DiffuJudge-AV: фреймворк, основанный на принципах диффузии, для оценки калиброванных AV-видеоматериалов.
Разработанная на основе принципов диффузии структура для стресс-тестирования и шумоподавления конвейеров обработки видео с использованием LLM в качестве эксперта, применяемая к видеоматериалам, критически важным для безопасности вождения.
Делиться

Я относился к LLM Judge как к шумному датчику. Это повлияло на то, какой именно оценщик систем автономного вождения я буду отправлять.
Существует особый тип результатов, которые выглядят впечатляюще, пока вы не зададите неправильный второй вопрос.
В этом проекте результатом стала корреляция Пирсона 0,753 , полученная с помощью текстового оценочного инструмента Клода, оценивающего визуальные ответы на вопросы по автономному вождению. На первый взгляд, это выглядит как пригодный для использования инструмент оценки. Он отслеживает эталонные значения, выдает обоснования, представляет собой надежную замкнутую модель. Достаточно хорош для сортировки результатов модели, верно?
Затем я посмотрел на взвешенный по квадрату коэффициент Коэна κ . Он составил 0,057 .
Именно в этот момент проект изменился. Рейтинг судьи коррелировал с золотыми метками, но он вел себя не как система оценки безопасности по порядковой шкале. Он усвоил наиболее безопасный на вид режим отказа: сжимать почти все значения к середине шкалы от 1 до 5. Для обычной отчетности по результатам тестирования это могло бы остаться незамеченным. Но для системы проверки автономного вождения, которая должна выявлять неверные ответы до утверждения выпуска программного обеспечения, это опасно.
Поэтому я создал DiffuJudge-AV — небольшую систему оценки оценок для судей LLM/VLM, оценивающих видеозаписи вождения. Идея проста: рассматривать оценку судьи как зашумленное наблюдение скрытой истинной оценки по рубрике, намеренно подвергать судью воздействию известных источников предвзятости при выставлении оценок, затем очищать полученное распределение оценок от шума с помощью одношагового апостериорного среднего Твиди и сообщать калиброванную неопределенность.
В ходе 28 400 оценок экспертов на бенчмарке LingoQA от Wayve наиболее интересным результатом стало не то, что победила более крупная закрытая модель. Этого не произошло. Лучшим экспертом в эксперименте оказалась Qwen2.5-VL-7B , открытая 7B модель обработки изображений и языка. Она достигла следующих результатов:
- Коэффициент корреляции Пирсона r = 0,857
- Коэффициент корреляции Спирмена ρ = 0,856
- Взвешенный по квадрату коэффициент Коэна κ = 0,837
- MAE = 0,57
- Коэффициент обнаружения сбоев F1 = 0,712
Примечание: Бенчмарк LingoQA распространяется под некоммерческой лицензией. Создатели набора данных из Wayve предоставили разрешение на его использование в данной статье.
Для этой задачи оценки в стиле AV открытая VLM оказалась не просто конкурентоспособной. Она превосходила конкурентов по показателям, которые действительно имеют значение.
Почему «оценка оценки»?
Когда модель отвечает на вопрос о ситуации за рулём автомобиля, очевидный вопрос для оценки звучит так:
Модель дала правильный ответ?
Например:
Вопрос: Есть ли припаркованные автомобили на обочине дороги? Ссылка: Да, справа припаркованы две машины. Ответ кандидата (тестируемая модель): Я не знаю. Оценка: 1,13 (низкая).
Для человека это просто. Посмотреть видеоролик, сравнить ответ со сценой, присвоить оценку. Однако в больших масштабах узким местом становится оценка человеком. Современные системы автономного управления генерируют больше видеороликов с восприятием, журналов сценариев, контрфактических сценариев и результатов работы моделей, чем любая команда аннотаторов может оценить вручную. Поэтому команды, естественно, обращаются к LLM в качестве судьи или VLM в качестве судьи : дают модели вопрос, ссылку, вариант ответа, рубрику и иногда кадры, а затем просят ее оценить.
Это создает проблему второго порядка:
Если судья является образцом для подражания, как мы можем быть уверены в его надежности?
Это оценка оценки (оценка оценки). Вместо того чтобы просто спрашивать, правильна ли модель AV, мы спрашиваем, является ли сам оценщик стабильным, откалиброванным, устойчивым к предвзятости и полезным для принятия последующих решений. В недавних статьях (Judging the Judges by Shi et al., IJCNLP-AACL 2025; JETTS by Salesforce, 2025; CALM by Ye et al., ICLR 2025) были описаны структурные сбои в работе судей LLM: предвзятость позиции, предвзятость многословия, предвзятость формата идентификатора оценки, самопротиворечивость между запусками и сильное сжатие оценок.
Существует также более неприятное утверждение из недавнего эссе Ван Луна «Ваши системы оценки сломаются, и вы этого не заметите»: инфраструктура оценки выходит из строя незаметно, когда модели превышают пороговые значения своих возможностей.
Поскольку существующие эталонные показатели предполагают постепенное улучшение, предложенное им решение — адаптивные оценки, которые сами определяют свою устарелость. DiffuJudge-AV — один из конкретных шагов в этом направлении. Присваивая каждой оценке, выдаваемой судьей, калиброванную неопределенность, система расширяет собственный доверительный интервал, прежде чем точечная оценка введет вас в заблуждение.
Для автономного вождения это имеет оперативное значение. Если опытный оценщик решает, какие сбои следует передать на рассмотрение человеку, какие сценарии — в набор регрессионных тестов или какие релизы заслуживают более тщательного изучения, то выявленные оценщиком режимы отказов становятся частью концепции безопасности.
Интуитивное объяснение: оценка эксперта — это зашумлённое показание датчика.
Оценка судьи LLM выглядит безупречно, потому что это число: 1, 2, 3, 4 или 5.
Но это число может меняться по причинам, не имеющим ничего общего с фактическим качеством ответа. Измените порядок вариантов. Перефразируйте критерии оценки. Переставьте критерии. Замените арабские цифры в обозначениях оценок на римские. Перевыберите примеры. Измените температуру. Перетасуйте кадры видео, которые вы выбираете. Истинное качество ответа не изменилось. Изменился судья.
Это наводит на мысль о полезной ментальной модели:
Относитесь к судье как к источнику шума.
Существует скрытый балл s = 0. Судья никогда не наблюдает его напрямую. Каждый вариант подсказки дает шумное показание.
s~t=s0+ϵt,t∈{1,…,7}tilde{s}_t = s_0 + epsilon_t, quad t in {1, ldots, 7}
Здесь t не является шагом диффузии в смысле генерации изображений. Это документированный источник оценки.
Возмущение, взятое непосредственно из литературы по проблеме предвзятости в оценке качества преподавания в магистратуре в 2024–2025 годах. Семь канонических источников, каждый из которых представляет собой контролируемый уровень шума:
| Уровень t | Возмущение | Что именно тестируется | Ссылка |
| 1 | опцион / обмен ордеров | позиционная предвзятость | Ши и др., 2025 |
| 2 | перефразирование рубрики | быстрая чувствительность | SPUQ, arXiv 2403.02509 |
| 3 | критерий переупорядочения | чувствительность порядка рубрики | Чен и др., 2025 |
| 4 | Перестановка формата оценочного балла и идентификатора (1–5 / I–V / A–E) | предвзятость формата оценки | Чен и др., 2025 |
| 5 | температурный шум | самопротиворечивость | Такур и др., 2025 |
| 6 | повторная выборка образца | дисперсия при малом количестве выстрелов | классический |
| 7 | перетасовка кадров (видео) | временная устойчивость | эта работа |
Для каждого элемента система проверяет работу судьи на всех семи уровнях возмущения, используя k = 3 выборки на каждом уровне, что дает примерно 22 наблюдения оценок на элемент вместо одного. Это практическое измерение нестабильности работы судьи. Это также позволяет нам выполнить обратный шаг.
Этап шумоподавления: Твиди в одном уравнении
Аналогия с диффузией становится полезной, поскольку в основе шумоподавления лежит классический результат: формула Твиди (Роббинс, 1956; переосмыслена для современной диффузии Манором и Михаэли, ICLR 2024).
Если зашумленное наблюдение s~ генерируется путем добавления гауссовского шума к скрытому чистому значению s 0, то апостериорное среднее равно:
s^0=s~+σt2∇s~logp(s~)hat{s}_0 = tilde{s} + sigma_t^2 , nabla_{tilde{s}} log p(tilde{s})
Var[s0|s~]=σt2+σt4∇s~2logp(s~)text{Var}[,s_0 mid tilde{s},] = sigma_t^2 + sigma_t^4 , nabla_{tilde{s}}^2 log p(tilde{s})
Данная модель оценивает p(s~) с помощью гауссовой оценки KDE по выборочным значениям каждого элемента. Дисперсия внутри уровня возмущения дает σt2sigma_t^2. Объединение по уровням осуществляется с учетом точности перед применением алгоритма Твиди.
Исправление. В результате этого единственного обратного шага получаются два результата:
- Очищенная от шума точечная оценка s^0hat{s}_0
- Апостериорная неопределенность для каждого элемента σ^ihat{sigma}_i
Второй результат — это то, что для меня важнее. В процессе проверки безопасности мне нужна не просто цифра. Мне важно знать, достаточно ли судья уверен в этом результате, чтобы принять какие-либо меры.
Затем очищенная от шума оценка помещается в интервал расщепленной конформности с порядковой границей (Sheng et al., EMNLP 2025), стандартизированный апостериорным распределением Твиди σ:
αi=|sitrue−s^i|max(σ^i, ϵ)alpha_i = frac{|,s_i^{text{true}} – hat{s}_i,|}{max(hat{sigma}_i, epsilon)}
Поскольку оценка является порядковой, результирующий интервал ограничивается допустимыми значениями от 1 до 5. Результатом работы судьи становится не «этот ответ — 2,1». Теперь он может выполнить одно из трех действий:
«Вероятнее всего, этот ответ находится в зоне отказа, а калиброванный интервал достаточно узок для автоматического повышения уровня ошибки».
«Вероятно, это чистый пас, и интервал между передачами узкий. Выпуск».
«Модель демонстрирует неопределенность в данном случае. Передача дела эксперту-специалисту».
Предметная область и данные
Данная структура является универсальной, но её применение намеренно специфично: оценка видеозаписей критически важных систем автономного вождения . Системы автономного вождения генерируют журналы сценариев и контрфактические сценарии развертывания в таком объеме, что ни одна команда людей не может их обработать. В настоящее время в отрасли регулярно используются эксперты LLM/VLM для оценки ответов моделей, качества прогнозов, обоснований планировщиков и результатов логической цепочки рассуждений, и эти эксперты определяют решения о выпуске. Типология NHTSA, описывающая сценарии аварий с участием легковых автомобилей, включает 37 сценариев; стандарты ISO 26262 и SOTIF требуют калиброванной степени достоверности критически важных для безопасности событий; CARLA Leaderboard 2.0 генерирует больше трафика для проверки в день, чем может покрыть любой бюджет на аннотирование.
В качестве эталонного набора данных мы используем LingoQA (Marcu et al., ECCV 2024), визуальный набор данных для ответов на вопросы в системах автономного вождения, выпущенный компанией Wayve. Каждый элемент представляет собой короткий видеоролик с записью вождения (4 секунды, видеорегистратор, 1 Гц, 5 кадров) с вопросом в свободной форме, эталонным ответом и эталонным баллом классификатора Lingo-Judge. Мы используем стратифицированное подмножество из 200 видеороликов из официального оценочного набора и рассматриваем оценки Lingo-Judge с высокой степенью достоверности как эталонные метки первого уровня.
Типичный образец, тот же самый, который оценивают судьи при производстве:
Вопрос: «Почему транспортное средство замедлило движение здесь?» Исходный ответ: «Потому что пешеход начал переходить дорогу на обозначенном пешеходном переходе». Вариант ответа (тестируемый AV-VLM): «Из-за движения впереди». Итоговый балл: 2.
Приведенная выше качественная диаграмма демонстрирует три реальных задания LingoQA. В задании с оценкой 1 (красная рамка) кандидат увидел в кадре галлюцинацию в виде мотоцикла, которого нет. Обоснование судьи, оценивающего визуальное восприятие, прямо указывает на это противоречие. В задании с оценкой 5 (зеленая рамка) кандидат правильно подтверждает отрицательное утверждение («скутеров не видно»), которое судья, оценивающий только текст, не может проверить, не видя сцены. Задание с оценкой 3 действительно неоднозначно: кандидат частично прав.
Это именно то решение, которое должен принять судья, и такое решение судья, рассматривающий дело только по тексту, не сможет принять правильно, потому что доказательства существуют в пикселях.
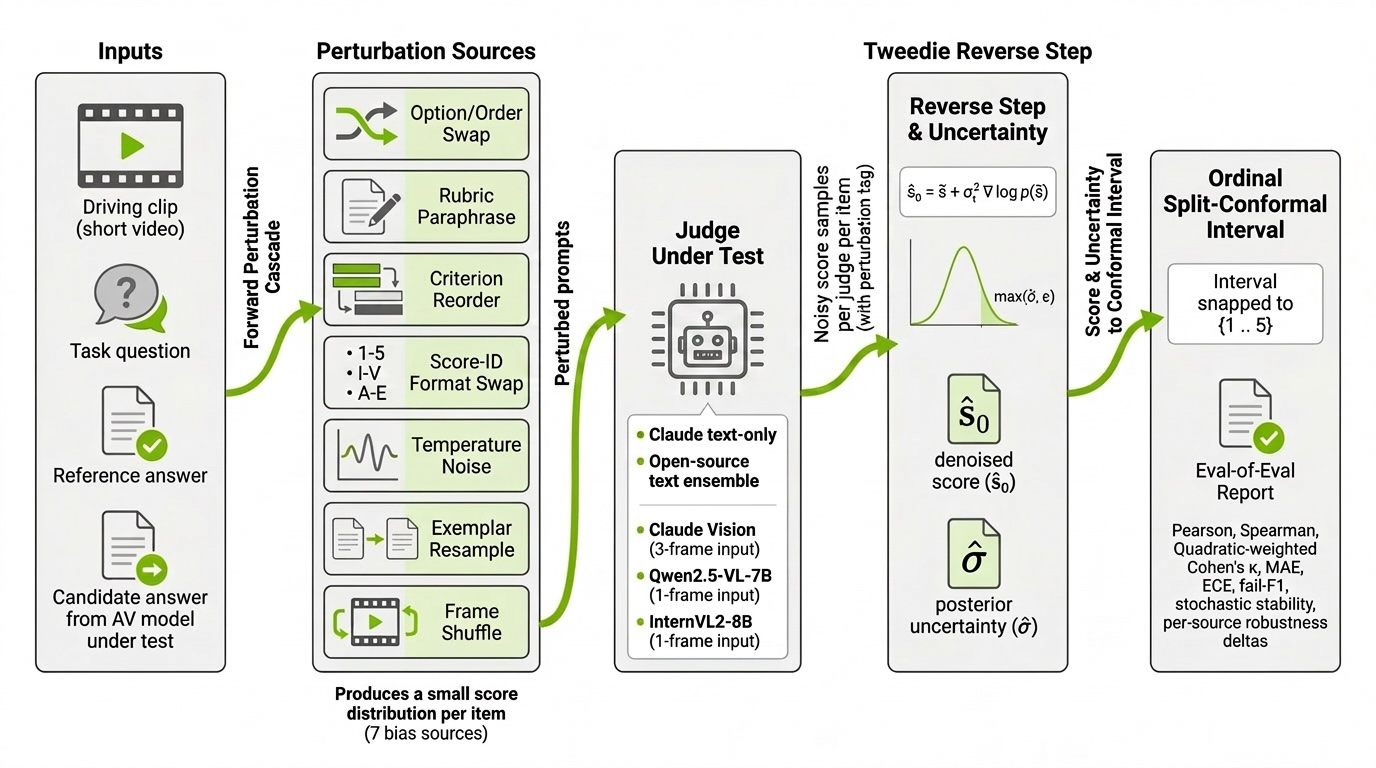
Трубопровод
Система, с помощью которой были получены данные, приведенные в этой статье, умещается на одной диаграмме:
Сверху вниз:
- Входные данные: видеозапись вождения с выборкой кадров, вопрос, эталонный ответ и вариант ответа, предложенный AV-VLM.
- Каскад прямых возмущений: 7 известных операторов предвзятости судьи, программно примененных к подсказке, в результате чего для каждого элемента было получено 22 варианта подсказки.
- Ансамбль судей: оценено пять конфигураций (ансамбль Claude только с текстом, ансамбль с открытым исходным кодом и текстом, Claude с 3 кадрами, Qwen2.5-VL-7B с 1 кадром, InternVL2-8B с 1 кадром). Каждая выдает скалярную оценку плюс однострочное обоснование.
- Образцы зашумленных оценок: распределение оценок по каждому элементу, помеченных уровнем возмущения.
- Обратный шаг Твиди: одношаговое шумоподавление с использованием апостериорного среднего и апостериорной дисперсии.
- Порядковый конформный интервал: с привязкой к границе, стандартизированный с помощью σ Твиди.
- Отчет об оценке: коэффициент Коэна κ, коэффициент Криппендорфа α, ECE, коэффициент Бриера, MAE, fail-F1, стохастическая устойчивость, разница в показателях робастности для каждого источника возмущения.
В результате, при всех пяти конфигурациях судей, на платформе LingoQA было получено 28 400 реальных оценок от судей .
Полная реализация, скрипты, журналы выполнения и все рисунки из этой статьи находятся в репозитории проекта по адресу github.com/syedhumarahim/diffujudge-av.
Какое место это займет в стеке AV-Eval от NVIDIA?
Я разработал эту структуру, руководствуясь принципами NVIDIA AV-Eval: конвейеры оценки, основанные на обучении, заменяют правила, созданные вручную; агентные рабочие процессы, связывающие вывод модели с поиском и структурированным рассуждением; и явная методология оценки результатов оценки. Каждый примитив в DiffuJudge-AV соответствует этому принципу. 7-уровневая каскадная модель возмущений — это агентный рабочий процесс. Слой Tweedie и конформный слой — это цикл калибровки. Внутренняя таксономия поведения из 12 категорий четко соответствует идентификаторам NHTSA до аварии, явлениям ASAM OpenSCENARIO 1.x и маршрутам CARLA Leaderboard 2.0 — тому же словарю сценариев, который уже используется в стеке обучения и оценки AV от NVIDIA.
В репозитории также содержится готовая оболочка для NVILA-8B , собственной эффективной VLM-системы NVIDIA (Liu et al.).
и др., 2024), а также рецепт развертывания, который предоставляет ансамбль из трех судей VLM в качестве совместимого с OpenAI решения.
Конечные устройства NVIDIA NIM . Одно замечание: архитектура NVIDIA-8B пока не поддерживается vLLM.
0.8.4, поэтому в данной статье в качестве заменителей открытой VLM используются Qwen2.5-VL-7B и InternVL2-8B. Интеграционная модель готова к тому дню, когда vLLM получит поддержку NVILA.
Результат: Корреляция Пирсона скрыла характер отказа.
Вот полная таблица показателей:
| Модель | Режим | р | ρ | κ | МАЭ | ECE | Fail-F1 |
| Клод (только текст) | текстовый ансамбль | 0,753 | 0,702 | 0,057 | 0,85 | 0.111 | 0,041 |
| Открытый программный комплекс TEXT | Qwen+Llama+DSV3 | 0,803 | 0,717 | 0.701 | 0,92 | 0.207 | 0,526 |
| Клод ВИЗИОН | 3 кадра | 0,708 | 0,703 | 0,632 | 1.05 | 0,252 | 0,612 |
| Qwen2.5-VL-7B VISION ★ | 1 кадр | 0,857 | 0,856 | 0,837 | 0,57 | 0.121 | 0,712 |
| InternVL2-8B VISION | 1 кадр | 0,766 | 0,753 | 0,738 | 0,60 | 0,084 | 0,511 |
Ключевой столбец — коэффициент Каппа Коэна. Текстовый вариант модели Клода показал достойный коэффициент корреляции Пирсона, но практически нулевое порядковое согласие. Почему? Потому что его прогнозы были сжаты в узкий средний диапазон. Модель учитывала направление, но не была полезна на практике.
Это и есть ловушка Пирсона :
Судья может сохранить приоритетность решений, одновременно разрушая те рамки принятия решений, которые для вас действительно важны.
Система проверки безопасности должна различать:
- Явная ошибка → отправка на проверку специалистом или проведение регрессионного анализа.
- Частичный ответ → проверить или оставить в неопределенности.
- Безупречная проверка → допустить проверку с более низким приоритетом.
Судья, отказывающийся использовать нижнюю и верхнюю границы шкалы, не сможет поддерживать такой рабочий процесс. Показатель F1 обнаружения ошибок Клода, основанный только на тексте, составляет 0,041 . Он выявляет 2% фактических ошибок. Та же модель с тремя кадрами показывает результат 0,612 . Qwen2.5-VL достигает еще более высокого значения — 0,712 , при κ = 0,837.
Результат: изменение восприятия повлияло на поведение Клода при подсчете очков.
Удивительным открытием стало не только то, что оценка только текста показала худшие результаты. Дело в том, что та же самая модель Клода вела себя по-разному, когда ей предоставлялись кадры.
Текстовый вариант прогнозов Клода сжал до приблизительного диапазона [1,3, 3,5] . При наличии трех управляющих кадров диапазон расширился до приблизительного диапазона [1,0, 5,0] .
На втором графике выше представлена только текстовая версия модели Клода: примерно 80% всех оценок — 3 балла, с небольшим количеством оценок 1 и 5. На третьем графике представлена та же модель Клода с тремя рамками: оценки теперь распределены по всей порядковой шкале. Та же модель, та же рубрика, те же пункты.
Сжатие не являлось свойством семейства моделей или общим эффектом RLHF. Оно зависело от режима ввода. Когда судья видел только текст, он уклонялся от прямого ответа. Когда судья видел сцену, он был готов использовать полную порядковую шкалу. Многие конвейеры оценки до сих пор используют подсказки для судьи, содержащие только текст, даже для визуальных задач. Они просят судью сравнить предлагаемый ответ с эталонным ответом, но судья никогда не видит лежащих в его основе доказательств. Для сцен вождения это серьезное ограничение. Судья, рассматривающий только текст, может проверить семантическое сходство; судья, рассматривающий визуальные задачи, может проверить, основан ли ответ на сцене.
Тот же результат, подтвержденный другим способом, — разброс значений по каждому элементу относительно золота:
Левая панель: каждое текстовое предсказание Клода находится внутри интервала [1.3, 3.5] независимо от фактического местоположения золота. Правая панель: тот же Клод на тех же предметах с тремя рамками. Предсказания теперь поднимаются по линии y = x.
Результат: система визуализации позволяет принимать решения на уровне, соответствующем порогу безопасности.
Ключевой оперативный показатель для системы проверки аудио- и видеотестов — это способность судьи отметить неверный ответ, когда эталонный ответ неверен? Это обнаружение сбоя при пороговом значении эталонного ответа ≤ 2.
- Claude TEXT-only: точность обнаружения ошибок 1,00, но полнота 0,02 . Обнаруживает 2% фактических ошибок, поскольку почти никогда не выдает «≤ 2».
- Claude VISION: точность 0,45, полнота 0,94 . Выявляет 94% ошибок.
- Qwen2.5-VL-7B: точность 0,43, полнота 1,00.
Для определения прохождения теста (золото ≥ 4) текстовый тест Claude имеет F1 = 0,00. Он никогда не отображает «5», поэтому никогда не может подтвердить прохождение теста без ошибок. Показатель Claude-vision достигает 0,76; Qwen-VL достигает 1,00.
Вот что дает вам на практике сочетание фиксации взгляда и калиброванной шкалы.
Результат: единая тепловая карта смещения оценок экспертов для каждого источника шума.
Одним из наиболее полезных артефактов, предоставляемых каскадом SDJ, является единое изображение, показывающее, к какому из семи известных источников предвзятости оценки наиболее чувствительно каждое семейство моделей. Для каждой ячейки (модель, уровень возмущения) мы усредняем абсолютное изменение оценки относительно опорной точки по всем элементам:
Следует отметить несколько моментов:
- Текстовая версия оценки Клода неизменно нестабильна. Перефразирование критериев, изменение порядка критериев, замена идентификатора оценки и температура — каждый из этих факторов сдвигает среднее значение примерно на 0,4 по шкале от 1 до 5. Это соответствует предсказанию модели диффузионного фрейминга о том, что сжатые, уклончивые оценки судей наиболее сильно меняются при изменении формулировки вопроса.
- Открытый набор текстовых данных примерно в 3 раза более устойчив по каждому столбцу, достигая максимального значения |Δ| = 0,15 при замене оценок и идентификаторов.
- В Qwen2.5-VL преобладает одно конкретное смещение: замена формата идентификатора оценки (арабский → латинский → A–E) сдвигает его среднее значение на 0,44. Знание того, какое именно смещение имеет наибольшее значение, само по себе является действенным: заблокируйте формат оценки в подсказках для этого судьи.
Это именно тот тип готового к аудиту, оценивающего сам процесс оценки артефакта, который необходим конвейеру оценки, чтобы поставляться вместе с основными показателями.
Результат: содержит ли неопределенность сигнал?
Обратный шаг Твиди позволяет получить апостериорное значение σ без дополнительных затрат. Вопрос в том, содержит ли это значение σ информацию. Совпадают ли элементы, которые каскад помечает как неопределенные, с элементами, в которых судья допускает ошибки? Для каждого судьи мы строим график стандартного отклонения выборок возмущений для каждого элемента (показатель апостериорного значения σ) в зависимости от абсолютной ошибки относительно эталонного значения:
Значение σ в Qwen2.5-VL имеет наиболее чистый сигнал (r = 0,26 между прогнозируемым σ и наблюдаемой |ошибкой|). В заданиях со значением σ, близким к нулю, |ошибка| почти никогда не превышает 1; задания со значением σ > 0,6 — это задания, где среднее значение оценки эксперта отличалось на 1–3 балла. Именно в этом режиме диаграмма «ворот безопасности» указывает на необходимость проверки человеком. Теперь у нас есть эмпирические доказательства того, что собственная оценка неопределенности системы выявляет такие задания.
Результат: стохастическая устойчивость достигла первоначальной цели.
Одна из целей заключалась в проверке того, может ли SDJ выявлять и уменьшать стохастическую нестабильность. Я запустил Qwen2.5-VL-7B с 5 случайными начальными значениями при двух температурах для всех 100 визуальных объектов:
| Температура | Медианное значение по каждому элементу стандартное отклонение | Иметь в виду | Фракционные элементы со стандартным отклонением ≤ 0,15 |
| T = 0,6 (шумный базовый уровень, полученный от одного судьи) | 0,40 | 0,40 | 31% |
| T = 0 (детерминированный нижний предел) | 0.00 | 0,024 | 95% |
Зашумлённый базовый уровень практически точно соответствовал ожидаемой нестабильности: около 0,40 на стандартное отклонение элемента, что соответствует данным литературы. При T = 0 95% элементов находились на уровне или ниже первоначального целевого значения 0,15.
/
В контексте диффузионного анализа температура является одним из источников прямого шума. Я не утверждаю, что каждый судья должен работать при T = 0 вечно. Суть в том, что система оценки должна явно измерять эту нестабильность, а не делать вид, что оценка детерминирована, и сообщать апостериорное значение σ наряду с точечной оценкой.
Результат: конформное покрытие соответствует калибровочной мишени.
Целью конформного слоя является достижение эмпирического охвата ≥ 1 − α, где α = 0,10. В трех запусках с достаточным количеством элементов для стабильной калибровки методом разделенного конформного слоя:
| Бегать | n_test | Эмпирическое покрытие | Цель | Средняя ширина интервала |
| Клод (только текст) | 80 | 0,950 | 0.900 | 4.51 |
| Текст с открытым исходным кодом | 80 | 1.000 | 0.900 | 4.50 |
| Клод ВИЗИОН | 20 | 1.000 | 0.900 | 3.50 |
Все три показателя выше целевого значения. Показатель охвата по каждому сегменту (неудовлетворительные/средние/удовлетворительные уровни) также превышает 0,92 в каждой ячейке. Интервалы имеют ширину 3,5–4,5 оценочных единиц по шкале от 1 до 5. Это цена полного охвата на гетерогенном калибровочном наборе.
Ограничения
Несколько важных замечаний, которые стоит отметить сразу. Золотые метки — это результаты высоконадежной классификации Lingo-Judge, а не набор данных, оцененный людьми третьего уровня. Разделение на стрессовые ситуации в стиле CODA-LM (вставки ночью, заслоненные VRU, неоднозначные близкие столкновения) пока не включено. Лучший измеренный показатель ECE составляет 0,084, а не исходный целевой показатель 0,05; последующая изотоническая или калибровка по Платту на калибровочном разделении почти наверняка устранит этот разрыв. В текущем ансамбле VLM два преданных своему делу эксперта (Qwen2.5-VL и InternVL2-8B) вместо запланированных трех. Количество тестовых запусков с визуальными данными меньше, чем количество запусков только с текстом (100 элементов против 200).
Из-за ограниченного количества доступных карт кадров, показатели по разным модальностям представляют собой сводные данные на уровне модели, а не строго сопоставимые данные по каждому элементу. А этап шумоподавления представляет собой одношаговую аналитическую коррекцию Твиди, а не многошаговый алгоритм выборки. Это честные ограничения, но они также напрямую соответствуют плану развития, представленному ниже.
Заключение
Самый важный урок этого проекта заключается не в том, что одна модель превзошла другую. Он в том, что метрика, которую вы оптимизируете во время оценки результатов, определяет, какой критерий оценки вы используете в дальнейшем.
Если бы я оптимизировал систему только по коэффициенту корреляции Пирсона r, я бы выпустил систему оценки Клода, основанную только на тексте, которая почти не использовала бы порядковую шкалу и выявляла бы лишь 2% критически важных отказов. Использование полной таблицы оценки (порядковый κ, F1 обнаружения отказов, калибровка, стохастическая устойчивость) изменило подход к использованию открытой системы оценки VLM с калиброванной неопределенностью и правилом маршрутизации, которое отправляет неоднозначные случаи специалистам. Те же данные, другая метрика, другая система оценки в производственной среде.
В этом и заключается разница между оценкой, которая хорошо выглядит в таблице сравнительных показателей, и оценкой, которая может служить основой для принятия реальных инженерных решений.
В системах оценки, основанных на машинном обучении, особенно в автономном вождении, робототехнике и здравоохранении, следует перестать рассматривать оценки оценщиков как истину в последней инстанции. Это всего лишь измерения. В измерениях присутствует шум. В шуме есть структура. Если мы сможем измерить эту структуру, мы сможем создать более совершенные системы оценки.
Именно это и пытается сделать DiffuJudge-AV: сделать видимыми режимы ошибок оценщика до того, как он станет частью цикла принятия решений в процессе производства. Эссе Ван Луна завершается фразой, которую стоит процитировать: «Если вы можете правильно оценивать, вы можете правильно обучать». Эта работа — один из небольших вкладов в достижение этой цели.
Дальнейшая работа
План действий напрямую вытекает из указанных выше ограничений: небольшой эталонный набор из 50 самых сложных заданий LingoQA, основанный на экспертной оценке третьего уровня, разделение на стрессовые ситуации в CODA-LM для граничных случаев, третий специализированный судья VLM (LLaVA-Critic-7B или NVILA-8B после того, как vLLM получит архитектуру), обученный многослойный персептрон Tweedie, заменяющий аналитическую гауссовскую оценку KDE небольшим шумоподавителем, обученным на признаках уровня возмущений / семейства судей / векторного представления элементов, слой изотонической калибровки post-hoc для устранения оставшегося пробела в ECE, и производственный ансамбль, обслуживаемый NIM, с инструментами A/B-сравнения и версионированием моделей.
Ссылки
- Ши, Ю. и др. Оценка судей: систематическое исследование предвзятости позиции в процессе судейства в рамках магистерской программы по праву. IJCNLP-AACL 2025.
- Чен, С. и др. Оценка предвзятости при выставлении оценок в рамках экзамена LLM в качестве судьи. arXiv 2506.22316, 2025.
- Такур, А. и др. Рейтинговая рулетка: самопротиворечивость в LLM как судье. arXiv 2510.27106, 2025.
- SPUQ: Семантически-возмущенная количественная оценка неопределенности. arXiv 2403.02509, 2024.
- Шенг, Х. и др. Анализ неопределенности LLM-в-функции-судьи с помощью конформного прогнозирования. EMNLP 2025 / arXiv 2509.18658.
- Йе, С. и др. CALM: Многоэтапная система оценки результатов, калиброванная по логическому мышлению. ICLR 2025.
- Ван Л. Ваши оценки рухнут, и вы этого не предвидите, блог, 2025.
- Роббинс, Х. Эмпирический байесовский подход к статистике. Берклианский симпозиум, 1956 (формула Твиди).
- Манор, Х. и Михаэли, Т. О апостериорном распределении в шумоподавлении: применение к количественной оценке неопределенности. ICLR 2024 / arXiv 2309.13598.
- Марку, А. и др. LingoQA: Визуальное решение вопросов для автономного вождения. ECCV 2024 (Wayve).
- Сима, С. и др. DriveLM: Вождение с помощью графического визуального ответа на вопросы. ECCV 2024.
- Лю, З. и др. NVILA: Эффективные модели визуального языка на переднем крае. NVIDIA, arXiv 2412.04468, 2024.
- Лин, Дж. и др. VILA: О предварительном обучении визуальных языковых моделей. NeurIPS 2024 / arXiv 2312.07533 (NVIDIA).
- Ван С. и др. OmniDrive: целостная структура LLM-агента для автономного вождения с 3D-восприятием, рассуждениями и планированием. NVIDIA, arXiv 2405.01533, 2024.
- Мао, Дж. и др. Обзор многомодальных больших языковых моделей для автономного вождения. NVIDIA / Цинхуа, arXiv 2311.12320, 2023.
- Наджм, В.Г. и др. Типология сценариев, предшествующих аварии, для исследований в области предотвращения столкновений. NHTSA / Volpe, 2007.
- Спецификация ASAM eV OpenSCENARIO 1.x. 2022–2024 гг.
Хума Шах Посмотреть все Хума Шах
Источник: towardsdatascience.com
Оцените материал:

