Комплексная оценка больших языковых моделей для медицинских задач с помощью MedHELM.
Абстрактный
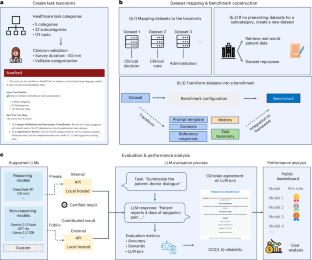
Хотя большие языковые модели (LLM) показывают почти идеальные результаты на экзаменах по лицензированию медицинских специалистов, эти оценки неадекватно отражают сложность и разнообразие реальной клинической практики. Здесь мы представляем MedHELM — расширяемую систему оценки, включающую три основных компонента. Во-первых, проверенную врачами таксономию, организующую приложения медицинского ИИ в пять категорий, отражающих реальные клинические задачи: поддержка принятия клинических решений (диагностические решения, планирование лечения), генерация клинических записей (документация посещений, отчеты о процедурах), общение с пациентами (образовательные материалы, инструкции по уходу), медицинские исследования (анализ литературы, анализ клинических данных) и администрирование (планирование, координация рабочих процессов). Эти категории включают 22 подкатегории и 121 конкретную задачу, отражающую повседневную медицинскую практику. Во-вторых, всеобъемлющий набор из 37 оценочных критериев, охватывающих все подкатегории. В-третьих, проведено систематическое сравнение девяти перспективных моделей LLM — Claude 3.5 Sonnet, Claude 3.7 Sonnet, DeepSeek R1, Gemini 1.5 Pro, Gemini 2.0 Flash, GPT-4o, GPT-4o mini, Llama 3.3 и o3-mini — с использованием автоматизированного метода оценки жюри LLM. Наше жюри LLM использует нескольких экспертов по искусственному интеллекту для оценки результатов работы моделей по критериям, определенным экспертами. Передовые модели рассуждений (DeepSeek R1, o3-mini) продемонстрировали превосходные результаты с показателем успеха в 66%, хотя Claude 3.5 Sonnet показала сопоставимые результаты при 15% меньших вычислительных затратах. Эти результаты не только подчеркивают текущие возможности моделей, но и демонстрируют, как MedHELM может обеспечить выбор медицинских систем искусственного интеллекта для применения в здравоохранении на основе фактических данных.
Купить или оформить подписку.
Это предварительный просмотр контента по подписке, доступ к которому осуществляется через ваше учреждение.
Варианты доступа
Получите доступ к журналу Nature и еще 54 журналам из портфолио Nature.
Оформите подписку Nature+, нашу самую выгодную подписку на онлайн-доступ.
27,99 € / 30 дней
отменить в любое время
Узнать больше
Подпишитесь на этот журнал
Получите 12 печатных выпусков и доступ к онлайн-версии.
251,40 € в год
всего 20,95 € за выпуск
Узнать больше
Купить эту статью
- Купить на SpringerLink
- Мгновенный доступ к полному PDF-файлу статьи.
39,95 €
К ценам могут применяться местные налоги, которые рассчитываются при оформлении заказа.
Дополнительные варианты доступа:

Похожий контент просматривают другие пользователи.
Оценка эффективности работы крупных языковых моделей на корейском медицинском лицензионном экзамене: трехлетний сравнительный анализ.
Источник: www.nature.com
Оцените материал:
