EmoNet: Трансформеры, учитывающие особенности речи говорящего, для распознавания эмоций — и что бы я изменил в 2026 году.
Ретроспектива моей магистерской диссертации, ее места в рейтинге и изменений в области магистратуры, которые с тех пор преобразили эту сферу.
Делиться

В марте 2024 года я защитил магистерскую диссертацию по распознаванию эмоций в разговоре (ERC). Модель EmoNet достигла взвешенного F1-критерия 39,18 на EmoryNLP — сопоставимого с результатами публичного рейтинга PapersWithCode на тот момент, находясь между TUCORE-GCN_RoBERTa (39,24) и S+PAGE (39,14), и превзойдя выбранную мной базовую модель CoMPM на +1,81 F1 .
Два года спустя я вернулся, чтобы посмотреть, как сейчас обстоят дела в этой области. Рейтинг совершенно неузнаваем. В числе лидеров уже не модели, использующие только кодировщики с интеллектуальными механизмами внимания, а системы на основе LLaMA-2–7B с тонкой настройкой LoRA и подсказками, дополненными механизмом поиска : InstructERC, CKERC, BiosERC, LaERC-S. Методы другие. Вычислительные ресурсы другие. Образ мышления другой.
И всё же — когда я внимательно читаю эти новые статьи, основные идеи, которые я предложил в EmoNet, обнаруживаются и в них, просто реализованные на другом уровне стека. Это история того, что я создал, какое место это заняло и что бы я создал сейчас, если бы начинал всё сначала.
Что такое ERC и почему сложно создавать текстовые версии?
Распознавание эмоций в разговоре — это задача присвоения эмоциональной метки каждому высказыванию в многоходовом диалоге. Она отличается от анализа настроений отдельных предложений одним важным моментом: эмоция высказывания формируется тем, что было сказано до него, и тем, кто говорит.
Рассмотрим следующий диалог из набора данных EmoryNLP (полученного из телешоу «Друзья»):
Моника: Венди, мы договорились! Да, ты обещала! Венди! Венди! Венди! [Злится]
Рэйчел: Кто это был? [Нейтральный]
Моника: Венди ушла. У меня нет официантки. [Злится]
Само по себе выражение «Кто это был?» эмоционально нейтрально. Однако ярлык «Нейтральный» имеет смысл только в контексте — он находится между двумя гневными высказываниями разных говорящих, и модели ERC должны учитывать эту динамику разговора.
Есть и вторая проблема: отсутствует мультимодальная информация. В реальном человеческом разговоре тон голоса, выражение лица и язык тела несут в себе огромную долю эмоциональных сигналов. ERC, основанный только на тексте, всё это лишает. Одни и те же слова — «О, отлично» — могут быть искренними или саркастическими, и сам текст часто не может определить, какие именно.
Главная проблема заключается в потере информации. Необходимо извлечь эмоции из сигнала, уровень шума в котором значительно выше, чем у сигнала, воспринимаемого человеком.
Ландшафт 2024 года
Когда я начал работу над своей диссертацией в конце 2023 года, в рейтинге EmoryNLP доминировали архитектуры на основе трансформеров с различными оригинальными модификациями. Краткий обзор:
– KET (Zhong et al., 2019) — обогащенный знаниями трансформер с аффективным вниманием к графу, первая работа, в которой трансформеры были внедрены в ERC.
– DialogueGCN (Ghosal et al., 2019) — графовая сверточная сеть, которая преобразует диалоги в задачи классификации узлов.
– RGAT (Ishiwatari et al., 2020) — механизм внимания к графам с учетом отношений и кодированием позиции отношений для зависимостей между говорящими.
– DialogXL (Шен и др., 2020) — адаптированная версия XLNet с учетом повторяемости высказываний и самовнимания в диалоге.
– HiTrans (Li et al., 2020) — иерархический трансформер с попарной проверкой говорящего в качестве вспомогательной задачи.
– TUCORE-GCN (Lee & Choi, 2021) — гетерогенный диалоговый граф с BERT, учитывающим говорящего.
– CoMPM (Lee & Lee, 2021) — сочетание контекста диалога с предварительно обученным отслеживанием памяти говорящего.
Я выбрал CoMPM в качестве основы по двум причинам. Во-первых, в нем предварительно обученная память говорящего была представлена как отдельный модуль, что соответствовало моей интуиции: важно не только то, что говорит говорящий, но и кто он. Во-вторых, его архитектура была достаточно модульной, чтобы его можно было расширять без переписывания с нуля. В статье о CoMPM было показано, что добавление предварительно обученной памяти к контекстной модели давало ощутимый прирост производительности, но при этом идентичность говорящего оставалась локальной для каждого диалога . В момент начала нового разговора все, что модель узнала о говорящем, отбрасывалось.
Эта проблема показалась мне стоящей решения.
Три вклада, основанные на интуиции.
1. Глобальная идентичность говорящего
Проблема. В CoMPM и большинстве предыдущих работ идентификаторы говорящих ограничены одним диалогом. Говорящий А в сцене 1 никак не связан с говорящим А в сцене 14, даже если это один и тот же человек. Следовательно, каждый диалог начинается без контекста.
Интуиция. У людей есть характерные эмоциональные модели поведения. Моника злится из-за определенных вещей; Фиби неизменно жизнерадостна; у Росса бывают предсказуемые приступы неуверенности. Если модель может передавать информацию об этом конкретном говорящем из одного диалога в другой, она должна быть способна делать более точные прогнозы, когда этот говорящий появится снова.
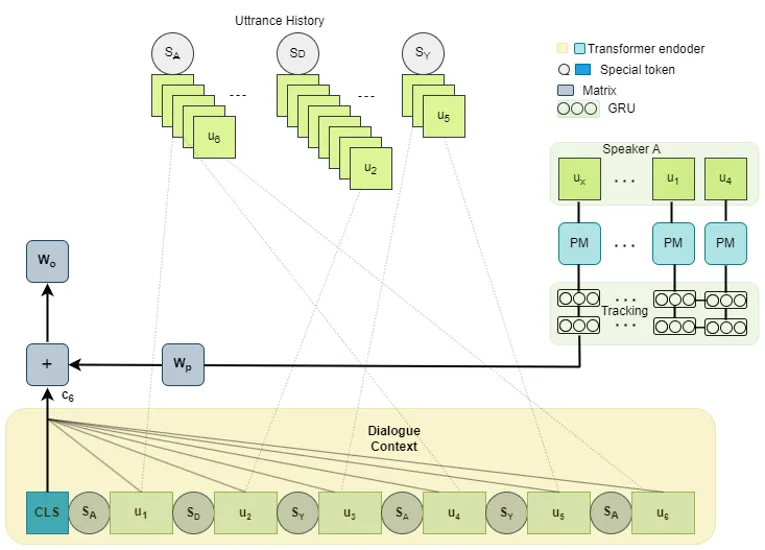
Реализация. Каждому уникальному говорящему во всем наборе данных присваивается стабильный идентификатор, действующий во всем наборе данных. При первом появлении Моники Геллер ей присваивается идентификатор — например, ID 7 — который сохраняется. При каждом последующем появлении — в эпизодах, сезонах, сценах — ей также присваивается ID 7. Теперь модель может изучать специфические для говорящего закономерности, которые сохраняются.
Сейчас это кажется очевидным. В 2024 году модели формирования рейтинговых таблиц работали иначе.
2. Модуль анализа поведения говорящего
Проблема. Глобальная идентичность говорящего — это всего лишь метка. Чтобы она была полезна, модели необходимо что-то сделать с накопленной историей говорящего. Как предоставить трансформеру доступ ко «всему, что Моника когда-либо говорила в этом наборе данных», не расширяя контекстное окно и не делая обучение невозможным?
Интуиция. Рекуррентность. GRU идеально подходит для последовательного сжатия исторических высказываний говорящего в единое представление фиксированного размера. Более новые высказывания вносят больший вклад; более старые постепенно уменьшаются. Настраиваемое скользящее окно ограничивает входные данные GRU — например, последние N высказываний этого говорящего — обеспечивая предсказуемость вычислительных ресурсов и памяти.
Реализация. Каждое высказывание кодируется независимо с помощью предварительно обученной архитектуры RoBERTa. Полученные эмбеддинги проходят через однонаправленный GRU. Конечное скрытое состояние GRU — назовем его `kt` — представляет собой поведенческий паттерн говорящего в текущий момент. Оно проецируется в ту же размерность, что и выходной контекст диалога, и добавляется. Объединенный сигнал подается на вход финального классификатора.
Архитектура структурно схожа с предварительно обученным модулем памяти CoMPM, но с двумя ключевыми отличиями: пул истории говорящих является глобальным (а не локальным для текущего диалога), и GRU явно моделирует временное затухание.
3. Взвешенная кросс-энтропийная функция потерь
Проблема. EmoryNLP несбалансирован — нейтральных фраз примерно в 4,5 раза больше, чем грустных. В большинстве работ это решается с помощью расширения данных или уменьшения выборки. Но разговорные данные являются последовательными : удаление или дублирование фраз искажает естественный эмоциональный поток, а именно на этом сигнале модель и пытается учиться.
Интуиция подсказывает: если нельзя безопасно изменить данные, измените функцию потерь. Присвойте более высокий вес редким классам, чтобы одна ошибка классификации «Грустный» обходилась модели дороже, чем одна ошибка классификации «Нейтральный».
Реализация. Кросс-энтропия с весами для каждого класса, полученными из обратной частоты классов, а затем нормализованными. Ничего экзотического — но, учитывая аргумент о последовательности разговора в качестве явной мотивации, это становится принципиальным, а не произвольным выбором.
Результаты: что сработало, и что меня удивило.
Вот таблица абляции из диссертации:
Результат, который меня удивил — и который, на мой взгляд, является самой честной частью этой работы, — это вторая строка. Добавление одного лишь глобального идентификатора говорящего существенно ухудшило модель (показатель F1 упал с 37,85 до 29,43). Сначала это выглядело как провал.
Но это было не так. Глобальная идентичность говорящего — это возможность, которая позволяет модели изучать паттерны речи говорящего на большом расстоянии. Сама по себе эта возможность создает дополнительную нагрузку на представление информации, с которой остальная часть модели не могла справиться. Ее вклад проявился только после добавления модуля «Поведение говорящего» , который предоставил модели структурированный способ использования глобальных идентификаторов. В окончательной конфигурации EmoNet восстановила свои позиции и превзошла базовый показатель CoMPM на 1,81 F1.
Вот какой урок я извлек из анализа изменений: функция не ценна сама по себе; она ценна в сочетании с механизмами, которые её используют. В научных статьях, где сообщается: «Это добавление дало нам +X%», часто скрываются строки с анализом изменений, где само по себе добавление ухудшило ситуацию. Я решил оставить эту строку.
Полная модель хорошо справлялась с нейтральным, радостным и испуганным состояниями. Наиболее сложным оставался сильный класс — отчасти потому, что он встречается редко, а отчасти потому, что сильные и радостные состояния практически неотличимы в текстовом общении без акустических сигналов. Это мультимодальная проблема, маскирующаяся под текстовую проблему.
Размышления (2026): область исследований изменилась, и нам тоже следует измениться.
Спустя два года рейтинг EmoryNLP выглядит совершенно иначе. Лидирующие системы теперь следующие:
– InstructERC (Lei et al., 2023) – переформулирует ERC как генеративную задачу LLM. Она использует шаблоны инструкций, дополненные средствами поиска информации, и вспомогательные задачи, такие как идентификация говорящего и прогнозирование эмоций, для лучшего моделирования ролей в диалоге и эмоциональной динамики.
– CKERC (Фу, 2024) — представляет собой систему ERC, дополненную здравым смыслом. Для каждого высказывания LLM генерирует аннотации, основанные на здравом смысле, о намерениях говорящего и вероятной реакции слушателя, обеспечивая неявное социальное и эмоциональное обоснование, выходящее за рамки явного контекста диалога.
– BiosERC (Xue et al., 2024) — внедряет полученную с помощью LLM биографическую информацию о говорящем в процесс ERC, позволяя модели рассуждать не только на основе контекста высказывания, но и на основе специфических характеристик говорящего.
– LaERC-S (Фу и др., 2025) — двухэтапная настройка инструкций. Этап 1: оснастить LLM характеристиками, специфичными для говорящего . Этап 2: использовать эти характеристики во время выполнения самого задания ERC.
Внимательно посмотрите на последние два.
Биографическая информация о говорящем в BiosERC по сути представляет собой расширенную версию Global Speaker Identity — вместо целочисленного идентификатора это текстовый профиль, на который может реагировать LLM. Характеристики говорящего в LaERC-S по сути представляют собой модуль Speaker Behaviour — исторические шаблоны поведения говорящего, доступные модели, — но интегрированные в настройку инструкций, а не реализованные как отдельный GRU.
Архитектурные идеи подтвердились. Изменился уровень реализации.
Вот что мне действительно интересно. Когда я работал над EmoNet в 2024 году, я размышлял в рамках парадигмы «только кодировщик-трансформатор»: «как добавить еще один модуль в архитектуру?» В статьях 2024–2025 годов рассматривается парадигма LLM: «как закодировать эту идею в контекст настройки инструкций или контекст поиска?» Идеи похожи, но точки приложения усилий разные.
Если бы я сегодня перестраивал EmoNet , я бы не начинал с RoBERTa-large. Я бы начал с небольшой модели LLM с открытым исходным кодом — LLaMA-3.2–3B, Qwen-2.5–3B или Phi-3.5 — и использовал бы LoRA для её тонкой настройки на EmoryNLP, следуя подходам семейства InstructERC. Глобальная идентификация говорящего становится текстовой биографией говорящего, полученной из векторного хранилища. Модуль поведения говорящего становится подсказкой для нескольких примеров с самой последней эмоциональной историей говорящего. Взвешенная функция потерь остаётся практически неизменной — дисбаланс классов не зависит от используемой модели.
Архитектурная схема выглядела бы совершенно иначе. Концептуальный долг перед диссертацией 2024 года был бы очевиден, если бы вы знали, куда смотреть.
Это научило меня тому, что исследовательский долг имеет более длительный период полураспада, чем я ожидал — идеи переживают сдвиги парадигмы, даже если их реализация терпит неудачу.
Вот к чему это меня приводит.
Проект EmoNet теперь находится в открытом доступе под DOI 10.5281/zenodo.20048006, а полная версия диссертации, слайды защиты и реализация на PyTorch доступны на GitHub. В настоящее время я работаю над модернизированной версией — LLM с тонкой настройкой LoRA и контекстом говорящего на основе поиска — в рамках последующего проекта, о котором я скоро напишу.
Если вы работаете над разговорным ИИ, прикладной обработкой естественного языка или тонкой настройкой LLM, мне было бы интересно узнать, что вы разрабатываете.
Biju Puthan Veetil Посмотреть все в Biju Puthan Veetil
Источник: towardsdatascience.com
Оцените материал:
