Изучение векторных представлений слов для анализа настроения: воспроизведение на Python.
Как создать представления слов с учетом эмоциональной окраски отзывов на IMDb, используя семантическое обучение, звездные рейтинги и линейную классификацию SVM.
Делиться

Мы автоматизировали анализ и разместили код на GitHub.
Идея для этой статьи пришла ко мне, когда я попытался воспроизвести работу Мааса и др. (2011) «Изучение векторных представлений слов для анализа настроений».
В то время я ещё учился на последнем курсе инженерного факультета. Цель заключалась в том, чтобы воспроизвести статью, подвергнуть сомнению методы авторов и, если возможно, сравнить их с другими способами представления слов, включая подходы, основанные на LLM.
Меня поразила простота и элегантность этого метода. В некотором смысле он напомнил мне логистическую регрессию в кредитном скоринге: простой, понятный и при этом эффективный при правильном применении.
Мне так понравилось читать эту статью, что я решил поделиться тем, что узнал из неё.
Настоятельно рекомендую прочитать оригинальную статью. Она поможет вам понять, что поставлено на карту в представлении слов, особенно как анализировать близость между двумя словами как с семантической точки зрения, так и с точки зрения эмоциональной полярности, учитывая конкретные контексты, в которых эти слова используются.
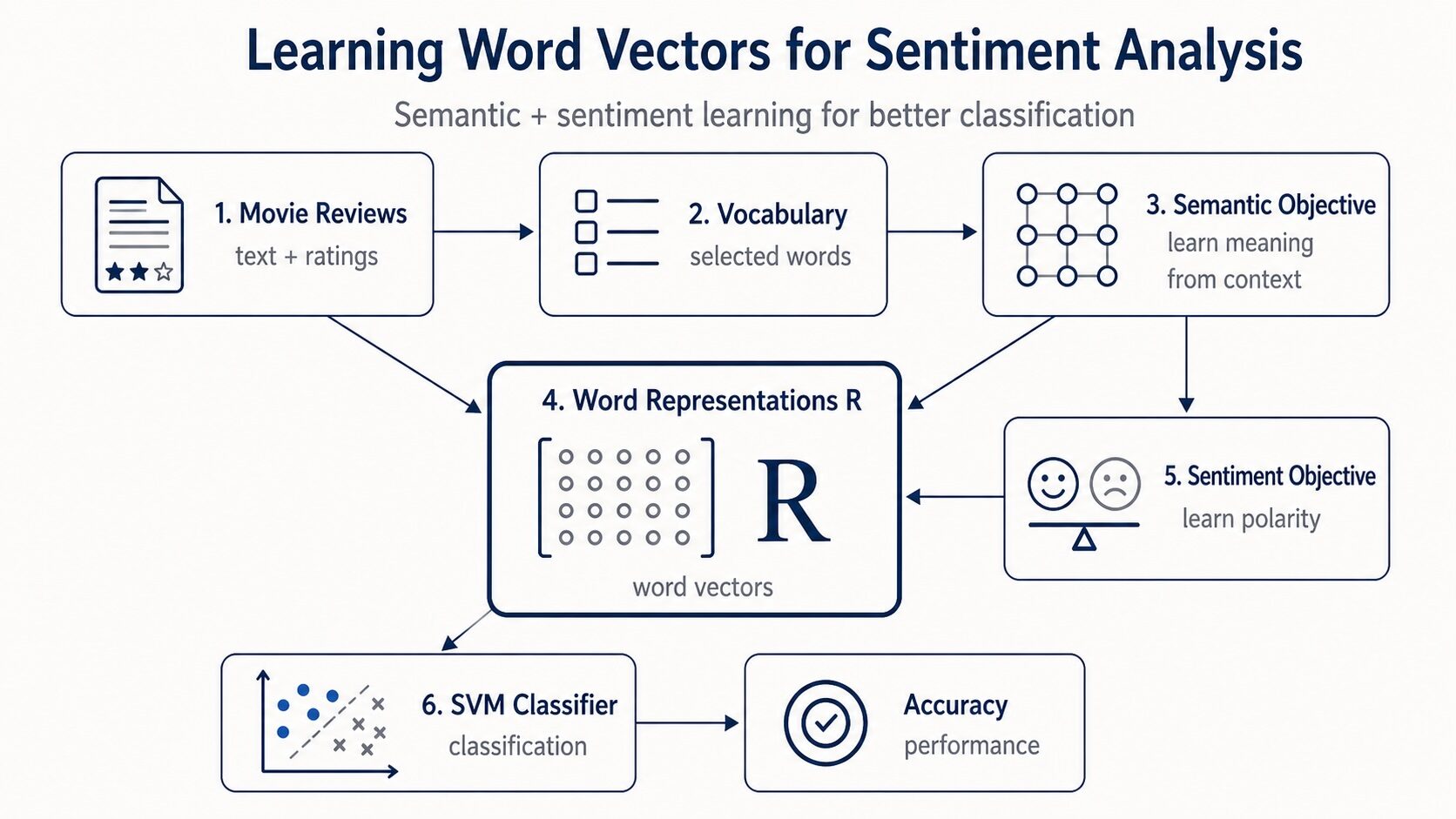
На первый взгляд, модель кажется простой: создать словарь, изучить векторные представления слов, учесть информацию об эмоциональной окраске текста и оценить результаты на основе отзывов IMDb.
Но когда я начал внедрять это, я понял, что несколько деталей имеют огромное значение: как строится словарь, как представляются векторные представления документов, как оптимизируется семантическая цель и как сигнал настроения вводится в векторные представления слов.
В этой статье мы воспроизведем основные идеи работы, используя Python.
Сначала мы объясним основную идею модели. Затем представим структуру данных, использованных в статье, построим словарь, реализуем семантический компонент, добавим целевую функцию для анализа тональности и, наконец, оценим полученные представления с помощью линейного SVM-классификатора.
Метод опорных векторов (SVM) позволит нам измерить точность классификации и сравнить наши результаты с результатами, представленными в статье.
Какую проблему решает эта статья?
Традиционные модели «мешка слов» полезны для классификации, но они не изучают осмысленные связи между словами. Например, слова «замечательный» и «удивительный» должны быть близки, потому что они выражают схожее значение и схожие чувства. С другой стороны, слова «замечательный» и «ужасный» могут встречаться в схожих контекстах рецензий на фильмы, но выражать противоположные чувства.
Цель данной работы — построить векторные представления слов, отражающие как семантическое сходство, так и эмоциональную окраску.
Структура данных
Набор данных содержит:
- 25 000 помеченных обзоров или документов по обучению
- 50 000 немаркированных отзывов об обучении
- 25 000 размеченных обзоров тестов
Отзывы, помеченные как содержащие противоречивые мнения, отличаются поляризацией:
- Отрицательные отзывы имеют оценки от 1 до 4.
- Положительные отзывы имеют оценки от 7 до 10.
Рейтинги линейно отображаются в интервал [0, 1], что позволяет модели рассматривать настроение как непрерывную вероятность положительной полярности.
aclImdb/ ├── train/ │ ├── pos/ "0_10.txt" -> review #0, 10 stars, very positive │ │ "1_7.txt" -> review #1, 7 stars, positive │ ├── neg/ "10_2.txt" -> review #10, 2 stars, very negative │ │ "25_4.txt" -> review #25, 4 stars, negative │ └── unsup/ "938_0.txt" -> review #938, 0 stars, unlabeled └── test/ ├── pos/ positive reviews, never seen during training └── neg/ negative reviews, never seen during training
Таким образом, мы можем хранить каждый документ в классе Review со следующими атрибутами: text , stars , label и bucket .
Конечно, это не обязательно должен быть класс с конкретным названием Review . Можно использовать любой объект, если он предоставляет хотя бы эти атрибуты.
from dataclasses import dataclass from typing import Optional @dataclass class Review: text: str stars: int label: str bucket: str
построение словарного запаса
В данной работе фиксированный словарь формируется путем первоначального исключения 50 наиболее часто встречающихся терминов, а затем сохранения следующих 5000 наиболее часто встречающихся элементов.
Стемминг не применяется. Стандартное удаление стоп-слов не используется. Это важно, поскольку некоторые стоп-слова, особенно отрицания, могут нести в себе информацию о настроении.
Прежде чем формировать этот словарь, нам сначала нужно взглянуть на исходные данные.
Мы заметили, что отзывы не полностью очищены. Некоторые документы содержат HTML-теги, поэтому мы удаляем их на этапе загрузки данных. Мы также удаляем знаки препинания, прикрепленные к словам, такие как "." , "," , "!" или "?" .
Это небольшое отличие от оригинальной статьи. Авторы сохраняют некоторые несловесные токены, поскольку они могут помочь уловить эмоциональную окраску. Например, "!" или ":-)" могут передавать эмоциональную информацию. В нашей реализации мы решили удалить эти знаки препинания и позже оценим, насколько это решение влияет на итоговую производительность модели.
При работе с текстовыми данными следующий вопрос всегда один и тот же:
Как следует представлять документы и слова в числовом виде?
Авторы начинают с того, что собирают все токены из обучающего набора, включая как размеченные, так и неразмеченные отзывы. Можно представить это как сбор всех слов из обучающих документов в одну большую корзину.
Затем, чтобы представить слова в пространстве, где мы можем обучить модель, они создают набор слов, называемый словарем.
Авторы создают словарь, который сопоставляет каждый токен (который мы будем условно называть словом) с его частотой. Эта частота — просто количество раз, когда токен встречается в полном обучающем наборе данных, включая как размеченные, так и неразмеченные отзывы.
Затем они отбирают 5000 наиболее часто встречающихся слов, предварительно удалив 50 наиболее часто встречающихся терминов.
Эти 5000 слов образуют словарный запас V.
Каждое слово в V будет соответствовать одному столбцу матрицы представления R. Авторы решили представлять каждое слово в 50-мерном пространстве. Следовательно, матрица R имеет следующую форму:
R∈ℝβ=50×|V|=5000R in mathbb{R}^{beta = 50times |V| = 5000}
Каждый столбец матрицы R представляет собой векторное представление одного слова: ϕw = Rw phi_w = Rw
Цель модели — обучить матрицу R таким образом, чтобы векторные представления слов одновременно отражали две вещи:
- Семантическая информация, то есть слова, используемые в схожих контекстах, должны быть близки по значению;
- Информация об эмоциональном состоянии, то есть слова со схожей полярностью, также должны быть близки по смыслу.
Это главная идея данной работы.
После загрузки, очистки данных и создания словаря мы можем перейти к построению самой модели.
Первая часть модели является неконтролируемой. Она обучается семантическим представлениям слов как на основе размеченных, так и неразмеченных отзывов.
Затем, во второй части добавляется контроль, используя звездные рейтинги для внесения эмоциональной окраски в то же векторное пространство.
Семантический компонент
Семантический компонент определяет вероятностную модель документа.
Каждому документу соответствует скрытый вектор тета. Этот вектор представляет собой семантическое направление документа.
Каждое слово имеет векторное представление ϕw phi_w, хранящееся в виде столбца матрицы R.
Вероятность обнаружения слова w в документе определяется моделью softmax:
p(w|θ;R,b)=exp(θ⊤ϕw+bw)∑w′∈Vexp(θ⊤ϕw′+bw′)p(w mid theta; R, b) = frac{exp(theta^top phi_w + b_w)}{sum_{w' in V} exp(theta^top phi_{w'} + b_{w'})}
Интуитивно понятно, что слово становится вероятным, когда его вектор ϕwphi_w хорошо совпадает с вектором theta документа.
Оценка MAP тета
Модель чередует два этапа.
Во-первых, он фиксирует R и b и оценивает один вектор тета для каждого документа.
Затем программа исправляет значение тета и обновляет значения R и b.
Векторы тета не сохраняются в качестве конечных параметров. Это временные переменные, специфичные для документа, используемые для обновления представлений слов.
Для оценки параметров модели авторы используют метод максимального правдоподобия.
Идея проста: мы хотим найти параметры R и b, которые делают наблюдаемые документы максимально вероятными в рамках модели.
Исходя из вероятностной формулировки документа, они вводят оценку MAP θ̂ₖ для каждого документа dₖ. Затем, взяв логарифм функции правдоподобия и добавив члены регуляризации, они получают целевую функцию, используемую для обучения матрицы представления слов R и вектора смещения b:
? sum_{i=1}^{N_k} log p(w_i mid hat{theta}_k; R, b)
который максимизируется относительно R и b. Гиперпараметрами модели являются веса регуляризации (λ и ν) и размерность векторного представления слова β.
На этом этапе мы изучаем матрицу семантического представления. Эта матрица отражает взаимосвязь слов в зависимости от контекста, в котором они встречаются.
Компонент настроения
Семантическая модель сама по себе может научиться распознавать слова в схожих контекстах. Но этого недостаточно для определения эмоциональной окраски слов.
Например, в кинорецензиях могут встречаться как слова «прекрасно», так и слова «ужасно», но они выражают противоположные мнения.
Для решения этой проблемы в статье добавлена функция оценки тональности текста с обучением под наблюдением:
p(s=1|w;R,ψ)=σ(ψ⊤ϕw+bc)p(s = 1 mid w; R, psi) = sigma(psi^top phi_w + b_c)
Вектор ψ определяет направление эмоциональной окраски слов в векторном пространстве слов. Здесь используются только размеченные данные.
Если вектор слова лежит с одной стороны гиперплоскости, он считается положительным. Если он лежит с другой стороны, он считается отрицательным.
Они объединили целевую задачу, связанную с анализом настроений, и часть, касающуюся анализа настроений, чтобы сформировать итоговую и полную целевую модель обучения:
ν‖R‖F2+∑k=1|D|λ‖θ^k‖22+∑i=1NklogP(wi|θ^k;R,b)+∑k=1|D|1|Sk|∑i=1NklogP(sk|wi;R,ψ,bc)begin{aligned} nu |R|_F^2 &+ sum_{k=1}^{|D|} lambda |hat{theta}_k|_2^2 + sum_{i=1}^{N_k} log P(w_i mid hat{theta}_k; R, b) &+ sum_{k=1}^{|D|} frac{1}{|S_k|} sum_{i=1}^{N_k} log P(s_k mid w_i; R, psi, b_c) end{aligned}
Первая часть обучается семантическому сходству. Вторая часть добавляет информацию о настроении. Регуляризационные члены предотвращают чрезмерное увеличение векторов.
|SkS_k| обозначает количество документов в наборе данных с одинаковым округленным значением sks_k. Весовой коэффициент 1|Sk|frac{1}{|S_k|} введен для борьбы с известным дисбалансом оценок, присутствующим в коллекциях отзывов.
Классификация и результаты
После того как матрица представления слов R будет обучена, мы можем использовать ее для построения признаков на уровне документа.
Теперь задача состоит в том, чтобы классифицировать каждый отзыв о фильме как положительный или отрицательный.
Для этого авторы обучают линейный SVM на 25 000 размеченных обучающих отзывах и оценивают его на 25 000 размеченных тестовых отзывах.
Важный вопрос заключается не только в том, насколько осмысленны векторные представления слов, но и в том, помогают ли они улучшить классификацию настроений.
Чтобы ответить на этот вопрос, мы оцениваем несколько вариантов представления документов и сравниваем их с результатами, представленными в таблице 2 статьи.
Единственное отличие между различными конфигурациями заключается в способе представления каждого отзыва перед передачей его классификатору.
1. Базовый уровень модели «мешок слов»
Первое представление — это стандартный «мешок слов». В статье этот базовый вариант обозначается как «мешок слов» (bnc) . Обозначение означает:
- b = бинарное взвешивание
- n = без взвешивания IDF
- c = нормализация косинуса
Обзор или документ представляется вектором v размером 5000, поскольку словарь содержит 5000 слов.
Для каждого слова j в словаре:
νj={1, если слово j встречается в обзоре; 0, в противном случаеnu_j = begin{cases} 1 & text{если слово } j text{ встречается в обзоре} 0 & text{в противном случае} end{cases}
Таким образом, это представление фиксирует только то, встречается ли слово хотя бы один раз. Оно не подсчитывает, сколько раз оно встречается.
Затем вектор нормализуется с помощью своей евклидовой нормы:
νbnc=ν‖ν‖2nu_{bnc} = frac{nu}{|nu|_2}
Это дает базовый уровень модели «мешок слов», используемый для обучения SVM.
Этот базовый уровень является надежным, поскольку классификация настроений часто опирается на прямые лексические подсказки. Такие слова, как excellent , boring , awful или great , уже несут в себе полезную информацию о настроении.
2. Семантическое векторное представление слов
Во втором представлении используются векторные представления слов, полученные с помощью модели, учитывающей только семантику.
Сначала авторы представляют документ в виде вектора v, полученного с помощью алгоритма «мешка слов». Затем они вычисляют плотное представление документа, умножая этот вектор на полученную матрицу:
zsemantic=Rsemantic×νz_{text{semantic}} = R_{text{semantic}} times nu
Где Rsemantic∈ℝ50×5000, ν∈ℝ5000⟹zsemantic∈ℝ50R_{text{semantic}} in mathbb{R}^{50 times 5000}, nu in mathbb{R}^{5000} quadimpliesquad z_{text{semantic}} in mathbb{R}^{50}
Этот вектор можно интерпретировать как взвешенную комбинацию векторных представлений слов, встречающихся в обзоре.
В статье при генерации признаков документа с помощью произведения Rv авторы используют взвешивание bnn для v. Это означает:
- b = бинарное взвешивание
- n = без взвешивания IDF
- n = отсутствие нормализации косинуса перед проекцией
Затем, после вычисления Rv, они применяют косинусную нормализацию к итоговому плотному вектору.
Таким образом, окончательное представление выглядит следующим образом:
z‾semantic=Rsemanticν‖Rsemanticν‖2bar{z}_{text{semantic}} = frac{R_{text{semantic}} nu}{| R_{text{semantic}} nu |_2}
В данном представлении используется семантическая информация, полученная в ходе обучающих исследований, включая как размеченные, так и неразмеченные документы.
3. Полное семантическое и эмоциональное представление
Третье представление построено по тому же принципу, но использует полную матрицу Rfull.
Эта матрица обучается с использованием обоих компонентов модели:
- семантическая цель, которая изучает контекстное сходство между словами;
- Объективный показатель настроения, который учитывает информацию о полярности, полученную из звездных рейтингов.
Для каждого документа мы вычисляем:
zfull=Rfullνz_{text{full}} = R_{text{full}} nu
Затем мы проводим нормализацию:
z‾full=Rfullν‖Rfullν‖2bar{z}_{text{full}} = frac{R_{text{full}} nu}{| R_{text{full}} nu |_2}
Интуитивно понятно, что RfullR_{full} должен создавать характеристики документа, которые отражают как суть отзыва, так и то, является ли формулировка положительной или отрицательной.
Основной вклад данной работы заключается в следующем: обучение векторным представлениям слов, сочетающим семантическое сходство и эмоциональную окраску.
4. Полное представление + Мешок слов
Итоговая конфигурация объединяет полученное плотное представление с исходным представлением «мешка слов».
Мы объединяем два представления, чтобы получить:
x=[z‾full‖νbnc]x = left[ bar{z}_{text{full}} ;middle|; nu_{bnc} right]
Это дает классификатору два взаимодополняющих источника информации:
- плотное 50-мерное представление, усвоенное моделью;
- Разреженное лексическое представление, сохраняющее точную информацию о наличии слова.
Такое сочетание полезно, поскольку векторные представления слов позволяют обобщать информацию на похожие слова, в то время как функция «мешка слов» сохраняет точные лексические данные.
Например, плотное представление может научиться различать слова wonderful и amazing , в то время как представление в виде мешка слов сохраняет точное наличие каждого слова.
Затем мы обучаем линейный SVM на размеченном обучающем наборе данных и оцениваем его на тестовом наборе данных.
Это позволяет нам ответить на два вопроса.
Во-первых, улучшают ли полученные векторные представления слов классификацию тональности?
Во-вторых, помогает ли добавление информации о настроении к векторным представлениям слов помимо одной лишь семантической информации?
Реализация на Python
Мы реализуем модель в пять этапов:
- Загрузите и очистите набор данных IMDb.
- Расширьте словарный запас.
- Обучите семантический компонент
- Обучите полную семантическую модель + модель анализа настроения.
- Оцените полученные представления с помощью SVM.
В таблице ниже показаны ближайшие соседи выбранных целевых слов в обученном векторном пространстве.
Для каждого целевого слова мы указываем пять наиболее похожих слов согласно косинусному сходству. Полная модель, которая объединяет семантическую и эмоциональную цели, как правило, находит слова, близкие как по значению, так и по эмоциональной окраске. Модель, учитывающая только семантику, фиксирует контекстное и лексическое сходство, но не использует явно эмоциональные метки во время обучения.
В таблице ниже сравниваются наши результаты с результатами, представленными в статье. Для каждого представления мы обучаем линейный SVM на размеченных обучающих отзывах и сообщаем точность классификации на тестовом наборе. Это позволяет нам оценить, насколько хорошо каждое представление документа справляется с задачей классификации тональности IMDb.
Полная модель очень близка к результату, представленному в статье. Это говорит о том, что целевая функция анализа настроений реализована корректно.
Наибольший разрыв наблюдается в модели, основанной исключительно на семантике. Это может быть связано с деталями оптимизации, предварительной обработкой или способом построения признаков на уровне документа для классификации.
Заключение
В данной статье мы воспроизвели основные компоненты модели, предложенной Маасом и др. (2011).
Мы реализовали семантическую целевую функцию, добавили целевую функцию анализа тональности и оценили полученные векторные представления слов на примере классификации тональности по данным IMDb.
Модель демонстрирует, как неразмеченные данные могут помочь в изучении семантической структуры, в то время как размеченные данные могут вносить информацию об эмоциональном состоянии в то же векторное пространство.
Это простая, но мощная идея: векторные представления слов должны не только отражать их значение, но и эмоциональную окраску.
Хотя в этом посте не рассматриваются все детали статьи, мы настоятельно рекомендуем ознакомиться с оригинальной работой авторов. Наша цель заключалась в том, чтобы поделиться идеями, которые нас вдохновили, и тем удовольствием, которое мы получили как от чтения статьи, так и от написания этого поста.
Мы надеемся, что вам это понравится так же, как и нам.
Источник изображений
Все изображения и визуализации в этой статье были созданы автором с использованием Python (pandas, matplotlib, seaborn и plotly) и Excel, если не указано иное.
Ссылки
[1] 𝗔𝗻𝗱𝗿𝗲𝘄 𝗟. 𝗠𝗮𝗮𝘀, 𝗥𝗮𝘆𝗺𝗼𝗻𝗱 𝗘. 𝗗𝗮𝗹𝘆, 𝗣𝗲𝘁𝗲𝗿 𝗧. 𝗣𝗵𝗮𝗺, 𝗗𝗮𝗻 𝗛𝘂𝗮𝗻𝗴, 𝗔𝗻𝗱𝗿𝗲𝘄 𝗬. 𝗡𝗴, 𝗮𝗻𝗱 𝗖𝗵𝗿𝗶𝘀𝘁𝗼𝗽𝗵𝗲𝗿 𝗣𝗼𝘁𝘁𝘀. 2011. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA. Association for Computational Linguistics.
Набор данных: Большой набор данных отзывов о фильмах IMDb (CC BY 4.0).
JUNIOR JUMBONG Посмотреть все товары от JUNIOR JUMBONG
Источник: towardsdatascience.com
Оцените материал:
