Базы знаний и LLM: паттерн Андрея Карпаты, который меняет правила игры
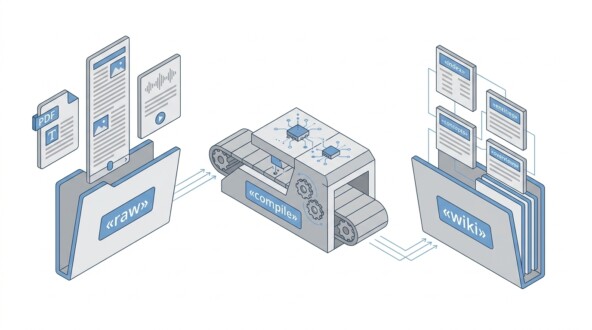
Почему RAG — это тупик для большинства баз знаний — и почему модель Карпаты (raw → wiki) лучше, чем “поиск по чанкам”.
 llm wiki — Андрей Карпаты
llm wiki — Андрей КарпатыПроблема: LLM забывает всё после каждого вопроса
Представьте, что вы читаете пять статей по одной теме. В понедельник — про внимательность в буддизме. Во вторник — про когнитивно-поведенческую терапию. В среду — про юнгианский анализ.
Обычный RAG-пайплайн каждый раз будет заново разбирать эти документы. Каждый вопрос — поиск по векторной базе, извлечение чанков, синтез с нуля. Накопления нет. Связи между документами не сохраняются. Противоречия не фиксируются.
Вы задаёте тонкий вопрос, требующий синтеза из пяти источников — и LLM заново собирает фрагменты. Ничего не строится. Чат-боты с загрузкой файлов, NotebookLM, большинство RAG-систем — все работают именно так.
Андрей Карпаты предложил альтернативу.
Суть идеи: LLM как компилятор знаний
В 2025 году Андрей Карпаты (сооснователь OpenAI, экс-директор Tesla AI) опубликовал gist с описанием паттерна LLM Wiki. Ключевая метафора:
LLM — это компилятор. Сырые источники — исходный код. Wiki — скомпилированный артефакт.
Вместо того чтобы искать по сырым документам при каждом запросе, LLM инкрементально строит и поддерживает постоянную вики — структурированную, связанную коллекцию markdown-файлов. Когда вы добавляете новый источник, LLM не просто индексирует его. Он читает его, извлекает ключевую информацию и интегрирует в существующую вики: обновляет страницы сущностей, пересматривает тематические сводки, отмечает где новые данные противоречат старым.
Знания компилируются один раз и поддерживаются в актуальном состоянии — не пересобираются на каждый запрос.
Три слоя архитектуры
Карпаты описывает систему как три концептуальных слоя на вашей файловой системе:
1. Raw sources (сырые источники)
Папка с curated-документами: статьи, PDF, транскрипты подкастов, главы книг, данные. Это immutable ground truth — LLM читает отсюда, но никогда не изменяет.
2. Wiki (LLM-генерируемая база)
Директория markdown-файлов, которыми LLM полностью владеет: страницы сущностей, концептов, сравнений, обзоров. LLM создаёт, обновляет, поддерживает перекрёстные ссылки.
3. Schema (схема)
Файл (например AGENTS.md или CLAUDE.md), который учит LLM быть дисциплинированным вики-менеджером: структура страниц, конвенции, workflow при приёме источников, ответах на вопросы и обслуживании вики. Вы и LLM совместно эволюционируете этот файл.
Четыре фазы жизненного цикла
Фаза 1: Ingest (приём)
Новый источник попадает в raw/ → LLM читает → обсуждает с вами ключевые выводы → создаёт summary-страницу → обновляет index → обновляет релевантные страницы сущностей и концептов → добавляет запись в log.
Один источник может затронуть 10-15 страниц вики. Карпаты предпочитает принимать источники по одному и оставаться вовлечённым — но можно и пакетно.
Фаза 2: Compile (компиляция)
LLM инкрементально строит структурированную вики:
- Index-файлы с короткими summary всех документов — входная точка для запросов
- Концептуальные статьи (~100 статей, ~400K слов) с обратными ссылками
- Производные артефакты: Marp-слайды, matplotlib-графики, filed-back ответы
LLM автоматически поддерживает граф ссылок между концептами и находит связи для новых статей.
Фаза 3: Query (запросы)
Вы задаёте вопросы по вики. LLM ищет релевантные страницы, читает их и синтезирует ответ с цитированием. Ответы могут принимать разную форму: markdown-страница, сравнительная таблица, слайды, график.
Критически важно: хорошие ответы сохраняются обратно в вики. Сравнение, которое вы запросили. Анализ, который вы открыли. Связь, которую обнаружили. Это ценные артефакты, и они не должны исчезать в истории чата.
Фаза 4: Lint (обслуживание)
Периодически LLM делает health-check вики. Ищет:
- Противоречия между страницами
- Устаревшие утверждения (новые источники опровергают)
- Orphan-страницы без входящих ссылок
- Важные концепты без собственной страницы
- Пропущенные перекрёстные ссылки
- Пробелы в данных, которые можно заполнить веб-поиском
После линтинга — возврат к фазе 2. Вики продолжает расти и улучшаться.
LLM как операционная система
Карпаты также известен метафорой LLM OS — и она идеально стыкуется с LLM Wiki:
- LLM (веса) → CPU: «процессор», замороженные веса модели
- Context window → RAM: рабочая память на текущий шаг
- Tools → I/O: поиск, код, браузер и т.д.
- Wiki на диске → persistent storage: долговременная память
Контекстное окно вмещает только то, что релевантно текущему шагу. Файловая система — это не-волатильная RAM: модель «подкачивает» куски в контекст, как классическая ОС делает paging.
Без файловой памяти агент обречён на амнезию. С ней — знания накапливаются.
Почему это побеждает RAG (для персональных баз знаний)
- Где знания RAG: разбросаны по чанкамLLM Wiki: структурированы в вики
- Синтез RAG: заново при каждом запросеLLM Wiki: один раз, сохраняется
- Связи RAG: не сохраняютсяLLM Wiki: граф перекрёстных ссылок
- Противоречия RAG: не фиксируютсяLLM Wiki: отмечаются и отслеживаются
- Накопление RAG: нет (stateless)LLM Wiki: да (compounding)
- Человекочитаемость RAG: только чанкиLLM Wiki: полноценная вики
- Инфраструктура RAG: векторная БД обязательнаLLM Wiki: до ~сотен страниц — не нужна
Для персонального масштаба (~100 источников, ~сотни страниц) **index.md + контекстное окно LLM достаточно для retrieval**. Векторная БД становится опциональной.
Главное преимущество: knowledge compounds. С каждой новой статьёй, каждым вопросом, каждым lint-прогоном — вики становится богаче. Это работает как сложный процент: чем дольше вы ведёте вики, тем ценнее каждый новый источник.
Практическая реализация: инструменты
Минимальный стек, который подразумевает идея Карпаты (без привязки к конкретным приложениям):
- Файловое хранилище (или любая папка/репозиторий), где лежат raw/ и wiki/
- LLM-агент, который умеет: читать новые raw-источники, обновлять wiki-страницы и вести log.md
- Поиск по тексту (опционально): обычный grep/полнотекст/гибридный поиск — чтобы быстрее находить релевантные страницы для ответа
Минимальный старт за 5 минут
- Создать папки raw/ и wiki/ (в любом удобном хранилище: локально, в репозитории, на сервере)
- Написать AGENTS.md со схемой (типы страниц, workflow)
- Начать складывать источники в raw/ (любым способом)
- Попросить coding-агента «скомпилируй эту папку в вики»
- Задавать вопросы по вики, сохранять хорошие ответы обратно
Живой пример: проект pifai
Один из реальных примеров реализации паттерна — проект pifai. Это база знаний по психологии и философии + чат-бот-психотерапевт.
Архитектура вики в точности повторяет паттерн Карпаты
Что интересно в этом проекте:
- 7 психологических подходов интегрированы в единую вики (ННО, Юнг, Франкл, Уилбер, Минделл, Адизес, Литвак)
- Два режима работы с вики: raw-only (просто сохранить источник) и full ingest (синтез key takeaways, создание/обновление wiki-страниц, перекрёстные ссылки)
- Скилл-система в самом проекте (.agents/skills/): llm-wiki, wiki-faq, wiki-images, summarize — никаких внешних зависимостей
- FAQ-страницы генерируются автоматически: краткий ответ, шаги, таблица сравнения, ссылки на вики
- Telegram-бот использует вики как knowledge base для эмпатичных ответов в стиле ННО
- Стек: Astro + Starlight (документация), Node.js + Cloudflare Workers (бот), Groq/Llama-3.3-70B
Это демонстрирует ключевое преимущество паттерна: вики отделена от приложения. Она живёт как plain markdown — её можно использовать и для сайта документации (Astro/Starlight), и для чат-бота (конденсированная копия в Cloudflare KV), и для локального coding-агента.
Примеры сценариев (на базе pifai)
- Инкрементальный ingest нового источника: добавляете новую статью/главу в raw/YYYY/MMDD/… → агент обновляет релевантные страницы в src/content/docs/ (например, по подходам/авторам/практикам) и фиксирует изменения в log.md.
- Компиляция обзора “под вопрос”: вопрос вида “как разные школы объясняют X?” → агент собирает сравнительную обзорную страницу, добавляет перекрёстные ссылки на authors/* и practices/*, и сохраняет результат как wiki-страницу (чтобы он не оставался только в чате).
- Автогенерация FAQ как продуктового слоя над вики: вопрос → короткий ответ + “шаги” + таблица сравнения подходов + ссылки на первоисточники/вики (удобно для бота, где нужна повторяемая структура).
- “Витрина” знаний: те же markdown-страницы можно отдать любому интерфейсу (сайт, бот, внутренний портал) — интерфейс меняется, база знаний остаётся той же.
- Генерация синтетики для оценки качества: из вики можно генерировать Q/A-диалоги, кейсы и тесты, чтобы прогонять регрессии и измерять, как бот отвечает “по базе”.
Что дальше: от вики к персональной модели
Карпаты упоминает следующую ступень: использование вики для генерации синтетических обучающих данных и fine-tuning модели. Чтобы знания жили не только в контекстном окне, но и в весах модели.
Это превращает персональную базу знаний в персональную модель. Вики становится training data factory.
Представьте: вы месяцами ведёте вики по теме. LLM знает её. Затем вы генерируете из неё синтетические диалоги и дообучаете модель. Теперь у вас модель, которая «знает» вашу область в своих весах — не только через промпты.
Как начать свою базу знаний
- Создайте структуру: raw/, wiki/, AGENTS.md
- Определите схему: какие типы страниц, какие секции, как называть файлы
- Начните с 3-5 хороших источников по одной теме
- Попросите LLM-агента скомпилировать их в вики — и посмотрите что получится
- Добавляйте по одному источнику, проверяйте обновления, направляйте LLM
- Раз в неделю — lint-прогон: что устарело, где пробелы, какие новые вопросы исследовать
Не пытайтесь импортировать всё сразу. Вики растёт органично — добавляйте заметки по мере поступления информации. Пусть LLM делает тяжёлую работу по структурированию; ваша задача — sourcing, exploration и правильные вопросы.
Резюме
Паттерн LLM Wiki меняет фундаментальный подход к работе LLM со знаниями:
- Вместо «извлеки чанки → синтезируй → выбрось» (RAG)
- Используем «скомпилируй в вики → переиспользуй → обновляй» (Wiki)
Результат — знания накапливаются, а не пересобираются. Связи сохраняются. Противоречия отслеживаются. Каждый новый источник делает базу ценнее.
И вся эта система живёт в обычных markdown-файлах на вашем диске. Никаких векторных баз. Никакого vendor lock-in. Просто файлы и LLM, который умеет их читать и писать.
LLM — компилятор. Raw — исходники. Wiki — артефакт. Файлы — память.
Источник: vc.ru
Оцените материал:
