Генерация текста с помощью трансформеров: различные методы декодирования
Примечание : Отредактировано в июле 2023 года с учетом актуальных ссылок и примеров.
Введение
В последние годы наблюдается растущий интерес к генерации открытого языка благодаря появлению больших языковых моделей на основе трансформеров, обученных на миллионах веб-страниц, включая ChatGPT от OpenAI и LLaMA от Meta. Результаты в области генерации открытого языка с учетом условий впечатляют: модели демонстрируют способность к обобщению на новые задачи, обработке кода или приему нетекстовых данных в качестве входных данных. Помимо улучшенной архитектуры трансформеров и огромных объемов обучающих данных без учителя, важную роль сыграли и более совершенные методы декодирования .
В этой статье представлен краткий обзор различных стратегий декодирования, и, что более важно, показано, как их можно реализовать с минимальными усилиями, используя популярную библиотеку transformers!
Все перечисленные ниже функции могут быть использованы для авторегрессивной генерации языка (здесь краткое напоминание). Вкратце, авторегрессивная генерация языка основана на предположении, что распределение вероятностей последовательности слов может быть разложено на произведение условных распределений следующих слов:
P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,при w1:0=∅, P(w_{1:T} | W_0 ) = prod_{t=1}^TP(w_{t} | w_{1: t-1}, W_0) text{ ,при } w_{1: 0} = emptyset,
и W0W_0 — это исходная последовательность слов в контексте. Длина TT Значение в последовательности слов обычно определяется в режиме реального времени и соответствует временному шагу t=Tt=T EOS генерируется из P(wt∣w1:t−1,W0)P(w_{t} | w_{1: t-1}, W_{0}) .
Мы рассмотрим наиболее распространенные на данный момент методы декодирования, в основном жадный поиск, поиск с помощью луча и метод выборки.
Давайте быстро установим трансформеры и загрузим модель. Для демонстрации мы будем использовать GPT2 в PyTorch, но API полностью совпадает для TensorFlow и JAX.
!pip install -q transformers from transformers import AutoModelForCausalLM, AutoTokenizer import torch torch_device = «cuda» if torch.cuda.is_available() else «cpu» tokenizer = AutoTokenizer.from_pretrained( «gpt2» ) # добавить токен EOS в качестве токена PAD, чтобы избежать предупреждений model = AutoModelForCausalLM.from_pretrained( «gpt2» , pad_token_id=tokenizer.eos_token_id).to(torch_device)
Жадный поиск
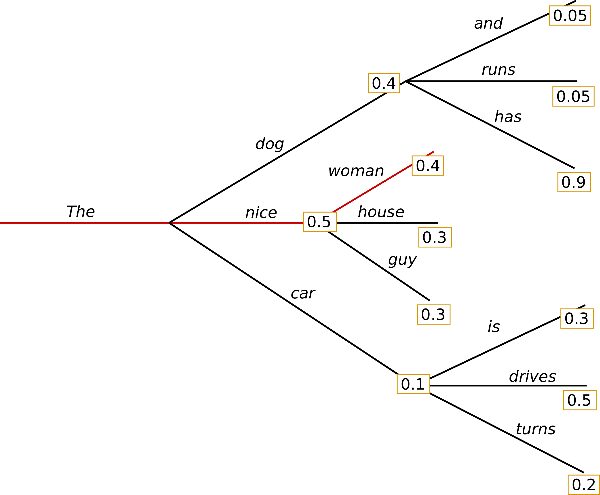
Жадный поиск — это простейший метод декодирования. Он выбирает слово с наибольшей вероятностью в качестве следующего слова: wt = argmaxwP(w∣w1:t−1)w_t = argmax_{w}P(w | w_{1:t-1}) на каждом временном шаге tt На рисунке показан жадный поиск.

Начиная со слова «The»,text{«The»}, выбирает следующее слово с наибольшей вероятностью — «nice»text{«nice»}. и так далее, так что итоговая сгенерированная последовательность слов выглядит так: («The»,»nice»,»woman»)(text{«The»}, text{«nice»}, text{«woman»}) имеет общую вероятность 0,5 × 0,4 = 0,20,5 × 0,4 = 0,2 .
Далее мы будем генерировать последовательности слов с помощью GPT2 на основе контекста («I»,»enjoy»,»walking»,»with»,»my»,»cute»,»dog»)(text{«I»}, text{«enjoy»}, text{«walking»}, text{«with»}, text{«my»}, text{«cute»}, text{«dog»}) . Давайте посмотрим, как жадный поиск может быть использован в трансформерах:
# кодирование контекста, на котором основана генерация model_inputs = tokenizer( 'Мне нравится гулять со своей милой собакой' , return_tensors= 'pt' ).to(torch_device) # генерация 40 новых токенов greedy_output = model.generate(**model_inputs, max_new_tokens= 40 ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(greedy_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой, но я не уверен, смогу ли я когда-нибудь гулять со своей собакой. Я не уверен, смогу ли я когда-нибудь гулять со своей собакой. Я не уверен
Отлично! Мы сгенерировали наш первый короткий текст с помощью GPT2 😊. Сгенерированные слова, соответствующие контексту, вполне приемлемы, но модель быстро начинает повторяться! Это очень распространенная проблема в генерации языка в целом, и, похоже, она еще более характерна для жадных алгоритмов и алгоритмов поиска по лучу — см. работы Виджаякумара и др., 2016 и Шао и др., 2017.
Однако главный недостаток жадного поиска заключается в том, что он пропускает слова с высокой вероятностью, скрытые за словами с низкой вероятностью, как это видно на приведенной выше схеме:
Слово «has»text{«has»} с высокой условной вероятностью 0,90.9 скрыто за словом «собака»text{«собака»} , которая имеет лишь вторую по величине условную вероятность, так что жадный поиск пропускает последовательность слов «The»,»dog»,»has»text{«The»}, text{«dog»}, text{«has»} .
К счастью, у нас есть алгоритм поиска по лучу, который решает эту проблему!
Поиск луча
Поиск по лучу снижает риск пропуска скрытых последовательностей слов с высокой вероятностью, сохраняя на каждом шаге наиболее вероятные num_beams гипотез и в конечном итоге выбирая гипотезу с наибольшей общей вероятностью. Проиллюстрируем это на примере num_beams=2:
На первом временном шаге, помимо наиболее вероятной гипотезы («The»,»nice»)(text{«The»}, text{«nice»}) , поиск по лучу также отслеживает второй наиболее вероятный вариант («The»,»dog»)(text{«The»}, text{«dog»}) . На втором шаге алгоритм поиска с помощью луча обнаруживает, что последовательность слов («The»,»dog»,»has»)(text{«The»}, text{«dog»}, text{«has»}) , имеет с 0.360.36 более высокая вероятность, чем («The»,»nice»,»woman»)(text{«The»}, text{«nice»}, text{«woman»}) , которая имеет 0.20.2 . Отлично, программа нашла наиболее вероятную последовательность слов в нашем примере с игрушечной игрушкой!
Метод поиска с использованием луча всегда находит выходную последовательность с большей вероятностью, чем жадный поиск, но не гарантирует нахождение наиболее вероятного результата.
Давайте посмотрим, как поиск по лучу может использоваться в трансформерах. Мы устанавливаем num_beams > 1 и early_stopping=True, чтобы генерация завершалась, когда все гипотезы о лучах достигают токена EOS.
# Активируем поиск по лучу и раннюю остановку beam_output = model.generate( **model_inputs, max_new_tokens= 40 , num_beams= 5 , early_stopping= True ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(beam_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я не уверена
Хотя результат, возможно, и более плавный, в выходных данных все еще встречаются повторения одних и тех же последовательностей слов. Одним из доступных решений является введение штрафов за n-граммы (или последовательности из n слов), как это было предложено Паулюсом и др. (2017) и Кляйном и др. (2017). Наиболее распространенный штраф за n-граммы гарантирует, что ни одна n-грамма не появится дважды, путем ручной установки вероятности следующих слов, которые могли бы создать уже встречающуюся n-грамму, равной 0.
Давайте попробуем установить параметр no_repeat_ngram_size=2, чтобы ни одна 2-грамма не появлялась дважды:
# установить no_repeat_ngram_size равным 2 beam_output = model.generate( **model_inputs, max_new_tokens= 40 , num_beams= 5 , no_repeat_ngram_size= 2 , early_stopping= True ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(beam_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я думала об этом уже некоторое время, и думаю, что мне пора
Отлично, выглядит намного лучше! Видно, что повторов больше нет. Тем не менее, штрафы за n-граммы следует использовать с осторожностью. В статье, посвященной городу Нью-Йорку, не следует использовать штраф в 2-граммы, иначе название города появится во всем тексте только один раз!
Еще одна важная особенность поиска по лучу заключается в том, что мы можем сравнить лучшие лучи после генерации и выбрать тот, который лучше всего соответствует нашим целям.
В трансформерах мы просто устанавливаем параметр num_return_sequences равным количеству лучей с наивысшим баллом, которые должны быть возвращены. Однако убедитесь, что num_return_sequences <= num_beams!
# установить return_num_sequences > 1 beam_outputs = model.generate( **model_inputs, max_new_tokens= 40 , num_beams= 5 , no_repeat_ngram_size= 2 , num_return_sequences= 5 , early_stopping= True ) # теперь у нас есть 3 выходные последовательности print ( «Выход:n» + 100 * '-' ) for i, beam_output in enumerate (beam_outputs): print ( «{}: {}» . format (i, tokenizer.decode(beam_output, skip_special_tokens= True ))) Вывод: —————————————————————————————————- 0: Мне нравится гулять со своей милой собакой, но я не уверен, смогу ли я когда-нибудь снова гулять с ней. Я уже давно об этом думаю, и думаю, пора мне 1: Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я уже давно об этом думаю, и думаю, пора мне 2: Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я уже давно об этом думаю, и думаю, это хорошая идея 3: Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я уже давно об этом думаю, и думаю, пора сделать перерыв 4: Мне нравится гулять со своей милой собакой, но я не уверена, смогу ли я когда-нибудь снова гулять с ней. Я уже давно об этом думаю, и думаю, это хорошая идея.
Как видно, пять гипотез, основанных на анализе лучей, лишь незначительно отличаются друг от друга, что не должно вызывать особого удивления при использовании всего пяти лучей.
В контексте генерации с открытым концом были выдвинуты несколько причин, по которым поиск по лучу может быть не самым лучшим вариантом:
-
Поиск по лучу может очень хорошо работать в задачах, где длина желаемого результата более или менее предсказуема, как, например, в машинном переводе или суммаризации — см. Murray et al. (2018) и Yang et al. (2018). Но это не относится к задачам генерации с открытым концом, где желаемая длина результата может сильно варьироваться, например, генерация диалогов и рассказов.
-
Мы видели, что алгоритм поиска по лучу сильно страдает от повторяющейся генерации. Это особенно трудно контролировать с помощью штрафов за n-граммы или других методов генерации историй, поскольку поиск оптимального компромисса между подавлением повторений и повторяющимися циклами идентичных n-грамм требует тщательной настройки.
-
Как утверждается в работе Ари Хольцмана и др. (2019), высококачественный человеческий язык не подчиняется распределению слов с высокой вероятностью. Другими словами, мы, люди, хотим, чтобы сгенерированный текст удивлял нас, а не был скучным/предсказуемым. Авторы наглядно демонстрируют это, построив график зависимости вероятности, которую модель присвоила бы человеческому тексту, от вероятности, которую дает поиск по лучу.
Так что давайте перестанем быть скучными и добавим немного случайности 🤪.
Отбор проб
В своей простейшей форме выборка означает случайный выбор следующего слова wtw_t. согласно его условному распределению вероятностей:
wt∼P(w∣w1:t−1) w_t sim P(w|w_{1:t-1})
Возвращаясь к приведенному выше примеру, на следующем графике визуализируется генерация языка при сэмплировании.
Становится очевидным, что генерация языка с использованием выборки больше не является детерминированной. Слово («машина»)(text{«машина»}) выбирается из обусловленного распределения вероятностей P(w∣»The»P(w | text{«The»}) , с последующим отбором проб («drives»)(text{«drives»}) из P(w∣»The»,»car»P(w | text{«The»}, text{«car»}) .
В трансформерах мы устанавливаем do_sample=True и отключаем выборку Top-K (подробнее об этом позже) с помощью top_k=0. Далее мы зафиксируем начальное значение генератора случайных чисел для наглядности. Вы можете изменить аргумент set_seed, чтобы получить другие результаты, или удалить его для обеспечения недетерминированности.
# Установите начальное значение генератора случайных чисел для воспроизведения результатов. Вы можете изменить начальное значение генератора случайных чисел, чтобы получить другие результаты от трансформеров. Импортируем set_seed set_seed( 42 ) # Активируем выборку и деактивируем top_k, установив top_k sampling равным 0 sample_output = model.generate(**model_inputs, max_new_tokens= 40 , do_sample= True , top_k= 0 ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(sample_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой весь остаток дня, но из-за этого мне пришлось остаться в необычном номере и не ходить на вечеринки с друзьями (что всегда будет вызывать вопросы хотя бы на минуту).
Интересно! Текст кажется нормальным, но при ближайшем рассмотрении он не очень связный и не звучит так, будто его написал человек. В этом и заключается главная проблема при обработке последовательностей слов: модели часто генерируют бессвязный набор бессмысленных символов, см. Ari Holtzman et al. (2019).
Хитрость заключается в том, чтобы сделать распределение P(w∣w1:t−1)P(w|w_{1:t-1}) более резкий (увеличивая вероятность слов с высокой вероятностью и уменьшая вероятность слов с низкой вероятностью) за счет снижения так называемой температуры функции softmax.
Пример применения температуры к нашему примеру, приведенному выше, можно представить следующим образом.
Условное распределение следующего слова на шаге t=1t=1 становится намного острее, практически не оставляя шансов для слова («car»)(text{«car»}) будет выбран.
Давайте посмотрим, как можно охладить дистрибутив в библиотеке, установив температуру равной 0,6:
# Установите начальное значение генератора случайных чисел для воспроизведения результатов. Вы можете изменить начальное значение генератора случайных чисел, чтобы получить другие результаты. set_seed( 42 ) # Используйте температуру для уменьшения чувствительности к кандидатам с низкой вероятностью. sample_output = model.generate(**model_inputs, max_new_tokens= 40 , do_sample= True , top_k= 0 , temperature= 0.6 ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(sample_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой, но я не люблю её грызть. Мне нравится её есть, а не грызть. Мне нравится гулять со своей собакой.» Так как же вы решили?
Хорошо. Странных n-грамм стало меньше, и выходные данные стали немного более согласованными! Хотя применение температуры может сделать распределение менее случайным, в пределе, когда температура устанавливается →0to 0, , выборка с температурной шкалой становится эквивалентной жадному декодированию и будет страдать от тех же проблем, что и раньше.
Выборка Top-K
Фан и др. (2018) представили простую, но очень эффективную схему выборки, называемую выборкой Top-K . При выборке Top-K отфильтровываются K наиболее вероятных следующих слов, и вероятностная масса перераспределяется только между этими K следующими словами. GPT2 использовал эту схему выборки, что стало одной из причин его успеха в генерации историй.
В приведенном выше примере мы расширяем диапазон слов, используемых на обоих этапах выборки, с 3 до 10 слов, чтобы лучше проиллюстрировать метод выборки Top-K.
При K=6K = 6 На обоих этапах выборки мы ограничиваем наш набор слов шестью словами. При этом шесть наиболее вероятных слов определяются как Vtop-KV_{text{top-K}} На первом этапе он охватывает лишь около двух третей всей вероятностной массы, а на втором — включает почти всю вероятностную массу. Тем не менее, мы видим, что он успешно исключает довольно странные кандидаты («не», «тот», «маленький», «сказанный») (text{«не`, text{«тот`, text{«маленький`, text{«сказанный`) на втором этапе отбора проб.
Давайте посмотрим, как можно использовать Top-K в библиотеке, установив top_k=50:
# Установите начальное значение генератора случайных чисел для воспроизведения результатов. Вы можете изменить начальное значение генератора случайных чисел, чтобы получить другие результаты. set_seed( 42 ) # Установите top_k равным 50 sample_output = model.generate(**model_inputs, max_new_tokens= 40 , do_sample= True , top_k= 50 ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(sample_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой весь остаток дня, но на этот раз мне было трудно придумать, что с ней делать. (Одна из причин, по которой я задал этот вопрос несколько месяцев назад, заключается в том, что у меня был
Совсем неплохо! Этот текст, пожалуй, самый человекоподобный из всех, что я встречал до сих пор. Однако есть одна проблема с методом выборки Top-K: он не адаптирует динамически количество слов, отфильтрованных из распределения вероятностей следующего слова P(w∣w1:t−1)P(w|w_{1:t-1}). может быть проблематично, поскольку некоторые слова могут быть выбраны из очень резкого распределения (распределение справа на графике выше), в то время как другие — из гораздо более пологого распределения (распределение слева на графике выше).
На шаге t=1t=1 Метод Top-K исключает возможность выборки («люди»,»большой»,»дом»,»кот»)(«люди», «большой»», «дом», «кот») , которые кажутся разумными кандидатами. С другой стороны, на шаге t=2t=2 Метод включает в себя, возможно, неподходящие слова («вниз», «а»)(«вниз», «а») в пуле слов-выборок. Таким образом, ограничение пула выборок фиксированным размером K может поставить под угрозу способность модели выдавать бессмысленный набор символов при четких распределениях и ограничить ее креативность при плоских распределениях. Эта интуиция привела Ари Хольцмана и др. (2019) к созданию метода выборки Top-p или ядра .
Выборка Top-p (ядро)
Вместо того чтобы выбирать только из наиболее вероятных K слов, в методе Top-p выборка осуществляется из наименьшего возможного набора слов, кумулятивная вероятность которых превышает вероятность p. Затем вероятностная масса перераспределяется между этим набором слов. Таким образом, размер набора слов (т.е. количество слов в наборе) может динамически увеличиваться и уменьшаться в соответствии с распределением вероятностей следующего слова. Ладно, это было очень многословно, давайте представим.
При заданном значении p=0,92, p=0,92 . Метод выборки Top-p выбирает минимальное количество слов, превышающее в сумме p=92%. от массы вероятности, определяемой как Vtop-pV_{text{top-p}} В первом примере это включало 9 наиболее вероятных слов, тогда как во втором примере достаточно выбрать всего 3 наиболее вероятных слова, чтобы превысить 92%. На самом деле все довольно просто! Видно, что алгоритм сохраняет широкий диапазон слов, где следующее слово, возможно, менее предсказуемо, например , P(w∣»The»)P(w | text{«The''}) , и лишь несколько слов, когда следующее слово кажется более предсказуемым, например , P(w∣»The»,»car»)P(w | text{«The»}, text{«car»}) .
Итак, пора проверить это в трансформерах! Мы активируем выборку Top-p, установив 0 < top_p < 1:
# Установите начальное значение генератора случайных чисел для воспроизведения результатов. Вы можете изменить начальное значение генератора случайных чисел, чтобы получить другие результаты. set_seed( 42 ) # Установите top_k равным 50 sample_output = model.generate(**model_inputs, max_new_tokens= 40 , do_sample= True , top_p= 0.92 , top_k= 0 ) print ( «Вывод:n» + 100 * '-' ) print (tokenizer.decode(sample_output[ 0 ], skip_special_tokens= True )) Вывод: —————————————————————————————————- Мне нравится гулять со своей милой собакой весь остаток дня, но из-за этого мне пришлось остаться в необычном номере и не ходить на вечеринки с друзьями (а я всегда буду мечтать о таком большом экране на своем столе).
Отлично, звучит так, будто это написал человек. Ну, может, пока еще нет.
Хотя теоретически Top-p кажется более элегантным, чем Top-K, на практике оба метода работают хорошо. Top-p также можно использовать в сочетании с Top-K, что позволяет избегать слов с очень низким рейтингом, обеспечивая при этом некоторую динамическую селекцию.
Наконец, чтобы получить несколько независимо отобранных выходных данных, мы можем снова установить параметр num_return_sequences > 1:
# Установите начальное значение генератора случайных чисел для воспроизведения результатов. Не стесняйтесь менять начальное значение генератора случайных чисел, чтобы получить другие результаты. set_seed( 42 ) # установить top_k = 50 и top_p = 0.95 и num_return_sequences = 3 sample_outputs = model.generate(**model_inputs, max_new_tokens= 40 , do_sample= True , top_k= 50 , top_p= 0.95 , num_return_sequences= 3 ) print ( «Вывод:n» + 100 * '-' ) for i, sample_output in enumerate (sample_outputs): print ( «{}: {}» . format (i, tokenizer.decode(sample_output, skip_special_tokens= True ))) Вывод: —————————————————————————————————- 0: Мне нравится гулять со своей милой собакой весь остаток дня, но на этот раз мне было тяжело Придумать, что с этим делать. Когда я наконец-то посмотрела на это несколько минут, я сразу подумала: «1. Мне нравится гулять со своей милой собачкой. Единственное время, когда мне хотелось гулять, это когда я работала, поэтому это было здорово. Я не хотела гулять целыми днями. Мне очень любопытно, как она может гулять со мной. 2. Мне нравится гулять со своей милой собачкой (Чама-IIII), и мне очень нравится бегать. Я играю в небольшую игру со своим братом, в которой фотографирую наши дома».
Отлично, теперь у вас есть все инструменты, чтобы ваша модель могла писать ваши истории с помощью трансформеров!
Заключение
В качестве методов декодирования ad-hoc, выборка top-p и top-K, по-видимому, обеспечивает более беглый текст, чем традиционные жадные алгоритмы и алгоритм поиска по лучу при генерации открытого языка. Есть данные, свидетельствующие о том, что очевидные недостатки жадных алгоритмов и алгоритма поиска по лучу — в основном, генерация повторяющихся последовательностей слов — вызваны моделью (особенно способом ее обучения), а не методом декодирования (см. Welleck et al. (2019)). Кроме того, как показано в Welleck et al. (2020), похоже, что выборка top-K и top-p также страдает от генерации повторяющихся последовательностей слов.
В работе Веллека и др. (2019) авторы показывают, что, согласно оценкам людей, метод поиска по лучу может генерировать более плавный текст, чем метод выборки Top-p, при условии адаптации целевой функции обучения модели.
Генерация открытого языка — это быстро развивающаяся область исследований, и, как это часто бывает, здесь нет универсального метода, поэтому необходимо выяснить, что лучше всего подходит для конкретного случая.
К счастью, вы можете опробовать все различные методы декодирования в трансформаторах 🤗 — обзор доступных методов можно найти здесь.
Спасибо всем, кто внес свой вклад в эту запись в блоге: Александру Рашу, Жюльену Шоману, Томасу Вольфу, Виктору Санху, Сэму Шлейферу, Клеману Делангу, Ясину Йерните, Оливеру Остранду и Джону де Вассейгу.
Приложение
Функция generate превратилась в очень гибкий метод с флагами для управления результирующим текстом в самых разных направлениях, которые не были рассмотрены в этой статье. Вот несколько полезных страниц, которые помогут вам:
-
Как параметризовать генерацию
-
Как транслировать вывод
-
Полный список вариантов декодирования
-
сгенерировать справочник API
-
Таблица лидеров по результатам LLM
Если вам сложно ориентироваться в нашей документации и вы не можете легко найти то, что ищете, напишите нам в этом обсуждении на GitHub. Ваши отзывы крайне важны для определения нашего дальнейшего направления! 🤗
Оцените материал:
