Самая передовая модель для профессиональной работы и агентов, работающих длительное время.
Представляем GPT-5.2 — самую функциональную серию моделей для профессиональной работы с интеллектуальными ресурсами.
Уже сейчас средний пользователь ChatGPT Enterprise говорит , что ИИ экономит ему 40–60 минут в день, а активные пользователи утверждают, что экономят более 10 часов в неделю. Мы разработали GPT-5.2, чтобы раскрыть еще большую экономическую выгоду для людей; он лучше справляется с созданием электронных таблиц, подготовкой презентаций, написанием кода, распознаванием изображений, пониманием длинных контекстов, использованием инструментов и обработкой сложных многоэтапных проектов.
GPT-5.2 устанавливает новый стандарт по многим показателям, включая GDPval, где он превосходит отраслевых специалистов в решении четко определенных задач интеллектуального труда, охватывающих 44 профессии.
GPT-5.2 Мышление | GPT-5.1 Мышление | |
ВВПval (победы или ничьи) | 70,9% | 38,8% (ГПТ-5) |
SWE-Bench Pro (общедоступный) | 55,6% | 50,8% |
Проверено с помощью SWE-bench | 80,0% | 76,3% |
GPQA Diamond (без инструментов) | 92,4% | 88,1% |
Рассуждения на CharXiv (с использованием Python) | 88,7% | 80,3% |
AIME 2025 (без инструментов) | 100.0% | 94,0% |
FrontierMath (Уровни 1–3) | 40,3% | 31,0% |
FrontierMath (Уровень 4) | 14,6% | 12,5% |
ARC-AGI-1 (проверено) | 86,2% | 72,8% |
ARC-AGI-2 (проверено) | 52,9% | 17,6% |
Notion (открывается в новом окне) , Box (открывается в новом окне) , Shopify (открывается в новом окне) , Harvey (открывается в новом окне) и Zoom (открывается в новом окне) отметили, что GPT-5.2 демонстрирует передовые возможности анализа долгосрочных горизонтов и вызова инструментов. Databricks (открывается в новом окне) , Hex (открывается в новом окне) и Компания Triple Whale (открывается в новом окне) признала GPT-5.2 исключительно эффективным в задачах агентного анализа данных и анализа документов. Компании Cognition (открывается в новом окне) , Warp (открывается в новом окне) , Charlie Labs (открывается в новом окне) , JetBrains (открывается в новом окне) и Augment Code (открывается в новом окне) утверждают, что GPT-5.2 обеспечивает передовые показатели производительности агентного программирования, с измеримыми улучшениями в таких областях, как интерактивное программирование, проверка кода и поиск ошибок.
В ChatGPT сегодня начнется внедрение GPT-5.2 Instant, Thinking и Pro, начиная с платных тарифных планов. В API они уже доступны всем разработчикам.
В целом, GPT-5.2 демонстрирует значительные улучшения в общем интеллекте, понимании долговременного контекста, вызове инструментов агентами и машинном зрении, что делает его более эффективным в выполнении сложных задач реального мира от начала до конца, чем любая предыдущая модель.
Производительность модели
Экономически ценные задачи
GPT-5.2 Thinking — лучшая на сегодняшний день модель для реального профессионального использования. В GDPval , оценке, измеряющей четко определенные задачи интеллектуального труда в 44 профессиях, GPT-5.2 Thinking устанавливает новый рекорд и является нашей первой моделью, которая работает на уровне эксперта или выше. В частности, по мнению экспертов, GPT-5.2 Thinking превосходит или сравнялась с ведущими специалистами отрасли в 70,9% случаев при сравнении задач интеллектуального труда в рамках GDPval. Эти задачи включают создание презентаций, электронных таблиц и других документов. GPT-5.2 Thinking выполнила задачи GDPval более чем в 11 раз быстрее и менее чем за 1% дешевле, чем эксперты, что говорит о том, что в сочетании с человеческим контролем GPT-5.2 может помочь в профессиональной работе. Оценки скорости и стоимости основаны на исторических показателях; скорость в ChatGPT может отличаться.
В GDPval модели пытаются выполнить четко определенную интеллектуальную работу, охватывающую 44 профессии из 9 ведущих отраслей, вносящих наибольший вклад в ВВП США. Задания требуют создания реальных результатов работы, таких как презентации продаж, бухгалтерские таблицы, графики работы пунктов неотложной помощи, производственные схемы или короткие видеоролики. В ChatGPT GPT-5.2 Thinking имеет новые инструменты, которых нет в GPT-5 Thinking.
Оценивая один из особенно удачных результатов работы, один из членов жюри GDPval отметил: «Это впечатляющий и заметный скачок в качестве результатов… [он] выглядит так, будто его выполнила профессиональная компания со своим штатом сотрудников, и имеет удивительно хорошо продуманную структуру и рекомендации для обоих результатов, хотя в одном из них нам еще предстоит исправить некоторые незначительные ошибки».
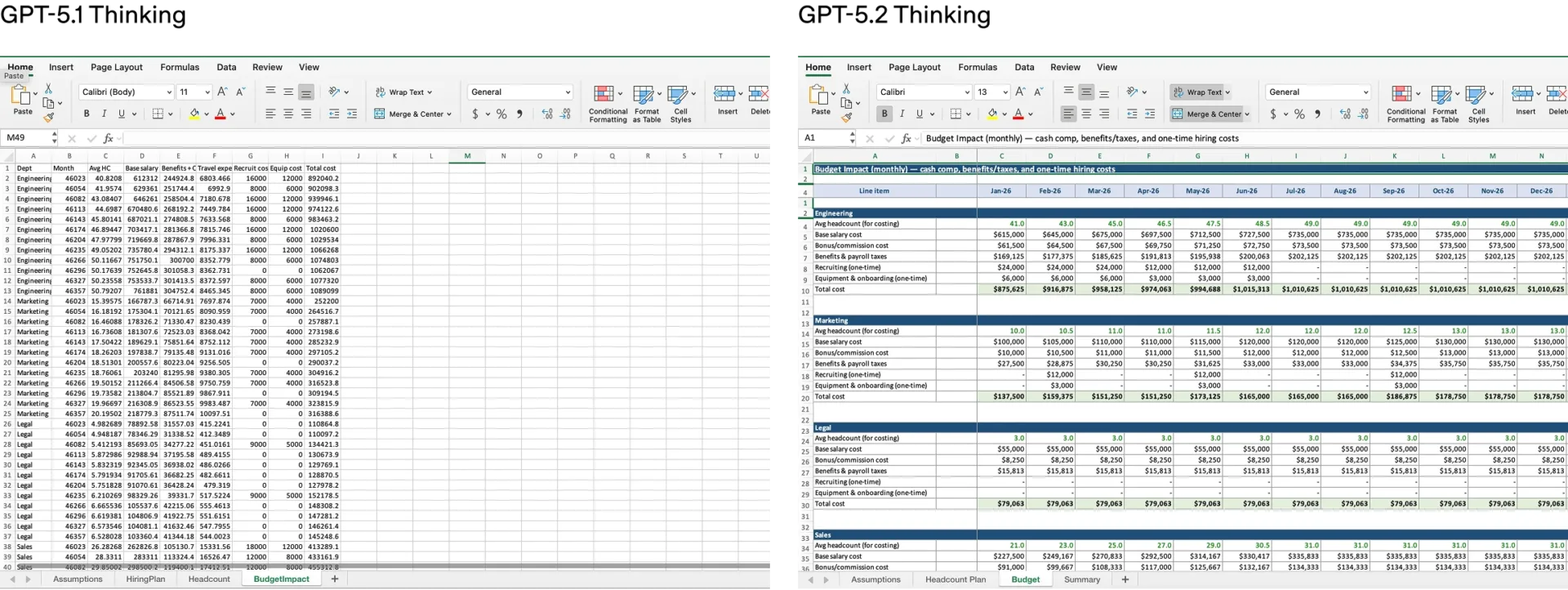
Кроме того, в нашем внутреннем сравнительном анализе задач по моделированию в электронных таблицах для младших аналитиков инвестиционного банкинга — таких как составление модели из трех финансовых отчетов для компании из списка Fortune 500 с правильным форматированием и ссылками или построение модели выкупа с использованием заемных средств для приватизации — средний балл GPT 5.2 Thinking за задачу на 9,3% выше, чем у GPT-5.1, увеличившись с 59,1% до 68,4%.
Сравнительный анализ показывает улучшенную детализацию и форматирование электронных таблиц и слайдов, созданных с помощью GPT-5.2 Thinking:

Задание: Создайте модель планирования численности персонала: численность сотрудников, план найма, текучесть кадров и влияние на бюджет. Включите в модель инженерный, маркетинговый, юридический и отдел продаж.
Для использования новых возможностей работы с электронными таблицами и презентациями в ChatGPT необходимо иметь тарифный план Plus, Pro, Business или Enterprise и выбрать либо GPT-5.2 Thinking , либо Pro . Создание сложных презентаций может занять много минут.
Программирование
GPT-5.2 Thinking устанавливает новый стандарт, достигнув 55,6% в тесте SWE-Bench Pro, представляющем собой строгую оценку реальных задач разработки программного обеспечения. В отличие от SWE-bench Verified, который тестирует только Python, SWE-Bench Pro тестирует четыре языка и стремится быть более устойчивым к загрязнению, сложным, разнообразным и актуальным для промышленности.
В SWE-Bench Pro ( открывается в новом окне) модели предоставляется репозиторий кода, и она должна сгенерировать патч для решения реалистичной задачи разработки программного обеспечения .
В тесте SWE-bench Verified (результаты не показаны) показатель GPT‑5.2 Thinking достиг нового максимума в 80%.
В повседневном профессиональном использовании это означает модель, которая позволяет более надежно отлаживать производственный код, реализовывать запросы на новые функции, рефакторить большие кодовые базы и выпускать исправления от начала до конца с меньшим количеством ручного вмешательства.
GPT-5.2 Thinking также лучше подходит для фронтенд-разработки, чем GPT-5.1 Thinking. Первые тестировщики обнаружили, что он значительно лучше справляется с фронтенд-разработкой и сложной или нестандартной работой над пользовательским интерфейсом, особенно с использованием 3D-элементов, что делает его мощным инструментом для инженеров, работающих со всем стеком технологий. Вот несколько примеров того, что он может создать на основе одного запроса:
Задание: Создайте одностраничное приложение в одном HTML-файле, отвечающее следующим требованиям:
— Название: Моделирование океанских волн
— Цель: Отобразить реалистичные анимированные волны.
— Функции: Изменение скорости ветра, высоты волн, освещения.
— Пользовательский интерфейс должен быть спокойным и реалистичным.
Первые тестировщики поделились своими отзывами о возможностях программирования в GPT-5.2:
«GPT-5.2 представляет собой самый большой скачок для моделей GPT в области агентного программирования со времен GPT-5 и является лучшей моделью программирования в своем ценовом диапазоне. Увеличение версии не отражает в полной мере скачок в интеллектуальных возможностях. Мы рады сделать ее моделью по умолчанию для Windsurf и нескольких основных рабочих нагрузок Devin».
Джефф Ванг, генеральный директор Windsurf
Фактичность
Модель GPT-5.2 Thinking реже выдает галлюцинации, чем модель GPT-5.1 Thinking. В наборе обезличенных запросов из ChatGPT количество ответов с ошибками было на 30% меньше . Для профессионалов это означает меньше ошибок при использовании модели для исследований, написания текстов, анализа и поддержки принятия решений, что делает модель более надежной для повседневной работы с информацией.
Уровень сложности рассуждений был установлен на максимально доступный, и был включен инструмент поиска. Ошибки были обнаружены другими моделями, которые сами могут допускать ошибки. Показатели ошибок на уровне отдельных заявок значительно ниже, чем показатели ошибок на уровне ответов, поскольку большинство ответов содержат множество заявок.
Как и все модели, GPT-5.2 «Мышление» несовершенна. По любому важному вопросу следует перепроверить ответы.
Длинный контекст
GPT-5.2 Thinking устанавливает новый стандарт в области анализа длинного контекста, демонстрируя лучшие результаты в тесте OpenAI MRCRv2 — оценке, проверяющей способность модели интегрировать информацию, разбросанную по длинным документам. В реальных задачах, таких как глубокий анализ документов, требующий связи между сотнями тысяч токенов, GPT-5.2 Thinking значительно точнее, чем GPT-5.1 Thinking. В частности, это первая модель, которая, как мы видели, достигает почти 100% точности в варианте MRCR с 4 иглами (до 256 тысяч токенов).
На практике это позволяет профессионалам использовать GPT-5.2 для работы с длинными документами — такими как отчеты, контракты, научные статьи, стенограммы и многофайловые проекты — сохраняя при этом согласованность и точность сотен тысяч токенов. Это делает GPT-5.2 особенно подходящим для глубокого анализа, синтеза и сложных рабочих процессов с использованием нескольких источников.
В OpenAI-MRCR (открывается в новом окне) v2 (многораундовое разрешение кореференции) несколько идентичных пользовательских запросов типа «игла» вставляются в длинные «стоги сена» похожих запросов и ответов, и модели предлагается воспроизвести ответ до n-й иглы. Версия 2 оценки исправляет ~5% задач, имевших неверные значения истинных значений. Средний коэффициент совпадения измеряет средний коэффициент совпадения строк между ответом модели и правильным ответом. Точки при максимальном количестве входных токенов 256 тыс. представляют собой средние значения по 128–256 тыс. входных токенов и так далее. Здесь 256 тыс. представляют собой 256 * 1024 = 262 144 токена. Усилие рассуждения было установлено на максимально доступное значение.
Для задач, требующих выхода за пределы максимального контекстного окна, GPT-5.2 Thinking совместим с нашей новой конечной точкой Responses /compact , которая расширяет эффективное контекстное окно модели. Это позволяет GPT-5.2 Thinking справляться с более ресурсоемкими и длительными рабочими процессами, которые в противном случае были бы ограничены длиной контекста. Подробнее читайте в нашей документации по API (открывается в новом окне) .
Зрение
Модель GPT-5.2 Thinking — наша самая мощная модель обработки изображений на сегодняшний день, позволяющая сократить количество ошибок примерно вдвое при анализе диаграмм и понимании интерфейса программного обеспечения.
В повседневном профессиональном использовании это означает, что модель может более точно интерпретировать панели мониторинга, скриншоты продуктов, технические схемы и визуальные отчеты, поддерживая рабочие процессы в финансах, операциях, проектировании, дизайне и поддержке клиентов, где визуальная информация имеет центральное значение.
В CharXiv Reasoning (открывается в новом окне) модели отвечают на вопросы, касающиеся визуальных диаграмм из научных статей. Был включен инструмент Python, а уровень сложности рассуждений был установлен на максимум.
В ScreenSpot-Pro (открывается в новом окне) модели должны анализировать скриншоты высокого разрешения графических пользовательских интерфейсов из различных профессиональных условий. Инструмент Python был включен, а уровень сложности анализа был установлен на максимум. Без инструмента Python результаты будут значительно ниже. Мы рекомендуем включать инструмент Python для подобных задач компьютерного зрения.
По сравнению с предыдущими моделями, GPT-5.2 Thinking лучше понимает расположение элементов на изображении, что помогает в задачах, где относительное расположение играет ключевую роль в решении проблемы. В приведенном ниже примере мы просим модель идентифицировать компоненты на входном изображении (в данном случае, материнскую плату) и вернуть метки с приблизительными ограничивающими рамками. Даже на изображении низкого качества GPT-5.2 идентифицирует основные области и размещает рамки, которые иногда соответствуют истинному расположению каждого компонента, в то время как GPT-5.1 помечает лишь несколько частей и демонстрирует гораздо более слабое понимание их пространственного расположения. Обе модели допускают явные ошибки, но GPT-5.2 демонстрирует лучшее понимание изображения.
ГПТ-5.1

ГПТ-5.2

вызов инструмента
GPT-5.2 Thinking достигает нового уровня производительности в 98,7% на тестовом наборе Tau2-bench Telecom, демонстрируя свою способность надежно использовать инструменты в длительных, многоэтапных задачах.
В сценариях использования, чувствительных к задержке, GPT-5.2 Thinking также демонстрирует гораздо лучшие результаты при reasoning.effort='none', существенно превосходя GPT-5.1 и GPT-4.1.
В τ2-bench (открывается в новом окне) модели используют инструменты для выполнения задач поддержки клиентов в многоэтапном взаимодействии с имитированным пользователем. Для телекоммуникационной отрасли мы включили в системное приглашение краткую, в целом полезную инструкцию для повышения производительности. Мы исключили подмножество авиаперевозок из-за более низкого качества эталонных оценок.
Для профессионалов это означает более эффективные сквозные рабочие процессы — такие как обработка обращений в службу поддержки клиентов, извлечение данных из нескольких систем, проведение анализа и создание конечных результатов с меньшим количеством сбоев между этапами.
Например, при обработке сложного вопроса в службе поддержки клиентов, требующего многоэтапного решения, модель может более эффективно координировать весь рабочий процесс между несколькими агентами. В приведенном ниже примере путешественник сообщает о задержке рейса, пропущенной пересадке, ночевке в Нью-Йорке и необходимости размещения по медицинским показаниям. GPT-5.2 управляет всей цепочкой задач — перебронированием, размещением с особыми потребностями и компенсацией — обеспечивая более полный результат, чем GPT-5.1.
Мой рейс из Парижа в Нью-Йорк задержали, и я пропустила стыковочный рейс в Остин. Мой зарегистрированный багаж также пропал, и мне нужно переночевать в Нью-Йорке. Кроме того, мне необходимо место в первом ряду по медицинским показаниям. Можете ли вы мне помочь?
ГПТ-5.1

ГПТ-5.2

Наука и математика
Одна из наших надежд на ИИ заключается в том, что он ускорит научные исследования на благо всех. С этой целью мы сотрудничаем с учеными и прислушиваемся к их мнению, чтобы понять, как ИИ может ускорить их работу, и в прошлом месяце мы поделились здесь некоторыми ранними результатами совместных экспериментов .
Мы считаем, что GPT-5.2 Pro и GPT-5.2 Thinking — лучшие в мире модели для помощи и ускорения работы ученых. В GPQA Diamond, сравнительном тесте вопросов и ответов для аспирантов, GPT-5.2 Pro набирает 93,2%, за ним следует GPT-5.2 Thinking с результатом 92,4%.
В GPQA Diamond (открывается в новом окне) модели отвечают на вопросы с несколькими вариантами ответов по физике, химии и биологии. Никакие инструменты не были включены, а уровень сложности рассуждений был установлен на максимум.
На платформе FrontierMath (уровни 1–3), оценивающей математический уровень экспертов, тест GPT-5.2 Thinking установил новый рекорд, решив 40,3% задач.
В FrontierMath (открывается в новом окне) модели решают математические задачи экспертного уровня. Был включен инструмент Python, а уровень сложности рассуждений был установлен на максимум.
Мы начинаем видеть, как модели ИИ существенно ускоряют прогресс в математике и науке, причем ощутимым образом. Например, в недавней работе с GPT-5.2 Pro исследователи изучили открытый вопрос в теории статистического обучения. В узкой, четко определенной постановке задачи модель предложила доказательство, которое впоследствии было проверено авторами и рассмотрено внешними экспертами, демонстрируя, как передовые модели могут способствовать математическим исследованиям под пристальным наблюдением человека.
ARC-AGI 2
В тесте ARC-AGI-1 (проверено), предназначенном для измерения общих способностей к рассуждению, GPT-5.2 Pro стал первой моделью, преодолевшей порог в 90%, улучшив свой результат с 87% (открывается в новом окне) в прошлогодней версии o3-preview, при этом снизив стоимость достижения этого показателя примерно в 390 раз.
На тесте ARC-AGI-2 (проверено), который повышает сложность и лучше изолирует гибкое мышление, GPT-5.2 Thinking достигает нового уровня для моделей логического мышления, набрав 52,9%. GPT-5.2 Pro показывает еще более высокие результаты, достигая 54,2%, что еще больше расширяет возможности модели для решения новых, абстрактных задач.
Улучшения, отмеченные в ходе этих оценок, отражают более эффективную многоступенчатую систему рассуждений GPT-5.2, более высокую количественную точность и более надежное решение сложных технических задач.
Вот что говорят о GPT-5.2 наши первые тестировщики:
«GPT-5.2 открыл для нас полный архитектурный сдвиг. Мы объединили хрупкую многоагентную систему в одного мега-агента с более чем 20 инструментами. Самое лучшее — это то, что он просто работает. Мега-агент стал быстрее, умнее и в 100 раз проще в обслуживании. Мы наблюдаем значительно меньшую задержку, гораздо более эффективный вызов инструментов, и нам больше не нужны разветвлённые системные подсказки, потому что 5.2 будет корректно выполняться с помощью простой однострочной подсказки. Это похоже на чистую магию».
Эй Джей Орбах, генеральный директор Triple Whale
GPT-5.2 в ChatGPT
В ChatGPT пользователи должны заметить, что GPT-5.2 удобнее в повседневном использовании — он более структурирован, надежен и при этом по-прежнему приятен для общения.
GPT-5.2 Instant — это быстрый и мощный инструмент для повседневной работы и обучения, демонстрирующий явные улучшения в поиске информации, инструкциях и пошаговых руководствах, техническом тексте и переводе, основанные на более дружелюбном разговорном тоне, представленном в GPT-5.1 Instant. Первые тестировщики особенно отметили более понятные объяснения, которые выводят ключевую информацию на первый план.
GPT-5.2 Thinking разработан для более глубокой работы, помогая пользователям решать более сложные задачи с большей отточенностью — особенно это касается программирования, составления резюме длинных документов, ответов на вопросы о загруженных файлах, пошагового решения математических и логических задач, а также поддержки планирования и принятия решений с помощью более четкой структуры и более полезной информации.
GPT-5.2 Pro — это наш самый умный и надежный вариант для сложных задач, где более качественный ответ стоит того, чтобы подождать. Предварительное тестирование показало меньшее количество серьезных ошибок и более высокую производительность в сложных областях, таких как программирование.
Безопасность
GPT-5.2 основан на исследованиях безопасного завершения , которые мы представили в GPT-5, и учит модель давать наиболее полезный ответ, оставаясь при этом в пределах безопасных границ.
В этом релизе мы продолжили работу по улучшению реакции наших моделей на деликатные разговоры , добившись значительных улучшений в том, как они реагируют на подсказки, указывающие на признаки суицидальных наклонностей или членовредительства, психического расстройства или эмоциональной зависимости от модели. Эти целенаправленные вмешательства привели к уменьшению количества нежелательных реакций как в GPT-5.2 Instant, так и в GPT-5.2 Thinking по сравнению с моделями GPT-5.1 и GPT-5 Instant и Thinking. Более подробную информацию можно найти в карточке системы .
Мы находимся на начальном этапе внедрения нашей модели прогнозирования возраста , которая позволит нам автоматически применять меры защиты контента для пользователей младше 18 лет, чтобы ограничить доступ к конфиденциальной информации. Это дополняет наш существующий подход к пользователям, которые, как нам известно, младше 18 лет, и наши средства родительского контроля.
GPT-5.2 — это лишь один шаг в серии непрерывных улучшений, и мы еще далеки от завершения. Хотя этот релиз обеспечивает значительный прирост интеллекта и производительности, мы знаем, что есть области, где люди хотят большего. В ChatGPT мы работаем над известными проблемами, такими как чрезмерное количество отказов, одновременно продолжая повышать общий уровень безопасности и надежности. Эти изменения сложны, и мы сосредоточены на том, чтобы сделать их правильно.
Оценка психического здоровья
ГПТ-5.2 | ГПТ-5.1 | ГПТ-5.2 | ГПТ-5.1 | |
Психическое здоровье | 0,995 | 0,883 | 0,915 | 0,684 |
Эмоциональная зависимость | 0,938 | 0,945 | 0,955 | 0,785 |
Причинять себе вред | 0,938 | 0,925 | 0,963 | 0,937 |
Наличие и цены
В ChatGPT мы начинаем внедрение GPT-5.2 (Instant, Thinking и Pro) сегодня, начиная с платных тарифных планов (Plus, Pro, Go, Business, Enterprise). Мы внедряем GPT-5.2 постепенно, чтобы обеспечить максимально плавную и надежную работу ChatGPT; если вы не видите его с первого раза, пожалуйста, попробуйте позже. В ChatGPT GPT-5.1 будет доступен платным пользователям в течение трех месяцев в рамках старых тарифных планов, после чего мы прекратим его поддержку.
Именование моделей в ChatGPT и API
ChatGPT | API |
ChatGPT-5.2 Instant | GPT-5.2-chat-latest |
ChatGPT-5.2 Мышление | ГПТ-5.2 |
ChatGPT-5.2 Pro | GPT-5.2 Pro |
В нашей API-платформе GPT-5.2 Thinking доступен уже сегодня в API ответов и API завершения чатов как gpt-5.2 , а GPT-5.2 Instant — как gpt-5.2-chat-latest . GPT-5.2 Pro доступен в API ответов как gpt-5.2-pro . Разработчики теперь могут устанавливать параметр логического вывода в GPT-5.2 Pro, и обе версии GPT-5.2 Pro и GPT-5.2 Thinking теперь поддерживают новый пятый уровень логического вывода — xhigh, для задач, где качество имеет первостепенное значение.
Цена GPT-5.2 составляет 1,75 долл. США за 1 млн входных токенов и 14 долл. США за 1 млн выходных токенов, при этом предоставляется скидка 90% на кэшированные входные данные. В ходе многочисленных агентских оценок мы обнаружили, что, несмотря на более высокую стоимость GPT-5.2 за токен, стоимость достижения заданного уровня качества в итоге оказалась ниже благодаря большей эффективности токенов GPT-5.2.
Хотя стоимость подписки на ChatGPT остаётся прежней, в API модель GPT-5.2 стоит дороже за токен, чем GPT-5.1, поскольку она более функциональна. Тем не менее, её цена по-прежнему ниже, чем у других перспективных моделей, поэтому пользователи могут продолжать активно использовать её в своей повседневной работе и основных приложениях.
Цена за миллион токенов
Модель | Вход | Кэшированный ввод | Выход |
gpt-5.2 / | 1,75 доллара | 0,175 доллара | 14 долларов |
gpt-5.2-pro | 21 доллар | — | 168 долларов |
gpt-5.1 / | 1,25 доллара | 0,125 доллара | 10 долларов |
gpt-5-pro | 15 долларов | — | 120 долларов |
В настоящее время у нас нет планов по прекращению поддержки GPT-5.1, GPT-5 или GPT-4.1 в API, и мы сообщим о любых планах по прекращению поддержки заблаговременно до того, как они станут недоступны для разработчиков. Хотя GPT-5.2 будет хорошо работать в Codex без дополнительных настроек, мы ожидаем выпустить версию GPT-5.2, оптимизированную для Codex, в ближайшие недели.
Наши партнеры
GPT-5.2 был разработан в сотрудничестве с нашими давними партнерами NVIDIA и Microsoft. Центры обработки данных Azure и графические процессоры NVIDIA, включая H100, H200 и GB200-NVL72, лежат в основе инфраструктуры масштабируемого обучения OpenAI, обеспечивая значительный прирост интеллектуальных возможностей моделей. Благодаря этому сотрудничеству мы можем уверенно масштабировать вычислительные мощности и быстрее выводить новые модели на рынок.
Приложение
Подробные сравнительные тесты
Ниже представлены полные результаты сравнительных тестов для GPT-5.2 Thinking, а также их часть для GPT-5.2 Pro.
Профессиональный
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| GDPval (допускаются ничьи, победы или ничьи) | 70,9% | 74,1% | 38,8% (ГПТ-5) |
| GDPval (допускаются ничьи, явные победители) | 49,8% | 60,0% | 35,5% (ГПТ-5) |
| ВВПval (без совпадений) | 61,0% | 67,6% | 37,1% (ГПТ-5) |
| Задачи по работе с электронными таблицами в инвестиционном банкинге (внутренние) | 68,4% | 71,7% | 59,1% |
Программирование
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| SWE-Bench Pro, публичный | 55,6% | — | 50,8% |
| Проверено с помощью SWE-bench | 80,0% | — | 76,3% |
| SWE-Lancer, IC Diamond* | 74,6% | — | 69,7% |
Фактичность
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| ChatGPT отвечает без ошибок (с функцией поиска). | 93,9% | — | 91,2% |
| Ответы ChatGPT без ошибок (без поиска) | 88,0% | — | 87,3% |
Длинный контекст
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| OpenAI MRCRv2, 8 игл, 4k–8k | 98,2% | — | 65,3% |
| OpenAI MRCRv2, 8 игл, 8k–16k | 89,3% | — | 47,8% |
| OpenAI MRCRv2, 8 игл, 16–32 тыс. | 95,3% | — | 44,0% |
| OpenAI MRCRv2, 8 игл, 32–64 тыс. | 92,0% | — | 37,8% |
| OpenAI MRCRv2, 8 игл, 64k–128k | 85,6% | — | 36,0% |
| OpenAI MRCRv2, 8 игл, 128–256 тыс. | 77,0% | — | 29,6% |
| BrowseComp Long Context 128k | 92,0% | — | 90,0% |
| BrowseComp Длинный контекст 256k | 89,8% | — | 89,5% |
| GraphWalks bfs <128k | 94,0% | — | 76,8% |
| Graphwalks parents <128k | 89,0% | — | 71,5% |
Зрение
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| Рассуждения на CharXiv (без инструментов) | 82,1% | — | 67,0% |
| Рассуждения на CharXiv (с использованием Python) | 88,7% | — | 80,3% |
| MMMU Pro (без инструментов) | 79,5% | — | — |
| MMMU Pro (с Python) | 80,4% | — | 79,0% |
| Видео MMMU (без инструментов) | 85,9% | — | 82,9% |
| Screenspot Pro (с Python) | 86,3% | — | 64,2% |
Использование инструментов
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| Tau2-bench Telecom | 98,7% | — | 95,6% |
| Tau2-bench Retail | 82,0% | — | 77,9% |
| BrowseComp | 65,8% | 77,9% | 50,8% |
| Масштаб MCP-атласа | 60,6% | — | 44,5% |
| Туатлон | 46,3% | — | 36,1% |
Академический
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| GPQA Diamond (без инструментов) | 92,4% | 93,2% | 88,1% |
| HLE (без инструментов) | 34,5% | 36,6% | 25,7% |
| HLE (с поиском, Python) | 45,5% | 50,0% | 42,7% |
| МММЛУ | 89,6% | — | 89,5% |
| HMMT, февраль 2025 г. (без инструментов) | 99,4% | 100.0% | 96,3% |
| AIME 2025 (без инструментов) | 100.0% | 100.0% | 94,0% |
| FrontierMath, уровни 1–3 (с Python) | 40,3% | — | 31,0% |
| FrontierMath Уровень 4 (с Python) | 14,6% | — | 12,5% |
Абстрактное рассуждение
| GPT-5.2 Мышление | GPT-5.2 Pro | GPT-5.1 Мышление | |
|---|---|---|---|
| ARC-AGI-1 (проверено) | 86,2% | 90,5% | 72,8% |
| ARC-AGI-2 (проверено) | 52,9% | 54,2% (высокий) | 17,6% |
Модели запускались с максимальным доступным уровнем вычислительных ресурсов в нашем API (xhigh для GPT-5.2 Thinking и Pro, и high для GPT-5.1 Thinking), за исключением профессиональных оценок, где GPT-5.2 Thinking запускался с максимальным уровнем вычислительных ресурсов, доступным в ChatGPT Pro. Бенчмаркинг проводился в исследовательской среде, что в некоторых случаях может дать несколько иные результаты по сравнению с производственной версией ChatGPT.
* В случае с SWE-Lancer мы исключаем 40 из 237 проблем, которые не были решены на нашей инфраструктуре.
Источник: openai.com