Инфраструктура, обеспечивающая реальную полезность местных агентов LLM.
Уроки, извлеченные из создания быстрого и надежного научного агента с использованием локальных моделей с открытыми весами, vLLM и инфраструктуры с длинным контекстом.
Делиться

Запуск языковой модели локально звучит довольно просто. Скачать веса, запустить сервер и отправлять запросы. Это работает для чат-бота, но для агента это не работает автоматически. В моем случае я разрабатываю агента для автоматизированного анализа РНК-секвенирования отдельных клеток. Идея заключается в том, что, имея необработанные данные, агент может самостоятельно запустить весь конвейер обработки данных, определяя, какие инструменты использовать, считывая результаты и выполняя анализ шаг за шагом.
Вы можете спросить, почему бы просто не использовать что-то вроде Claude Code с навыком анализа отдельных клеток. Краткий ответ: для научных рабочих процессов этого недостаточно. Навыки, по сути, являются подсказками и, следовательно, могут быть переопределены или проигнорированы. Что еще важнее, научная работа требует воспроизводимости и отслеживания происхождения: точного знания того, какие параметры были использованы, какие клетки были отфильтрованы, какое разрешение кластеризации дало какой результат и т. д. Эта запись должна быть структурированной и постоянной, а не воссозданной из разговора. Для длительных сессий также необходимо явное управление состоянием системы, а не полагаться на компактизацию контекста для сохранения того, что имеет значение. Все это нужно создавать целенаправленно. Создание всего этого на основе локальной модели также означает, что вы владеете инфраструктурой, и именно на этом я собираюсь сосредоточиться здесь.
Созданный нами агент работает на высокопроизводительных вычислительных системах институционального уровня, используя новейшие модели с открытым исходным кодом. Легко предположить, что модели с открытым исходным кодом недостаточно сильны для такого рода работы. Но это становится всё менее верным. Недавние релизы, такие как Qwen3.6–27B и Gemma 4–31B, действительно полезны для структурированных, управляемых инструментами рабочих нагрузок (если вам интересно следить за развитием открытого исходного кода, на Interconnects AI есть интересные материалы, за которыми вы можете следить). И это одна из главных причин, почему локальный хостинг здесь имеет смысл. Наш агент также поддерживает облачные API, такие как Claude и GPT, но при их использовании вся инфраструктура, которую я собираюсь описать, становится для вас невидимой. Кто-то уже решил эту проблему. Когда вы размещаете модель самостоятельно, эти проблемы становятся вашими.
Когда я впервые запустил модель, она работала в узком смысле. Модель вызывала инструменты, инструменты запускались, и анализ продвигался вперед. Но она еще не была по-настоящему пригодна для использования. Простой анализ одной клетки мог содержать 50–80 вызовов инструментов в цикле. Каждый вызов нес один и тот же фиксированный багаж: системную подсказку, схемы инструментов и растущую историю диалога. Для этого агента только системная подсказка и схемы инструментов составляли около 36 тысяч токенов. Прежде чем модель могла что-либо решить, ей сначала приходилось считывать десятки тысяч токенов инструкций и определений инструментов. Затем ей приходилось делать это снова на следующей итерации. И снова на следующей. Каждая итерация занимала от 10 до 15 секунд. А длительный сеанс в конечном итоге завершался с ошибками переполнения контекста, унося с собой все состояние анализа в памяти. Эта статья посвящена решению обеих этих проблем.
Первая часть посвящена ускорению процесса вывода за счет ряда оптимизаций, применяемых к серверу вывода vLLM (движок вывода с открытым исходным кодом, созданный для высокопроизводительной обработки LLM-данных). Вторая часть посвящена поддержанию активности длительных сессий за счет улучшенного управления контекстом и структурированного состояния мира, сохраняющегося после обрезки. Я провел эксперименты на графических процессорах A100 и H100, чтобы измерить влияние каждого изменения, и они описаны ниже.
Часть 1: Ускорение процесса вывода заключений
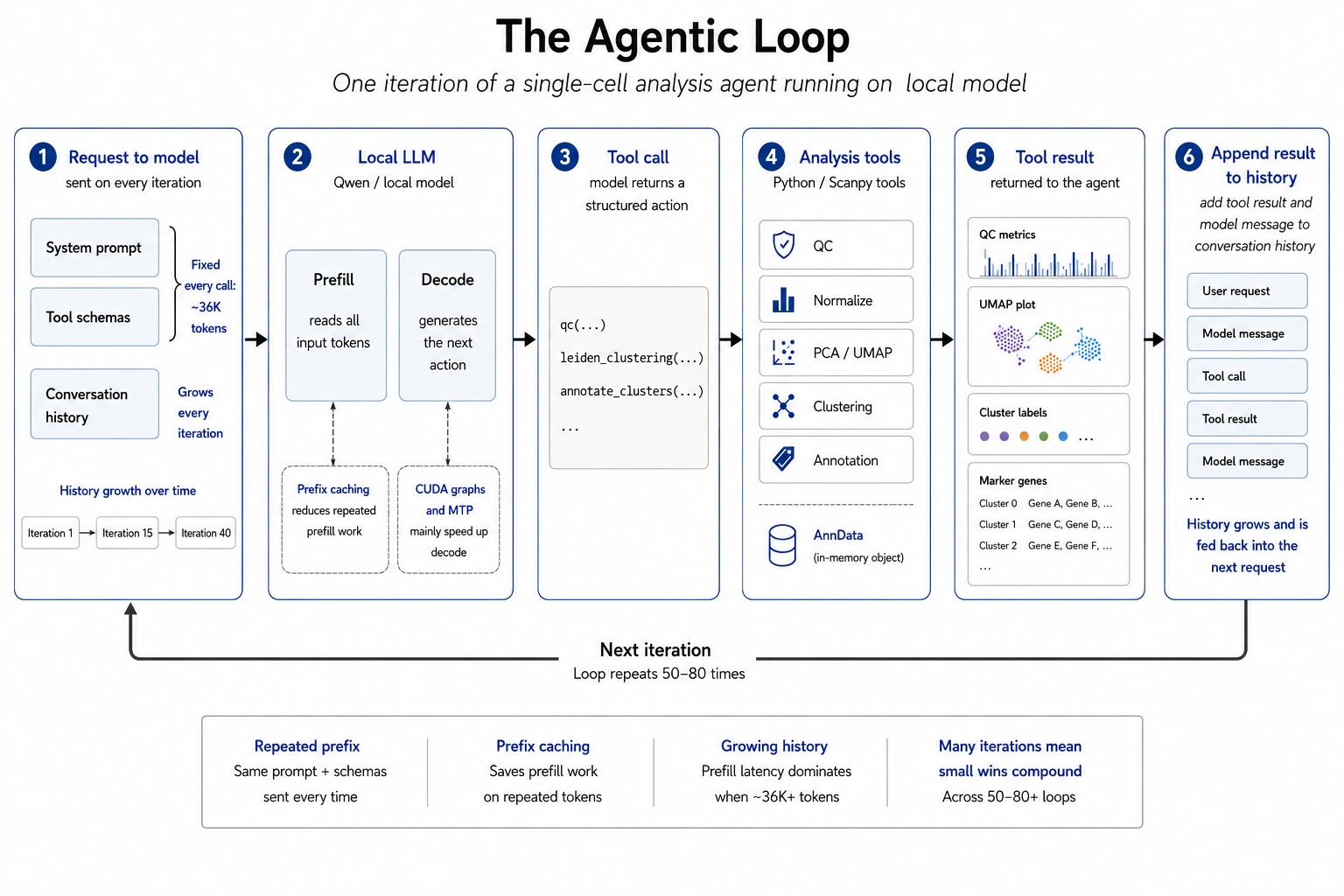
Прежде чем перейти к отдельным оптимизациям, полезно понять, что на самом деле происходит на каждой итерации цикла агента. На диаграмме ниже показана одна итерация: агент отправляет модели запрос, содержащий системную подсказку, схемы инструментов и полную историю разговора. Модель считывает все это и решает, какие инструменты вызвать. Инструмент запускается и возвращает результат, который добавляется к истории перед началом следующей итерации. Здесь стоит отметить два момента. Фиксированный префикс, который представляет собой системную подсказку плюс схемы инструментов, составляет примерно 36 000 токенов и отправляется при каждом вызове. И история разговора растет с каждой итерацией. К 40-й итерации модель больше не считывает короткую инструкцию. Она считывает длинный аналитический текст со множеством вызовов инструментов, выходных данных инструментов, промежуточных результатов и т. д. Оба этих фактора влияют на производительность агента.
1.1 Графы CUDA: сокращение сотен инструкций на токен до одной
Для понимания этого процесса полезно знать, что происходит внутри графического процессора, когда он генерирует отдельный токен.
Генерация отдельного токена на этапе декодирования включает в себя последовательное выполнение ядер графического процессора: внимание, прямое распространение, нормализация и так далее. Каждый из этих запускающих ядер имеет небольшие затраты на координацию со стороны центрального процессора. Центральный процессор должен поставить в очередь инструкцию, указывающую графическому процессору, какое именно ядро запустить, с какими формами тензоров и указателями памяти. Для модели с 27 миллиардами параметров, с которой мы работаем, это означает сотни отдельных запусков на каждый токен. Каждый из них невелик, но в сумме они дают значительный результат.
Графы CUDA устраняют эти накладные расходы. Перед обработкой реальных запросов vLLM может выполнить подготовительный проход, в ходе которого он записывает все команды ядра для шага декодирования в один воспроизводимый объект. После этого генерация каждого токена выполняется одной инструкцией для графического процессора вместо сотен. В результате задержка снижается примерно на 20–25% благодаря этому единственному изменению, без изменения самой модели.
Это замечательно, но графы CUDA также требуют статических форм тензоров, то есть граф компилируется для определенного размера пакета и длины последовательности. Это означает, что первый запуск занимает больше времени, чем последующие. Последующие запуски намного быстрее. Как показано на рисунке 8 ниже, для агента, выполняющего сотни итераций, кумулятивный эффект очень велик.
1.2. Размещение большего количества данных в памяти
Каждый вес в нейронной сети — это число, и формат хранения этого числа влияет как на объем занимаемой памяти, так и на скорость работы графического процессора. Стандартный формат для современных LLM (по крайней мере, для обучения) — BF16, который хранит каждый вес как 16-битное число с плавающей запятой. Для Qwen3.6–27B с 27 миллиардами параметров это примерно 56 ГБ данных о весах только для загрузки модели.
В FP8 каждый вес хранится в одном байте вместо двух. Теперь та же модель помещается примерно в 31 ГБ. Освобожденную память можно использовать для кэша ключ-значение (KV-кэш), в котором хранится контекст диалога. Больший объем KV-кэша означает, что модель может обрабатывать более длинные входные данные, прежде чем закончится место. Но память, которую мы освобождаем для KV-кэша, используется по-разному каждой моделью. Объем контекста, получаемого из этой памяти, зависит от архитектуры самой модели. Полезным показателем здесь является KV-память на токен , то есть, сколько памяти GPU требуется модели для хранения одного токена контекста.
Именно поэтому две модели с похожим количеством параметров могут вести себя по-разному на практике. Например, Gemma 4–31B использует примерно 1,1 МБ кэша ключ-значение на токен. Qwen 3.6–27B, в зависимости от того, как считать слои внимания, может использовать около 256 КБ на токен, если оценивать консервативно. Это означает, что на том же объеме оставшегося графического процессора можно получить гораздо больше токенов контекста на Qwen, чем на Gemma.
Например, предположим, что после загрузки модели на два графических процессора по 80 ГБ и с учетом некоторого запаса времени выполнения, у нас остается около 82 ГБ доступного места для кэша ключ-значение. С Gemma мы получаем 82 ГБ/1,1 МБ ≈ 74 тыс. токенов. С Qwen, если мы используем 256 КБ на токен, 82 ГБ/256 КБ ≈ 320 тыс. токенов. На практике максимальная длина контекста, заданная моделью, ограничивает это значение примерно 262 тыс. токенов (хотя, если использовать YaRN, ее можно увеличить до 1 млн токенов), но суть остается той же. Qwen может использовать ту же память графического процессора гораздо эффективнее для рабочих нагрузок с длительным контекстом.
Возвращаясь к работе с FP8 для весов нашей модели, следует отметить, что для умножения чисел FP8 с использованием аппаратных тензорных ядер требуются выделенные арифметические блоки FP8, которые NVIDIA представила в поколении Hopper. В H100 они есть, а в A100 — нет. Поэтому в A100 мы используем веса BF16, а в H100 — веса FP8. Преимущество в скорости вытекает непосредственно из этого. Во время декодирования графический процессор должен считывать веса модели из памяти для каждого генерируемого токена. При размере пакета 1, как это выглядит в сеансе одного пользователя, узким местом является именно чтение из памяти, а не сами вычисления. Меньшие веса означают меньше данных для чтения на токен, что означает более быструю генерацию.
Помимо самих весов модели, есть еще одно преимущество FP8, которое работает на обоих графических процессорах. Хранение векторов кэша ключ-значение в FP8 вместо BF16 вдвое снижает стоимость обработки одного токена (для Qwen3.6–27B — с 256 КБ до 128 КБ), напрямую удваивая количество токенов, помещающихся в память. Векторы хранятся в FP8 для повышения эффективности использования памяти, но при фактическом использовании в вычислениях внимания происходит их деквантизация обратно в BF16, поэтому для этого не требуются тензорные ядра FP8.
Есть еще один фактор, усиливающий преимущество в плане памяти. Запуск модели на нескольких графических процессорах с использованием тензорного параллелизма распределяет матрицы весов между обеими картами. Теперь каждый графический процессор хранит половину весов, что освобождает еще больше места для кэша ключ-значение на каждом графическом процессоре. На A100 это уменьшает объем памяти, занимаемый каждым графическим процессором для хранения весов, с 56 ГБ до 28 ГБ, оставляя 44 ГБ на каждый графический процессор для кэша ключ-значение вместо 16 ГБ. Это соответствует контекстному окну примерно в 180 000 токенов на оборудовании A100, чего достаточно для выполнения полной сессии анализа без переполнения (тензорный параллелизм отличается от FSDP, который является другим методом распределения рабочей нагрузки. Подробнее об этом можно прочитать в моей другой статье здесь).
1.3 Кэширование префиксов
Помните упомянутый ранее фиксированный префикс: схемы системных подсказок и инструментов, которые отправляются на каждой итерации цикла агента. Для этого агента это примерно 36 000 токенов. На каждой итерации, прежде чем модель сможет что-либо решить, ей сначала нужно прочитать и обработать все эти токены с нуля. Это означает, что при каждом вызове вычисляется полное внимание ко всем 36 000 токенам, даже несмотря на то, что в этом префиксе ничего не изменилось с момента последнего вызова.
Кэширование по префиксу решает эту проблему, сохраняя векторы ключей и значений для любой последовательности токенов, которую модель уже обработала. Если следующий запрос начинается с того же префикса, эти векторы извлекаются непосредственно из кэша, а не пересчитываются. Модель оплачивает полную стоимость предварительного заполнения только при первом запросе. Каждый последующий запрос в той же сессии сразу переходит к новым токенам в конце. Но если что-то меняется в этом префиксе в середине сессии, всю историю необходимо прочитать заново. Например, если вы редактируете системную подсказку или редактируете список инструментов, добавляя инструменты MCP, все это необходимо прочитать заново. То же самое происходит, если вы изменяете модель в середине сессии. Возможно, вы видели это в Claude Code, где говорится, что все сообщение необходимо прочитать заново, если вы пытаетесь изменить модель в середине сессии.
Для цикла работы агента это особенно ценно, поскольку фиксированная часть велика, а новая часть, добавляемая на каждой итерации, сравнительно мала. По мере развития сессии коэффициент попадания в кэш фактически улучшается. К 40-й итерации большая часть запросов уже кэширована, и только самые новые добавления требуют новых вычислений.
Для оценки реального влияния мы запустили реальные схемы командной строки и инструментов агента, а также все 36 000 токенов, через сервер vLLM с включенным и выключенным кэшированием префиксов, на оборудовании A100 и H100. Мы измерили время до получения первого токена при холодном старте, то есть при первом запросе, когда кэш пуст и весь префикс должен быть вычислен с нуля, и при последующих теплых запросах, когда кэш уже заполнен. На A100 время до получения первого токена (TTFT) при холодном старте составило 11 470 мс. С теплым кэшем оно снизилось до 706 мс. На H100 время при холодном старте составило 2655 мс, а при теплом старте — 249 мс. Это связано с тем, что префикс не пересчитывается. Обрабатываются только новые токены в конце запроса.
1.4 Спекулятивное декодирование
Декодирование по своей природе является последовательным процессом. Модель генерирует один токен, добавляет его к контексту, а затем генерирует следующий в авторегрессивном режиме. Каждый токен зависит от всех предыдущих, поэтому невозможно распараллелить обработку токенов так же, как это можно сделать с пакетом данных. Для сеанса работы с одним пользовательским агентом при размере пакета 1 это последовательное узкое место является основным ограничением пропускной способности.
Спекулятивное декодирование обходит эту проблему, вводя небольшую предварительную модель, которая работает впереди основной модели. Предварительная модель предлагает следующие k токенов быстро и недорого. Затем основная модель проверяет все k предложенных токенов за один параллельный проход. Поскольку основная модель считывает k токенов одновременно, а не генерирует их по одному, этап проверки обходится примерно так же, как и генерация одного токена обычным способом. Если большинство предложений принимаются, вы получаете k токенов почти по цене одного.
Ключевым фактором является процент принятия предложений. Если предложения, выдвигаемые предварительной моделью, постоянно оказываются неверными, основная модель отклоняет их и переключается на генерацию токенов по одному, но при этом вы всё равно платите за обработку предварительного варианта. Точная точка безубыточности зависит от предварительной модели, количества предлагаемых токенов, оборудования и реализации сервиса. В нашей конфигурации процент принятия ниже примерно 40% был невыгоден.
Здесь выбор черновой модели имеет огромное значение. Изначально мы попробовали DFlash, отдельную небольшую модель, используемую в качестве черновой. Процент принятия на нашем рабочем задании составлял от 4 до 7%, что значительно ниже точки безубыточности. На самом деле это замедлило работу. (Справедливости ради, на момент написания этой статьи создатели DFlash из Z lab заявили, что черновая модель из Qwen3.6–27B все еще находится в процессе обучения, поэтому, возможно, после его завершения она станет лучше). Но в нашем случае Qwen3.6–27B имеет встроенную функцию: многотокеновый блок прогнозирования (MTP), который является вспомогательным блоком прогнозирования, обучаемым параллельно с основной моделью и встроенным непосредственно в веса. Поскольку блок MTP обучается параллельно с основной моделью и использует собственные скрытые состояния модели, его предложения гораздо лучше соответствуют тому, что модель сгенерировала бы в любом случае.
Мы измерили процент принятия MTP в реальных сессиях с агентами как на A100, так и на H100. При медианном показателе принятия около 89% MTP оказался в выигрышном положении, значительно превышая точку безубыточности и оставаясь стабильным на разных этапах аналитического процесса.
Подводя итог всему
Каждая из этих оптимизаций тестировалась кумулятивно, при этом каждая конфигурация основывалась на всех предыдущих. Полная производительность стека измерялась на оборудовании A100 и H100 на модели Qwen, которую мы используем с нашей реальной системой запросов токенов на 36 000, что соответствует фактическим условиям сеанса агента.
Несколько моментов бросаются в глаза. Графы CUDA обеспечивают доминирующий прирост производительности декодирования, примерно в 3 раза на A100 и в 6 раз на H100. Базовый показатель H100 на самом деле начинается медленнее, чем A100, что противоречит интуиции (на самом деле, следует отметить, что протокол связи между вашими графическими процессорами имеет большое значение, помимо простого типа графического процессора. Золотым стандартом является использование NVLink через NVSwitch, затем NVLink Bridge, а затем PCIe). Это отражает, насколько сильно накладные расходы ЦП ограничивают ядра FP8 до компиляции графов. Однако после включения графов H100 вырывается вперед и удерживает эту позицию.
Кэширование ключ-значение FP8 и кэширование префиксов демонстрируют стабильную пропускную способность декодирования, что и ожидаемо. Они связаны с объемом памяти и задержкой предварительного заполнения соответственно, а не со скоростью генерации токенов. Эффект кэширования префиксов четко виден на стороне TTFT в диаграмме водопада: ровная линия на протяжении первых трех конфигураций, а затем резкое падение при включении кэширования.
MTP является вторым по величине фактором, влияющим на декодирование на обоих графических процессорах, добавляя около 37% на A100 и 20% на H100.
Часть 2: Поддержание работоспособности длительных сессий
При использовании облачных моделей управление контекстом проще игнорировать. Окна контекста часто достаточно велики для обычных сеансов чата, а инфраструктура обслуживания обрабатывается автоматически. При запуске локальной модели окно контекста становится аппаратным бюджетом. Больше контекста означает больше кэша ключ-значение. Больше кэша ключ-значение означает больше памяти графического процессора. В одной из наших ранних конфигураций A100 эффективное окно контекста составляло около 74 000 токенов.
Анализ отдельных клеток может выполнять от 50 до 80 и более итераций. Каждая итерация добавляет вызовы инструментов, результаты работы инструментов, промежуточные наблюдения, графики, ошибки, исправления и ограничения пользователя обратно в историю диалога. Когда история заполняется без какого-либо управления, API возвращает ошибку превышения длины контекста, и сессия завершается, удаляя все состояние анализа в памяти, включая объект AnnData, содержащий обработанный набор данных.
Таким образом, проблема заключалась не только в том, чтобы сделать модель быстрой. Агент также должен был продержаться достаточно долго, чтобы завершить работу.
Управление контекстом звучит просто. Отслеживайте, насколько заполнено окно, и обрезайте его, когда оно становится слишком переполненным. Однако на практике есть несколько мест, где наивные реализации могут дать сбой.
Компания Anthropic разработала руководство по контекстной инженерии для агентов и описывает три стратегии для задач с длительным горизонтом: сжатие, структурированное ведение заметок и многоагентные архитектуры. Сжатие — наиболее распространенное решение, и для универсального помощника оно хорошо работает. Когда контекст заполняется, история разговора передается обратно в модель для краткого изложения, и сессия продолжается с этой сжатой версией.
Для рядового ассистента это может сработать. Но для научного анализа это приводит к упущению важных моментов.
Проблема научного рабочего процесса заключается в том, что в кратком изложении в прозаическом виде теряется именно та информация, которая необходима. Фраза «Анализ кластеризовал данные и провел контроль качества» — это допустимое резюме, но оно игнорирует пороговые значения контроля качества, разрешение кластеризации, количество сохраненных ячеек и т. д. Именно эти параметры необходимы специалисту для воспроизведения этапа, описания методологии или правильного ответа на вопрос о том, что было сделано. Это не просто косметические детали. Это и есть сам анализ. Научному специалисту нужна точная запись, а не просто суть.
Помимо концептуальной проблемы с компактизацией, существуют и более фундаментальные способы, которыми управление контекстом может давать сбои. Первый — это учет фиксированных затрат. Каждый вызов API включает в себя системный запрос, схемы инструментов и зарезервированный бюджет завершения до появления хотя бы одного сообщения истории. Для этого агента только системный запрос и схемы инструментов составляют около 36 000 токенов. Если порог обрезки не вычитает эти фиксированные затраты в первую очередь, агент может в итоге обрезать данные по бюджету, который уже был превышен до включения какой-либо истории.
Третий способ — определение контекстного ограничения. Контекстное ограничение является знаменателем каждого расчета бюджета. Если запрос метаданных модели завершается неудачей, и код молча возвращается к жестко заданному значению по умолчанию, все последующие решения по корректировке будут неверными.
Более разумный подход — перестать рассматривать историю разговора как запись всего произошедшего. Для научного рабочего процесса у вас уже есть более надежная запись: структурированный журнал каждого шага, предпринятого агентом, с точными параметрами и результатами. Мы называем это состоянием мира.
Состояние системы — это объект Python, отслеживающий ход анализа. Каждый завершенный вызов инструмента записывает в него структурированную запись: какой шаг был выполнен, с какими параметрами и каковы были результаты. Эта запись сериализуется в системную подсказку на каждой итерации. Она занимает менее 1000 токенов, содержит точные параметры, а не их краткое описание, и хранится в системной подсказке, которая никогда не удаляется. Когда старые результаты работы инструмента удаляются из истории сообщений, запись об анализе остается неизменной.
Это меняет ваше представление об удалении лишней информации. Вместо того чтобы рассматривать историю сообщений как нечто ценное, что нужно сохранять, потому что она содержит запись о произошедшем, вы можете удалять её агрессивно, потому что запись находится в другом месте. История становится полезным контекстом. Мировое состояние становится эталоном.
Мировое состояние решает вопрос о том, что следует сохранить. Остальные исправления касаются вопроса о том, как определить, когда и насколько следует сократить ресурсы.
Первым решением стало прекращение обработки всего контекстного окна как доступной истории. Доступный бюджет рассчитывается путем вычитания фиксированных затрат авансом:
available = ( context_limit - tool_schema_tokens - system_tokens - COMPLETION_RESERVE - safety_margin )
При размере контекстного окна в 262 КБ и типичных накладных расходах остается около 219 000 токенов для истории сообщений. При более узком контексте в 32 КБ корректно отображается лишь несколько тысяч доступных токенов. Это полезно. Это сразу сообщает о том, что длительные сессии не будут работать при таком размере контекста, вместо того, чтобы незаметно завершиться с ошибкой через 3 итерации.
Второе решение заключалось в самокалибрующемся подсчете токенов. Вместо того чтобы пытаться точно соответствовать правилам токенизации Qwen, мы используем собственный ответ API для корректировки наших оценок. После каждого вызова ответ включает фактическое количество обработанных токенов. Мы сравниваем его с нашей оценкой и корректируем соответствующий коэффициент в сторону увеличения, если фактическое количество оказалось выше:
if actual_tokens > our_estimate: calibration = max(calibration, actual_tokens / our_estimate) calibration = min(calibration, 4.0)
Коэффициент только увеличивается. Переоценка приводит к немного более частой корректировке. Недооценка приводит к сбою следующего вызова. Последствия асимметричны, поэтому коррекция односторонняя.
Третье решение заключалось в стратегическом, а не равномерном сокращении. При приближении к бюджету агент собирает подходящие результаты работы инструментов, сортирует их по размеру и удаляет в первую очередь самые большие. Один большой блок выходных данных выполнения кода может содержать от 50 до 200 КБ логов, таблиц или данных графиков, закодированных в base64. Удаление одного большого блока может сохранить столько же контекста, сколько удаление десятков небольших сообщений. Сообщения пользователей никогда не обрезаются. Они содержат научный замысел и ограничения, определяющие, что должен делать анализ.
В совокупности эти изменения сделали агента действительно пригодным для использования. Теперь полный анализ, включающий более 50 итераций, выполняется до конца без появления у пользователя контекстной ошибки.
Заключение
Запуск локальной модели LLM для реальной агентной нагрузки выявляет проблемы, которые легко упустить при использовании облачного API. Важно не просто, чтобы модель была хорошей. Сервер вывода должен быть настроен целенаправленно, а контекстное окно должно управляться целенаправленно. Ни одна из этих проблем не является неразрешимой, но ни одна из них не решается автоматически.
Оптимизации, описанные в Части 1, суммируются способами, которые не очевидны на первый взгляд. Графы CUDA превращают едва работающий базовый вариант в пригодный для использования. Кэширование префиксов меняет интерактивность агента, позволяя избежать затрат на повторное чтение одного и того же 36K-токенового префикса при каждом вызове. Кэш FP8 KV увеличивает объем контекста, помещающегося в память. MTP дополнительно повышает пропускную способность декодирования. В совокупности эти изменения сокращают время выполнения агентом одной итерации с 10–15 секунд до примерно 1–3 секунд.
Изменения в управлении контекстом во второй части решают другую проблему: корректность. Долго работающему научному агенту необходимо помнить, что он делал, а не просто продолжать разговор. История разговора — полезный контекст, но это хрупкий источник истины. Она растет, сокращается и в конечном итоге должна быть сжата или удалена. Подход с использованием состояния мира, в частности, я бы рекомендовал любому, кто создает специализированного агента для научных или аналитических рабочих процессов. Надежная запись должна храниться вне стенограммы, в структурированном состоянии, которое фиксирует каждый шаг с точными параметрами и результатами.
Главный урок, который я извлек из создания этой системы, заключается в следующем: полезный агент — это не просто модель с инструментами. Это замкнутый цикл с окружающей его инфраструктурой. Модель решает, что делать дальше, но система вокруг неё определяет, достаточно ли быстрый, стабильный и надежный этот цикл для завершения работы.
Спасибо за прочтение, и надеюсь, это было вам полезно!
Список литературы / Дополнительные материалы
- Документация vLLM: https://docs.vllm.ai/
- Автоматическое кэширование префиксов vLLM: https://docs.vllm.ai/en/latest/features/automatic_prefix_caching.html
- Спекулятивное декодирование vLLM: https://docs.vllm.ai/en/stable/features/speculative_decoding/
- Графики vLLM CUDA: https://docs.vllm.ai/en/stable/design/cuda_graphs/
- Графики NVIDIA CUDA: https://developer.nvidia.com/blog/cuda-graphs/
- Статья о PagedAttention / vLLM: https://arxiv.org/abs/2309.06180
- Антропическая контекстная инженерия для агентов: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- DFlash: https://z-lab.ai/projects/dflash/
- Страница модели Qwen3.6–27B: https://huggingface.co/Qwen/Qwen3.6-27B
Хуссен Мохаммед Ибрагим. Все материалы от Хуссена Мохаммеда Ибрагима.
Источник: towardsdatascience.com
Оцените материал:

