ATLAS: Практические законы масштабирования для многоязычных моделей
Мы представляем новые законы масштабирования для многоязычных языковых моделей. ATLAS предоставляет рекомендации по смешиванию данных и обучению наиболее эффективных моделей для работы с языками, выходящими за рамки английского.
Быстрые ссылки
- Бумага
- Делиться
Более 50% пользователей моделей ИИ говорят на языках, отличных от английского, однако общедоступные законы масштабирования в подавляющем большинстве случаев ориентированы на английский язык. Этот дисбаланс создает критический пробел в открытых исследованиях, оставляя разработчиков моделей, которым предстоит обслуживать миллиарды международных и многоязычных пользователей, без основанных на данных рекомендаций по ключевым решениям в области эффективности, качества и стоимости при разработке моделей для языков, отличных от английского, или с учетом специфических языковых сочетаний.
В докладе «ATLAS: Адаптивные законы масштабирования переноса для многоязычной предварительной подготовки, тонкой настройки и преодоления «проклятия многоязычия»», который будет представлен на ICLR 2026, мы стремимся восполнить этот пробел. Мы представляем крупнейшее на сегодняшний день публичное исследование многоязычной предварительной подготовки, охватывающее 774 запуска обучения для моделей с 10 млн–8 млрд параметров. Оно включает данные по более чем 400 языкам и оценки на 48 языках. В результате этого исследования мы оцениваем синергию между 1400 парами языков и представляем адаптивные законы масштабирования переноса (ATLAS) для построения многоязычных моделей, которые позволяют специалистам эффективно балансировать соотношение языков в обучающих данных с размером модели.
ATLAS: единый закон масштабирования, адаптирующийся к многоязычным смесям.
ATLAS — это простой и практичный подход к определению оптимального размера модели, объема данных и языковых сочетаний для обучения. В отличие от традиционных законов масштабирования, ориентированных на моноязычные среды, ATLAS предоставляет эти рекомендации для более сложных многоязычных сред. Он специально оптимизирует производительность на целевом языке (например, каталанском), используя данные из нескольких разных языков. ATLAS расширяет эти традиционные принципы законов масштабирования за счет трех компонентов:
- Матрица межъязыкового переноса, используемая для определения того, какие языки лучше всего изучать вместе.
- Закон масштабирования, который дает рекомендации по эффективному расширению размера модели и объема данных по мере увеличения количества поддерживаемых языков.
- Правила определения того, когда следует предварительно обучать модель с нуля, а когда — дообучать ее на основе многоязычной контрольной точки.
ATLAS достигает этого за счет обучения на сотнях многоязычных экспериментов (с использованием корпуса MADLAD-400, содержащего более 750 запусков на более чем 400 языках) и учета трех различных источников данных: 1) целевой язык, 2) языки-переносчики, выявленные в ходе эмпирического анализа (например, каталанский может включать латинские языки, такие как испанский, португальский и итальянский), и 3) все остальные языки. Этот новаторский подход позволяет закону определить, насколько каждый источник действительно помогает или мешает целевому языку, чего не было в предыдущих законах.
Оценка
Мы использовали набор данных MADLAD-400 для оценки того, насколько хорошо ATLAS предсказывает производительность модели на новых размерах модели, различных объемах обучающих данных или новых языковых смесях . Для этого мы измеряли производительность, используя функцию потерь, не зависящую от словаря, на более чем 750 независимых запусках в моноязычных, двуязычных и многоязычных средах. Наши оценки показывают, что ATLAS неизменно превосходит предыдущие работы.
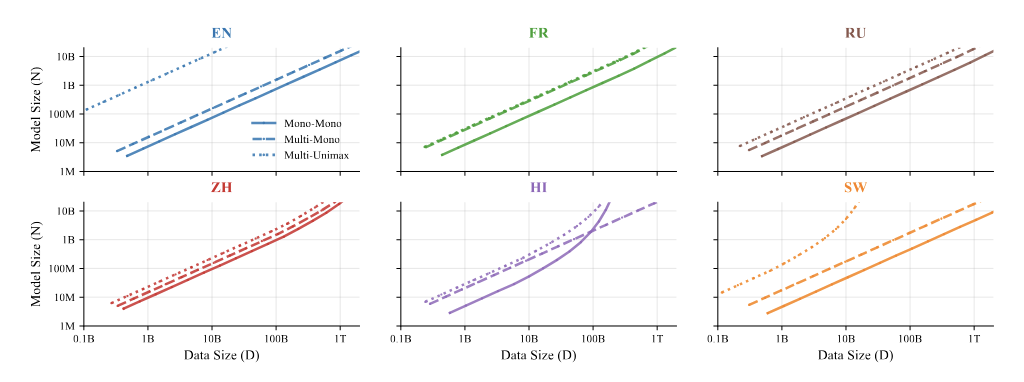
Для шести языков — английского (EN), французского (FR), русского (RU), китайского (ZH), хинди (HI) и суахили (SW) — мы проанализировали, как ATLAS предсказывает оптимальный размер модели ( N ) и размер данных ( D ), которые следует масштабировать. При сравнении этих оптимальных траекторий масштабирования для разных языков мы сделали два наблюдения. Кривые выглядят поразительно похожими, но обучение с использованием многоязычного словаря или полностью многоязычных данных сопряжено с затратами вычислительной эффективности — особенно для английского языка. Языки с ограниченными ресурсами демонстрируют восходящие изгибы по мере истощения данных, и модели трудно обучаться на основе повторения данных. ATLAS явно моделирует эти эффекты.

На этих диаграммах показаны оптимальные траектории масштабирования (размер модели ( N ) и размер данных ( D )), определенные ATLAS для каждого языка и типа модели. Линии представляют три конфигурации: сплошная (одноязычный словарь/данные), пунктирная (многоязычный словарь/одноязычные данные) и точечная (многоязычный словарь/многоязычные данные). Пунктирные линии неизменно показывают самые высокие значения, указывая на то, что обучение с использованием полностью многоязычной конфигурации требует немного больше вычислительных ресурсов для достижения того же качества.
Карта межъязыкового переноса
Далее мы измерили синергию и интерференцию между языками в масштабе, создав матрицу, которая количественно определяет, насколько обучение на языке А помогает (или вредит) языку В. Наши результаты показывают очень наглядные данные: норвежскому языку в основном помогают шведский и немецкий, малайскому — индонезийский, а арабскому — иврит. Английский, французский и испанский являются наиболее полезными языками для обучения, вероятно, из-за присущего им качества, разнообразия и количества текста на этих языках, представленного в интернете.
Анализ показывает, что наиболее значимым фактором, определяющим положительный перенос, является принадлежность к одной письменности и/или языковой семье (например, латинская письменность), статистически значимое различие с p < .001. Английский язык помогает многим, но не всем языкам; и перенос не всегда симметричен ( A может помочь B больше, чем B помогает A ). Эти измерения превращают «интуитивные предположения» в основанные на данных решения по сочетанию языков.
Эта тепловая карта отображает матрицу межъязыкового переноса, количественно оценивая синергию и взаимосвязь между языками. Красный цвет указывает на то, что язык помогает, а синий — на то, что он мешает. В прямоугольниках выделены 5 наиболее важных вспомогательных языков для каждого целевого языка. Языки, использующие одну и ту же систему письма (например, латинский алфавит), демонстрируют значительно большую синергию.
Расшифровка «проклятия многоязычия» с помощью четких правил масштабирования.
«Проклятие многоязычия» — это явление, при котором модели, обученные на нескольких языках, демонстрируют снижение производительности с каждым новым языком из-за ограниченной пропускной способности модели. Мы формализуем эту проблему с помощью закона масштабирования, который учитывает не только размер модели ( N ) и количество обучающих данных ( D ), но и количество языков в этих данных ( K ). Применив этот закон ко многим экспериментам, мы обнаружили, что, хотя добавление языков приводит к небольшому увеличению пропускной способности, наблюдается высокая степень положительного переноса. Это означает, что если мы хотим обучить модель для поддержки вдвое большего количества языков (2· K ), то нам следует увеличить размер модели в 1,18 раза, а общий объем данных — в 1,66 раза. Это соответствует 83% данных на каждом из 2K языков. Хотя данных на каждый язык меньше, положительная синергия от обучения на всех языках компенсирует ограничения пропускной способности, вызывающие снижение производительности.
Эти кривые показывают, насколько следует увеличить размер модели N или размер данных D при масштабировании от K до rK языков обучения. Например, синяя сплошная линия показывает все возможные варианты увеличения N и/или D для достижения той же производительности с 2K , что и с K языками. Пунктирная фиолетовая линия показывает наиболее эффективный с вычислительной точки зрения способ увеличения N и D при увеличении K.
Когда следует проводить предварительное обучение, а когда — тонкую настройку многоязычной контрольной точки
Для десяти языков мы сравниваем два пути получения модели с наилучшими характеристиками: (а) предварительное обучение с нуля на целевом языке или (б) тонкая настройка на основе сильной многоязычной контрольной точки «Unimax». Вариант (б), вероятно, обеспечит наилучшие результаты с минимальными дополнительными вычислительными затратами, поскольку модель уже достаточно сильна в разных языках. Однако, если обучение модели может занять гораздо больше времени, то вариант (а) часто может дать лучшие долгосрочные результаты. Наша цель — найти точку пересечения между двумя кривыми обучения, исходя из того, сколько вычислительных ресурсов может потратить разработчик модели.
Наши результаты показывают, что тонкая настройка выигрывает на ранних этапах, но предварительное обучение становится предпочтительнее, как только вы можете позволить себе достаточное количество токенов. В наших запусках точка пересечения обычно находится между ~144B и 283B токенами (зависит от языка) для моделей с 2B параметрами. Далее мы построили график точки пересечения как функцию размера модели. Это дает конкретное, учитывающее бюджет правило: если ваш бюджет токенов и вычислительных ресурсов ниже точки пересечения для вашего размера модели, начните с многоязычной контрольной точки; в противном случае предварительное обучение с нуля обычно завершается с лучшими результатами. Обратите внимание, что точные пороговые значения зависят от базовой модели и ее комбинации.
По мере увеличения размера модели увеличивается и объем вычислительных ресурсов (или обучающих токенов, поскольку C = 6 ND ), необходимых для достижения точки пересечения (где предварительное обучение с нуля лучше, чем тонкая настройка). Мы оцениваем функцию для точки пересечения на основе размера модели. Вы можете увидеть, как это оценочное правило ( черная линия ) приблизительно соответствует точкам пересечения, найденным для 10 языков, представленных на графике.
Попробуйте сами!
Выходя за рамки масштабирования, ориентированного исключительно на английский язык, ATLAS предоставляет дорожную карту для разработчиков моделей по всему миру. Его можно напрямую применять для масштабирования языковых моделей за пределы английского языка, помогая разработчикам:
- Планируете обучить новую многоязычную или неанглоязычную модель? Используйте рисунок 1 или таблицу C.1 из статьи, чтобы получить представление о потенциальных законах масштабирования в зависимости от словарного запаса или выбора параметров обучения.
- Выбираете новый набор обучающих материалов? Обратитесь к матрице переноса (Рисунок 2), чтобы выбрать исходные языки, которые, согласно эмпирическим данным, помогают вашим целевым группам, особенно тем, которые используют одну и ту же письменность/семейство языков.
- Обучаете новую модель с большим количеством языков? Обратитесь к разделу 5, чтобы определить, как наиболее эффективно расширить размер модели и объем данных, чтобы смягчить последствия «проклятия многоязычия».
- Ограничения по вычислительным ресурсам? Обратитесь к разделу 6, чтобы решить, следует ли вам дообучать многоязычную модель или предварительно обучить ее с нуля.
Мы надеемся, что эта работа позволит создать новое поколение многоязычных моделей, обслуживающих миллиарды людей, не говорящих по-английски.
Благодарности
Мы благодарим Люка Зеттлемойера, Кэтрин Арнетт и Стеллу Бидерман за полезные обсуждения статьи. Мы благодарим Бяо Чжана и Хавьера Гарсию за технические обсуждения и отзывы по предварительным направлениям исследований.
Источник: research.google
Оцените материал:
