Перевод речи в реальном времени

Мы представляем инновационную сквозную модель перевода речи (S2ST), которая обеспечивает перевод в реальном времени голосом говорящего с задержкой всего в 2 секунды, воплощая в жизнь давно задуманную технологию и делая межъязыковое общение более естественным.
Общение в режиме реального времени является неотъемлемой частью как нашей профессиональной, так и личной жизни. При удаленном общении с людьми, несмотря на языковые барьеры, бывает сложно установить подлинный контакт, полагаясь только на современные переведенные субтитры, поскольку им не хватает индивидуальности и оперативной реакции, необходимых для непринужденного общения. Появление системы преобразования речи в речь (S2ST) устраняет этот пробел, напрямую генерируя переведенный аудиоматериал, что приводит к более естественному общению. Существующие системы преобразования речи в речь часто имеют значительные задержки (4–5 секунд), склонны к накоплению ошибок и, как правило, не обладают персонализацией.
Сегодня мы описываем инновационную сквозную модель S2ST, которая преодолевает эти ограничения, обеспечивая перевод в реальном времени голосом говорящего с задержкой всего в 2 секунды. Новая архитектура использует потоковую обработку данных и, благодаря обучению на синхронизированных по времени данных, значительно сокращает задержку между исходным вводом и переведенной речью. Для поддержки широкого спектра языков мы представляем масштабируемый конвейер сбора синхронизированных по времени данных, который позволяет постепенно расширять систему, включая больше языков. Эта технология продемонстрировала свою эффективность на примере успешного развертывания в критически важных для реального времени сценариях использования.
Каскадный S2ST
Ранее существовавшие технологии преобразования речи в речь в реальном времени использовали каскадную последовательность отдельных блоков обработки:
- Во-первых, исходный аудиофайл преобразуется в текст с помощью моделей автоматического распознавания речи (ASR) на основе искусственного интеллекта.
- Далее, расшифрованный текст дословно переводится на целевой язык с помощью автоматического перевода речи (AST).
- Наконец, переведенный текст преобразуется обратно в аудио с помощью конвейеров преобразования текста в речь (TTS).
Схематическое представление классической каскадной системы преобразования речи в речь.
Несмотря на высокое качество отдельных компонентов каскада, обеспечение бесперебойной работы системы S2ST в режиме реального времени оказалось сложной задачей из-за трех основных факторов:
- Значительные задержки в 4–5 секунд, вынуждающие вести диалог по очереди.
- Накопленные ошибки на каждом этапе процесса перевода.
- Заметное отсутствие персонализации из-за использования универсальной технологии преобразования текста в речь.
Новая комплексная персонализированная система S2ST
Для существенного улучшения S2ST мы создали масштабируемый конвейер сбора данных и разработали сквозную модель, обеспечивающую прямой перевод языка в реальном времени с задержкой всего в две секунды:
- Масштабируемый конвейер сбора данных : Мы создали конвейер обработки данных для преобразования необработанного аудио в синхронизированный по времени входной/целевой набор данных. Это было достигнуто путем интеграции существующих технологий распознавания речи и преобразования текста в речь с точными этапами выравнивания, обеспечивающими наилучшее соответствие переведенного аудио входным данным. Для удаления трудно поддающихся выравниванию примеров были применены строгие фильтрация и проверка.
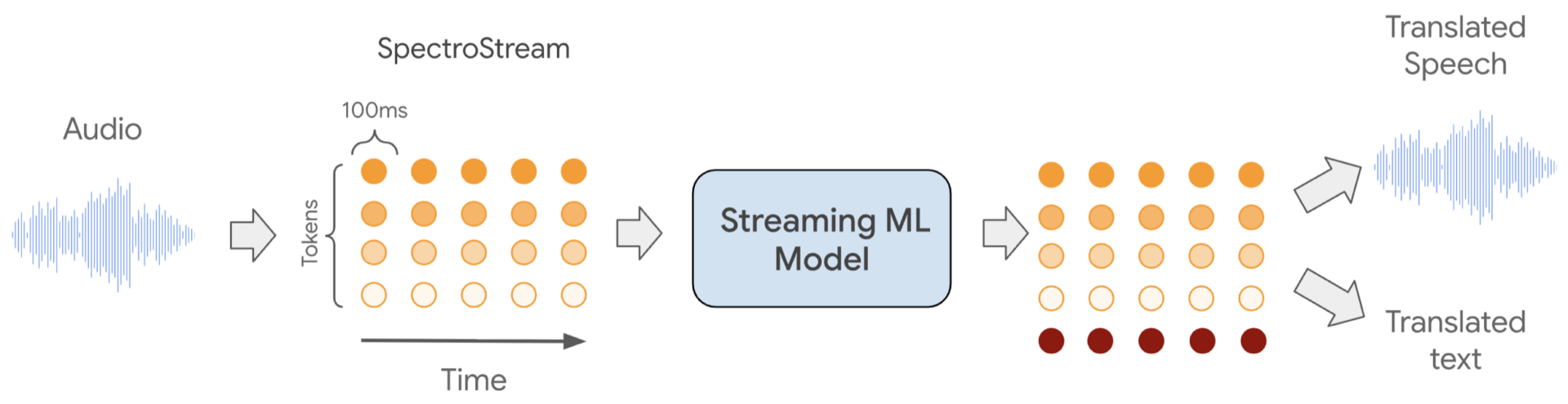
- Архитектура преобразования речи в речь в реальном времени : Мы представили архитектуру машинного обучения для потоковой обработки аудиоданных, предназначенную для поддержки обучения на этих синхронизированных по времени данных. Основываясь на фреймворке AudioLM и основных блоках трансформеров, эта архитектура разработана для обработки непрерывных аудиопотоков, позволяя модели самостоятельно определять, когда выводить результаты преобразования. Она также структурирована для управления иерархическими представлениями аудио с использованием технологии кодека SpectroStream.
| Пример применения нашей персонализированной системы S2ST к испанскому оригиналу, переведенному на английский. |
Масштабируемый конвейер сбора данных
Для заданной пары языков начальная работа начинается с получения исходных аудиоданных. Мы используем разнообразный набор аудиоисточников, включая данные, сгенерированные моделями синтеза речи. Эти аудиоданные проходят процесс очистки и фильтрации, чтобы гарантировать, что они содержат речь одного носителя исходного языка и имеют соответствующий уровень шума. После первоначального сбора данных этап автоматического распознавания речи (ASR) транскрибирует исходный текст. При наличии как исходного аудио, так и текста алгоритм принудительного выравнивания генерирует временные шаги выравнивания (сопоставление аудио и текста). Любые аудиосегменты, где выравнивание не удалось, отбрасываются.
Оставшиеся фрагменты текста переводятся машинным способом с исходного языка на целевой. Затем ряд автоматических фильтров проверяет переведенный текст, обеспечивая его точность и соответствие исходному тексту. Далее, исходный транскрибированный и переведенный тексты также выравниваются для создания соответствующих аннотаций с временными метками (сопоставление текста с переведенным текстом).
С помощью специально разработанного механизма генерации речи переведенный текст преобразуется в переведенный аудиофайл, сохраняя голосовые характеристики исходного аудио и обеспечивая естественное звучание. Конвейер обработки завершается еще одним этапом принудительного выравнивания переведенного текста и сгенерированной речи (преобразование речи в текст).
Создание набора данных для перевода потокового аудио в аудиоформат.
Используя три сгенерированных выравнивания из предыдущих шагов, вычисляется их перекрытие, в результате чего получаются маски выравнивания между исходным и целевым аудиосигналом. Затем эти маски выравнивания используются для управления вычислением функции потерь во время обучения.
Выравнивание текста входных данных и переведенного аудио с соответствующими наложениями.
Недопустимые наложения или смещения, не соответствующие требованиям по задержке, отфильтровываются из обучающего набора данных. Оставшиеся выровненные данные используются для обучения потоковой модели S2ST фрагментами длительностью до 60 секунд. В процессе обучения также применяются различные методы улучшения звука, включая снижение частоты дискретизации, реверберацию, насыщение и шумоподавление.
Архитектура преобразования речи в речь в реальном времени
В сквозной модели S2ST используются основные трансформаторные блоки, и она состоит из двух главных компонентов:
- Потоковый кодировщик: суммирует исходные аудиоданные на основе предыдущих 10 секунд входного сигнала.
- Потоковый декодер: авторегрессионно предсказывает преобразованный звук, используя состояние сжатого кодировщика и предсказания из предыдущих итераций.
Особенностью этих моделей является представление аудио в виде двумерного набора токенов, известных как аудиотокены RVQ. Как показано ниже, ось X представляет время, а ось Y — набор токенов, описывающих текущий аудиосегмент. При суммировании все токены в определенном наборе могут быть легко преобразованы в аудиопоток с помощью кодека машинного обучения. Количество токенов определяет качество звука для каждого сегмента: чем больше токенов, тем выше качество. Модель предсказывает токены последовательно, отдавая приоритет начальным. Как правило, 16 токенов достаточно для высококачественного представления аудиофрагмента длительностью 100 мс.
Схематическое представление процесса обработки потоковой передачи аудиоданных для S2ST.
Модель выдает один текстовый токен в дополнение к аудиотокенам. Этот текстовый токен служит дополнительным априорным значением для генерации аудио и позволяет напрямую вычислять метрики (BLEU) без использования прокси-систем распознавания речи.
В процессе обучения к модели применяется функция потерь для каждого токена, чтобы обеспечить точный перевод. Задержка предсказания модели, или опережающий просмотр, может быть скорректирована путем смещения эталонных токенов вправо, что обеспечивает гибкость в зависимости от сложности целевого языка. Для разговоров в реальном времени обычно используется стандартная задержка в 2 секунды, которая подходит для большинства языков. Хотя более длительный опережающий просмотр улучшает качество перевода, предоставляя больше контекста, он негативно влияет на качество общения в реальном времени.
Отключение прогнозируемого просмотра и соответствующего качества перевода для пары языков испанский/английский (BLEU, чем выше показатель, тем лучше).
Помимо внутренней задержки в 2 секунды, время вывода модели также вносит свой вклад в общую задержку системы. Для минимизации этого фактора и достижения производительности в реальном времени мы реализовали несколько методов оптимизации, включая гибридное квантование с низким разрядом (int8 и int4) и оптимизированные предварительные вычисления контекстно-свободного грамматического графа.
Ниже приведены примеры перевода для различных языковых пар с использованием разработанных моделей и соответствующих эталонных данных (взятых из общедоступного набора данных CVSS):
|
Направление |
Входной аудиосигнал |
Переведенное аудио |
Истинные данные |
|
с испанского на английский |
В прибрежных районах наблюдается большее накопление молекул воды в воздухе. |
||
|
с английского на испанский |
На знаках отличия портавионов, «Портавионы» Грозный огонь, вызванный камикадзе без серьезных последствий. |
||
|
немецкий на английский |
Электрик использовал кусок алюминиевой фольги, чтобы соединить контакты предохранителя. |
||
|
английский на немецкий |
Маргарет версухт с Алленом Миттельном: «Катастрофа из-за катастрофы». |
||
|
с итальянского на английский |
Нажав на значок колокольчика справа, вы можете активировать уведомления Pash, чтобы получать их в режиме реального времени. |
||
|
английский на итальянский |
Популярные голоса владельцев терьеров, мафиози и представителей Консерваторской партии и их имени, которые мы знаем, все. |
||
|
с португальского на английский |
Данный текст распространяется на условиях соответствующей лицензии. |
||
|
английский на португальский |
Um homem de camisa azul наблюдает за всем проектом на фронте. |
||
|
французский на английский |
Добровольные пожарные являются неотъемлемой частью нашего арсенала гражданской безопасности. |
||
|
с английского на французский |
|
|
Правительство и такое большинство предвещают, что они несут ответственность за эту ситуацию. |
| Примеры двунаправленного перевода, сгенерированные обученными моделями для английского, испанского, немецкого, итальянского, португальского и французского языков, с соответствующими эталонными данными. |
Применение в реальном мире
Новая комплексная технология S2ST запущена в двух ключевых областях, подчеркивая важность межъязыковой коммуникации в реальном времени. Теперь она доступна в Google Meet на серверах, а также в качестве встроенной функции на новых устройствах Pixel 10. Хотя продукты используют разные стратегии для запуска конвейера S2ST, они используют общие обучающие данные и архитектуру модели. Функция Pixel Voice Translate на устройстве также использует каскадный подход для максимального охвата языков. Чтобы предотвратить потенциальное неправильное использование функции, перед каждым сеансом перевода мы информируем конечного пользователя о том, что перевод выполняется синтетическим способом.
Посмотрите фильм
Ссылка на видео на YouTube
Новая сквозная технология S2ST обеспечивает функцию перевода речи в Google Meet.
Текущая сквозная модель обеспечивает высокую производительность для пяти языковых пар на основе латинского алфавита (английский на испанский, немецкий, французский, итальянский, португальский и обратно), что позволяет нам запускать первые версии продукта. Мы также наблюдаем многообещающие возможности в других языках, таких как хинди, которые мы планируем развивать дальше. Будущие улучшения будут сосредоточены на повышении динамики прогнозирования модели. Это позволит технологии S2ST беспрепятственно адаптироваться к языкам со значительно отличающимся от английского порядком слов, что обеспечит более контекстуальный, а не дословный перевод.
Мы считаем, что этот прорыв в технологии S2ST произведет революцию в общении между языками в режиме реального времени, превратив давно задуманную концепцию в реальность.
Благодарности
Мы искренне благодарны всем, кто внес свой вклад в этот проект; их неоценимый вклад сыграл решающую роль в его реализации. Особую благодарность мы выражаем нашим коллегам: Кевину Килгуру, Пен Ли, Феликсу де Шомону Квитри, Майклу Дули, Джереми Торпу, Михайло Велимировичу, Алексу Тюдору, Кристиану Франку, Даниэлю Йоханссону, Ханне Силен, Кристиану Шульдту, Хенрику Лундину, Эсбьорну Доминику, Маркусу Вайрбранду, Даниэлю Калландеру, Пабло Баррере Гонсалесу, Хуибу Кляйнхауту, Никласу Блюму, Фредрику Линдстрому, Эше Убовее, Картику Равендрану, Фредерику Рехтенштейну, Син Ли, Куини Чжан, Чэн Янгу, Джейсону Фану, Мацвею Ждановичу, Цзянину Вэю и Маттиасу Грундманну.
Источник: research.google
Оцените материал:

