Это уроки, которые мы усвоили на этом пути. Или нет?
Исследовательские проекты в эпоху искусственного интеллекта
Делиться

Вкратце: я попытался дать ChatGPT типичную задачу для месячной стажировки в области данных. В каком-то смысле задача была «решена», но я не уверен, что это означает то, что я ожидал. Для специалистов по данным и ИИ это теперь очень практический вопрос. Многие команды используют стажеров или исследовательские проекты для изучения идей: достаточно ли хорош ИИ сейчас? Эти проекты касаются только конечного результата?
Стажеры как исследователи
Разработка технологической дорожной карты для стартапа на ранней стадии развития, занимающегося обработкой данных, не сильно отличается от составления типичной карты для видеоигры:
План развития гораздо шире, чем просто то, что вы можете сделать, но и то, что вы можете увидеть. Если бы мы только могли заглянуть за «горизонт (продукта)», отправив исследователя расчистить карту, тогда мы бы получили представление о том, что нас ждет, когда мы туда доберемся (исследователь может погибнуть, так что аналогия хороша до определенного момента).
Компания Bauplan (которую я соосновал в 2024 году) приняла необычное (для своего размера) решение организовать летние стажировки для студентов ведущих вузов (Колумбийский университет, Университет Карнеги-Меллона, Университет Висконсина в Мэдисоне), чтобы заглянуть в будущее. Пока что это работает очень хорошо. Помимо улучшения процесса найма, повышения репутации в сообществе и некоторого влияния в социальных сетях, результаты исследований нашли отражение в нашем продукте и станут стратегическими активами по мере роста компании.
Пока я рассылаю предложения о стажировке на лето 2026 года, половина моей ленты X сообщает мне, что я всё делаю неправильно. Это далеко не гипотетическая проблема, и на разных этапах, при разных размерах и ограничениях, все команды, занимающиеся данными и ИИ, сегодня сталкиваются с одним и тем же вопросом: существует ли лучший способ проводить исследовательские работы с агентами? Если да, то какая хорошая, проверенная система ИИ легко адаптируется?
В надежде, что наш опыт и точка зрения окажутся полезными для многих специалистов по работе с данными, мы представляем вам нашу схему работы и уроки, извлеченные из реального исследовательского проекта, проведенного в сотрудничестве с ChatGPT.
Сначала они пришли за консультантами, а я не стал возражать…
В эпоху, когда ИИ угрожает работникам интеллектуального труда, первыми, похоже, падают позиции младших специалистов. Зачем McKinsey нанимать аналитика из университета Лиги плюща, если подписка за 200 долларов позволяет получать больше отчетов быстрее? В последнее время в моей ленте новостей, кажется, указывается, что ИИ может угрожать и исследователям: ученые пытаются автоматизировать свою работу — «полностью автономные исследования от идеи до публикации» — а профессора спорят, стоит ли вообще нанимать ассистентов.
Существуют очевидные аргументы против этой тенденции. Мы можем критиковать результат и утверждать, что технология всё ещё содержит ошибки, поэтому обещанного «равенства университетов Лиги плюща» просто нет. Мы можем утверждать, что нарушается общественный договор : конечно, молодые исследователи всегда были (в некотором смысле) «бременем», но это бремя было одновременно способом отплатить добром за добро и инвестицией в следующее поколение. Мы также можем подчеркнуть потенциальный долгосрочный ущерб от замены хорошо изученного мыслительного процесса новым, непроверенным рабочим процессом.
Хотя все эти аргументы имеют под собой веские основания, аналогичные доводы можно поверхностно применить к изобретению автомобилей или чему-либо подобному. Для подобных дискуссий всегда есть свое время и место, но сегодня меня интересует гораздо более локальный и личный вопрос: каково было бы мне бросить своих стажеров ради подписки за 200 долларов?
Итак (подобно тому физическому эксперименту, который я недавно обнаружил) я попытался уместить месяц стажировки в выходные дни, работая с ChatGPT.
Мифический агентский месяц
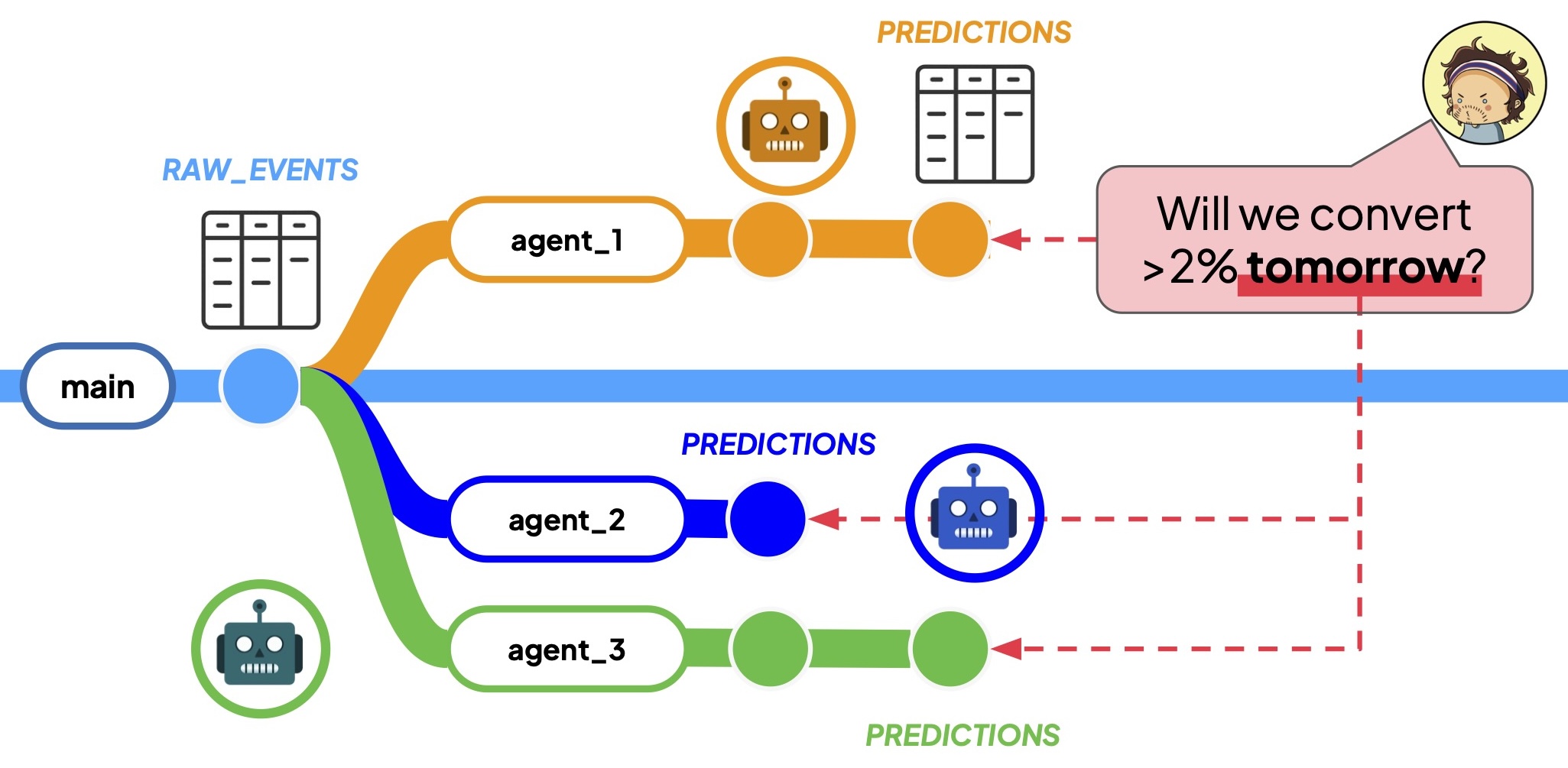
Хотя точная проблема не так уж важна, ознакомление с условиями стажировки может быть полезным, чтобы понять, чем занимаются стажеры в Bauplan (можете пропустить!). Bauplan — это платформа для работы с разветвленными данными: агенты и люди могут открывать ветки, подобные Git, в своих таблицах. В результате одна и та же таблица может иметь разные версии в разных ветках. В нашем примере компания Acme Inc. — это онлайн-ритейлер, в котором группа агентов, работающих с данными, должна выполнить различные прогнозы продаж на завтра:
В идеале, работу должен проверить человек, сравнить и сопоставить полученные результаты, а затем объединить таблицу прогнозов в качестве канонического представления данных. Но что, если кто-то задаст вопрос до того, как это произойдет?
Существующие системы просто откажутся отвечать, даже если это интуитивно кажется расточительным: два агента, вычисляющие ежемесячную выручку, могут расходиться во мнениях относительно точной цифры, но оба согласны с тем, что выручка выросла более чем на 10% по сравнению с предыдущим кварталом. Другими словами, даже если нет общепринятой версии данных, мы все равно могли бы ответить на множество интересных вопросов.
Наша цель стажировки — создать прототип такой системы. Для этого потребуется изучить ветвление, освоить новые математические методы, разработать решение на основе Bauplan, а также создать модуль преобразования текста в SQL (довольно простая задача) и пользовательский путь выполнения запросов (довольно сложная задача).
Настройка ИИ
Недавно участникам форума Bauplaners посчастливилось увидеть живую демонстрацию работы своей установки в исполнении самого Уэса Маккинни, поэтому я решил перенять её (с некоторыми незначительными изменениями):
- ChatGPT 5.2 для планирования и принятия решений по стратегиям (например, как разработать эталонный показатель, подчеркивающий разницу между инженерными подходами);
- Используйте код Claude Code внутри Visual Studio для выполнения фактического цикла разработки;
- Roborev будет локально проверять коммиты в противовес друг другу. Благодаря Codex, проверки выявляют потенциальные проблемы и предлагают улучшения;
- Roborev проводит обзоры для упорядочивания сложности проекта примерно каждые 10 коммитов: эти обзоры учитывают архитектурную точку зрения и помогают сократить избыточность.
Настоящее сокровище – это друзья, которых мы встретили на своем пути.
Поскольку мне совершенно не нравится идея, что за меня будет писать ИИ (честно говоря, мне также не нравится идея, что это будут делать стажеры), я сам дописал окончательный вариант. Так как стажировки обычно заканчиваются публикацией результатов в сообществе, у меня накопилось достаточно материала для статьи в ACM SAO под названием «Запрос всего и везде одновременно».
По некоторым показателям, сторонники теории X оказались правы: даже при допущении несоответствия качества, я «нянчился» с ИИ 48 часов, чтобы выполнить, скажем, 80% работы, на которую ушли бы недели. Интересно, что «няньство» имеет другую природу: ИИ настолько стремится угодить, что часто «жульничает», чтобы добиться поверхностных результатов с помощью жестко запрограммированных упрощений. Хотя многие проблемы с данными и ИИ на первый взгляд легко проверить, по нашему опыту, их также легко обмануть: это особенно верно, когда интерпретация экспериментальной установки сложна или конечный показатель не является очевидным: следует трижды проверить, действительно ли ваши агенты ИИ «восходят на вершину» или просто притворяются.
С другой стороны, ИИ не нужно обучать моделям Тарского или «избытку истины», поскольку достаточно приложить несколько статей, чтобы сразу же приступить к работе. Результаты также оказались «ощутимыми»: у меня есть хорошо выглядящее веб-приложение, и мне не пришлось снова брать в руки D3.js (спустя 10 лет после последнего раза!), а также демонстрационный скрипт, имитирующий агентные конвейеры и бизнес-вопросы с ветвлениями. Если вы считаете (как и я), что прототипы обычно лучше, чем презентации PowerPoint (или статьи), то нет сомнений, что стек ИИ принес свои плоды.
Сложнее всего выразить словами то, что не было реализовано, или, точнее, то, что я потерял в процессе. Несмотря на весь ажиотаж вокруг невероятного графика и неожиданного бенчмарка, ничто из этого на самом деле не привело к большему пониманию. Я не стал мудрее от того, что прошёл через этот исследовательский процесс: у меня появилось немного больше интуиции, чем раньше (например, как лучше подсказывать для качественного перевода SQL-запросов), но мои ментальные модели в основном сохранили ту же детализацию, что и в начале. Работа со стажёрами может быть трудоёмкой и порой даже утомительной, но она всегда порождает лучшие идеи — и у них, и у меня: объясняя и наставляя их, они в каком-то смысле объясняют и наставляют меня в ответ.
Если я теперь получаю результаты, почти ничему не научившись, меня это беспокоит главным образом потому, что неясно, имеет ли это значение. Я не имею в виду, имеет ли это значение в глобальном масштабе, в масштабах большого мозга: конечно, если наши дети перестанут учиться, а наши ученые перенесут свои мысли на беседы, это плохо. Сейчас я просто умеренно сосредоточен на этом: имеет ли это значение для меня, для моей компании, для моих инвесторов?
Локальный, личный ответ — если, конечно, у вас нет завышенного самомнения — менее однозначен. Я умею программировать и, вероятно, мог бы еще преподавать математическую логику, поэтому в каком-то смысле этот проект не является чем-то принципиально новым: возможно, здесь не так уж многому можно научиться (помимо осуществимости всего этого, что я, конечно, и предполагал с самого начала), а чувство беспокойства, которое я испытываю, — это наследие прежнего образа мышления. Или, возможно, нет такой задачи, которая была бы слишком скромной, чтобы стать немного лучшей версией себя: выполнение кропотливой работы по подключению наших API к диаграмме, 13 неудачных попыток компиляции DataFusion, бесконечные раздумья о том, как выбрать запросы для убедительного бенчмарка, где ни одна другая система не может выразить — не говоря уже о вычислении — наш путь запроса. Я чувствую себя неловко, потому что реальные проекты для реальных людей, не слишком завышенного в своем эго, имеют очень широкий спектр проблем, которые не являются очевидными с точки зрения фундаментальных принципов или очевидными деталями реализации.
Сегодня у меня нет проблем (завтра посмотрим…) с упрощенным представлением о том, что думать должны люди, а специалисты по лингвистике должны исправлять синтаксис matplotlib. Но меня мучает большая серая зона между ними, и внутренний голос шепчет, что, рассматривая все как детали реализации, я скоро перестану мыслить четко. Не становимся ли мы похожими на тех венчурных капиталистов, которые «сопоставляют шаблоны» и теряют все нюансы? Смысл доказательства в доказательстве теоремы (каким бы странным ни казалось доказательство) или в предоставлении нам нового понимания?
Будущее может немного подождать.
Анализ моих решений (а не моих чувств) на лето 2026 года действительно показывает последствия этого эксперимента. Компания Bauplan наняла двух стажеров (людей), двух молодых, талантливых и мотивированных специалистов по информатике, которым поручено исследовать границы нашей продуктовой карты в отношении сквозной оптимизации ИИ (развитие навыков с помощью GEPA) и масштабирования git-for-data. С практической точки зрения, я принял то же решение, что и до начала этого проекта. Однако я не думаю, что вышел из него невредимым и невредимым: мои чувства в какой-то момент кристаллизуются в новые концепции и затем повлияют на мои решения.
С одной стороны, как большой поклонник «Маленького принца», я понимаю, что именно время, потраченное на эту розу, сделало её важной: время, проведённое с моими стажёрами этим летом, (я верю) сделает их и наш совместный проект более значимыми. С другой стороны, это лишь отчасти отражает моё нынешнее настроение. Мне пришлось покопаться в интернет-архиве, чтобы восстановить кое-что, что я недавно вспомнил из 2006 года (видимо, математическая логика — не единственное, что я помню из своих 20 лет). Это запись №1 в списке Blender «50 худших вещей, которые могут случиться с музыкой»:
#01 . ДЕТИ СЕГОДНЯ
В наши дни у нас не было ваших модных iPod, рингтонов и загрузок. У нас не было роскоши и удобства ваших колец для мошонки и ваших веб-блогов. Когда мы хотели украсть новый альбом URIAH HEEP, мы не могли просто побродить по интернету в поисках, нам приходилось делать это по старинке — идти в магазин (в гору в обе стороны) и запихивать 30-сантиметровые виниловые пластинки под свитера (которые нам приходилось вязать самим). Вот почему вы, нытики-выскочки, не цените настоящую музыку. Или Uriah Heep. А теперь убирайтесь к черту с нашей лужайки!
Будем ли мы по-прежнему ценить «истинную ценность вещей», если теперь можем «воровать их», не выходя из дома, с помощью ноутбуков?
До встречи, агентские ковбои!
Благодарим Луку, Колина и Итана за их комментарии к предыдущей версии этой статьи.
Если вы хотите стать стажером в Bauplan и заниматься интересными проектами в области данных и искусственного интеллекта (например, вот этим, этим или этим), я по-прежнему принимаю кандидатов-людей: свяжитесь со мной!
Якопо Тальябуэ Посмотреть все магазины Якопо Тальябуэ
Источник: towardsdatascience.com
Оцените материал:

