От логарифмической функции потерь к градиентному спуску, шаг за шагом.
Делиться

Сегодняшняя модель — логистическая регрессия.
Если вы уже знакомы с этой моделью, вот вам вопрос:
Логистическая регрессия — это регрессор или классификатор ?
Этот вопрос сродни вопросу: помидор — это фрукт или овощ ?
С точки зрения ботаника, помидор — это фрукт, потому что они изучают его структуру: семена, цветы, биологию растения.
С точки зрения повара, помидор — это овощ, потому что они обращают внимание на вкус, на то, как он используется в рецепте, добавляется ли он в салат или десерт.
Один и тот же объект, два правильных ответа, потому что точка зрения разная.
Логистическая регрессия работает именно так.
- С точки зрения статистики/обобщенной линейной модели , это регрессия. И в этой системе координат в любом случае нет понятия «классификации». Существуют гамма-регрессия, логистическая регрессия, регрессия Пуассона…
- С точки зрения машинного обучения , он используется для классификации. Следовательно, это классификатор.
Мы вернемся к этому позже.
На данный момент можно с уверенностью сказать одно:
Логистическая регрессия очень хорошо подходит, когда целевая переменная является бинарной , и обычно y кодируется как 0 или 1.
Но…
Что представляет собой классификатор для модели, основанной на весах?
Таким образом, y может принимать значения 0 или 1.
0 или 1 — это же числа, верно?
Таким образом, мы можем просто рассматривать y как непрерывную переменную!
Да, y = ax + b, где y = 0 или 1.
Почему нет?
Возможно, вы спросите: почему именно сейчас? Почему этот вопрос не был задан раньше?
Что ж, для моделей, основанных на расстоянии и на деревьях решений, категориальная переменная y действительно является категориальной.
Когда y — это категориальное значение, например, красный, синий, зеленый или просто 0 и 1:
- В алгоритме K-NN классификация осуществляется путем анализа соседей каждого класса.
- В центроидных моделях сравнение производится с центроидом каждого класса.
- В дереве решений вы вычисляете доли классов в каждом узле.
Во всех этих моделях:
Метки классов — это не числа.
Это категории.
Алгоритмы никогда не рассматривают их как значения.
Таким образом, классификация происходит естественно и незамедлительно.
Но в случае с моделями, основанными на весе, все работает по-другому.
В модели, основанной на весах, мы всегда вычисляем что-то вроде:
y = ax + b
или, позднее, более сложная функция с коэффициентами.
Это означает:
Эта модель работает с числами повсюду.
Итак, вот ключевая идея:
Если модель выполняет регрессию, то ту же самую модель можно использовать для бинарной классификации.
Да, мы можем использовать линейную регрессию для бинарной классификации!
Поскольку двоичные метки равны 0 и 1 , они уже являются числовыми.
В этом частном случае мы можем применить метод наименьших квадратов (МНК) непосредственно к случаям y = 0 и y = 1.
Модель будет соответствовать прямой линии, и мы можем использовать ту же формулу в замкнутом виде, как показано ниже.

Мы можем использовать тот же метод градиентного спуска, и он прекрасно сработает:

А затем, чтобы получить окончательное предсказание класса, мы просто выбираем пороговое значение .
Обычно это 0,5 (или 50 процентов), но в зависимости от того, насколько строгим вы хотите быть, вы можете выбрать другое значение.
- Если прогнозируемое значение y≥0,5, прогнозируйте класс 1.
- В противном случае, класс 0
Это классификатор.
А поскольку модель выдает числовой результат, мы можем даже определить точку, где: y=0,5.
Это значение x определяет границу принятия решений .
В предыдущем примере это происходит при x=9.
На этом этапе мы уже зафиксировали одну ошибку классификации .
Однако проблема возникает, как только мы вводим точку с большим значением x.
Например, предположим, что мы добавим точку с параметрами: x = 50 и y = 1.
Поскольку линейная регрессия пытается построить прямую линию через все данные, это единственное большое значение x сдвигает линию вверх.
Граница принятия решений смещается от x= до приблизительно x=12 .
И теперь, с этой новой границей, мы получаем две ошибочные классификации .

Это иллюстрирует главную проблему:
Линейная регрессия, используемая в качестве классификатора, чрезвычайно чувствительна к экстремальным значениям x. Граница принятия решений резко смещается, и классификация становится нестабильной.
Это одна из причин, почему нам нужна модель, которая не ведет себя линейно бесконечно. Модель, которая остается в диапазоне от 0 до 1, даже когда x становится очень большим.
Именно это нам и даст логистическая функция.
Как работает логистическая регрессия
Мы начинаем с ax + b, как и в линейной регрессии.
Затем мы применяем функцию, называемую сигмоидной или логистической функцией.
Как видно на скриншоте ниже, значение p находится в диапазоне от 0 до 1, что идеально.
- p(x) — это прогнозируемая вероятность того, что y = 1.
- 1 − p(x) — это прогнозируемая вероятность того, что y = 0
Для классификации можно просто сказать:
- Если p(x) ≥ 0,5, предскажите класс 1.
- В противном случае, предскажите класс 0.

От вероятности к логарифмической функции потерь
Теперь линейная регрессия методом наименьших квадратов (OLS) пытается минимизировать среднеквадратичную ошибку (MSE).
Для бинарной целевой переменной используется логистическая регрессия на основе функции правдоподобия Бернулли . Для каждого наблюдения i:
- Если yᵢ = 1, то вероятность данной точки данных равна pᵢ.
- Если yᵢ = 0, то вероятность данной точки данных равна 1 − pᵢ
Для всего набора данных функция правдоподобия представляет собой произведение по всем i. На практике мы берем логарифм, который превращает произведение в сумму.
С точки зрения обобщенной линейной модели (GLM) , мы стремимся максимизировать эту логарифмическую функцию правдоподобия.
С точки зрения машинного обучения , мы определяем функцию потерь как отрицательный логарифм правдоподобия и минимизируем её. Это даёт обычную логарифмическую функцию потерь .
И это эквивалентно. Мы не будем проводить здесь демонстрацию.

Градиентный спуск для логистической регрессии
Принцип
Как и в случае с линейной регрессией, здесь также можно использовать градиентный спуск . Идея всегда одна и та же:
- Начните с некоторых начальных значений a и b.
- Вычислите функцию потерь и её градиент (производную) по параметрам a и b.
- Немного переместите a и ba в направлении, которое уменьшит потери.
- Повторить.
Ничего загадочного.
Процесс тот же, что и раньше, с сохранением механического механизма.
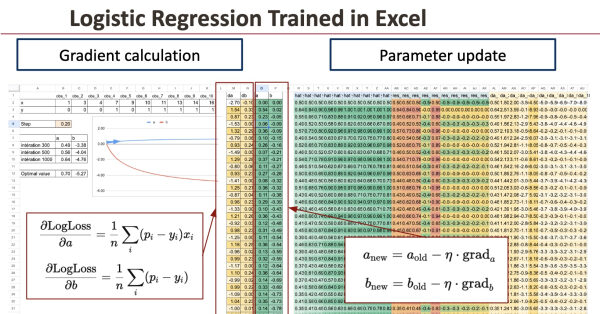
Шаг 1. Расчет градиента
В логистической регрессии градиенты среднего логарифма функции потерь имеют очень простую структуру.
Это просто средний остаток .
Ниже мы приведем результат, полученный с помощью формулы, которую можно реализовать в Excel. Как видите, в итоге все довольно просто, хотя формула логарифмической функции потерь на первый взгляд может показаться сложной.
В Excel эти две величины можно вычислить с помощью простых формул SUMPRODUCT.

Шаг 2. Обновление параметров
Как только градиенты становятся известны, мы обновляем параметры.
Этот этап обновления повторяется на каждой итерации.
Итерация за итерацией значение функции потерь уменьшается, а параметры сходятся к оптимальным значениям.

Теперь у нас есть полная картина.
Вы ознакомились с моделью, функцией потерь, градиентами и обновлениями параметров.
А благодаря подробному отображению каждой итерации в Excel, вы можете фактически экспериментировать с моделью : изменять значение, наблюдать за движением кривой и видеть, как шаг за шагом уменьшается значение функции потерь.
Удивительно приятно наблюдать, как всё так чётко и логично сочетается.

А что насчет многоклассовой классификации?
Для моделей, основанных на расстоянии и на деревьях:
Никаких проблем.
Они естественным образом обрабатывают несколько классов, поскольку никогда не интерпретируют метки как числа.
А что насчет моделей, основанных на весе?
Здесь мы столкнулись с проблемой.
Если мы напишем номера класса: 1, 2, 3 и т. д.
Затем модель интерпретирует эти числа как действительные числовые значения.
Это приводит к проблемам:
- Модель считает, что класс 3 «больше», чем класс 1.
- Середина между 1-м и 3-м классами — это 2-й класс.
- Расстояние между классами становится значимым
Но в контексте классификации ничего из этого не соответствует действительности.
Так:
Для моделей, основанных на весах, мы не можем просто использовать y = 1, 2, 3 для многоклассовой классификации.
Данная кодировка неверна.
Позже мы увидим, как это исправить.
Заключение
Начав с простого бинарного набора данных, мы увидели, как модель, основанная на весах, может выступать в качестве классификатора, почему линейная регрессия быстро достигает своих пределов и как логистическая функция решает эти проблемы, поддерживая значения прогнозов в диапазоне от 0 до 1.
Затем, выразив модель через функцию правдоподобия и логарифмическую функцию потерь, мы получили формулировку, которая является одновременно математически обоснованной и простой в реализации.
И как только все данные помещены в Excel, весь процесс обучения становится видимым: вероятности, функция потерь, градиенты, обновления и, наконец, сходимость параметров.
Благодаря подробной таблице итераций вы можете наглядно увидеть , как модель улучшается шаг за шагом.
Вы можете изменить значение, отрегулировать скорость обучения или добавить точку и мгновенно увидеть, как реагирует кривая и функция потерь.
В этом и заключается настоящая ценность применения машинного обучения в электронных таблицах: ничто не скрыто, и каждое вычисление прозрачно.
Построив логистическую регрессию таким образом, вы не только поймете саму модель, но и поймете, зачем она была обучена.
И это интуитивное понимание останется с вами, когда мы перейдем к более продвинутым моделям позже в рамках Адвент-календаря.
Источник: towardsdatascience.com