Привет, Хабр! На связи команда Рег.облака. Мы давно следим за развитием Retrieval-Augmented Generation (RAG) и хотели проверить, как эта технология работает в живых сценариях.
У нас есть ИИ-ассистент — это образ виртуальной машины с предустановленными Ollama, Open WebUI и набором моделей. Его можно развернуть в пару кликов и сразу работать с LLM в приватном окружении. Но мы решили пойти дальше и проверить, как он справится в прикладной задаче: собрать чат-бота для нашей техподдержки.
Навигация по тексту
Задача и критерии успеха
Что за ассистент и из чего он состоит
Что именно входит в образ
Как реализован RAG под капотом
Как это работает внутри ИИ-ассистента
CPU или GPU: где лучше запускать
Практическая часть: бот для поддержки
Безопасность и приватность
Что мы узнали
Что дальше
Задача и критерии успеха
Нам нужно было проверить, насколько реально встроить RAG в повседневный процесс поддержки без fine-tuning.
Что проверяли:
можно ли быстро собрать рабочего чат-бота на базе нашего ИИ-ассистента (Ollama + Open WebUI) с фронтендом в корпоративном Rocket.Chat и автоматизацией через n8n;
даёт ли он ответы по актуальным документам (без переобучения модели);
укладывается ли по задержкам и удобен ли в сопровождении в облаке.
Почему не fine-tuning: он дорогой и инерционный, а документы постоянно обновляются. RAG подмешивает знания из базы «на лету» и решает задачу актуальности.
Но обо всём по порядку.
Что за ассистент и из чего он состоит
Вместо того чтобы дообучать модели, мы собрали решение из готовых кубиков:
Ollama — движок для работы с LLM. Поддерживает популярные модели (от компактного Groq 4B до DeepSeek 32B).
Open WebUI — веб-интерфейс, который включает в себя чат.
Набор LLM — предустановленные модели для разных сценариев; запуск возможен и на CPU, и на GPU — всё зависит от выбранной модели и требований к производительности.
Что именно входит в образ
Образ содержит Ollama, Open WebUI и набор готовых моделей (~60 GB). Один и тот же образ подходит и для CPU, и для GPU: при наличии GPU автоматически стартует профиль с ускорением.
Как реализован RAG под капотом
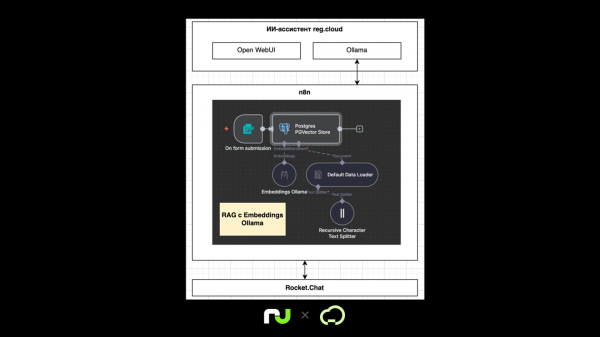
У ИИ-ассистента по умолчанию уже есть встроенный RAG: достаточно загрузить документы в Open WebUI, и они будут использоваться в ответах. Но для эксперимента мы решили собрать свой кастомный сценарий — вынесли хранение и обработку знаний в Postgres и связали всё через n8n.
У такого RAG-сценария на базе n8n и Ollama есть два ключевых процесса:
1. Загрузка знаний в базу
Файл загружается через форму в n8n.
Default Data Loader преобразует файл (PDF, TXT, MD) в текст.
Recursive Character Text Splitter делит текст на чанки по 1000 символов.
Embeddings Ollama (nomic-embed-text) превращает каждый чанк в векторное представление.
Векторы и текстовые фрагменты сохраняются в Postgres с расширением PGVector (n8n_knowledge_base).
📌 Этот процесс — на схеме ниже:

2. Формирование ответа на запрос
Сотрудник пишет сообщение в Rocket.Chat.
n8n преобразует текст запроса в вектор (через ту же модель Embeddings Ollama).
Выполняется поиск ближайших векторов в n8n_knowledge_base.
Найденные фрагменты подмешиваются к запросу и передаются в Ollama для генерации ответа.
Результат возвращается в Rocket.Chat, а история сохраняется в n8n_chat_histories.
Такое разделение важно: Embeddings Ollama используется и при загрузке файлов, и при обработке запросов пользователей. Благодаря этому бот всегда отвечает, опираясь на актуальные документы из базы.
Как это работает внутри ИИ-ассистента
Под капотом процесс выглядит так:
Запрос пользователя поступает к узлу AI Agent.
Узел отправляет запрос в Ollama.
Ollama понимает, что нужны данные из базы знаний, и вызывает инструмент PostgreSQL PGVector Store.
Перед обращением к базе формируется вектор запроса через Embedding Ollama (она работает на той же ВМ, что и основная модель).
В PGVector Store ищутся релевантные фрагменты текста, которые возвращаются в модель и используются при генерации ответа.
CPU или GPU: где лучше запускать
CPU-тариф: подходит для тестов и демо. Ответы занимают 20–40 секунд и более. Голосовые функции работают нестабильно, часть моделей зависает.
GPU-тариф: продуктивный вариант. Ответы обычно занимают 2–30 секунд. Есть озвучка ответов, но распознавание русской речи слабое.
Минимальный конфиг без GPU (только текстовые запросы):
8 vCPU / 32 GB RAM / 100 GB NVMe.
Смена тарифа CPU ↔ GPU возможна, но занимает до 15 минут.
Дополнение: предустановленные модели и ориентиры по ресурсам (оценочно; для продакшена рекомендуем GPU)
gemma-3-12b — ~8.1 GB
deepSeek-R1-Distill-Qwen-14B — ~9 GB
deepseek-r1-distill-qwen-32b — ~20 GB
grok-3-gemma3-12b-distilled — ~12.5 GB
grok-3-reasoning-gemma3-4b-distilled — ~4.13 GB
llama-3-8b-gpt-4o-ru1.0 — ~4.7 GB
Совокупно — порядка 60 GB диска под модели (без учёта вашего контента).
Практическая часть: бот для поддержки
Наш коллега Игорь Голубев, старший специалист техподдержки облачных сервисов, собрал пример — бот поддержки на связке Ollama + n8n + Rocket.Chat.
Рабочий процесс «Add Document»
Для загрузки документов мы используем тот же конвейер, что описан выше: форма → Data Loader → Splitter → Embeddings Ollama → PGVector Store.
В итоге тексты и их векторные представления попадают в базу n8n_knowledge_base, откуда потом подтягиваются для ответов бота.
Рабочий процесс «Получение запроса из Rocket.Chat»
Schedule Trigger — опрос API каждые 10 секунд.
⚠️ В прототипе был выбран таймер, но можно использовать вебхуки Rocket.Chat для мгновенной реакции.
HTTP Request (GET /api/v1/dm.list) — список чатов и последних сообщений.
Split Out — разбиение массива ims.
Remove Duplicates — исключение уже обработанных сообщений.
If — фильтрация сообщений от самого бота.
Edit Fields (Set) — подготовка sessionId и chatInput.
Обработка запроса ИИ-ассистентом
Подгружается история чата (n8n_chat_histories).
Ollama через API получает запрос, системный промпт и список инструментов.
Вызывается PGVector Store, ищутся релевантные фрагменты.
Фрагменты возвращаются в модель и используются при генерации ответа.
Формирование ответа
Ответ сохраняется в историю чата.
Для отправки используется API Rocket.Chat: POST /api/v1/chat.sendMessage.
Чтобы сообщение корректно дошло, пришлось использовать JSON-конструкцию с преобразованием текста через JSON.stringify().
Это важно: без него тело запроса может быть некорректным — спецсимволы «ломают» структуру JSON, и Rocket.Chat не принимает сообщение.
Пример:
{ «message»: { «rid»: {{ JSON.stringify($(‘Edit Fields’).item.json.sessionId) }}, «msg»: {{ JSON.stringify($json.output) }} }
Безопасность и приватность
Ассистент разворачивается в изолированном окружении Рег.облака.
Данные хранятся у клиента.
API Ollama ограничен локальным доступом (фаервол).
В Open WebUI закрыты внешние регистрации.
Сервисы запускаются не от root.
Образ собирается без X/VNC (минимальная поверхность атаки).
Что мы узнали
Эксперимент показал, что связка RAG на базе нашего ИИ-ассистента и n8n действительно закрывает сценарий поддержки без fine-tuning: бот отвечает по последней версии документов, и это работает так, как мы задумывали. Архитектурно себя оправдало разделение процессов — отдельно конвейер загрузки знаний (сплиттер, embeddings, PGVector) и отдельно формирование ответа через поиск релевантных фрагментов и генерацию в Ollama.
Из минусов: тяжёлые модели требуют серьёзных ресурсов, голос на русском пока сыроват, а переключение тарифов даёт задержки. Но в остальном решение оказалось рабочим и масштабируемым.
Что дальше
Мы планируем развивать связку: добавить JupyterHub для разработки и тестирования кастомных сценариев и кода агентов; выпустить отдельный образ с n8n, чтобы его можно было развернуть «из коробки» и строить агентов, которые будут интегрироваться в бизнес-процессы — от телеграм-ботов до внутренних инструментов.
Мы проверили RAG в связке с нашим ассистентом — а у вас он решает задачи целиком или больше как дополнение к fine-tuning? Поделитесь опытом!
Источник: habr.com