Гибридный поиск и переранжирование в Production RAG
Когда семантического поиска недостаточно для RAG
Делиться

Несколько недель назад один из наших инженеров-платформенщиков из команды инфраструктуры пожаловался на то, что наш внутренний помощник по управлению знаниями уверенно выдает неверные ответы на вопрос о политике повторных попыток для потребителей наших очередей сообщений. На первый взгляд, это простой вопрос, и помощник должен был дать хорошо документированный ответ, но я ошибался.
Система выдала ответ из трех абзацев об экспоненциальном замедлении с учетом дрожания. Все это было точно, но ни один из пунктов не соответствовал ее запросу. В документе, который ей был нужен, описывалось пользовательское изменение настроек, которое мы внедрили для одной конкретной службы после инцидента в производственной среде, произошедшего шесть месяцев назад. В документе неоднократно использовалась фраза «порог очереди недоставленных сообщений». Наша модель встраивания определила, что «экспоненциальное замедление» и «порог очереди недоставленных сообщений» семантически достаточно близки.
Я проверил журналы поиска и обнаружил, что нужный ей документ находился на одиннадцатой позиции в результатах, чуть ниже первой десятки, переданной модели. Система не допустила ошибки при индексации или поиске, но документ занимал место ниже десяти других документов.
В этой статье
- Почему одного лишь плотного поиска недостаточно
- BM25: что это такое, почему это все еще важно и в чем заключаются его ошибки.
- Гибридный поиск: сочетание двух методов.
- Кросс-кодировщик
- Внедрение переранжирования
- Оценка воздействия
- Фильтрация метаданных
- Собираем всё воедино
- И последнее замечание о RAGAS
Проблема плотных векторов
Это третья часть серии статей о RAG для предприятий , и если вы пропустили предыдущие части, я настоятельно рекомендую сначала ознакомиться с ними: Практическое руководство по RAG для предприятий, База знаний и Ваши фрагменты кода не сработали, Ваш RAG в производственной среде.
Плотный поиск работает путем преобразования текста в многомерные векторы и поиска фрагментов, векторы которых геометрически близки к вектору запроса. Если два фрагмента текста означают контекстно схожие вещи, их векторы должны оказаться близко друг к другу в пространстве вложений.
Это хорошо работает для концептуальных запросов, таких как «Каков наш процесс эскалации инцидентов?». Этот запрос позволит получить документы, связанные с инцидентом, даже если в документе используются слова типа «оценка степени серьезности» вместо «эскалация». Модель встраивания научилась понимать взаимосвязь этих понятий, и косинусное сходство это отражает.
Проблема возникает, когда в дело вступает специфическая техническая терминология. Инженер, ищущий «конфигурацию порога очереди недоставленных писем», задает не концептуальный вопрос. Она хочет получить точный термин из точного документа, но векторное представление «порога очереди недоставленных писем» усреднено по всему остальному в окружающих абзацах и объединено в один плотный вектор. Это усреднение — компромисс. То же свойство, которое делает плотный поиск хорошим для концептуального сопоставления, делает его ненадежным для поиска точного термина.
Бикодеры , модели, лежащие в основе плотного поиска, сжимают смысл целого фрагмента в один вектор фиксированного размера. Это сжатие приводит к потере информации. Вопрос не в том, следует ли терять какую-либо информацию, а в том, какую информацию мы можем себе позволить потерять.
BM25: что это такое и как это помогает?
До появления нейронных систем поиска, поиск в основном осуществлялся с помощью методов, основанных на частоте встречаемости терминов . BM25, или Best Match 25, — один из лучших существующих методов, широко используемый в Elasticsearch, Solr, Weaviate и большинстве производственных поисковых систем.
BM25 оценивает документ по отношению к запросу, рассматривая его с разных сторон. Его основные компоненты:
Компонент IDF задает себе вопрос о том, насколько сложно найти тот или иной термин в корпусе. Термин, встречающийся в большинстве документов, практически ничего не говорит о релевантности. «Пороговое значение очереди недоставленных писем», встречающееся лишь в нескольких документах, является сильным сигналом. IDF придает большее значение редким терминам.
Компонент частоты встречаемости термина запрашивает, как часто термин встречается в данном конкретном документе. Здесь BM25 проявляет смекалку и применяет функцию насыщения вместо использования только исходной частоты. Благодаря этой функции насыщения оценка быстро растет в начале, а затем выравнивается.
Компонент нормализации длины наказывает за длинные документы. Более длинный документ, естественно, содержит больше вхождений терминов. Без нормализации он будет отображать самые длинные документы, что нам не нужно.
BM25 не может сопоставлять синонимы, обрабатывать перефразирования или понимать взаимосвязь между «переопределением конфигурации» и «пользовательскими настройками». Это модель «мешка слов», и порядок слов и семантика для неё не имеют значения. Фразы «конфигурация переопределяет поведение повторной попытки по умолчанию» и «поведение повторной попытки по умолчанию может быть переопределено через конфигурацию» идентичны для BM25, и в этом заключается как его сила, так и его ограничение.
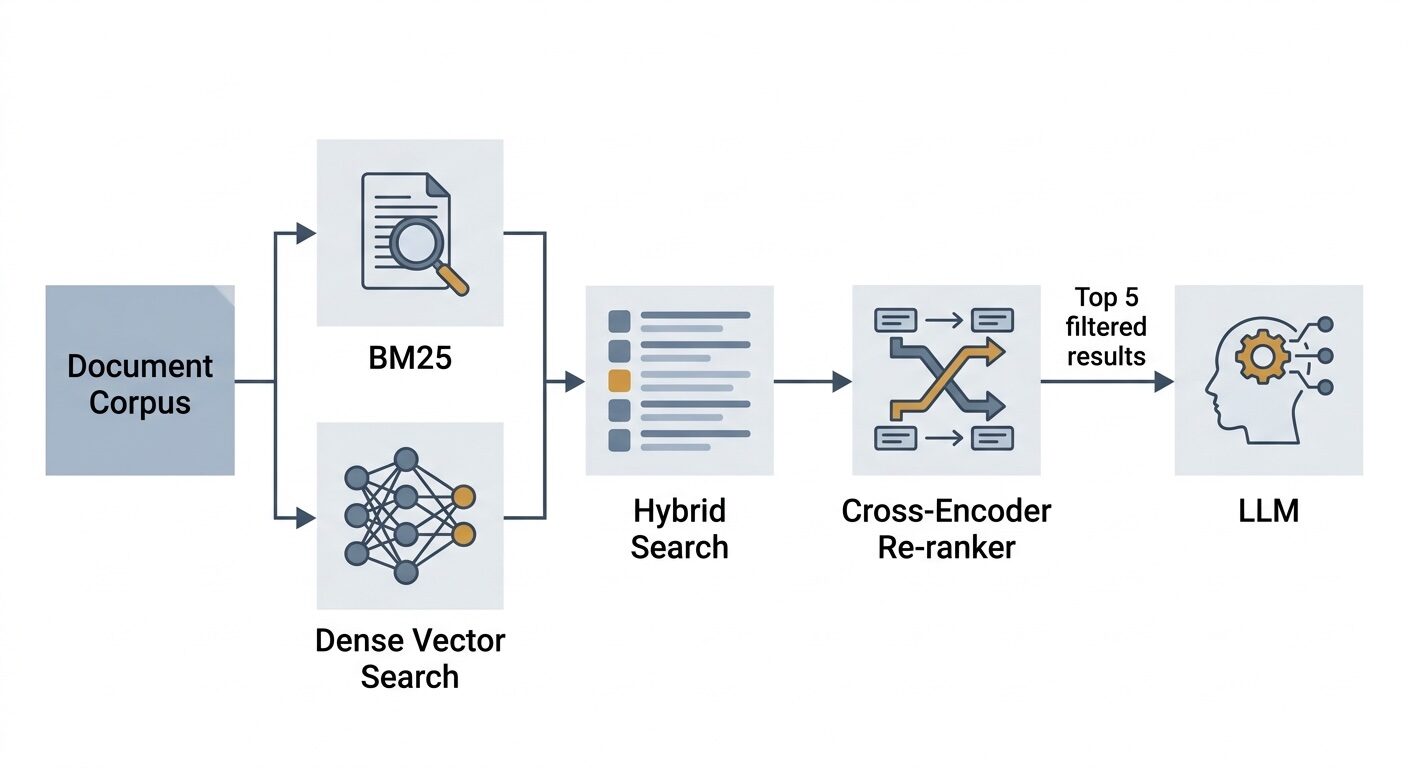
Гибридный поиск: сочетание обоих методов.
Weaviate изначально поддерживает гибридный поиск, объединяя оценки ключевых слов BM25 и оценки сходства плотных векторов в единый ранжированный список с помощью метода, называемого Relative Score Fusion . Ключевым параметром является альфа, которая управляет сочетанием. Альфа, равная 1, соответствует чисто векторному поиску, а альфа, равная 0, — чистому поиску BM25. Все значения между ними представляют собой взвешенную комбинацию.
from llama_index.core.retrievers import VectorIndexRetriever from llama_index.core.vector_stores import MetadataFilter, MetadataFilters # Alpha of 0.5 = equal weight to keyword and semantic signals retriever = VectorIndexRetriever( index=index, similarity_top_k=10, vector_store_query_mode="hybrid", alpha=0.5, vector_store_kwargs={ "filters": MetadataFilters(filters=[ MetadataFilter(key="department", value="engineering") ]) } )
Это простая часть, но определить, какое значение альфа-канала использовать, — гораздо сложнее.
Вопрос в том, насколько точен ваш типичный запрос. Если большинство ваших запросов носят концептуальный характер («как работает наш процесс обработки инцидентов?»), то более высокий уровень альфа-значения склоняет вас к семантическому сопоставлению. Если запросы часто представляют собой поиск точных терминов («контрольный список статьи 17 GDPR», «пороговое значение DLQ политики повторных попыток», «SLA сервиса X»), то более низкий уровень альфа-значения придает больший вес сопоставлению по ключевым словам.
На практике лучше измерить результат, а не просто гадать. Вот как я настроил альфа-критерий на нашем корпусе, используя размеченный оценочный набор из 150 пар запрос-документ, взятых из истории нашей службы поддержки ИТ.
import ragas from ragas.metrics import ContextPrecision, ContextRecall from datasets import Dataset import numpy as np def evaluate_alpha(alpha_value, eval_queries, ground_truth_docs): results = [] for query, expected_doc_ids in zip(eval_queries, ground_truth_docs): # Update retriever with new alpha retriever.alpha = alpha_value retrieved_nodes = retriever.retrieve(query) retrieved_ids = [n.node.metadata.get("doc_id") for n in retrieved_nodes] hit = any(doc_id in retrieved_ids for doc_id in expected_doc_ids) rank = next( (i + 1 for i, doc_id in enumerate(retrieved_ids) if doc_id in expected_doc_ids), None ) results.append({"hit": hit, "rank": rank}) hit_rate = np.mean([r["hit"] for r in results]) mrr = np.mean([1 / r["rank"] if r["rank"] else 0 for r in results]) return {"alpha": alpha_value, "hit_rate": hit_rate, "mrr": mrr} # Test across the range alphas = [0.0, 0.25, 0.5, 0.75, 1.0] results = [evaluate_alpha(a, eval_queries, ground_truth_docs) for a in alphas] for r in results: print(f"Alpha: {r['alpha']:.2f} | Hit Rate: {r['hit_rate']:.3f} | MRR: {r['mrr']:.3f}")
В нашем инженерном корпусе результаты выглядели следующим образом (ваши показатели могут отличаться):
Alpha: 0.00 | Hit Rate: 0.71 | MRR: 0.58 # Pure BM25 Alpha: 0.25 | Hit Rate: 0.80 | MRR: 0.66 Alpha: 0.50 | Hit Rate: 0.83 | MRR: 0.69 -> our sweet spot Alpha: 0.75 | Hit Rate: 0.81 | MRR: 0.67 Alpha: 1.00 | Hit Rate: 0.73 | MRR: 0.61 # Pure dense
Чистые режимы явно были хуже любых смешанных. Запрос к очереди недоставленных сообщений, который ранее завершился неудачей, переместился с одиннадцатого ранга на четвертый при значении альфа 0,5, потому что сигнал BM25 поднял его, несмотря на то, что плотный сигнал все еще оставался неоднозначным.
Важное замечание по поводу этих цифр : если ваш корпус в основном состоит из длинных повествовательных документов, вам может подойти значение альфа-критерия 0,65–0,75. Если же он содержит много точных технических идентификаторов, кодов ошибок, названий продуктов, то, скорее всего, лучше подойдет значение 0,35–0,5. Универсального правильного значения не существует. Измеряйте на собственных данных.
Примечание: Если ваш показатель попаданий при
alpha=0.0(чистый BM25) значительно ниже, чем приalpha=1.0(чистый плотный корпус), значит, ваш корпус содержит богатый словарным запасом контент с перефразированием; в этом случае следует отдать предпочтение более высокому значению альфа. Если верно обратное, и пользователи ищут информацию с помощью точных технических терминов, то следует отдать предпочтение более низкому значению альфа. Если же показатели схожи, начните с 0,5 и корректируйте значение по мере необходимости.
Проблема, которую гибридный поиск не решает
Когда вы передаете десять извлеченных фрагментов в LLM, он считывает их все. Но его внимание не распределяется равномерно по контекстному окну. Многочисленные исследования, такие как проблема «потерянного посередине», показали, что модели уделяют больше внимания контексту в начале и конце входных данных и менее надежны в отношении информации, скрытой посередине. Если наиболее релевантный фрагмент находится на восьмой позиции из десяти, вы полагаетесь на модель, которая должна извлечь его из относительно невнимательной зоны.
Кросс-кодировщики: что это такое и почему они работают.
Двузначный кодировщик обрабатывает запрос и документ совершенно независимо друг от друга. К моменту вычисления сходства два итоговых вектора ничего не знают друг о друге.
Кросс-кодировщик делает нечто иное. Он берет запрос и один документ, объединяет их в одну входную последовательность и пропускает через трансформер. Теперь каждый слой внимания в модели может позволить токенам запроса взаимодействовать с токенами документа и наоборот. Модель видит полное взаимодействие между ними, прежде чем выдать оценку релевантности.
Разница в том, что может обнаружить модель, существенна. Рассмотрим запрос «Каков лимит повторных попыток для платежного сервиса?» и два возможных фрагмента: «Лимиты повторных попыток различаются в зависимости от типа сервиса. Для большинства внутренних сервисов по умолчанию установлено три попытки с экспоненциальной задержкой» и «Потребитель платежного сервиса настроен на максимальное количество повторных попыток — пять, прежде чем сообщение будет перенаправлено в очередь недоставленных сообщений».
Двусторонний кодировщик может присвоить фрагменту A более высокий рейтинг, поскольку фразы «лимит повторных попыток» и «лимиты повторных попыток различаются в зависимости от типа услуги» семантически близки. Кросс-кодировщик, читающий оба текста вместе, сразу замечает, что фрагмент B содержит фактическое число для конкретной услуги, о которой спрашивается в запросе. Перекрестное внимание между «платежной службой» в запросе и «потребителем платежной службы» в документе дает ему прямое доказательство того, что фрагмент B является правильным ответом.
Именно поэтому кросс-кодировщики значительно точнее би-кодировщиков в задачах ранжирования. Ограничение заключается в том, что они не могут ничего предварительно вычислять. Би-кодировщик может предварительно внедрить все ваши документы во время индексации, а затем просто внедрить запрос во время поиска, выполняя таким образом две операции. Кросс-кодировщик должен обрабатывать каждую пару (query, document) во время запроса. Для миллиона документов это миллион прямых проходов. Вы не можете запустить кросс-кодировщик на всем вашем корпусе.
Решение заключается в двухэтапной воронке: сначала используется бикодировщик для охвата широкого круга кандидатов и быстрого извлечения N лучших, а затем кросс-кодировщик для точной переоценки только этих N кандидатов.
На практике кросс-кодировщик добавляет примерно 80–120 мс к задержке запроса при переранжировании 20 документов с помощью облегченной модели на ЦП.
Внедрение переранжирования
Мы используем ms-marco-MiniLM-L-6-v2 из библиотеки sentence-transformers. Она была обучена на MS MARCO, крупномасштабном наборе данных для ответов на вопросы, и является наиболее широко используемым кросс-кодировщиком с открытым исходным кодом для общих задач поиска. Для контента, специфичного для конкретной области, вы можете выполнить тонкую настройку на собственных размеченных парах, но общая модель является разумной отправной точкой.
from sentence_transformers import CrossEncoder reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2") def rerank_nodes(query: str, retrieved_nodes: list, top_n: int = 5) -> list: """ Takes query and a list of LlamaIndex NodeWithScore objects, returns top_n nodes reranked by cross-encoder score. """ # Build (query, chunk_text) pairs for the cross-encoder pairs = [(query, node.node.get_content()) for node in retrieved_nodes] # Score all pairs and returns a list of floats scores = reranker.predict(pairs) # Attach scores to nodes and sort for node, score in zip(retrieved_nodes, scores): node.score = float(score) reranked = sorted(retrieved_nodes, key=lambda n: n.score, reverse=True) return reranked[:top_n] # Full retrieval + re-ranking pipeline query = "What is the retry limit for the payment service dead-letter queue?" # Stage 1: retrieve more than you need (20 candidates) retrieved = retriever.retrieve(query) # top_k=20 in retriever config # Stage 2: re-rank down to 5 reranked = rerank_nodes(query, retrieved, top_n=5) # Inspect what happened to document ranks print("After re-ranking:") for i, node in enumerate(reranked): source = node.node.metadata.get("source", "unknown") print(f" Rank {i+1} | Score: {node.score:.4f} | Source: {source}")
LlamaIndex также имеет встроенный постпроцессор SentenceTransformerRerank , который легко интегрируется в конвейер обработки запросов:
from llama_index.postprocessor.sbert_rerank import SentenceTransformerRerank from llama_index.core import QueryBundle from llama_index.core.query_engine import RetrieverQueryEngine reranker_postprocessor = SentenceTransformerRerank( model="cross-encoder/ms-marco-MiniLM-L-6-v2", top_n=5 ) query_engine = RetrieverQueryEngine.from_args( retriever=retriever, node_postprocessors=[reranker_postprocessor] ) response = query_engine.query( "What is the retry limit for the payment service dead-letter queue?" )
Параметр top_n=5 здесь указывает алгоритму переранжирования, сколько документов следует передать на этап генерации. Увеличение этого параметра дает алгоритму LLM больше контекста, но увеличивает как задержку, так и риск появления шума. В нашей системе значение 5 оказалось оптимальным — достаточно контекста для многосоставных вопросов, не перегружая подсказку.
Примечание: Зарегистрируйте корреляцию рангов между порядком поиска и порядком переранжирования для выборки запросов. Если кросс-кодировщик редко меняет ранжирование, либо ваш бинарный кодировщик уже хорошо справляется со своей задачей, и переранжирование малоэффективно, либо ваша модель кросс-кодировщика слишком универсальна для вашей предметной области.
Оценка воздействия
Мы сравниваем три варианта одновременно: чистый плотный поиск (наш базовый уровень), гибридный поиск и гибридный поиск с переранжированием. Я провел оценку с использованием набора из 150 запросов во всех трех конфигурациях.
from ragas import evaluate from ragas.metrics import ( ContextPrecision, ContextRecall, AnswerRelevancy, Faithfulness ) from datasets import Dataset def build_ragas_dataset(queries, retrieved_contexts, ground_truths, generated_answers): return Dataset.from_dict({ "question": queries, "contexts": retrieved_contexts, # list of lists of strings "answer": generated_answers, "ground_truth": ground_truths }) # Build datasets for each configuration, then evaluate baseline_dataset = build_ragas_dataset( queries, baseline_contexts, ground_truths, baseline_answers ) hybrid_dataset = build_ragas_dataset( queries, hybrid_contexts, ground_truths, hybrid_answers ) hybrid_rerank_dataset = build_ragas_dataset( queries, hybrid_rerank_contexts, ground_truths, hybrid_rerank_answers ) metrics = [ContextPrecision(), ContextRecall(), AnswerRelevancy(), Faithfulness()] baseline_result = evaluate(baseline_dataset, metrics=metrics) hybrid_result = evaluate(hybrid_dataset, metrics=metrics) hybrid_rerank_result = evaluate(hybrid_rerank_dataset, metrics=metrics)
Результаты анализа нашего инженерного корпуса (это реальные данные из нашей внутренней оценки):
Configuration | Context Precision | Context Recall | Answer Relevancy | Faithfulness ----------------------------|-------------------|----------------|------------------|------------- Dense only (alpha=1.0) | 0.61 | 0.74 | 0.78 | 0.82 Hybrid (alpha=0.5) | 0.71 | 0.83 | 0.81 | 0.85 Hybrid + Re-ranking (top 5) | 0.79 | 0.84 | 0.87 | 0.89
Несколько моментов, на которые стоит обратить внимание:
Показатель полноты контекста существенно улучшился при переходе от плотного набора данных к гибридному (с 0,74 до 0,83), а затем практически не изменился после переранжирования (0,84). Это произошло потому, что полнота измеряет, был ли найден правильный документ или нет. Переранжирование не улучшает полноту, поскольку оно работает в рамках уже найденного набора данных. Улучшение полноты в гибридном наборе данных было обусловлено тем, что компонент BM25 извлекал точные совпадения терминов, которые плотная модель оценила слишком низко.
Точность контекста значительно возросла после переранжирования (с 0,71 до 0,79). Точность измеряет, какая доля полученных фрагментов действительно релевантна. Переранжирование делает именно то, что должно, вытесняя нерелевантный материал из топ-5, который передается на этап генерации.
На каждом этапе улучшались показатели релевантности и достоверности ответов . Это сквозные метрики, отражающие совокупный эффект от улучшения поиска и, как следствие, от улучшения генерации результатов.
Фильтрация метаданных
Фильтрация метаданных позволяет сузить область поиска до выполнения векторного поиска. Если пользователь из инженерного отдела задает вопросы о процессах развертывания, вы можете ограничить поиск инженерными документами еще до начала сравнения векторов. В результате вы получаете не только более быстрый поиск, но и меньший, но более релевантный пул кандидатов, что повышает точность как BM25, так и плотной оценки.
from llama_index.core.vector_stores import ( MetadataFilter, MetadataFilters, FilterOperator, FilterCondition ) # Apply filters based on user context def build_retriever_with_filters( index, user_department: str, max_doc_age_days: int = 365, classification_level: str = "internal" ): from datetime import datetime, timedelta cutoff_date = (datetime.now() - timedelta(days=max_doc_age_days)).isoformat() filters = MetadataFilters( filters=[ MetadataFilter( key="department", value=user_department, operator=FilterOperator.EQ ), MetadataFilter( key="updated_at", value=cutoff_date, operator=FilterOperator.GT ), MetadataFilter( key="classification", value="confidential", operator=FilterOperator.NE # Exclude confidential unless authorised ), ], condition=FilterCondition.AND ) return VectorIndexRetriever( index=index, similarity_top_k=20, vector_store_query_mode="hybrid", alpha=0.5, vector_store_kwargs={"filters": filters} )
Инструкция по эксплуатации сервиса, выведенного из эксплуатации восемнадцать месяцев назад, не только бесполезна, но и опасна, если система отображает её как уверенный ответ на вопрос о текущей инфраструктуре. Фильтрация по updated_at может помочь в этом случае, предотвращая появление старой информации.
Один из возможных сбоев, о котором следует помнить: если ваш фильтр слишком узкий и исключает документ, который фактически содержит ответ, вы получите неверный ответ, уверенно полученный из оставшихся документов. Правильный подход заключается в том, чтобы начать с разумных значений по умолчанию (фильтр по отделам, возможно, фильтр по дате) и добавлять более строгие фильтры только для документированных случаев использования, где вы убедились, что они помогают в реальных запросах.
Полный трубопровод
Вот как все три компонента взаимодействуют в процессе извлечения данных (для демонстрации):
from llama_index.core.query_engine import RetrieverQueryEngine from llama_index.postprocessor.sbert_rerank import SentenceTransformerRerank from llama_index.core.response_synthesizers import get_response_synthesizer from llama_index.llms.ollama import Ollama # LLM (local, via Ollama) llm = Ollama(model="llama3", request_timeout=120.0) # Stage 1: Hybrid retriever with metadata filters retriever = build_retriever_with_filters( index=index, user_department="engineering", max_doc_age_days=365 ) # Stage 2: Cross-encoder re-ranker reranker = SentenceTransformerRerank( model="cross-encoder/ms-marco-MiniLM-L-6-v2", top_n=5 ) # Stage 3: Response synthesizer synthesizer = get_response_synthesizer( llm=llm, response_mode="compact", # Merges multiple chunks into one prompt use_async=True ) # Assemble the query engine query_engine = RetrieverQueryEngine( retriever=retriever, node_postprocessors=[reranker], response_synthesizer=synthesizer ) # Query it response = query_engine.query( "What is the retry limit for the payment service dead-letter queue?" ) print(response.response) # Source attribution: important for enterprise use cases for node in response.source_nodes: print(f" Source: {node.node.metadata.get('source')} | Score: {node.score:.4f}")
Следует отметить параметр response_mode="compact" : в этом режиме несколько полученных фрагментов объединяются в один вызов запроса, а не выполняется отдельный вызов LLM для каждого фрагмента. Для пяти фрагментов это существенно снижает задержку и позволяет поддерживать приемлемый уровень использования контекстного окна. Если вы используете модель с меньшим ограничением контекста или ваши фрагменты длинные, альтернативным вариантом является response_mode="tree_summarise" , который обрабатывает данные поэтапно.
После внесения всех этих изменений и внедрения в рабочую среду наш внутренний специалист по управлению знаниями смог ответить на вопрос о политике повторных попыток для потребителей нашей очереди сообщений, предоставив корректные данные.
И последнее замечание о RAGAS
Показатель RAGAS не является метрикой качества продукта. Это диагностический инструмент. Точность контекста 0,79 означает, что в среднем 79% передаваемых в модель данных являются релевантными. Это не означает, что 79% пользователей получают правильные ответы.
RAGAS действительно полезен для измерения влияния изменений. Увеличилась ли точность контекста (Context Recall) после внедрения гибридного поиска? Улучшилась ли точность контекста (Context Precision) без снижения точности контекста (Recall) после добавления переранжирования? На эти вопросы он может дать надежные ответы. Используйте его как инструмент сравнения «до» и «после» каждый раз, когда вы что-то меняете в процессе поиска, и отслеживайте показатели с течением времени по мере развития вашего корпуса.
К чему это приведет в сериале?
В первой статье мы разработали конвейер индексирования: загрузка документов из Confluence и локальных каталогов с помощью LlamaIndex, их разбиение на фрагменты, встраивание с помощью BGE-large и сохранение в Weaviate. Во второй статье мы подробно рассмотрели стратегии разбиения на фрагменты и узнали, что форма фрагментов определяет, что система поиска может, а что не может найти.
В этой статье мы напрямую рассмотрели проблему качества поиска. Гибридный поиск обеспечил нам значительное улучшение полноты поиска по запросам с точными терминами. Переранжирование с использованием разных кодировщиков повысило точность данных, передаваемых в LLM. Фильтрация метаданных исключала устаревшие и нерелевантные документы из пула кандидатов еще до начала дорогостоящих этапов оценки. Показатели RAGAS продемонстрировали кумулятивное улучшение на каждом этапе.
Следите за продолжением этой серии статей, где мы рассмотрим еще один вопрос, который ставит перед инженерами сложные задачи при создании производственных систем RAG.
Приянш Бхардвадж Посмотреть все о Приянш Бхардвадж
Источник: towardsdatascience.com
Оцените материал:
