Размышление для вспоминания: как рассуждение раскрывает параметрические знания в магистерских программах.
Мы изучаем парадоксальное явление, когда рассуждения помогают языковым моделям вспоминать простые факты, даже когда не требуются сложные пошаговые решения. Мы показываем, что это явление обусловлено двумя механизмами: (1) использованием сгенерированных токенов рассуждений для выполнения скрытых вычислений и (2) генерацией связанных фактов для стимулирования запоминания правильного ответа.
Быстрые ссылки
- Бумага
- Делиться
Хорошо известно, что предоставление большим языковым моделям (ЛЯМ) возможности генерировать пошаговые логические цепочки рассуждений, обычно называемые цепочками мыслей (ЦМ), повышает производительность при решении сложных задач. Когда модель решает сложные математические уравнения, пишет программное обеспечение или отвечает на многоэтапные фактические вопросы, разбиение проблемы на управляемые логические шаги оказывается весьма эффективным.
Однако полезность этого подхода остается неясной для простых, одношаговых фактических вопросов. Например, рассмотрим запрос: «В каком году Мэри Энгл Пеннингтон была включена в Национальный зал славы изобретателей?» Либо параметрическая память хранит этот факт в своей параметрической памяти (знание закодировано непосредственно в ее весах), либо нет; никаких сложных арифметических или логических вычислений не требуется. Так почему же трассировка рассуждений может помочь?
В статье «Мышление для запоминания: как рассуждение открывает доступ к параметрическим знаниям в моделях с линейной логикой» мы исследуем это явление. Мы демонстрируем, что предоставление модели возможности генерировать траекторию рассуждения открывает доступ к правильным ответам, которые в противном случае были бы фактически недостижимы. Чтобы понять, почему рассуждение способствует запоминанию параметрических знаний, когда нет сложных шагов рассуждения, мы проводим серию контролируемых экспериментов, основанных на гипотезах. Наши результаты выявляют два взаимодополняющих механизма, лежащих в основе этого явления: эффект вычислительного буфера и фактическое праймирование.
Исследование границ знаний
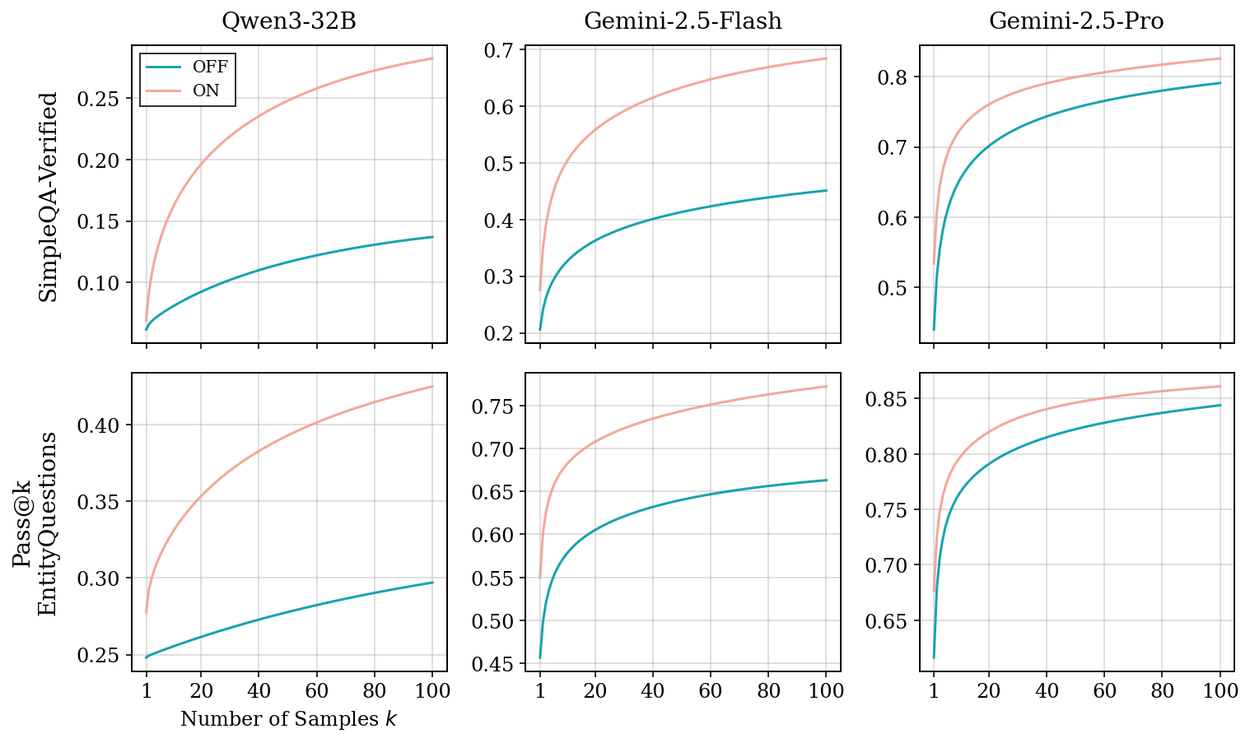
Сначала мы измеряем границу параметрической способности к запоминанию с помощью метрики pass@k. Вместо проверки только одного ответа, сгенерированного моделью, pass@k проверяет, существует ли правильный факт среди нескольких сгенерированных попыток. Оценивая наличие успешных путей рассуждения в выходном распределении модели, при этом будучи менее чувствительным к их точному ранжированию, pass@k помогает нам оценить потенциал рассуждения для запоминания фактов, а не только рассматривать текущее поведение модели, занимающей первое место. Чтобы оценить влияние рассуждения при контроле параметрических знаний, мы фокусируемся на моделях LLM с рассуждениями (R-LLM), где рассуждение может быть включено или выключено (переключено в положение «вкл.» или «выкл.»), и сравниваем pass@k между этими двумя режимами. Мы фокусируемся на моделях Gemini-2.5 (Flash и Pro) и Qwen3-32B, используя два сложных набора данных для вопросов и ответов с закрытой книгой: SimpleQA Verified и EntityQuestions.
Результаты оказались на удивление согласованными. При включенном логическом выводе модели успешно восстанавливают ответы, которые практически невозможно получить, если вывод отключен. Важно отметить, что это улучшение обусловлено не только тем, что модель разлагает сложные вопросы на составляющие. Это результат нашего целенаправленного подхода к наборам данных, содержащим преимущественно простые вопросы, требующие одного шага.
Кривые Pass@𝑘 построены на основе двух наборов данных для закрытых вопросов и ответов и трех моделей LLM, сравнивая одни и те же модели с включенным (ON) и выключенным (OFF) логическим мышлением.
Полученные результаты поднимают вопрос: если эффект не является результатом пошагового рассуждения, то какие же модели рассуждений позволяют модели получить правильный ответ?
Механизм 1: Вычислительный буфер
Наша первая гипотеза сосредоточена на механике генерации. Мы берем давно существующую гипотезу о том, что генерация дополнительных токенов увеличивает время вычислений за счет дополнительных проходов вперед, и проверяем ее в новой постановке задачи параметрического восстановления знаний в R-LLM. В частности, мы предполагаем, что модели неявно используют эти токены рассуждений в качестве вычислительного буфера для выполнения скрытой обработки, независимо от фактического генерируемого семантического содержимого.
Для проверки этого мы разработали эксперимент, в котором из трассировки рассуждений удаляется весь осмысленный контент. Мы перехватываем процесс рассуждений модели и заменяем сгенерированную ею трассировку бессмысленной строкой «Дайте мне подумать» , повторяющейся снова и снова, пока она не сравняется по длине с исходной трассировкой рассуждений. Затем мы позволяем модели предсказать окончательный ответ, исходя из этого фиктивного текста.
Примечательно, что обусловливание модели этим бессмысленным следом существенно улучшает ее способность запоминать правильный ответ по сравнению с базовым вариантом, где рассуждения полностью отключены. Это убедительно доказывает, что простое предоставление модели большего вычислительного пространства помогает ей уточнять свое внутреннее состояние и извлекать труднодоступные факты.

Эффект буфера вычислений на Gemini-2.5-Flash. Функция ON Dummy заменяет ход рассуждений короткой последовательностью без фактического содержания, которая повторяется до длины токена, соответствующей длине исходного расшифровки.
Однако эффект буферизации вычислений имеет свои пределы. Увеличение длины фиктивного текста в конечном итоге приводит к снижению отдачи и никогда не достигает полной производительности естественных логических рассуждений модели. Это означает, что хотя дополнительные вычисления помогают, фактическое содержание мыслей по-прежнему имеет значение.

Эффективность рассуждений как функция длины входных данных в токенах при условии использования фиктивных последовательностей рассуждений. В режиме ON Dummy X последовательность рассуждений заменяется короткой фиктивной последовательностью, которая повторяется таким образом, что длина входных данных составит X токенов. Показатель эффективности рассуждений (Ω) суммирует выигрыш в проходах по k значениям для всех k значений. Мы определяем его как взвешенное среднее относительное различие в проходах по k значениям между режимами ON и OFF рассуждений.
Механизм 2: Фактическое праймирование
Анализируя закономерности естественного мышления, возникающие при решении простых фактических вопросов, мы замечаем общую картину. Модели не выводят логические доказательства, а выявляют связанные факты.
В человеческой когнитивной системе существует концепция, известная как распространение активации, при которой обработка определенной концепции активирует связанные с ней концепции в семантической памяти, облегчая их извлечение. Мы предполагаем, что языковые модели демонстрируют аналогичный генеративный механизм самовоспроизведения, который мы называем фактическим праймингом . Генерируя факты, тематически связанные с вопросом, модель строит контекстный мост, облегчающий извлечение правильного ответа.
Для проверки гипотез мы извлекаем из траекторий рассуждений модели только конкретные факты, применяя строгую фильтрацию для удаления любого лишнего текста, планов поиска или явных упоминаний конечного целевого ответа. Затем мы изолируем эффект запомненных фактов и показываем, что обусловливание на коротком списке запомненных фактов восстанавливает большую часть преимуществ рассуждений и помогает даже тогда, когда рассуждения отключены.

Эффект предварительной обработки фактов в Gemini-2.5-Flash. Сначала мы извлекаем факты, упомянутые в процессе рассуждений. В режиме ON Facts исходный алгоритм рассуждений модели заменяется этим коротким списком фактов и генерируется окончательный ответ, а в режиме OFF Facts алгоритм рассуждений модели запускается в отключенном режиме с использованием списка фактов, предоставленного в качестве дополнительного контекста ввода в рамках запроса.
Например, если спросить имя 10-го короля Непала, логическая модель может сначала перечислить девять предыдущих королей. Воспоминание этих девяти служит семантической разминкой, подготавливая сеть к успешному воспроизведению имени 10-го. Сами факты являются ступеньками на этом пути.

Иллюстрация «фактического прайминга» в действии, где промежуточное извлечение фактов (перечисление девяти предыдущих царей) подготавливает модель к успешному запоминанию 10-го царя Непала. Модель успешно отвечает правильно при включенном (ON) рассуждении, но терпит неудачу без него. Она также успешно отвечает, когда предсказание обусловлено лишь коротким списком фактов, вспомненных во время рассуждения (ON Facts).
Ловушка галлюцинаций
Хотя генеративное самовосстановление является мощным механизмом, оно сопряжено с фундаментальным риском. Поскольку модель генерирует эти промежуточные факты самостоятельно, они могут быть галлюцинаторными. Поэтому мы проверяем, как ошибки на этапе рассуждения влияют на конечный ответ. Чтобы это выяснить, мы создаем крупномасштабный конвейер аудита, используя верификатор с поддержкой поиска, для независимой проверки корректности каждого отдельного промежуточного факта, сгенерированного в сотнях тысяч трасс рассуждений.
Анализ выявил четкую закономерность. Если в логической последовательности рассуждений содержится хотя бы один вымышленный промежуточный факт, вероятность получения правильного окончательного ответа значительно снижается. Это говорит о том, что, несмотря на свою эффективность, механизм фактического прайминга может быть уязвимым.

Соотношение правильных ответов в случаях, когда в рассуждениях присутствуют галлюцинации (галлюцинации), по сравнению с случаями, когда галлюцинаций нет (чистые ответы).
Создание более надежных моделей
Понимание этих механизмов открывает практические пути для повышения надежности модели. Поскольку фактическое предварительное воздействие эффективно, а промежуточные факты, созданные на основе иллюзий, ухудшают производительность, мы можем использовать оба этих подхода для повышения точности модели.
Для оценки потенциала этих выводов мы используем стратегию отбора на этапе тестирования, которая генерирует несколько траекторий рассуждений для одного вопроса, сохраняя только те, которые содержат проверяемые, не содержащие галлюцинаций факты. Приоритизация этих траекторий значительно повышает точность. На практике такая приоритизация может быть реализована во время обучения с помощью вознаграждений за процесс, которые поощряют промежуточные шаги, подкрепленные фактами.

Ожидаемая точность в соответствии с критериями отбора для тестирования, основанными на запоминании фактов и их достоверности.
Заключение
Наши результаты показывают, что рассуждения в языковых моделях служат гораздо более широкой цели, чем просто декомпозиция задачи или математическая логика. Они выступают в качестве фундаментального механизма для раскрытия внутренней памяти модели и расширения границ ее параметрических знаний. Эти выводы открывают захватывающие направления для будущих исследований. Знание того, что фактически точные траектории рассуждений дают лучшие ответы, предполагает возможность дальнейшей оптимизации алгоритмов обучения. Используя вознаграждения за процесс, которые специально поощряют фактически обоснованные промежуточные шаги, мы можем обучить модели, которые по своей природе более надежны и менее склонны к ошибкам. Мы с нетерпением ждем, как исследовательское сообщество продолжит изучать взаимосвязь рассуждений, памяти и извлечения информации.
Благодарности
Данное исследование было проведено Зориком Гехманом, Рои Ахарони, Эраном Офеком, Мор Гевой, Рои Райхартом и Джонатаном Херцигом. Мы благодарим Эяля Бен-Давида и Авинатана Хассидима за рецензирование работы и ценные замечания.
Источник: research.google
Оцените материал:
