе, принцип зеркального отображения (4 кирпича для одного документа → 4 кирпича для корпуса), минимальный базовый запуск
corpus_qa_baselineна пяти PDF-файлах NIST, показывающий, где происходит потеря ресурсов. - Статья 15: От папки с PDF-файлами к доступному для запросов корпусу RAG, по одному вопросу за раз. Усовершенствованный блок 1. Иерархический каскад вопросов заполняет
corpus_indexдля каждого документа, с двумя путями выполнения (регулярное выражение по имени файла, конвейер обработки одного документа в противном случае) и нормализацией номенклатуры (извлечение исходных данных → каноническая сущность). Реальные запуски на 24 PDF-файлах NIST и 30 статьях arXiv. - Статья 16: Почему вашему корпоративному RAG нужна онтология, а не граф знаний. Краеугольный камень. Знания эксперта, кодифицированные в виде пяти реляционных таблиц (правила каскадирования, ключевые слова концепций, отношения концепций, маршрутизация концепций к типам документов, номенклатура). Преимущества в плане проверяемости, стоимости, обслуживания, актуальности и владения. Три сектора (кибербезопасность NIST, NLP/IR arXiv, вымышленный страховой брокер) доказывают перенос шаблонов. Анти-GraphRAG — это следствие, а не слоган.
- Статья 17: Как RAG отвечает на вопрос в рамках корпуса: сначала фильтрация SQL, затем извлечение. Усовершенствованная схема 2-3-4. Оркестратор определяет намерение (столбец / документ / гибрид), запускает агент SQL или фильтрует, а затем извлекает данные, и отправляет команду на генерацию. Три реальных запуска на NIST
corpus_indexзавершают архитектуру.
Часть V: Работа в процессе производства
Система построена. Теперь запустите её на годы. Архитектура кода, позволяющая нескольким разработчикам работать параллельно, уровень хранения, содержащий воспроизводимые артефакты, оценка каждого режима отказа на основе тщательно подобранного набора данных (без иллюзий относительно точности агрегирования), стоимость и задержка, измеряемые как агрегированные SQL-запросы на одном и том же хранилище, и защитная оболочка, охватывающая всё это. Специфические для RAG проблемы, которые не рассматриваются в общих руководствах по машинному обучению и безопасности.
- Статья 18: Архитектура кода для Enterprise RAG: четыре слоя и карта функций. Структура пакетов, сохранившаяся за годы эволюции. Четыре слоя (ядро, хранилище, аннотации, конвейер) с однонаправленными зависимостями, один метод на скрипт и карта функций, которая привязывает каждый блок к его диспетчеру и подфункциям.
- Статья 19: Хранилище для Enterprise RAG: Единая база для всего, что вы измеряете. Около тридцати реляционных таблиц в пяти подсхемах, основанных на двух хеш-идентификаторах (
file_id,question_id). Длинный формат для хранения, широкие представления для вывода. Столбецllm_raw_jsonи таблицаquery_logиспользуются для чтения данных из таблиц evaluation, cost и audit. - Статья 20: Оценка Enterprise RAG: Измеряйте процесс, а не модель. Оценка по каждому режиму отказа как
pandas.groupbyв таблице результатов, объединенной из хранилища, описанного в статье 19. Агрегированные метрики лгут; метрики по каждому типу вопроса говорят правду. - Статья 21: Стоимость и задержка в корпоративной RAG: измерение на основе хранилища. Те же исходные таблицы, что и в статье 20, но другие агрегации. Токены, задержка, оповещения, версионирование. Самостоятельно размещенный тест производительности Ollama уровня 1 в домене брокера.
- Статья 22: Безопасность и соответствие требованиям для корпоративных RAG. Заключительная глава. Быстрое внедрение через документы, изоляция арендаторов, GDPR в отношении производных данных, журнал аудита, контроль доступа на уровне документов, саморазмещенная граница конфиденциальности: специфический для предприятия уровень, который не рассматривается в общих руководствах по безопасности.
Дополнительные статьи
Каждый из них представляет собой сквозную практическую проблему, затрагивающую несколько основных разделов, но не относящуюся ни к одному отдельному разделу.
- B01: Орфографические варианты в RAG. Почему одной проверки орфографии недостаточно. Сорок лет классической коррекции орфографии (Levenshtein, BK-tree, Soundex, SymSpell) справляются с большинством опечаток в отдельных словах. Эмбеддинги и LLM-модели решают остальные проблемы. Практическое разделение для корпоративного RAG: проверка орфографии вопроса по словарю корпуса во время синтаксического анализа; для документов очистка канонических ссылок один раз, оставление объема данных «шумным» и разработка поиска с учетом этого шума.
- B02: FAQ как RAG. Когда вы приступаете к разработке корпуса. Контрапункт к остальной части серии, основанный на контролируемом корпусе. Стандартный RAG предполагает, что вы наследуете хаотичный корпус; FAQ переворачивает это с ног на голову. Анализ становится тривиальным, поиск одновременно служит кэшем, а подсказки с малым количеством примеров сами по себе становятся проблемой поиска. Завершается циклом обратной связи, который превращает FAQ в живой корпус, управляемый потоком вопросов.
- B03: Когда RAG говорит «Я не знаю». Обоснование отсутствия ответа. Уверенный неправильный ответ — это ошибка. Простое «нет ответа» без обоснования почти так же плохо. Каждый из четырех блоков должен предоставить пользователю одно доказательство: что было проанализировано, какой словарь был использован для поиска, какие страницы были просмотрены, почему ничего не совпало. «Я не знаю» становится поддающимся проверке, а не непрозрачным.
- B04: Таблицы в PDF-файлах для RAG. Не следует сглаживать сетку. Таблицы — это то место, где большинство конвейеров RAG молча терпят неудачу. Линейное дерево решений для разных типов таблиц не работает, потому что измерения пересекаются. Правильная схема — это четыре уровня представления (строка как линия в
line_df, отдельныйtable_df, столбцовое представление с именованными и типизированными столбцами, столбцовое, но неоднородное представление), диагностика для каждой таблицы по пяти ортогональным осям и несколько идемпотентных операций, перемещающих таблицы между уровнями. Большинство таблиц остаются на самом простом уровне; только те немногие, которым это необходимо, платят за эскалацию.
Каждая статья самодостаточна. Каждая развивает предыдущие таким образом, что это должно восприниматься естественно: тот же минимальный механизм из статьи 1 перерастает в архитектуру статей 18-19 и в область безопасности статьи 22, причем каждое дополнение мотивировано конкретной ошибкой, выявленной ранее.
5. Для кого это предназначено?
Инженеры, разрабатывающие системы RAG для корпоративных документов. Юридические, страховые, финансовые, регулируемые отрасли в целом — везде, где стоимость неправильного ответа измерима. Если вы выпустили систему RAG, которая работала в демонстрационных версиях, но сломалась у реальных пользователей, эта серия для вас.
Специалисты по анализу данных, которые считают, что интуитивные представления о машинном обучении не совсем соответствуют теории рационального использования ресурсов (RAG), ошибаются. Сериал наглядно и наглядно показывает разницу и предлагает практические решения.
Руководители технологических компаний принимают архитектурные решения. Когда использовать векторные базы данных. Когда нет. Когда использование агентных шаблонов оправдано. Когда нет. Когда стоит инвестировать в более глубокий анализ данных. В этой серии статей высказывается собственное мнение по этим вопросам и объясняется логика их принятия.
6. Кому это не подходит
Команды, не имеющие внутренних экспертов по документам. В этой серии предполагается, что у вас есть или вы можете связаться с людьми, которые уже знакомы с вашим корпусом документов:
- юристы, которые читают контракты,
- андеррайтеры, устанавливающие франшизы,
- Сотрудники, ответственные за контроль за соблюдением нормативных требований.
Практически каждое архитектурное решение в этой серии усиливает этот опыт. Если вы создаете систему контроля качества в открытой предметной области на основе корпуса, который никто внутри компании не понимает, то решения, принятые здесь, не подойдут. Существуют ситуации, когда универсальный поиск и автономные агенты более целесообразны; эта серия не об этом.
Исследователи на переднем крае науки. Эта серия посвящена производственной инженерии, а не новым методам. В ней приводятся ссылки на последние исследования, где это уместно, но она не стремится к их дальнейшему развитию.
Всем, кто ищет волшебный фреймворк. Эта серия — полная противоположность. Она о том, как достаточно хорошо понять, что лежит в основе фреймворков, чтобы делать осознанный выбор. Иногда это означает использование фреймворка. Часто это означает написание сотни строк простого кода, который работает лучше, чем то, что предоставил вам фреймворк.
7. Что не рассматривается в этом сериале
Серия статей посвящена анализу и генерации ответов на вопросы в PDF-документах . Она не охватывает другие форматы документов (Word, Excel, PowerPoint, электронная почта), сравнение документов «бок о бок», структурированные данные рядом с документами (базы данных), конвейеры перевода, крупномасштабное суммирование, генерацию документов или автономных агентов, работающих с документами.
Это реальные потребности предприятий. Они опущены, потому что с операционной точки зрения отличаются от RAG-on-PDF. Их включение приводит к запутанным архитектурам, которых, как мы пытаемся помочь читателям избежать, является важным моментом.
Последующий том, запланированный на период после завершения этого, рассматривает каждый из них по-своему: другие форматы документов (Word / Excel / PowerPoint / электронная почта), сравнение бок о бок, перевод, обобщение, структурированные данные наряду с документами, генерация документов. Одна и та же инженерная дисциплина, примененная к различным формам проблем.
8. Как следить за сериалом
Статьи будут публиковаться ежедневно в порядке очередности, начиная со статьи 1: Минимальный RAG, от PDF до выделенного ответа.
Он строит весь конвейер примерно за сто строк кода на Python. Каждая последующая статья начинается с того, что в ней рассматриваются вопросы, которые естественным образом возникают при использовании работающей минимальной версии.
Если вы внедряете RAG в рабочую среду и считаете, что стандартные настройки, принятые в отрасли, неверны, эта серия статей расскажет вам, как с этим справиться.
Анджела Ши. Все материалы от Анджелы Ши.
Источник: towardsdatascience.com
Оцените материал:

